5种流行假脸视频检测网络性能分析和比较
2019-11-05高逸飞胡永健余泽琼林育仪刘琲贝
高逸飞,胡永健,余泽琼,林育仪,刘琲贝
1.华南理工大学电子与信息学院,广州510641
2.中新国际联合研究院,广州511356
人脸作为身份认证的特征之一,在人类生物识别和交际沟通中起着重要的作用.随着人工智能和机器学习的快速发展,使用深度网络模型替换人脸的Deepfake1https://en.wikipedia.org/wiki/Deepfake假脸视频在社交媒体和互联网中迅速传播.没有编程和图像编辑基础的人也可以用开源软件和应用程序实现换脸,如DeepFaceLab2https://github.com/iperov/DeepFaceLab、Deep-Faceswap3https://github.com/deepfakes/faceswap、Deep-Faceswap-GAN4https://github.com/shaoanlu/faceswap-GAN、myFakeApp5https://bitbucket.org/radeksissues/myfakeapp/src等.不法分子基于假脸视频制造的虚假新闻、恶搞视频、色情视频等严重损害了公众对大众传媒的信任度,扰乱社会治安,破坏国家安全.
换脸视频经历了从单张图像换脸发展到整段视频换脸的过程,从实现技术手段来看,先后引入了图像处理技术、计算机图形学、深度神经网络技术.早期换脸合成主要用专业的图像编辑工具(如Adobe Photoshop)对单张图像进行操作,用户挑选脸部角度相近的照片,手动提取源图像中脸部区域替换到目标图像中[1-3],这一阶段的换脸技术运算较复杂,无法批量合成假脸图像或是直接合成假脸视频.为合成动态假脸视频研究人员引入了计算机图形学方法,其基本原理是对目标脸进行精密三维建模,追踪动作并进行动画处理,使源脸能够精确替换目标脸[4-15].基于计算机图形学的换脸技术主要受限于三维建模步骤的高复杂度,也容易受视频分辨率等因素影响.近年来,深度神经网络的出现不但极大地降低了换脸合成的技术门槛,还显著提高了合成逼真度.最初,深度神经网络主要用于编辑人脸的部分特征.如利用生成式对抗网络(generative adversarial networks,GANs)生成年龄老化后的人脸[16];通过深度卷积神经网络对人脸的姿态、表情、肤色和场景光照等特征进行编码,实现二维图像的三维建模[17];利用卷积网络进行精确的人脸分割[18];用具有时空结构的生成神经网络实现源视频人脸对目标视频人脸的表情和动作操控[19].随着Deepfake(深度假脸工具包)在网络论坛Reddit 上的广泛传播,基于深度学习的换脸技术才真正引起了社会各界的关注.这是因为Deepfake 依靠卷积神经网络、生成式对抗网络和自编码器等深度学习技术可完成对人脸提取、人脸编码解码训练和人脸交换等一系列操作,使用简单且效果逼真,极大推进了换脸合成的技术现状.尽管原始的Deepfake 代码由于被恶意使用而遭到下架封禁,但其技术精髓仍保留在许多开源网站以及应用软件中,如著名的Deep-FaceSwap3和Faceswap-GAN4等.与之前的换脸方法相比,深度网络可以学习到目标视频中更深层次的人脸特征,从而更精准地将目标人脸替换为源视频人脸,同时还能较好地匹配目标视频中人脸的动作及变化,甚至同时实现音频匹配,所生成的合成视频以假乱真,难以辨别.总体而言,换脸视频从引入计算机图形学方法后开始逐步成熟,在引入深度学习方法后实现了飞跃.
假脸视频的迅猛发展对社会的威胁已引起了学术界的广泛关注,国内外研究者们均已开展假脸视频检测的相关研究.目前所提出的检测方法中,既有基于手工提取特征的,也有基于深度学习技术的算法,还有初步构建若干公开数据库[20-22]用于假脸检测研究.总的来看,目前关于假脸检测的研究工作仅处于初级阶段,各种算法通常只对特定的数据库有效,缺乏全面性能评估.尽管文献[22]已注意到这个问题并针对泛化性能进行了跨库测试,但所使用的网络模型主要是用于物体识别的分类器,而不是专门针对假脸检测的分类器.
本文重点关注基于深度学习的假脸检测算法,为了较全面评价各检测算法的性能,对文献中基于MesoInception-4、MISLnet、ShallowNetV1、Inception-v3、Xception 这5 种深度网络的深度假脸检测器[23-27]进行了库内和跨库测试,首先讨论其泛化性能,然后在数据增广、数据库划分、阈值选取上进一步讨论这些因素对算法性能的影响,具体内容包括:1)进行库内和跨库测试,讨论跨库对检测性能的影响;2)分析常用的数据增广方法对假脸视频检测的影响;3)比较数据库划分方法对泛化性能带来的影响;4)比较不同阈值对目标域的适应性.
1 Deepfake 假脸检测网络简介
图1给出了使用3 种经典换脸技术合成的假脸图像示例,分别是基于计算机图形学的Face2Face、Faceswap 以及基于深度学习的Deepfake.检测Deepfake 假脸视频较有效的算法均基于卷积神经网络,本文选取较新且效果较好的5个网络[23-27]进行实验.首先对这5个网络进行简单回顾.
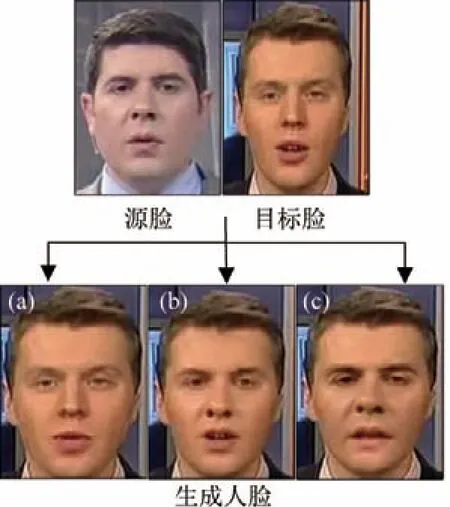
图1 3 种流行的换脸技术合成示例.(a) Face2Face; (b) Faceswap; (c) DeepfakeFigure1 Examples of three popular fake face composition methods.(a) Face2Face; (b)Faceswap; (c) Deepfake
1.1 MesoNet
文献[23]指出视频压缩使噪声衰减,因此难以通过单独分析噪声来检测伪造人脸的痕迹.文献[23]提出了2个浅层面部视频伪造检测网络:Meso-4 和MesoInception-4.Meso-4 由连续的4 层卷积层和2 层全连接层构成,但仅使用4 层卷积层提取的特征不足以较好地完成真假脸分类的任务.因此,MesoInception-4 在Meso-4 的基础上将前2 层普通卷积替换为改进的Inception 模块[28].与原始的Inception 模块相比,改进主要体现在两个方面:一是使用3×3的扩展卷积代替5×5 的普通卷积,避免提取到高语义的特征;二是在扩展卷积前使用1×1的卷积层减少参数,降低计算量.具体网络细节如图2所示.
1.2 MISLnet
文献[24]认为诸如AlexNet 的经典卷积神经网络从训练数据上学习到的特征是表征图像内容而非篡改检测所需要的篡改痕迹,因此为了更好地学习篡改检测特征并削弱内容信息,文献[24]定义了一种新的卷积层,称为受约束卷积层(constrained convolutional layer),如图3(a)所示.为了对预测误差进行提取,受约束卷积层位于MISLnet 网络的第1 层作为第1 部分;由于这些特征比较容易受到非线性运算比如池化和激活函数的破坏,第2 部分使用3 层普通卷积继续进行分层特征提取,并且每层卷积之间含有批归一化层和最大池化层;第3 部分采用1×1 的卷积层进行跨特征学习;网络的最后部分是平均池化层和3个全连接层构成的分类器.网络结构图如图3(b)所示.

