基于图像翻译的载体选择式图像隐写方案
2019-11-05李宗翰张敏情
李宗翰,刘 佳,柯 彦,张敏情,罗 鹏
武警工程大学密码工程学院,西安710086
通信和隐私安全越来越受到人们的广泛关注.信息隐藏将秘密信息以各种手段隐藏在原始载体中形成含密载体并发送给接收方.接收方能够恢复秘密信息且通信过程对任何第三方隐蔽、不可见.根据构造含密载体的不同,文献[1]将隐写算法分成3 种策略:基于载体修改的方法、基于载体选择的方法、基于载体合成的方法.
基于载体修改的方法是目前的主流隐写方法,通过对原始图像载体进行修改的操作以达到将秘密消息嵌入的目的.该方法可以分为两类:一是基于模型保持的隐写,由于修改操作导致原始图像统计模型的变化,早期的隐写算法仅考虑保持一种或几种简单模型的统计特征不变,如改进的最低有效位(least significant bit,LSB)[2]等,因此很难抵抗其他统计特征的隐写分析;二是文献[3]提出的基于失真代价函数的方法,该方法通过定义“失真”刻画修改带来的影响,并提出利用伴随网格编码(syndrome-trellis codes,STC)来解决信息嵌入问题.然而“失真”的定义并不具体,很多失真代价函数借助了图像的某些统计模型,很难抵抗基于特征学习的深度神经网络模型的隐写分析技术[4].
基于载体选择的信息隐藏方法,在双方通信前建立固定的图像数据库,通信时根据秘密信息的内容从图像数据库中选择合适的图像,并以传输图像的方式来传输秘密信息.由于不需要对载体进行修改,该类方法旨在建立消息与载体数据集之间的映射,通常需要通信双方共享载体数据集或映射关系,并且需要对载体数据集或映射关系严格保密.该类方法主要集中在人工建立图像与秘密消息的映射[5]及提高嵌入率[6]上.但此类传统的载体选择方法嵌入率低,同时在隐写信道多次传输存在暴露图像库的风险.文献[7]利用生成对抗网络(generative adversarial networks,GAN)建立载体与消息的映射,首次提出生成式隐写的概念,与之前需要共享数据集不同,该方案不需要双方提前共享图像数据集或映射,其本质上是载体选择方案.发送方根据要发送的秘密信息S以及选定的载体图片I产生一个相应的隐写密钥k.而后,载体图片I通过公开信道发送,而密钥通过专门的密钥信道发送,只有同时接收到隐写密钥k与载体I,生成器才可以恢复出秘密信息S.该方案中由于载体图像和秘密信息可以任意选择,在每一次通信时要重新训练,并需要一个安全的通道传送密钥,因此在实际使用中存在一定的限制性.该类方法在实际通信中,通信双方需要对图像库进行保密,不仅存储开销大且随着通信次数增多图像库易暴露.
基于载体合成的图像隐写方法不依赖原始载体,而是直接生成含密载体.文献[8-9]首次提出了一种基于载体合成的生成式隐写方法,该方法首先利用GAN 构建一个图像采样器,然后利用约束采样的方法,生成满足消息提取和图像自然这两个约束的含密载体.该方案的特点在于生成的图像不依赖任意一个特定的载体,含密载体是从生成器分布中采样得到的一个样本,利用图像补全技术实现了一个称之为数字化的卡登格子(digital Cardan grille)的生成隐写方法.文献[10]提出了基于辅助分类器生成对抗网络(auxiliary classifier generative adversarial network,ACGAN)的无载体信息隐藏方案,首先建立秘密信息与噪声的映射关系--码表,然后利用ACGAN 的特点,将噪声z和类别标签C联合作为驱动直接生成含密图像.文献[11]提出的深度卷积生成对抗网络(deep convolution generative adversarial network,DCGAN)隐写方案将秘密信息S分段并映射成(-1,1)上的噪声z,然后输入到生成器G中生成含密图像,恢复消息时将含密图像输入到预先训练好的提取器E中并输出噪声z′,利用映射关系将噪声z′恢复成秘密信息S.以上方法都是直接生成含密载体,能够抵抗基于统计的隐写分析算法的攻击.另外,也有许多学者利用图像翻译的方法,将图像生成风格或内容不同的图像,例如利用跨域变换进行图像翻译的模型[12-14]和利用风格迁移进行图像翻译的模型[15-16]等.图像翻译在一定程度上与载体合成相同,因此可以使用图像翻译的方法实现载体合成式图像隐写.
