一种基于DPI和负载随机性的加密流量识别方法
2019-11-05孙中军翟江涛戴跃伟
孙中军,翟江涛,戴跃伟
1.江苏科技大学电子信息学院,江苏镇江212003
2.南京信息工程大学计算机与软件学院,南京210044
随着网络技术的快速发展,网络安全问题越来越受到人们的关注,加密流量及与其相关的识别技术受到研究者的青睐.现有以僵尸网络、高级持续性威胁(advanced persistent threat,APT)[1]、木马等为主要形式的网络攻击通常采用相关隐匿技术绕过安全设备入侵系统.加密流量隐蔽性的特点使其成为网络攻击的载体,如果不能有效检测异常入侵,就会时刻威胁网络空间安全[2],因此对加密流量的识别已经成为防御网络攻击的重点.
目前,加密流量的识别方法主要分为6 类:基于有效负载特征字段匹配的识别方法、基于机器学习的方法、基于主机行为的识别方法、基于数据分组分布的方法、基于负载随机性的方法、多种策略结合的方法[3].文献[4]提出了一种基于特征字段匹配的识别模型,该方法通过对数据包网络协议特征的匹配,能有效地识别各类流量,但其最大缺陷是无法识别协议交互阶段的加密数据和私有协议.文献[5]提取国际公开数据集网络流的静态特征,通过机器学习算法训练决策取得了较好的识别效果.文献[6]提出了一种基于加权累积和检验的时延自适应加密流量盲识别算法,利用加密数据随机性的特点,实现对加密流量的有效识别.文献[7]利用SSL/TLS 协议会话证书包的长度和第1个应用程序数据的大小,提出一种基于二阶马尔科夫链模型(second-order Markov chains,SOM),实验表明该方法能有效区别加密流量.然而,上述方法都没有考虑到私有协议和未加密压缩流量给识别加密流量带来的问题,导致将压缩流量误判为加密流量,针对私有协议的识别效果也不佳.网络中存在着大量的压缩流量,这将大大降低算法的识别效果,同时因为私有协议没有国际标准协议的规范而容易成为网络攻击载体,所以现有的模型难以有效判断是否为加密流量.本文在现有研究的基础上,提出一种基于深度包检测技术(deep packet inspection,DPI)和负载随机性检测结合识别的方法,实验表明该方法不仅克服了DPI 无法识别协议交互阶段加密数据和私有协议的缺陷,同时解决了用信息熵识别加密流量和非加密压缩流量误判的问题,表明了识别模型具有良好的实验效果.
1 相关工作
1.1 网络流量负载随机性分析
在网络流量传输中,传输的内容均以字符出现,因此每个数据包的内容荷载都可以看作256个ASCII 组成的字符合集.网络会话出现的字符一般是有统计规律可寻的,即常见字符出现的频率高,不常见字符则出现的频率低.比如在网络流量包中出现大小写26个英文字母和阿拉伯数字频率很高,但在对流量进行加密之后,流量包的字符就会乱码,各种字符出现的频率接近平等[8],因此从数据包字符出现频率的角度度量可以有效地进行流量识别.
1.2 DPI 识别技术
DPI 采用匹配特征字段对网络流量进行识别[9].如图1所示,DPI 提取每个样本数据包包头的网络协议特征字段与DPI 指纹库数据进行特征匹配,从而确定每个应用程序类型[10-11].DPI 可快速准确地识别指纹库存在的流量,但也存在致命的缺陷:DPI 识别依赖于应用协议特征字段而无法识别协议交互阶段的加密数据和私有协议[12],该检测方法越来越无法满足实际需求.本文用DPI 技术快速筛选识别网络流量,发挥了DPI 识别速度快的优点,对识别模型预处理过程有较大的作用.