图2 MoseNet 网络结构流程图Figure2 Network structure of MoseNet
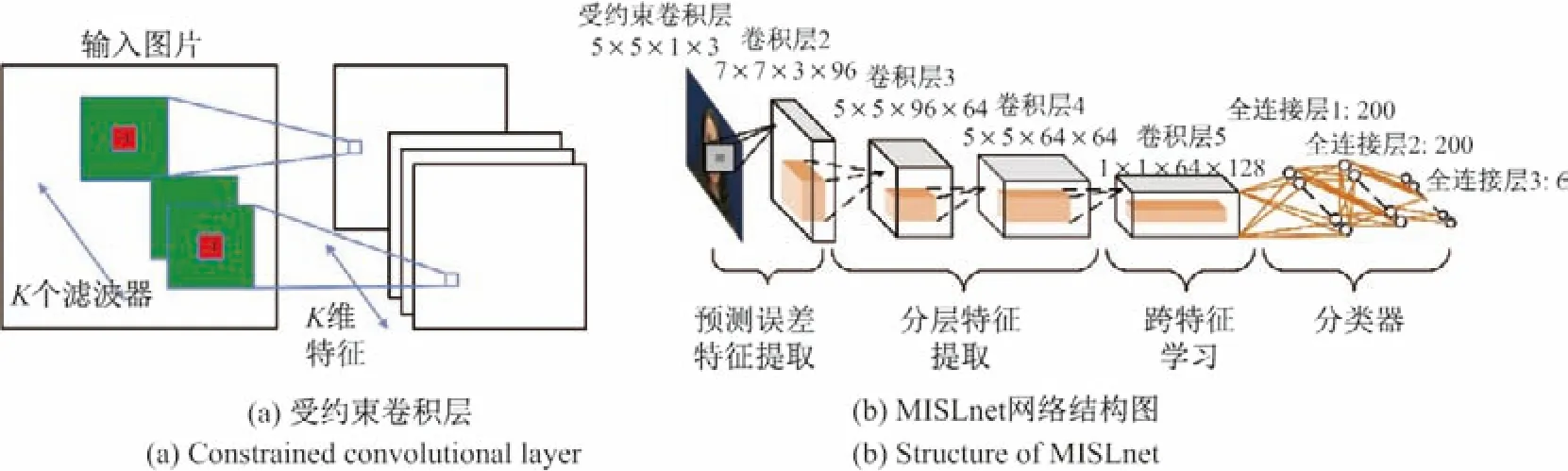
图3 MISLnet 网络结构图Figure3 Network structure of MISLnet
1.3 ShallowNet
文献[25]提出了一个无需人为干预和图像元数据的端到端网络,适用于检测GANs 生成的和Photoshop 等图像编辑工具手工篡改的两种假脸图片.不同于当前主流的深度复杂网络,文献[25]提出了ShallowNetV1,V2,V3 这3个版本的轻量级网络,网络的具体结构见表1.ShallowNetV1 主要由卷积层、最大池化层、全连接层等组成的7个自定义模块构成.为了防止过拟合,每个卷积层采用了L2 正则化.V1 版本在小图片比如64×64 的分辨率检测上表现不佳.V2、V3 版本结构和深度相似,不同之处在于V3 上的最大池化使其在低分辨的图像上有更好的表现.

表1 ShallowNet V1~V3 版本网络结构Table1 Network structure of ShallowNet V1~V3
1.4 Inception-v3
Inception 模块[28]中首先对输入分别进行4 种不同大小的卷积和池化操作,再将各路输出拼接成为一个特征维度.这种设计有助于解决网络层数过深带来过拟合、计算复杂度增大、梯度消失等问题.尽管大尺寸滤波器的卷积能够学到更多的信息,但计算量随之增大.因此,Inception-v3[26]做了两方面改进,一是提出了非对称卷积,即将大尺寸滤波器卷积用小尺寸滤波器的级联来代替,这样能在保证学习信息不减少的情况下大大降低计算量;二是引入了具有正则化作用的辅助分类器,加快网络收敛的同时提高主分类器的准确率.若将检测假脸视频当成一个真假脸分类任务,则将Inception-v3 这样一个公认表现优秀的深度分类网络用于检测是一种较好的方法.Inception-v3 网络结构及参数见表2,其中的Inception 模块结构图如图4所示.