基于载体选择和基于载体合成的方法与传统隐写方法的不同之处在于,载体选择和载体合成方法不需要通过修改原始载体来嵌入信息,而是通过算法直接“生成”含密载体,因此能够抵御基于统计的隐写分析,安全性较高.
本文提出了一种将载体选择与载体合成结合的方法.基于载体合成不依赖原始载体的思想,将由载体选择方法得到的含密图像通过跨域变换,得到与含密图像内容“不相关”的图像进行传输,解决了传统载体选择方法在隐写信道多次使用可能会暴露图像库的问题.通信双方只需在线下传递跨域关系即可完成对图像的跨域变换,从而实现对含密图像的隐藏与恢复.每次通信时可根据安全需要对跨域关系进行更换,能够解决在信道多次传输同一图像集的安全性问题.此外,在严格保密跨域关系的情况下可将图像库公开,既能减小内存开销,又能提高通信的安全性.
1 本文方法
本文提出的基于图像翻译的载体选择式隐写方案的基本结构如图1所示,主要由以下几部分组成:
1)秘密信息与图像集的映射关系库.该部分建立了秘密信息与图像集图像的映射规则,双方在进行隐藏和提取时根据此映射规则对秘密信息和图像进行可逆转换.该映射关系库可被公开,从而减小了双方通信所造成的内存开销.
2)隐写过程.首先将秘密信息进行分段,然后根据已经建立好的映射关系库对分段秘密信息进行载体选择得到含密图像,最后将含密图像输入到预先训练好的DiscoGAN 跨域变换模型中得到跨域图像并发送给接收方.
3)提取过程.接收方接收到跨域图像后,将跨域图像输入到DiscoGAN 跨域变换模型中,根据事先约定好的跨域变换关系输出得到含密图像,然后依据映射关系库将含密图像逆向转化为秘密信息.
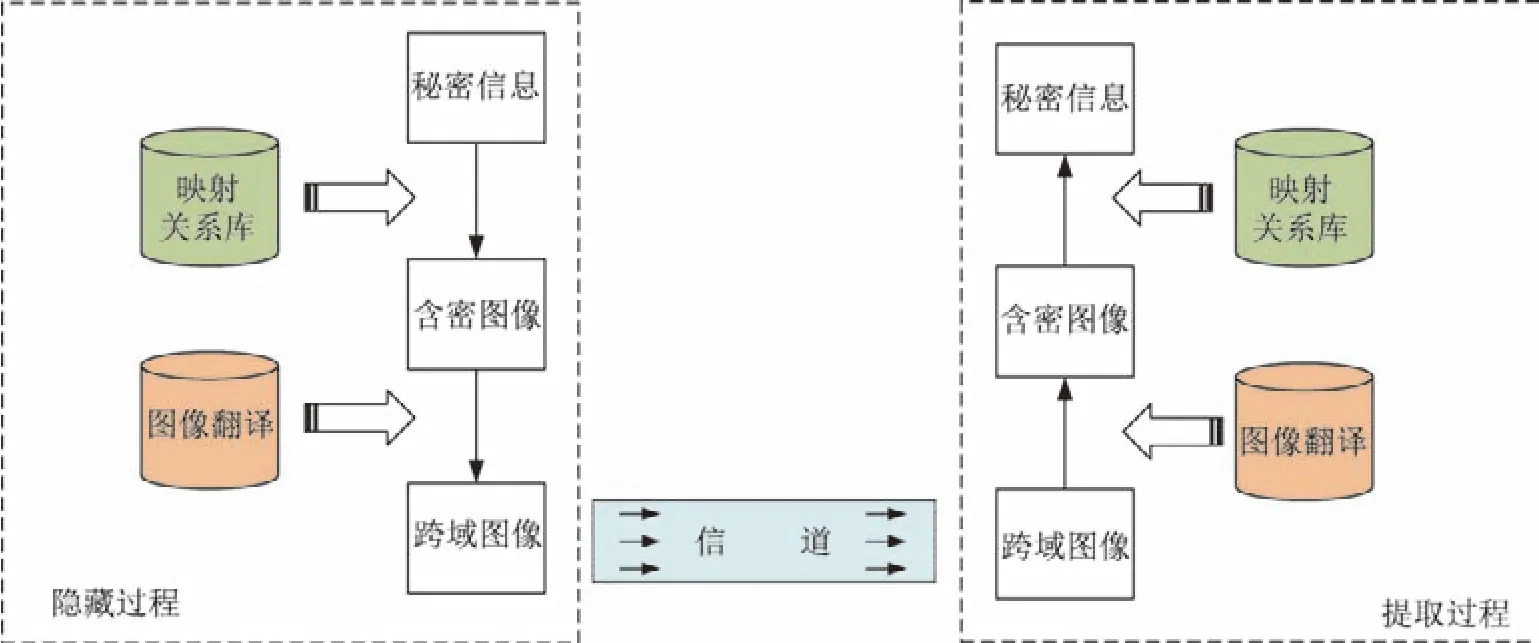
图1 本文方案基本结构Figure1 Basic structure of this scheme
1.1 图像翻译模型——DiscoGAN 的结构
目前用于图像翻译的模型有很多,如DualGAN[12]、CycleGAN.[13]、DiscoGAN[14]等.虽然三者在想法和构思上都非常相似,但CycleGAN 与DualGAN 转换前后两幅图像的相关性较大,如马到斑马、苹果到橘子等.而DiscoGAN 转换前后两幅图像之间的相关性更小,更适合做隐写方案,因此本文选取DiscoGAN 作为图像翻译模型.