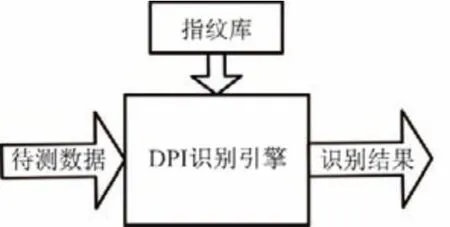
图1 DPI识别过程Figure1 Process of DPI identification
1.3 信息熵
熵由信息论之父Shannon C E 提出,其定义如下:对于一个有N个可能事件A1,A2,··· ,An,其发生的概率为P1,P2,··· ,Pn,则熵的定义为

熵反映了能量的均匀分布程度,熵值越大表示能量越均匀离散,熵的计算有香农熵和Tasllis熵两种方法[13].由1.1 节负载随机性的分析可知,加密流量和未加密流量的负载熵值存在差异.一般来说,对流量的加密导致负载字符乱码而使其熵值增大,但也存在其他情况.如图2所示,明文流量和加密流量的熵值存在差异,但未加密压缩流量和加密流量负载字符熵值相近,仅用熵值的传统加密流量识别模型存在很大的局限性.
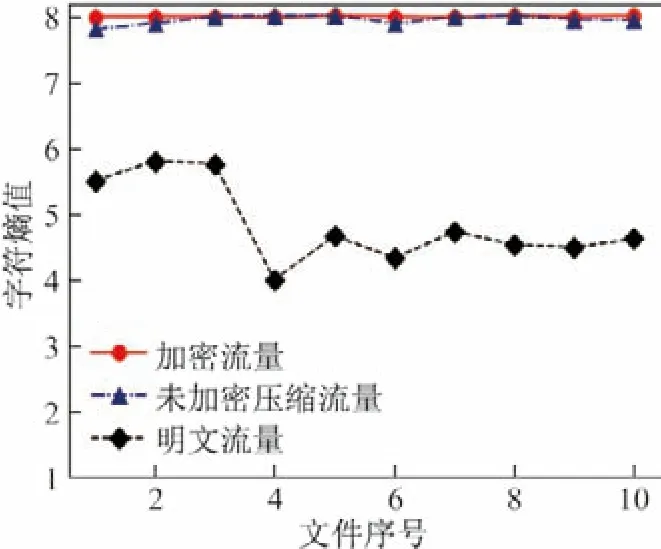
图2 不同流量类别的字符熵值Figure2 Character entropy values for different traffic classes
1.4 蒙特卡罗仿真
分析压缩技术原理可知,对于数据的长字符,若以短字符来代替并去除冗余的字符,就可以最大程度地节省空间,图片的实质也是一种压缩格式.压缩流量会呈现字符的局部随机性,从而使压缩后的网络流量从整体上来看体现出一种伪随机性,而不是加密流量后的整体随机性[14].提取数据包有效荷载的每N个字符作为一组蒙特卡罗仿真点,其思想是在1个正方形内有1个内切圆,前N/2个字符作为坐标轴x点,后N/2个字符作为坐标轴y点,根据坐标点落入圆中的个数计算π 估计值并计算其与真实π 值的误差.图3为未加密压缩流量和加密流量π 值误差的对比图,可以看出未加密压缩流量的π 值误差较大,而加密流量的π 值表现误差较小.所以用蒙特卡罗仿真估计π 值的误差可以区分未加密压缩流量和加密流量.
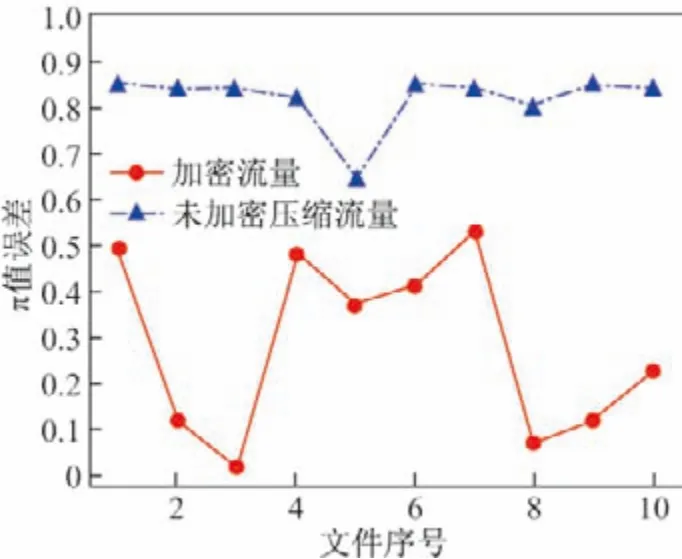
图3 未加密压缩流量和加密流量的π 值误差Figure3 Value error of unencrypted compressed traffic and encrypted traffic π
2 基于DPI 和负载随机性的加密流量识别模型
本文提出的加密流量识别模型以C4.5 决策树算法为基分类器.C4.5 决策树算法的学习采用自上而下的递归思想,以信息增益率为度量构造一颗熵值下降最快的树,到叶子节点的熵值为0,此时每个叶子节点的实例都属于同一类别[15-16].C4.5 决策树方法在模型构建和样本预测过程中均不依赖网络流量样本的分布,能够有效地避免网络流样本分布变化所带来的影响和不必要的干扰.在处理分类问题时具有良好的稳定性.相较于其他传统机器学算法,该方法计算相对简单、效果优良、速度快、分类效率较高,更适合网络流量的识别.