表2 Inception-v3 网络结构Table2 Network structure of Inception-v3
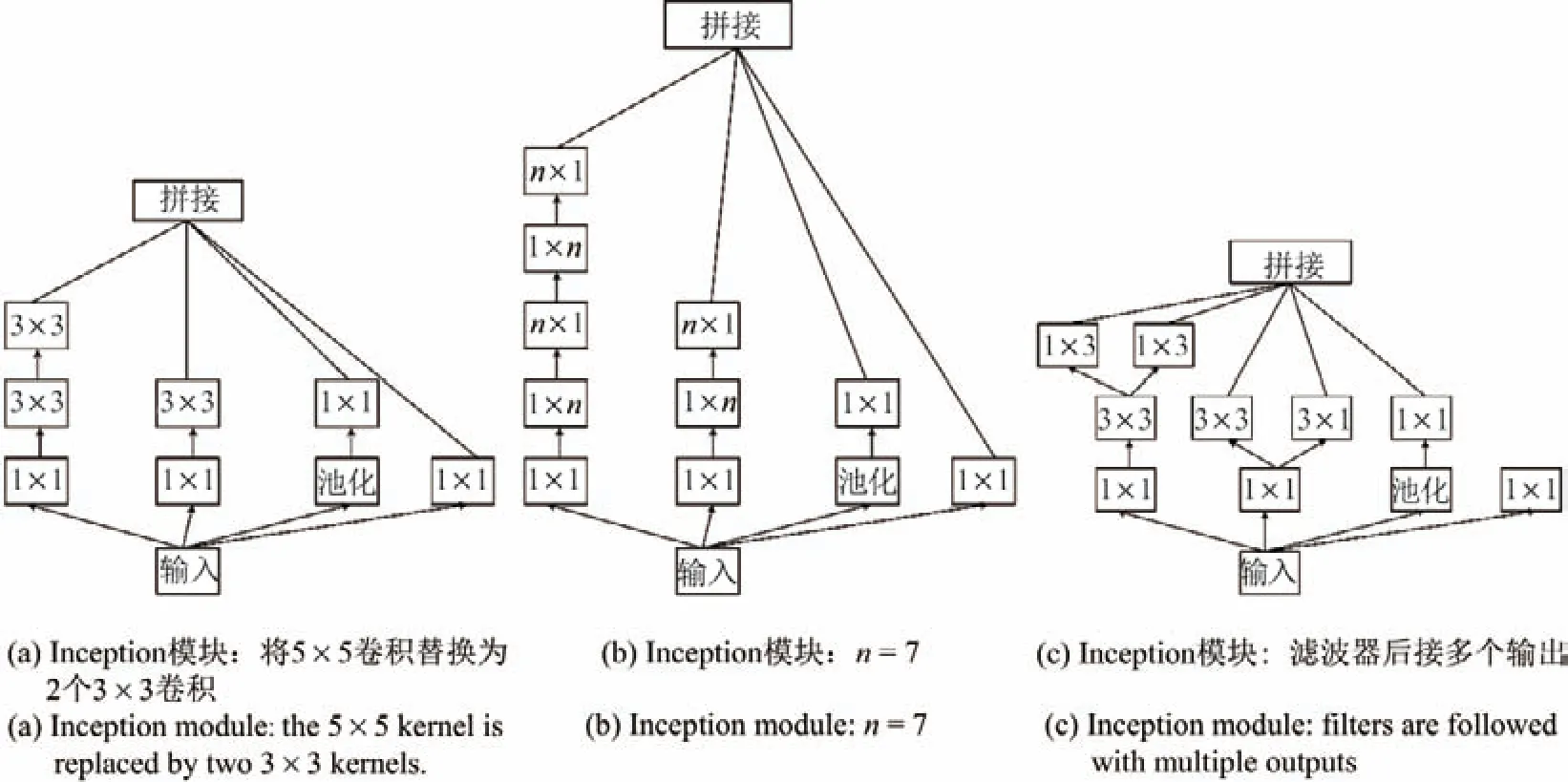
图4 Inception-v3 中的3 种Inception 模块Figure4 Three Inception modules in Inception-v3
1.5 Xception
文献[27]在Inception-v3 的基础上进一步改进,旨在缓解随着网络的加深导致参数过多的问题.该文提出了Bottleneck 的结构,即先利用卷积对数据进行降维,再经过维数较低的卷积,最后通过1×1 卷积升维,这种结构与普通卷积相比大大降低了参数量.同时,文献[27]认为特征通道之间的相关性和特征图上的空间相关性是可以完全解耦的,从而提出了深度可分离卷积,即先在每个特征图上进行空间卷积,再对每个特征点用1×1 卷积来学习不同通道的特征.这种设计在提高网络性能的同时减小网络计算的复杂度,文献[20,22,25]同样用Xception 进行了实验,并且验证了深度可分离卷积在Deepfake 假脸上的有效性.网络结构图如图5所示.
2 Deepfake 数据库简介
目前公开的Deepfake 数据库主要有3个:TIMIT 数据库[21]、FaceForensics++ 数据库[20]、Fake Face in the Wild(FFW)数据库[22].为了进行合理的跨库测试,本节对这3 种数据库进行简要介绍及比较.
2.1 TIMIT 数据库
该数据库由真实视频和篡改视频两部分构成,一是澳大利亚昆士兰大学(UQ)构建的VidTIMIT 音频视频数据库[29].二是瑞士Idiap 研究所基于VidTIMIT 数据库构建的DeepfakeTIMIT 数据库[21].VidTIMIT 数据库包含43个对象,每个对象拍摄了13 段真实视频,DeepfakeTIMIT 数据库从VidTIMIT 数据库中选取了16 对肤色和光照差异相近的对象,使用开源的Deep-Faceswap-GAN4方法实现人脸互换.对于每一对视频,分别使用不同的训练模型和融合技术生成低质量(LQ)和高质量(HQ)的两种视频(如图6).其中,LQ 模型的输入/输出图像(仅面部区域)尺寸为64×64,而HQ 模型的输入/输出图像尺寸为128×128.