DiscoGAN 运用生成对抗网络寻找跨域关系,其思想是将“寻找两个域之间的关系”问题转化为“由一个域生成另一个域”的问题.与传统生成对抗网络[17]模型不同,如图2所示,DiscoGAN 包含2个生成器(GAB和GBA)、2个判别器(DA和DB)、2个重构损失LCONSTA和LCONSTB.其中,生成器GAB的目标是将属于A域的图像xA生成属于B域的图像xAB,相似地,生成器GBA的目标是将属于B域的图像xB生成属于A域的图像xBA;判别器DA和DB用来判别生成器GAB和GBA生成的图像xAB和xBA是否分别属于B域和A域;重构损失LCONSTA使得将xA由A域转化为B域后,再转化回来时依旧属于A域,重构损失LCONSTB同理.生成器输入输出皆为64×64×3 的图像,编码器部分采用4 层卷积层,使用4×4的卷积核,除第1 层与最后一层外,所有卷积层应用Batch Normalization,输出端应用带泄露整流函数(leaky Relu);解码器部分采用4 层反卷积层,使用4×4 的卷积核,除第1 层与最后一层外,所有卷积层应用Batch Normalization,输出端应用线性整流函数(Relu).判别器结构与编码器相似,不同之处在于,前者多出一个附加卷积层,输出端采用sigmoid 函数.
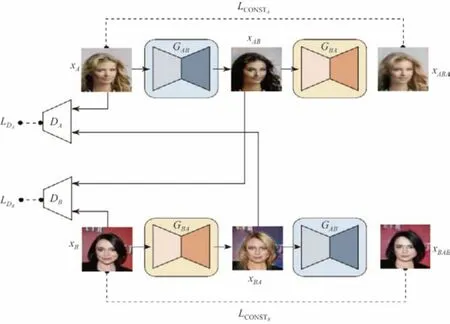
图2 DiscoGAN 结构Figure2 Structure of DiscoGAN
DiscoGAN 模型的损失函数由生成器损失LG和判别器损失LD构成.生成器LG损失函数为

式中,LGANB表示图1上半部分模型的损失,LGANA表示图1下半部分模型的损失,这两部分损失加上两个重构损失LCONSTA和LCONSTB,共同构成生成器损失LG.式(1)中上下2个等号等价.判别器损失LD为

式中,LDA与LDB分别为判别器DA和DB的损失.
1.2 秘密信息与图像集的映射关系库的构建
本方案中映射关系库的构建选取的图像集为鞋图像集,将鞋按人的性别、颜色、材料、鞋头形状、鞋跟类型、鞋帮高低以及鞋带种类等分为7 种分类特征,以二进制信息表示各特征,进而表示图像集中的图像.其中:
1)按人的性别类型分为男鞋和女鞋,用1 位二进制表示.男鞋设置为0,女鞋为1.
2)按颜色类型分为红、橙、黄、绿、青、蓝、紫、黑、白、灰、棕、粉、浅黄、浅绿、浅蓝和浅棕共16 位颜色,用4 位二进制表示.具体信息对照情况见表1.