加密流量的识别是一个二分类的问题,本文采用信息熵h和蒙特拉罗估计π值误差p作为分类器的特征向量输入,记作X,类别加密和非加密流量用标签Y 表示,其中加密流量取1,非加密流量取0.本文实验方法的流程如图4所示.整个模型分为以下几个部分:
1)预处理阶段
采集并筛选完整的会话网络流,其余不完整网络流不予使用.如本文TCP 流语义完整的判定条件是以完整的握手过程(SYN-ACK)开始,且以完整的握手过程(FIN-ACK)结尾的TCP 双向流.检查并提取会话流的特征规则,将提取出的特征规则写入DPI 指纹库中,保证DPI 的有效作用.
2)DPI 指纹识别模块
此模块可对加密流量进行识别预处理,提取每个样本数据包包头的网络协议特征字段与DPI 指纹库特征数据进行特征匹配,通过对样本流量的快速识别提高模型的整体效率.
3)负载随机性计算模块
此模块是整个模型最重要的阶段,主要工作对DPI 识别失败的样本指定N个数据包并计算其有效负载的随机性,提取特征向量信息熵h和蒙特拉罗估计π值误差p输入分类器训练模型,并保持模型的持久化以便对待测样本的决策分类.
4)分类器决策模块
把DPI 识别失败样本的特征输入分类器,最终进行决策评估.

图4 基于DPI 和负载随机性的加密流量识别流程Figure4 Encrypted traffic identification process based on DPI and load randomness
3 实验结果及分析
3.1 实验方案与评价指标
3.1.1 实验环境
本文实验的主机配置如下:操作系统为Windows 7 专业版,CPU 为四核Intel(R)Core(TM)i5-3230M CPU @2.60GHz,8GB 内存.第三方软件及API 为VMware Workstion 12、Ubuntu 16.04、Python 3.6.4、scapy、libpcap、sklearn 等.
3.1.2 实验数据集
为了测试本文所述算法检测数据流加密的准确性,实验数据集来源于如表1所示的实验室真实网络,共采集6 500个加密通信流和7 500个未加密通信流,其中加密流量数据集包括Skype 协议、SSL 协议、SFTP 协议,未加密流量数据集包括HTTP 协议、SMTP 协议、抓取socket 文件传输的明文流量包(传输文件内容有txt、doc、pdf、zip 等类型).