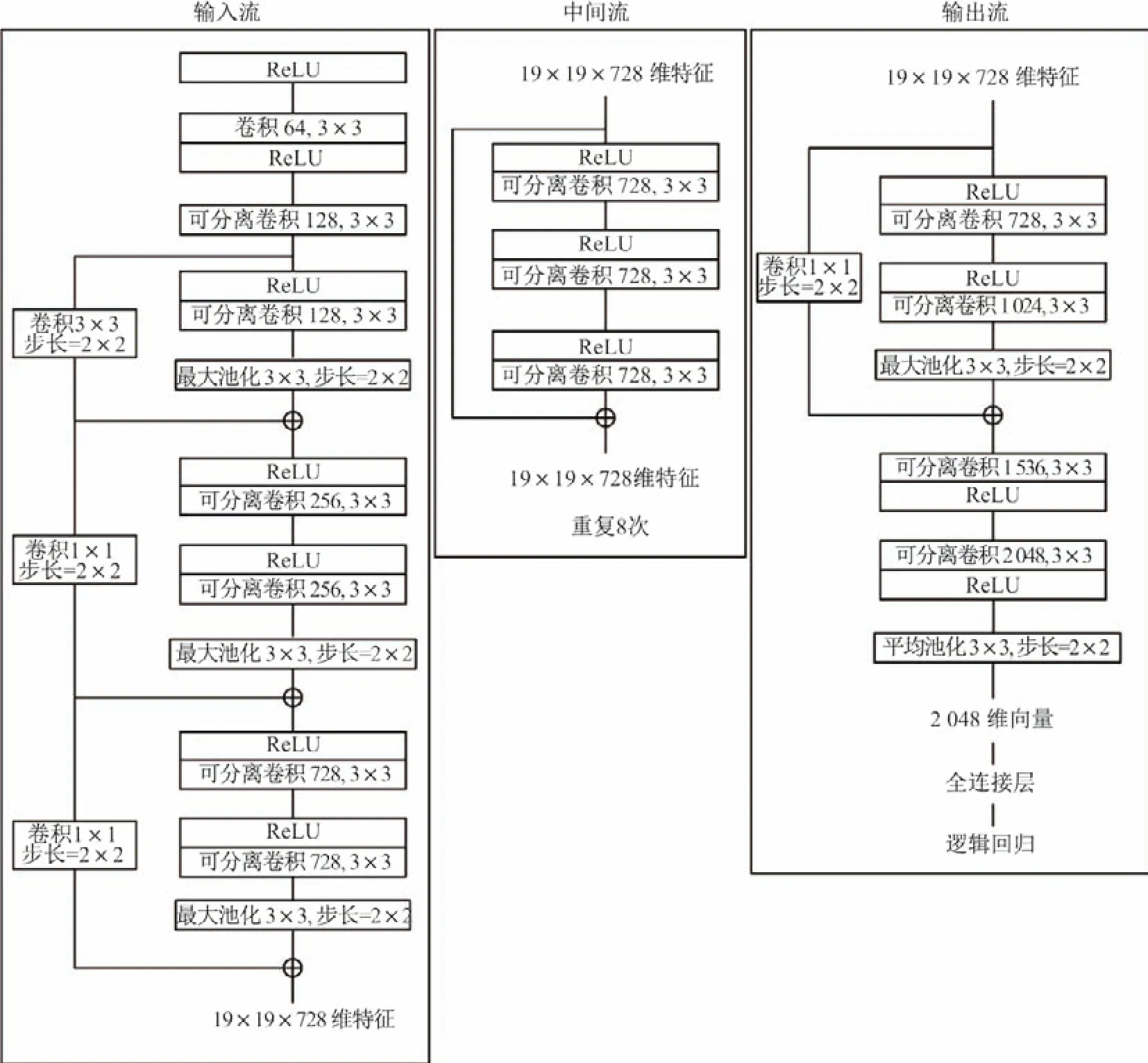
图5 Xception 网络结构图Figure5 Network structure of Xception
2.2 FaceForensics++数据库
FaceForensics ++[20]是德国慕尼黑工业大学(TUM)视觉计算组构建的一个大型换脸数据库,其中包括从视频网站YouTube 上收集的1 000个真实视频,以及使用Face2Face、Faceswap 和Deepfake 篡改方法合成的3 000个篡改视频.其中,Deepfake 假脸视频是基于自编码器模型的Deep-Faceswap3方法实现的,并使用H.264 编解码器分别合成压缩率0(C0)、压缩率23(C23)和压缩率40(C40)3 种不同压缩程度的视频,即无压缩假脸视频、高质量(HQ)假脸视频和低质量(LQ)假脸视频,如图7所示.值得注意的是,FaceForensics++数据库根据视频的压缩程度定义HQ 和LQ 假脸视频,而DeepfakeTIMIT 数据库根据训练模型的输入/输出图像大小定义HQ 和LQ 假脸视频.
2.3 FFW 数据库
FFW(fake faces in the wild)数据库[22]由挪威科技大学生物识别实验室从视频网站YouTube 上收集的假脸视频构成,涉及的篡改技术有计算机图形学技术(computer graphics interface,CGI)、脸部替换、脸部拼接、FakeAPP 等.其中,Deepfake 假脸视频利用了基于深度学习的FakeAPP 换脸技术(如图8所示),该技术最近已被禁用.FFW 数据集提供了来自YouTube 的50个Deepfake 假脸视频ID,现只有46个视频有效可用.