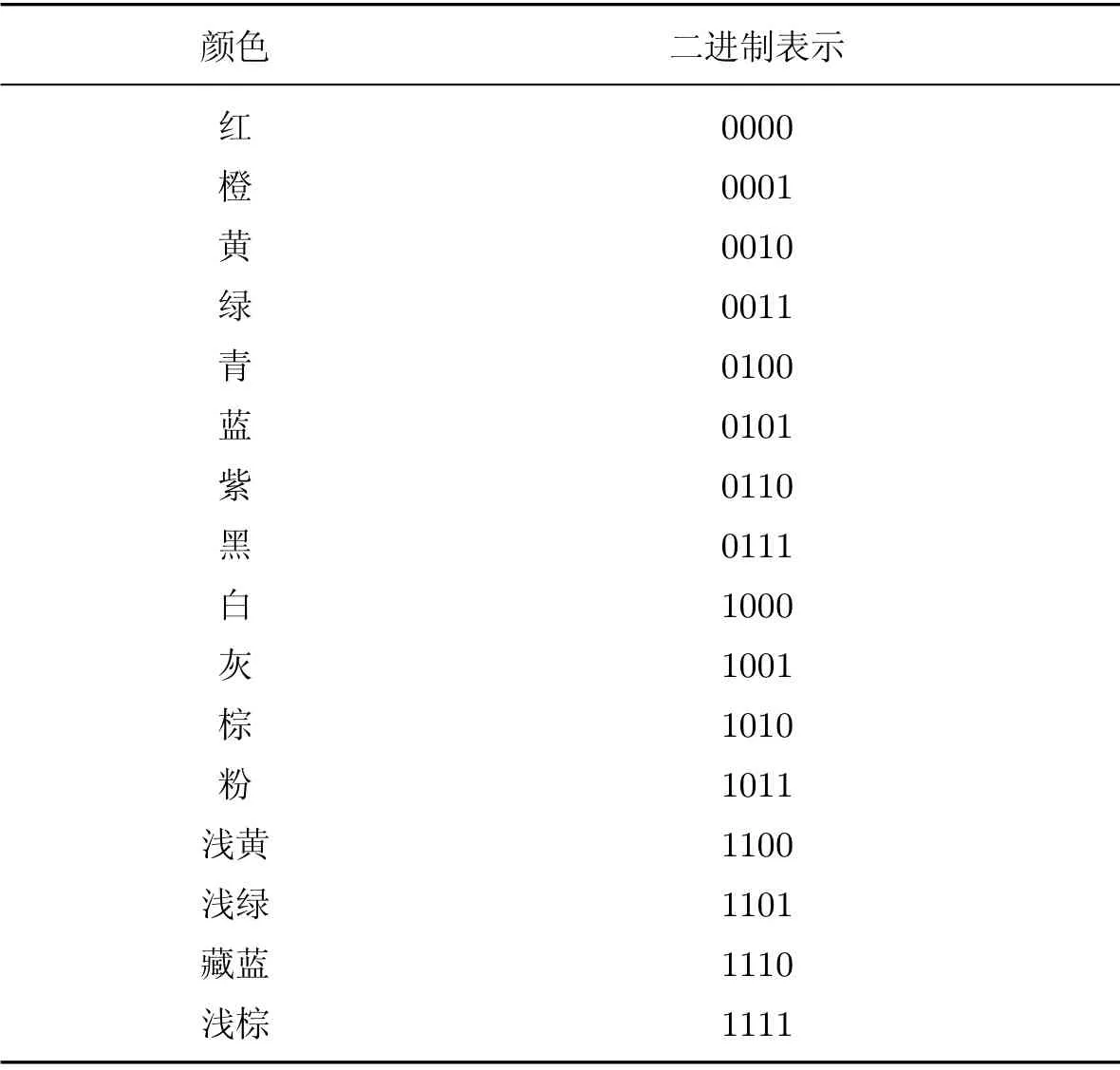
表1 颜色与二进制信息对照表Table1 Color and binary information corresponding
3)按材料可分为皮鞋、布鞋2 种,用1 位二进制表示,皮鞋为0,布鞋为1.
4)按鞋头形状可分为圆头、尖头2 种,用1 位二进制表示,圆头为0,尖头为1.
5)按鞋跟类型可分为有跟、无跟2 种,用1 位二进制表示,有跟为0,无跟为1.
6)按鞋帮高低可分为无帮、低帮、中帮、高帮4 种,用2 位二进制表示、如无帮为00,低帮为01,中帮为10,高帮为11.
7)按鞋带种类可分为无、鞋带、拉锁、粘带4 种,用2 位二进制表示无为00,鞋带为01,拉锁为10,粘带为11.