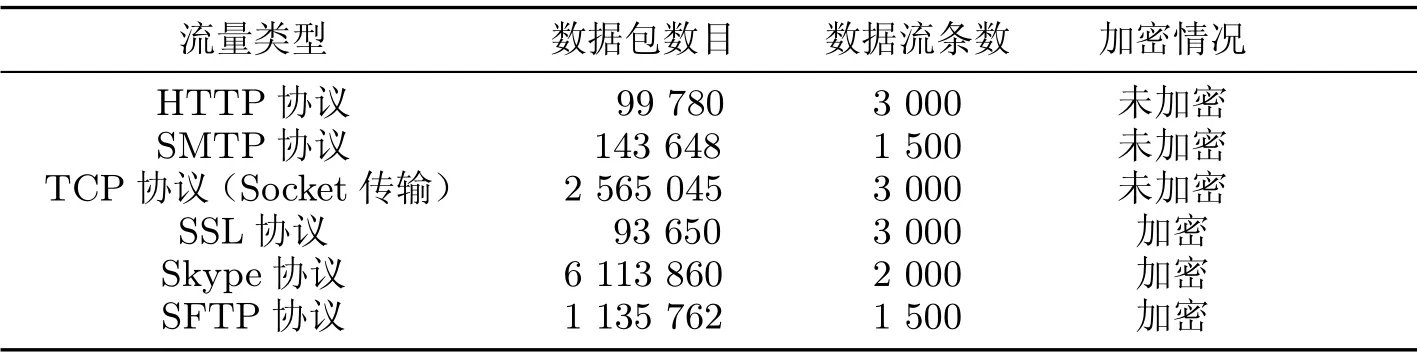
表1 实验数据集Table1 Experimental data set
3.1.3 实验步骤
具体实验步骤如下:
步骤1用Wireshark 抓取网络流量,生成会话,通过五元组对流量过滤分流获取实验数据集.
步骤2提取数据包包头的网络协议格式字段与指纹库匹配,并通过去掉DPI 指纹库某一协议特征字段的方式模拟私有协议.若与MDPI 指纹库特征匹配成功则转到步骤3,否则进入步骤4,进一步进行流量识别.
步骤3DPI 指纹库匹配成功,则可直接决策待识别流量的结果.
步骤4对于DPI 识别失败的流量,通过LICPCAP 库提取待测数据,判断第1个数据包的长度,若大于1 024 字节,则提取此数据包的有效负载,否则丢弃此包进入下一个包,直至提取到N个数据包.采用等间距算法,以有效负载每个字符为1个计算单位,用香农熵公式计算字符在整个数据包中出现的熵值,并将所提取数据包的有效负载的每N个字符作为一组蒙特卡罗仿真点,前N/2个字符作为坐标轴x点,后N/2个字符作为坐标轴y点,根据坐标点落入圆中的数目计算π 估计值,并计算其与真实π 值的误差.
步骤5对字符熵h和蒙特卡罗估计π 值误差p的数据进行标准化处理,把特征向量输入C4.5 决策树分类器,通过交叉验证方式调试分类器参数得到最优的分类器模型并进行决策评估.
3.1.4 评价指标
为了客观评价算法的性能,本文参考精准率P、召回率R、F1-Measure 这3 项评分.精准率是所有预测正确的占总的比例,召回率即正确预测为正的占全部实际为正的比例,F1值是一项综合评价指标,定义为精准率和召回率的调和均值.这些指标的计算公式分别为

式中,Tp真正表示加密流量的样本被正确识别的数目,Fp假正表示真实是加密流量但被错误的标识的数目,FN假负表示未加密流量的样本被正确识别的数目.
3.2 实验结果与分析
3.2.1 数据包数目与准确率的关系
对于DPI 识别失败的流量需要进一步识别判定.由于数据包字节太小时不能反映负载随机性的特点,提取网络流负载大于1 024 字节的数据包.网络流样本观察窗口的大小对模型的识别率有很大的影响,如图5所示.识别模型刚开始的平均准确率与数据包数目呈正比关系,当数据包数目较少时模型的准确率偏低,从统计学角度来看,因为数据量不足不能充分反映网络流量的特点,局限性太大.当数据包数目为10 时平均准确率最高达到95.25%,之后两者之间呈振荡关系上下浮动,考虑到模型时间效率和计算机的资源开销,本实验选择数据包数目为10 时能达到最理想的识别效果.