图6 TIMIT 数据库示例Figure6 Examples from TIMIT dataset

图7 FaceForensics ++数据库示例Figure7 Examples from FaceForensics ++ dataset

图8 FFW 数据库示例Figure8 Examples from FFW dataset
2.4 数据库比较
观察发现,3个数据库中的Deepfake 假脸视频大部分是正脸,面部遮挡等复杂情况较少.其中FFW 数据库合成质量最高,FaceForensics++数据库合成质量最低,但均存在少数假脸轮廓明显、五官模糊等合成效果不好的篡改视频,主要是因为篡改区域与其周围区域之间的分辨率不一致造成的.表3对比了上述3个Deepfake 假脸视频数据库.
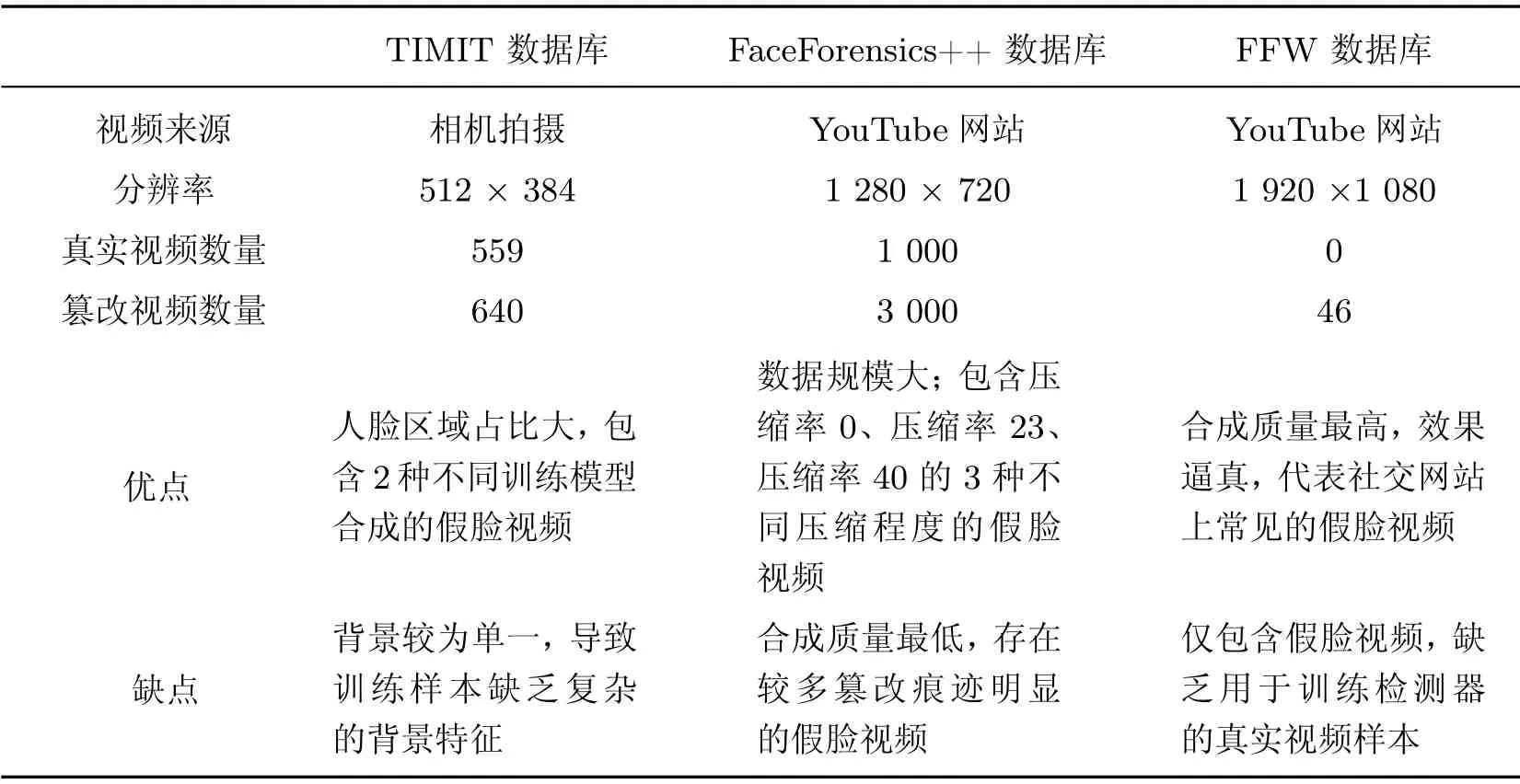
表3 Deepfake 数据库的比较Table3 Comparison of different Deepfake datasets
3 实验结果及分析
为了对5 种Deepfake 假脸视频检测的网络进行性能分析和比较,本文着重在数据处理、数据库处理、阈值选取这3个方面进行对比实验.实验环境为配有Intel(R) Xeon(R) E5-2686 v3 @ 2.00Ghz 和GTXTITANX、GTX 1080Ti 的Ubuntu16.04 服务器,程序代码用Keras 框架编写.
在经典机器学习问题中,训练集所在的域被称为源域(source domain),测试集所在的域被称为目标域(target domain),两者之间的差异被称为域偏移(domain shift).为了评估模型在不同域偏移下的性能,实验主要进行了库内测试和跨库测试.由于同一个库内的视频数据所在场景和生成方式相近,即库内测试中目标域与源域偏移较小,用于评价模型的学习效果;而不同库的视频数据相差较大,即跨库测试中目标域与源域偏移较大,用于评价模型的泛化性能.因为FFW 库和FaceForensics++库中的真实视频有部分相同,为了保证实验严谨性,本文不用FaceForensics++库训练出来的模型对FFW库进行跨库测试.
本文使用准确率(accuracy,ACC)和错误率来评价算法的性能.库内测试用准确率和错误率评价,跨库测试仅用错误率评价.错误率包括两个部分:一是在验证集上漏检率和虚警率相等时的阈值计算得到的等错误率(equal error rate,EER);二是在测试集上使用之前的阈值所得到的平均错误率(half total error rate,HTER).等错误率和平均错误率公式如下:
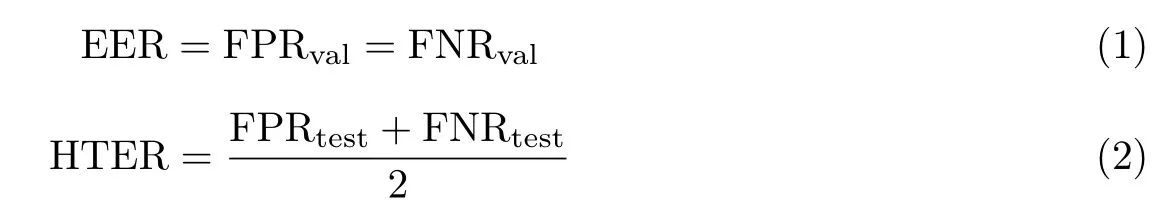
式中,FPR 为虚警率,FNR 为漏检率,val 表示在验证集上结果,test 表示在验证集上结果.
3.1 实现细节
为了客观地比较5个检测网络的性能,在实验过程中训练和测试环境都保证一致性.对于网络的输入,首先使用dlib 库中的卷积神经网络检测器以及预训练权重对人脸区域进行框选,然后根据FAN-2D 网络[30]检测出的鼻尖点坐标,再对人脸框进行水平平移,保证鼻尖点在人脸框的中垂线上.为了让模型能够学习人脸及周围环境的信息,以人脸框为中心向外扩张1.3 倍的区域作为输入图片.为了预防梯度爆炸等问题,输入数据都进行了归一化,其中MesoInception-4、MISLnet、ShallowNetV1、Inception-v3 的范围为0~1,Xception 的范围为-1~1.
为了让各模型的训练保持一致,5个检测网络的损失函数均采用了分类问题中常用的交叉熵.文献[23]采用的损失函数是均方误差(mean square error,MSE).本文优化过程中采用了自适应Adam算法[31]并使用提前终止的策略以预防过拟合.整个训练过程分成2个阶段,第1个阶段学习速率为1e-4,若6 次迭代验证集的损失都未下降则进入第2 阶段;第2个阶段学习速率为1e-6,若15 次迭代验证集的损失均未下降则结束训练.优化器的其他参数均默认为缺省值.
在模型的结构上,MesoInception-4,Inception-v3 和Xception 直接调用文献[23,26-27]提供的模型代码,MISLnet 和ShallowNetV1 则是根据文献[24-25]给出的结构复现.
3.2 场景设置
为了有效训练和测试网络,本文在数据和数据库的形式上给出了不同场景进行对比实验.数据的处理包括是否进行数据增广,数据库的处理包括不同的划分方式.除此以外,还讨论了不同阈值对结果的影响.
3.2.1 数据处理
数据增广旨在通过计算机手段对训练样本进行扩充来增强数据的多样性,从而使模型能适应广泛的应用环境,在目标识别、目标检测等问题中有广泛应用.常见的数据扩增方式包括拉伸、旋转、翻转等.文献[23]所采用的5 种数据增广方式如表4所示,本文采用相同的方式进行测试.