具体映射关系可见表2.
1.3 隐写过程
双方在通信前应共享相同的跨域变换模型,此模型中包含若干种预先训练好的跨域关系,每次通信需要事先约定好本次通信使用的跨域关系,然后进行信息的隐藏与传递.具体隐藏步骤如下:
步骤1将秘密信息M以每12 位为一段分成n个秘密信息片段M={m1,m2,··· ,mn},若最后一段mn的位数不足12,则剩余位用0 补齐;

表2 映射关系库节选Table2 Excerpt from the mapping library
步骤2根据建立好的图像库映射规则,将每段秘密信息片段mi进行图像检索,得到对应的含密图像Ii实现对秘密信息的第1 次隐藏;
步骤3将载体选择后的含密图像Ii输入到预先训练好的DiscoGAN 模型中,进行跨域变换得到跨域图像I∗i,实现对秘密信息的第2 次隐藏

步骤4按顺序排列所有跨域图像并发送给接收方

隐藏过程如图3所示.

图3 隐藏方案Figure3 Hiding process
1.4 提取过程
发送方传递秘密信息前需要事先训练好若干跨域变换模型,而每个跨域变换模型的训练需要大量的数据集.发送方将训练好的转换模型通过安全信道发送给接收方.接收方不需要事先以大量数据集进行训练,只需通过发送方线下发送的转换模型即可对接收到的跨域图像进行转换,大大减少了通信开销.接收方在接收前利用特征提取算法提取图像库图像的SIFT 特征.提取的具体步骤如下:
步骤1接收方接收到将跨域图像I∗后,将其中每张I∗i输入到DiscoGAN 模型中得到含密图像Ii

步骤2通过计算含密图像Ii与数据库中图像的余弦距离,选择距离最近的图像并根据映射关系库转化为对应的秘密信息片段mi;
步骤3按顺序连接所有秘密信息片段mi得到完整秘密信息m

提取过程如图4所示.
2 实验与分析
本实验在Windows 10 操作系统下运行,深度学习框架为Pytorch1.0.1,编程语言为Python3.7.3,显卡为RTX 2070 Max-Q,计算架构为cuda 10.0,依赖包为cudnn7.5.1.样本数据集为edges2handbags 和edges2shoes 数据集[14](分别包含138 567 张简笔画及其对应包的图像和49 825 张简笔画及其对应鞋的图像),模型输入图像为两个图像集中经过转换且去除edges 部分的图像,大小为64×64,学习率为0.000 2,批处理尺寸batch-size 为64,训练70个迭代次数epoch.根据明文空间,从去除edges部分的edges2shoes 数据集中选取符合映射关系的4 096 张图像构建图像映射库.