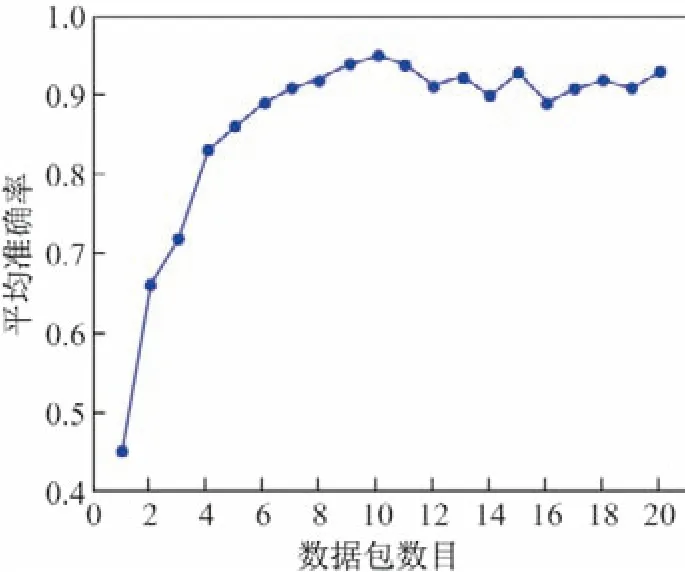
图5 数据包数目对准确率的影响Figure5 Effect of the number of packets on the accuracy rate
3.2.2 坐标点字符的数目与准确率的关系
蒙特卡罗仿真点的坐标点字符的数目同样影响着识别模型的准确率,如图6所示,当坐标点字符的数目为2 时,模型的准确率89.02%,与仅用信息熵单一特征精准率的效果差别不大.当坐标点字符的数目增加到6 时模型准确率最高,之后随着坐标点字符的数目的增大准确率会下降,可见本文识别模型的观察窗口设置为6 时最能区别未加密压缩流量负载的伪随机特征.
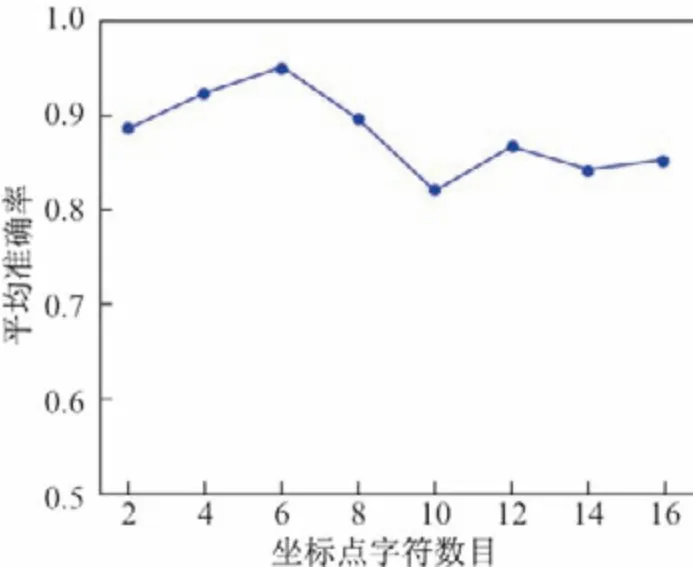
图6 坐标点字符数目对准确率的影响Figure6 Effect of the number of characters in the coordinate point on the accuracy
3.2.3 与传统识别模型的比较
图7~9 是本文提出的基于DPI 和负载随机性的加密流量识别模型与文献[8]基于信息熵的加密流量识别模型和文献[17]提出的基于流特征识别模型实验效果的对比图可以看出,本文方法实验效果最好,平均精准率、召回率、F1-Measure 分别超过了94.98%、90.05%、92.45%.由于加密流量和非加密压缩流量在信息熵会表现出相似的特征,文献[8]仅用熵值这一特征会造成两者误判,所以其平均精准率、召回率、F1-Measure 仅分别为85.45%、83.43%、84.42%.同时,本文方法较文献[17]提出的基于流特征的识别模型实验效果更好,文献[17]识别模型平均的精准率、召回率、F1-Measure 仅分别为92.34%、88.50%、90.38%,因为基于流特征的识别模型对于数据包存在字节填充的情况以及网络流太短的流量不能准确识别,这就造成了模型之间的效果差异.