表4 数据增广方式Table4 Data augmentation approaches
3.2.2 数据库处理
若使用重复的数据对模型进行训练、验证、测试会导致模型在源域数据上产生严重的过拟合现象,因此根据经验,本文将TIMIT 库和FaceForensics++库按约7:2:1 的比例划分为训练集、验证集、测试集.数据库划分主要有两种形式:一是随机划分,即直接以视频为单位,按照规定的比例分成3个数据集,划分后的数据库如表5和6 所示;二是按人划分,即在控制比例的基础上考虑到视频里的人,保证同一个人的视频只出现在一个数据集中,划分的数据库如表7和8 所示.
由于FFW 库只有假视频,视频数量少但质量高,所以本文仅用这个库做跨库测试.为了保证正负样本的平衡,本文从FaceForensics++ 库分出的测试集中选出50个真脸视频对FFW数据库进行了补充,如表9所示.
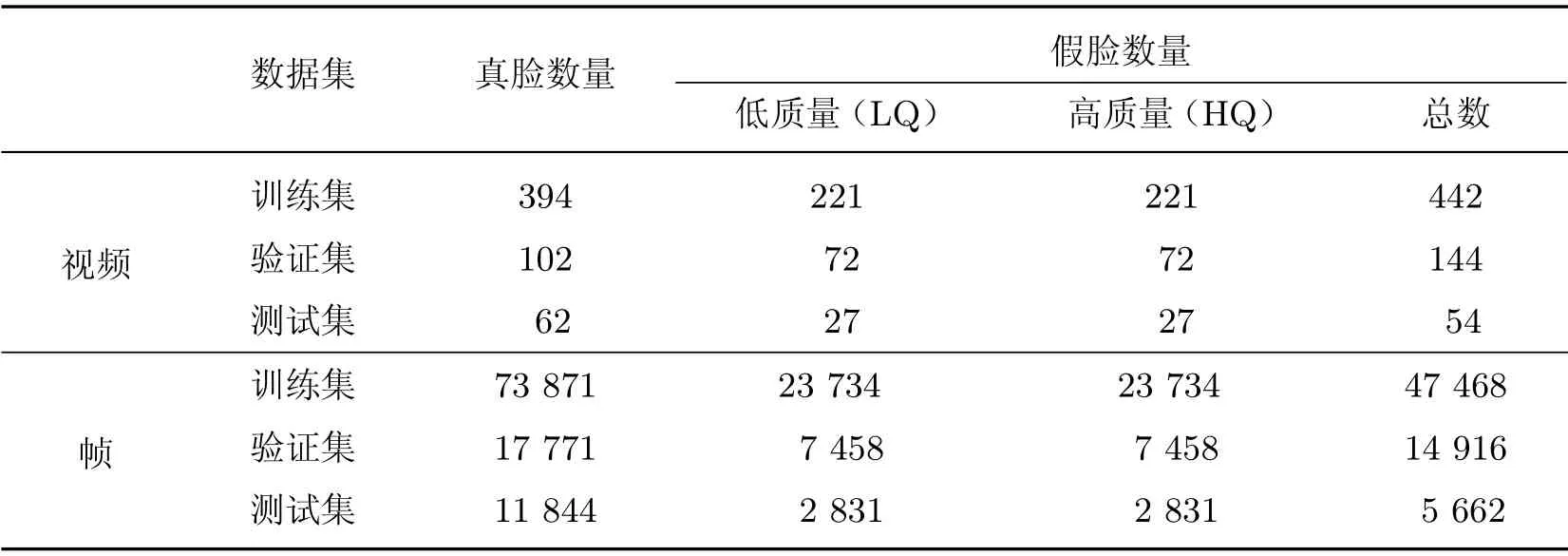
表5 TIMIT 数据库的随机划分方式Table5 Random partition of the TIMIT dataset
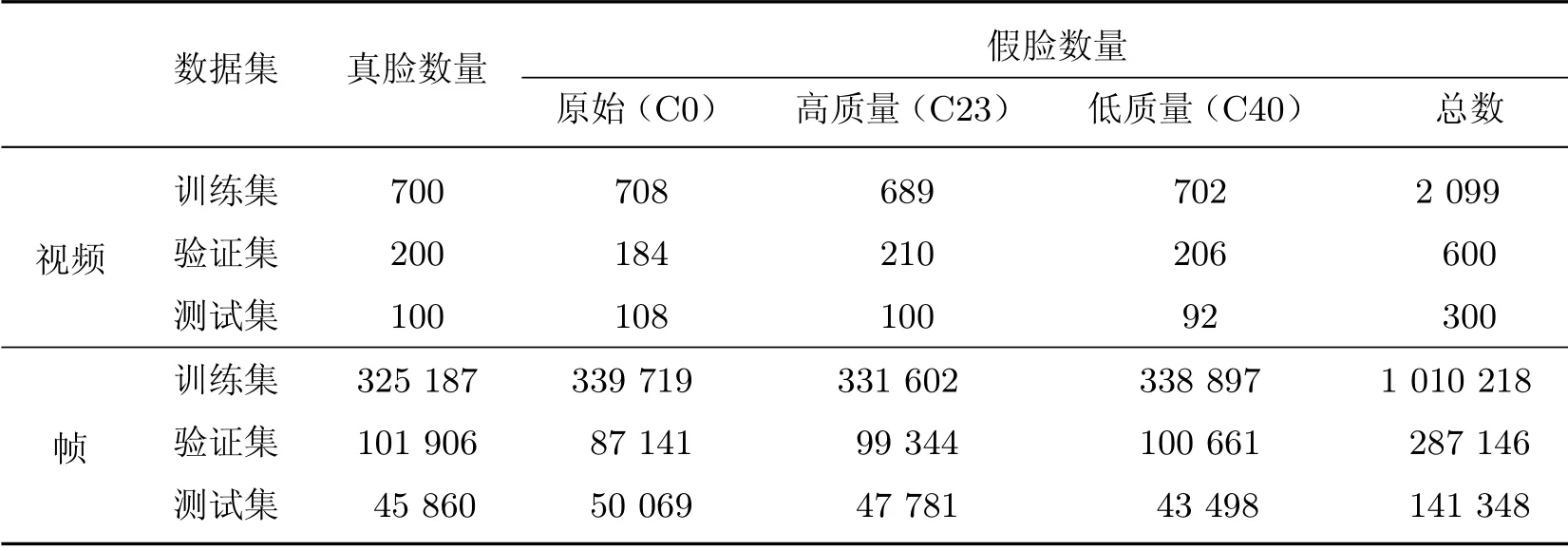
表6 FaceForensics++数据库的随机划分方式Table6 Random partition of the FaceForensics++ dataset
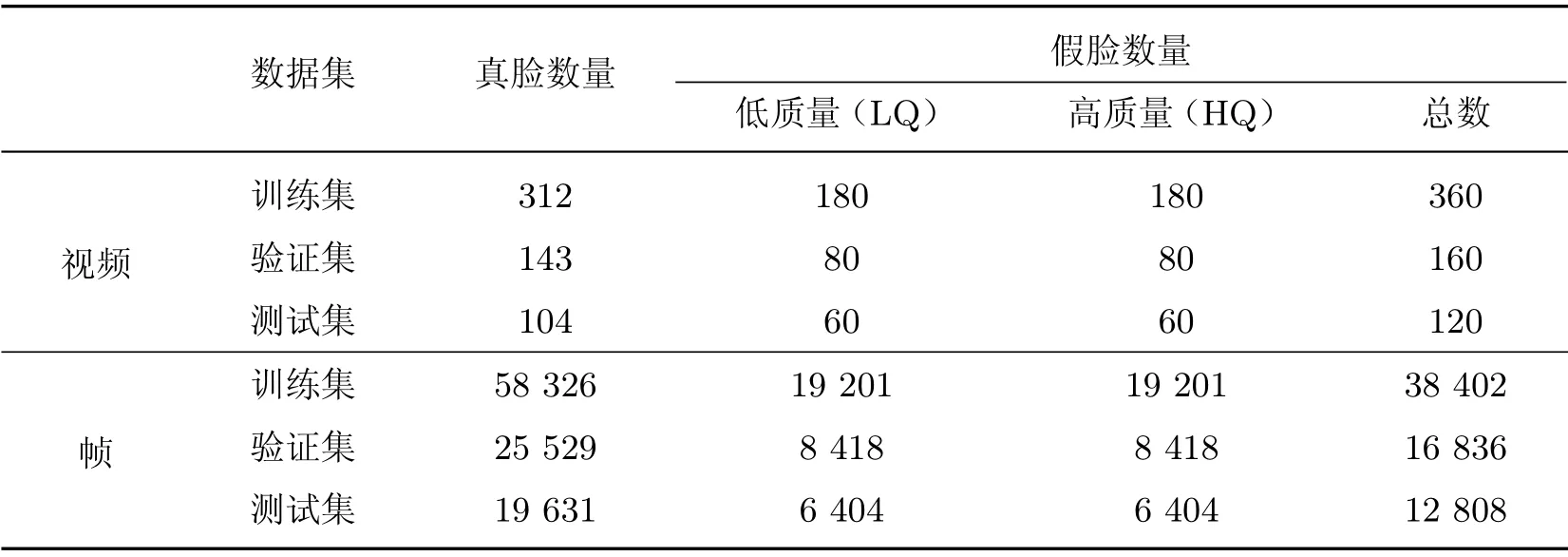
表7 TIMIT 数据库的按人划分方式Table7 Person-based partition of the TIMIT dataset