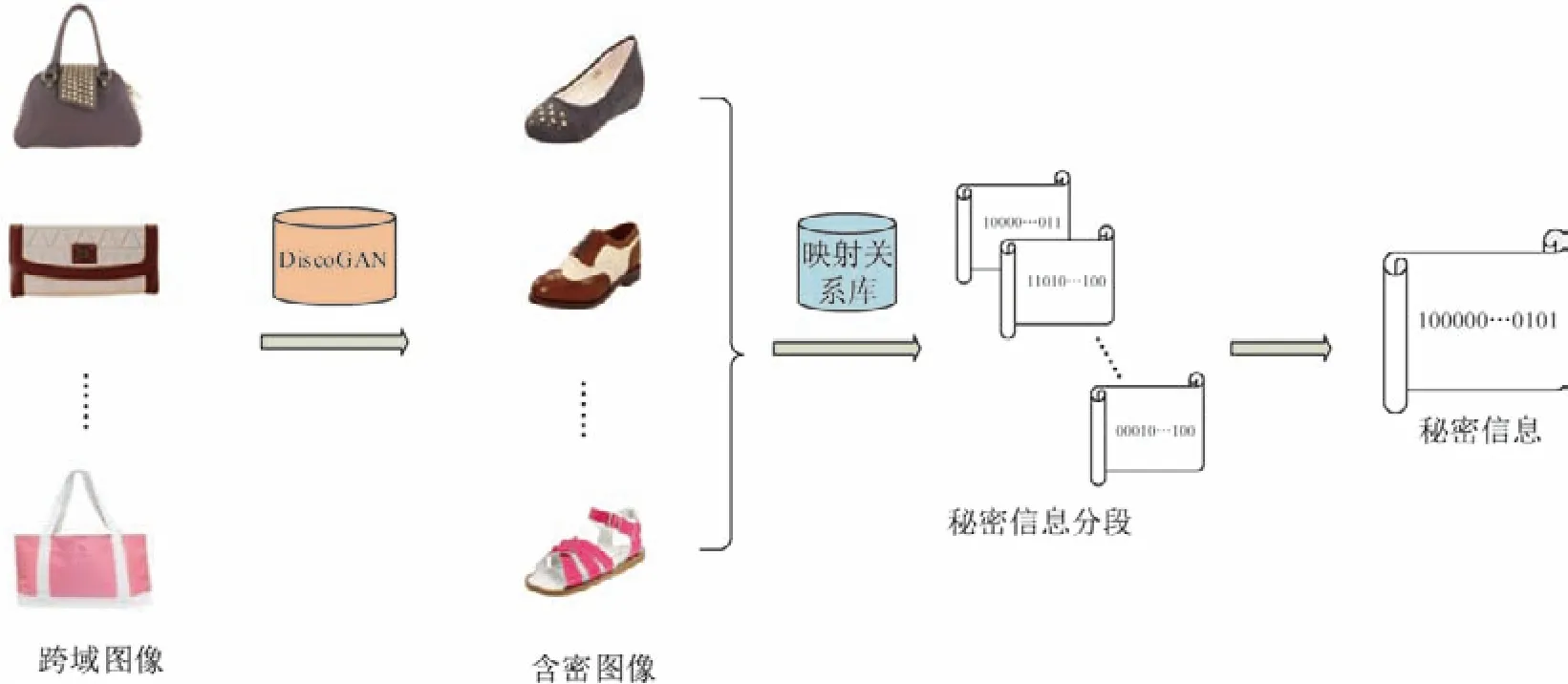
图4 提取过程Figure4 Extracting process
首先对DiscoGAN 模型进行训练,找出2个数据集之间的跨域关系,保存跨域变换模型并用作方案实施.图5是2个数据集训练寻找跨域关系的训练效果图,由图中可以看出,初始未经过训练时,包和鞋都不能相互转化,而随着epoch 即训练轮数的增大,包和鞋能够逐渐地找到跨域关系,直至第70 轮,包和鞋已经能够较好地相互转化,此时认为已经能够找到跨域关系,且DiscoGAN 模型能够进行隐写和提取过程的实现.

图5 鞋训练效果图Figure5 Training effect diagram
2.1 容量
整套方案有2 次秘密信息隐藏过程:第1 次隐藏通过载体选择进行数据嵌入;第2 次通过跨域变换进行数据转换.每幅图能够隐藏秘密信息位数为12.而本方案中构建秘密信息与图像集映射关系库时,关于颜色分类只考虑了16 种主色,若有其他颜色则都归为16 种主色的方法.该方法可以通过细化颜色种类来提高容量;另外在对图像进行特征分类时,只考虑了人的性别、颜色、材料等7个方面,还可以通过增加分类特征来提高容量.
1)细化颜色种类.本文方案中选用的颜色为红、橙、黄、绿、青、蓝、紫、黑、白、灰、棕、粉、浅黄、浅绿、浅蓝、浅棕等16 种颜色.但数据集中依然有混合色的鞋存在,如在一种鞋同时包含蓝、白、灰、橙4 种颜色的情况下,单独以一种颜色表示则不太恰当,可以将颜色用16位表示,那么此鞋颜色用二进制表示则为0100010011000000.此时,每幅图能够隐藏秘密信息位数为24.这种方法虽然能够增加容量,但受所选数据集大小限制,24 位数据需要用16 777 216 种图像表示,远远超出数据集所能表示的范围,所以在本文方案中没有应用此方法.
2)增加分类特征.本文方案考虑的分类特征有性别、颜色、材料、鞋头形状、鞋跟类型、鞋帮高低、鞋带种类等7 种分类特征.其中,性别特征还可以加上儿童,则性别一类改用2 位表示;还可以通过增加用途特征来增大容量,按用途分可分为登山鞋、运动鞋、沙滩鞋、休闲鞋、高跟鞋、正装鞋等6 种,用3 位表示.此时,每幅图能够隐藏秘密信息位数由12 增加到16.未考虑扩容方法有以下两点原因:一是增加位数后超出数据集所能表示的范围;二是加上用途特征后与已有的7 种特征有重合部分.