图7 不同模型精准率的比较Figure7 Precision rates comparison of different model
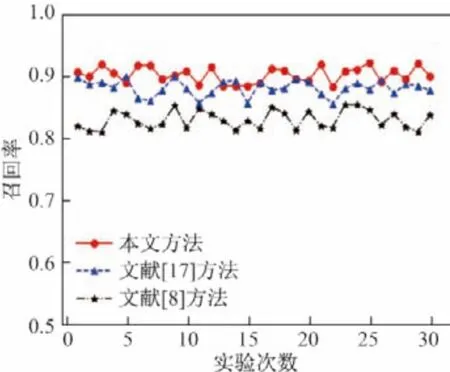
图8 不同模型召回率的比较Figure8 Recall rates comparison of different model

图9 不同模型F1-Measure的比较Figure9 F1-Measure comparison of different model
3.2.4 鲁棒性实验
为测试本文识别模型的鲁棒性,通过去掉DPI 指纹库某一协议特征字段来模拟私有协议.图10 和11 分别给出了去除指纹库HTTP 协议和Skype 协议的特征字段模拟私有协议Ⅰ和私有协议Ⅱ的实验效果,模拟私有协议Ⅰ的实验效果平均精准率、召回率、F1-Measure 分别达到94.84%、90.32%、92.52%,模拟私有协议Ⅱ平均精准率、召回率、F1-Measure 分别为94.47%、90.11%、92.01%,可以看出模型在有干扰的情况下总体表现稳定,证明了本文的识别模型具有良好的鲁棒性.
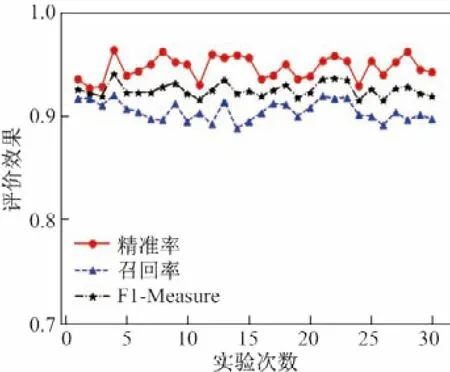
图10 识别模型在模拟私有协议Ⅰ下的性能Figure10 Identification model performance under simulated private protocol I
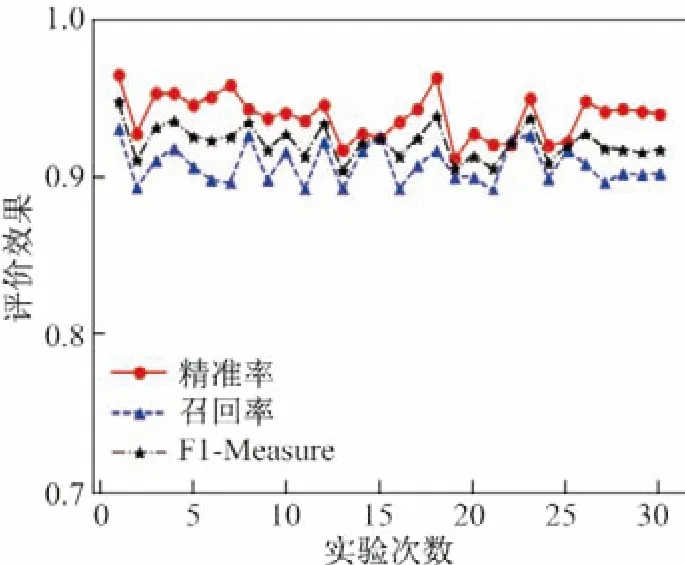
图11 识别模型在模拟私有协议Ⅱ下的性能Figure11 Identification model performance under simulated private protocol Ⅱ
4 结 语
本文分析了网络流量负载随机性的特点,提出了基于DPI 和负载随机性的加密流量识别模型,该方法通过DPI 技术快速准确地进行流量预分类,充分发挥了DPI 的优势,并对DPI无法识别的流量,进一步计算其数据包负载的随机性,从而达到有效识别加密流量的目的,本文取得的主要成果如下:
1)设计了一种基于数据流前10个数据包有效负载的识别模型;
2)本文所提的加密流量识别模型较传统的基于流特征的识别模型实验效果好,其平均精准率、召回率、F1-Measure 分别超过了94.98%、90.05%、92.45%,与传统的流量识别模型相比具有优良的识别性能.
3)通过模拟私有协议的扰动实验表明本文提出的识别模型具有良好的鲁棒性.
本文实验的网络环境较简单,未来将考虑更复杂的网络环境下的加密流量识别问题.