表8 FaceForensics++数据库的按人划分方式Table8 Person-based partition of the FaceForensics++ dataset

表9 补充真实视频后的FFW 数据库Table9 Composition of FFW dataset after real videos are added
3.2.3 阈值的选取
对于二分类问题,不同阈值直接影响测试的分类结果,从而造成不同的虚警和漏检.因此,在库内和跨库测试中,本文首先使用与训练集所属同一个库的验证集即域偏移较小的数据在EER 准则下确定阈值.这是因为在实际应用中难以得知测试视频的场景,只能借助已有视频来确定阈值.除了这种阈值选取方式,本文尝试了其他选取方式对比.在库内测试中增加Softmax 分类准则,即以0.5 为阈值.在跨库测试中,一是增加了Softmax 分类准则的阈值,二是使用与测试数据所属同一个库的验证集即域偏移较大的数据在EER 准则下确定的阈值.
3.3 性能结果分析
3.3.1 基准条件
根据文献[23]本文确定如下基准条件:在数据处理上采用数据增广,在数据库处理上进行随机划分,在阈值选取上使用域偏移较小的数据,在EER 准则下确定的阈值.得到的实验结果如表10 和11 所示.
根据实验结果,可以得到观察和结论如下:
1)在库内测试上均有较好的结果,TIMIT 库准确率超过97.8%,FaceForensics++库也超过90.5%.其中Xception 表现最好,准确率接近100%;MesoInception-4 和Inception-v3 的表现相对较差,说明了Inception 模块提取的特征没有Xception 模块提取的特征好.

表10 TIMIT 库训练模型的测试结果Table10 Experimental results based on training on TIMIT dataset %

表11 FaceForensics++库训练模型的测试结果Table11 Experimental results based on training on FaceForensics++ dataset %
2)与库内测试结果相比,跨库结果均不理想,HTER 最低也超过30%,说明这些模型很难识别出域偏移较大的视频.5 种网络中MISLnet 的表现较为稳健,可能是因为MISLnet 中的第1 层即限定层抑制了图像内容信息,提取到一部分高频上的篡改特征.
3)综合库内和跨库测试,MISLnet 都展现出相对较好的性能.
综上,在库内测试中,由于域偏移较小,5 种模型均具有较好的学习能力,正确检测的能力较强.在跨库测试中,由于域偏移较大,即不同的数据库目标大小、背景复杂度、分辨率大小以及合成假脸质量有差异,使数据分布的差异较大,从而导致模型无法正确做出判断,检测结果不佳.
3.3.2 数据增广
本节从基准条件出发,讨论不同的数据处理方式对假脸检测的影响.具体讨论数据增广对测试结果的影响.
表12~14 所示的HTER 结果表明,数据增广没有像一般意义上的提高检测器泛化性能,而是导致平均误差没有一致性.具体地,对于库内测试,5个检测网络的准确率波动约在1%以内;对于跨库测试,HTER 的变化范围大部分在-5%~5%之间.以MISLnet 为例,用TIMIT 库训练的模型在测试FaceForensics++库时,与不加数据增广相比HTER 降低了约5%,而在测试FFW数据库时却提高了0.4%.一种合理的解释是,数据增广会改变像素值,容易破坏浅层的高频信息,因此,在假脸检测中会对提取基本的篡改特征产生一定的干扰.换句话说,假脸检测中使用数据增广不能提高模型的泛化性能,因此是不必要的.

表12 对比是否有数据增广的TIMIT 库内测试结果Table12 Intra-dataset test results on TIMIT dataset with/without data augmentation %
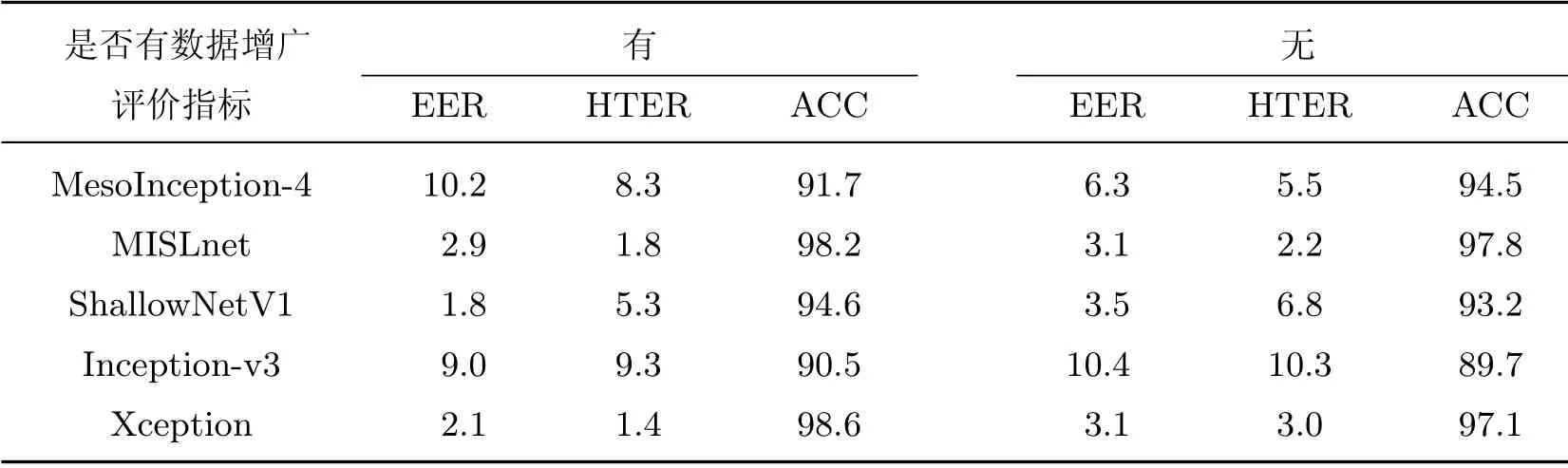
表13 对比是否有数据增广的FaceForensics++库内测试结果Table13 Intra-dataset test results on FaceForensics++ dataset with/without data augmentation %
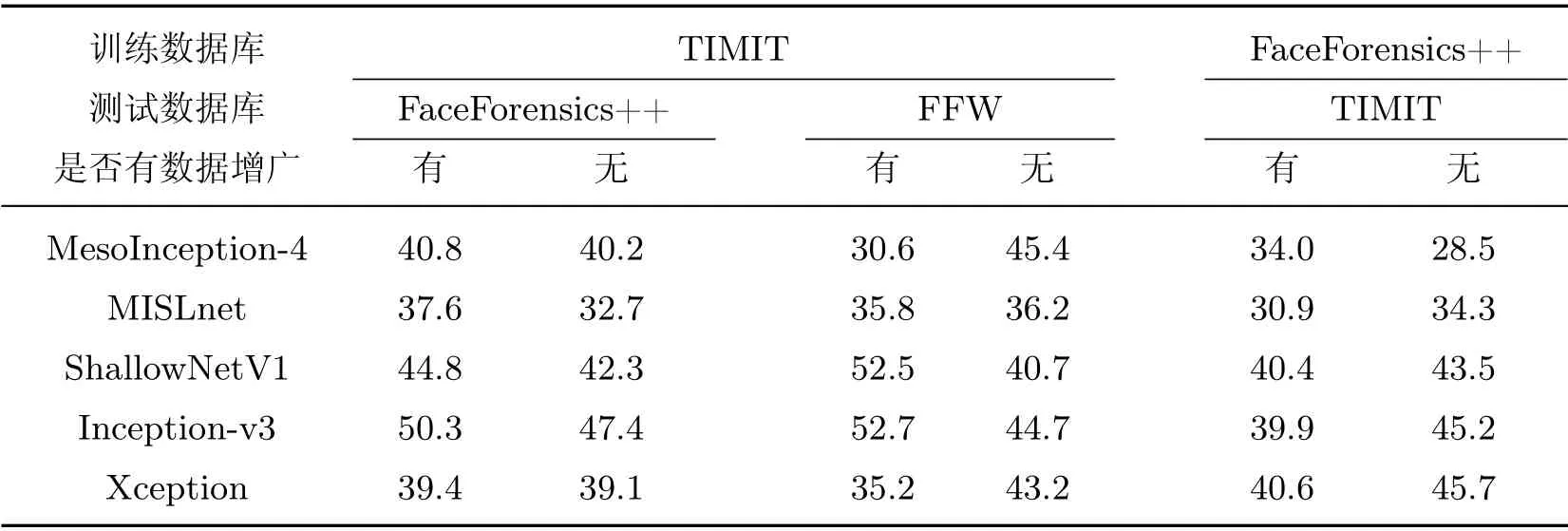
表14 对比是否有数据增广的跨库测试结果(HTER)Table14 Cross-dataset test results(HTER)with/without data augmentation %
3.3.3 数据库划分
本节讨论不同数据库划分对假脸视频检测的影响.根据上节对实验结果的分析,本节不使用数据增广进行训练和测试所得到的结果如表15~17 所示.实验结果显示如下:
1)对于TIMIT 库的库内测试,在按人划分的数据库划分准则下,所有检测器的准确率均有一定的下降.同时等错误率和平均错误率均增加.