表3所示为本文方案与一些载体选择与载体合成式隐写方案的隐写容量对比,第1~3 行为基于载体选择的隐写方案,第4~7 行为基于载体合成的隐写方案,第8~10 行为本文提出的方案及其变种.对比发现,虽然本文提出的方案比载体合成式隐写的容量相比较低,但与目前较为先进的载体选择式隐写方案在容量上相比较高.
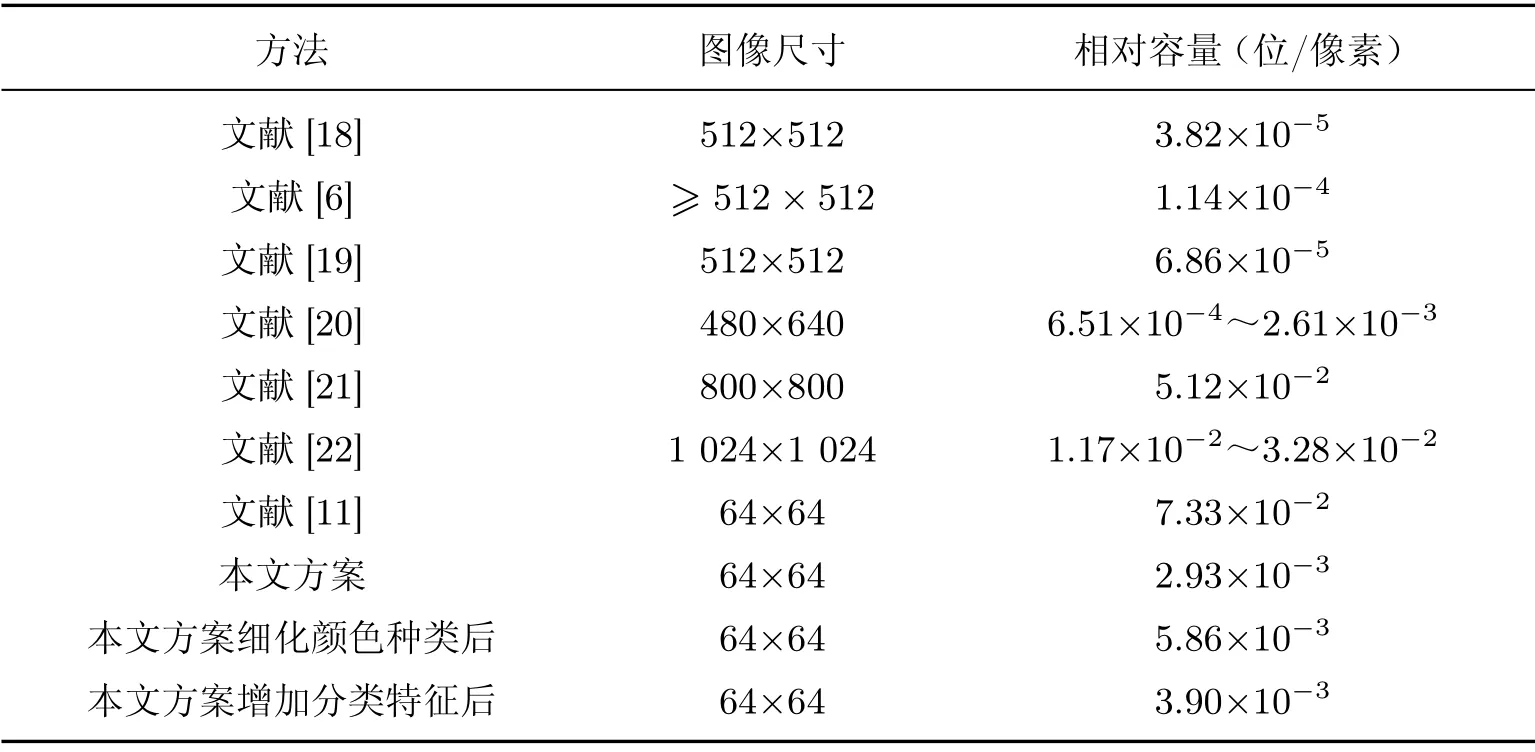
表3 隐藏容量结果表Table3 Experimental results for testing the hiding capacity
2.2 抗检测性
本文根据构建的映射关系库,将秘密信息的隐藏转化为对图像库中自然图像的选择,然后对被选图像进行跨域变换,生成与映射关系库“毫无关联”的跨域图像进行传递.与传统隐写方法相比,虽然传统隐写方法得到的含密图像与原始载体图像用肉眼无法区分,但难以抵御基于统计的信息隐藏分析算法的检测.而本文隐写方案中,由秘密信息选择得到的含密图像与将其生成的跨域图像在纹理细节等方面存在差异,因此这类生成的图像能够抵御基于统计的信息隐藏分析算法的检测.