表15 不同划分下的TIMIT 库库内测试结果Table15 Intra-dataset test results on TIMIT dataset using different data partition methods%

表16 不同划分下的FaceForensics++库库内测试结果Table16 Intra-dataset test results on FaceForensics++ dataset using different data partition methods %

表17 不同划分下的跨库测试结果(HTER)Table17 Cross-dataset test results(HTER)using different data partition methods %
2)对于FaceForensics++库的库内测试,难以确定两种划分方式对检测器性能的影响,准确率、等错误率、平均错误率的变化方向没有一致性.
3)对于跨库测试,除了FFW 库,按人划分的数据库的平均错误率明显低于随机划分.对于FFW 库,平均错误率在两种划分的情况下有高有低.
上述结果表明,不同的划分方式对库内和跨库测试都会造成一定影响.仔细观察和分析还可以发现,数据库大小对测试结果也有一定的影响.对于TIMIT 这种规模较小的数据库,随机划分容易使模型学习人脸对象本身的特征而非换脸的篡改特征,因此库内测试HTER 低而跨库测试HTER 高.对于FaceForensics++这种规模较大的数据库,随机划分较少出现库内测试的HTER 明显低于按人划分的情况,甚至在ShallowNetV1 上按人划分的HTER 还会有所降低.对于跨库测试,则与TIMIT 库的情况一致,即随机划分的HTER 高一些.这是因为FaceForensics++库规模较大且数据多样,提高了模型的泛化能力.
综上,对于假脸视频检测,由于目前大规模的数据库较少,数据总量和多样性不足,随机划分可能导致模型学习更倾向于源域人脸对象的特征,不能较好地泛化到目标域上,因此数据库应采用按人划分的方式.
3.3.4 阈值的选取
本节讨论不同的阈值选取对测试结果的影响.以TIMIT 库的训练模型为例进行测试并且根据之前的讨论结果,不使用数据增广且数据库为按人划分方式,实验结果如图9所示,可以发现:

图9 TIMIT 库训练模型在不同阈值下的测试结果,其中纵坐标Y表示评价指标,横坐标X表示具体阈值和表示模型Figure9 Intra-dataset test results on TIMIT under different threshold values.Y-axis indicates evaluation measurement,X-axis indicates the threshold values and models
1)在库内测试中(见图9(a)),以Softmax 准则下的阈值(0.5)所得到的准确率比EER准则下阈值所得到的准确率有所降低,其中MesoInception-4 的降低最多,约为6%.但对于之前分析中性能较好的MISLnet,两个准确率差异很小.
2)在FaceForensics++库的跨库测试中(见图9(b)),以Softmax 准则下的阈值(0.5)所得到的HTER 比EER 准则下阈值所得到的HTER 高,最大的差异超过10%;而利用域偏移较大数据确定的阈值比域偏移较小数据确定的阈值效果好一些,除Inception-v3 外,HTER均有一定程度的下降.
3)在FFW 库的跨库测试中(见图9(c)),不同域确定的两种阈值对每个检测器的影响不同,对于MesoInception-4、MISLnet 以及Xception,利用域偏移较大数据确定的阈值比域偏移较小数据确定的阈值效果好一些,而对于ShallowNetV1 和Inception-v3,情况正好相反.此外,ShallowNetV1 在EER 准则下计算出的阈值偏向于0.5,而其他检测器在EER 准则下计算出的阈值都接近于1,这说明不同的检测器对合成质量不同的检测对象有不同的检测灵敏度.
需要说明的是,在实际应用中难以得到与目标域相近的数据来计算EER 下的阈值.本节通过比较在域偏移不同数据所得到的阈值来评估一个模型的泛化能力.
4 结 论
随着深度学习技术的飞速发展,合成得到的深度假脸越来越逼真.为了辨别和对抗这种假脸生成技术,研究人员提出使用CNN 分类器来进行检测,已获得一定的成果.本文复现了MesoInception-4、MISLnet、ShallowNetV1、Inception-v3 和Xception 这5个模型的检测效果,在TIMIT、FaceForensics++、FFW 数据库上进行了库内测试和跨库测试.实验表明,这些模型都能较好地检测出域偏移较小(即库内)的视频,但在域偏移较大(即库外)的视频上表现较差.对此,本文讨论了一些可能影响泛化能力的因素.从对比实验中得到结论如下:1)数据库的划分方式对检测器的性能有直接影响,为了提高泛化性能,数据库应该按人进行划分;2)在一般意义下能提高检测器泛化性能的数据增广技术在深度假脸视频的检测中效果并不明显;3)跨库测试必须考虑源域数据与目标域数据的分布,直接使用源域数据所确定的阈值在目标域中通常会导致较高的错误率.
由于深度网络是数据驱动的,因此假脸视频的来源、目标大小、合成方式、合成质量给基于深度网络的假脸检测器的设计带来巨大的挑战.研究网络检测模型的泛化能力是一个广泛而复杂的问题,该研究对于假脸检测器的实际应用有着巨大的理论和实际意义.