2.3 恢复准确率
本文方法与载体合成式隐写和载体选择式隐写在恢复准确率方面的对比如表4所示.文献[6]利用深度卷积神经网络的方法进行信息的隐藏和提取属于载体合成式隐写,利用噪声驱动生成含密载体,以σ表示1 位噪声能携带的秘密信息位数.当σ取值为1~3 时,其恢复准确率为0.893~0.960;文献[11]为基于bag-of-words 模型的载体选择式隐写,用bag-of-words模型提取图像的视觉关键词来表达待隐藏的文本信息,提取时根据建立好的映射关系恢复出秘密信息;本文方法先采用载体选择的方法选取含密图像,再经过跨域变换生成跨域图像,用以传递秘密消息,提取时先经过跨域变换恢复出含密载体,而后根据映射关系恢复秘密消息.由于在提取过程中,个别经DiscoGAN 跨域变换回来的图像存在颜色误差,导致根据特征恢复秘密消息时颜色特征部分所对应的秘密消息存在误差,平均恢复准确率为0.85.
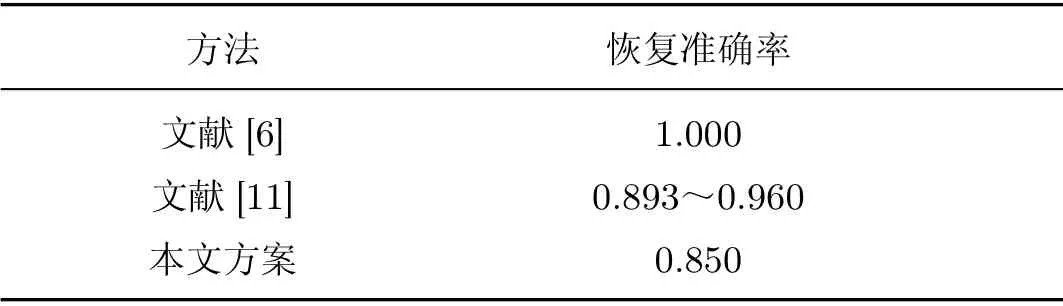
表4 恢复准确率对比Table4 Comparison of recovery accuracy
2.4 安全性分析
文献[23]将隐写分析攻击划分为唯含密载体攻击(SCOA)、已知载体攻击(KCA)、选择载体攻击(CCA)、自适应载体攻击(ACCA)4 类.
无载体信息隐藏由于直接生成含密载体,攻击者除了能得到含密图像之外,不能通过统计分析来区分原始载体与含密载体,所以能够抵抗唯含密载体攻击(SOCA);但若攻击者能够拥有许多成对的原始载体与含密载体,在多次传输的情况下,攻击者便能够获取全部的原始载体与含密载体对,使得保密通信“无密可保”,因此不能抵抗已知载体攻击(KCA).
本文方案解决了传统载体选择多次在信道中传输存在的安全风险,不存在泄露图像库间接泄露秘密信息的情况.在算法以及映射图像库完全公开的情况下,只要保证含密图像与跨域图像之间的跨域关系不被泄露,攻击者即使得到跨域图像也不能推断出跨域图像与含密图像之间的联系,所以能够抵抗唯含密载体攻击(SOCA);即使攻击者能够得到一次消息传递中的所有含密图像与跨域图像对,只需在下次通信时更换跨域关系即可使下次传递的跨域图像不同,此时攻击者已拥有的含密图像与跨域图像对便失效,所以本文方案还能够抵抗已知载体攻击(KCA).
3 结 语
本文提出了一种基于图像翻译的载体选择式图像隐写方案,主要包含两部分:一是通过建立好的映射关系库对秘密信息进行载体选择得到含密载体,二是对含密载体进行跨域变换,生成跨域图像.本文将载体选择方法与载体合成方法结合,通过对载体选择得到的图像进行跨域变换从而改变图像内容,解决了载体选择方法多次在信道传输会泄露图像库的安全风险的问题.实验结果表明,本文提出的方案在容量上比大多数载体选择和部分载体合成方案高,比传统隐写方案在抗检测性和安全性等方面表现更好.
