基于领域词典和机器学习的影评情感分析
2019-11-03徐善山
徐善山
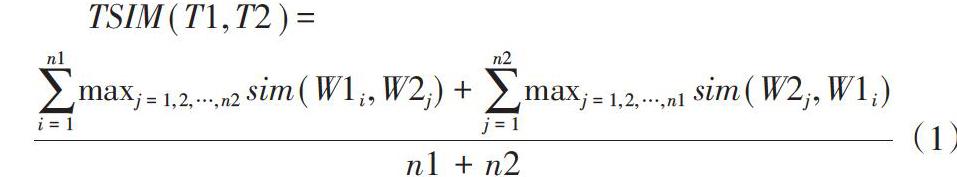


摘要:针对影评文本情感分析准确性不高的问题,本文提出一种基于影评领域词典结合机器学习的情感分析方法。首先,构建完备的影评领域相关词典,如程度副词词典、否定词词典和网络用词词典。然后,利用文本相似度的方法(TSIM)对训练数据集进行去重处理,并提出三类特征:词性、句法、依存进行選择。最后,利用NB和SVM相结合的分类方法对影评进行情感分类。实现结果表明,该方法相对于仅仅基于传统的机器学习的方法,具有更准确的分类精度。
关键词:情感分析;领域词典;机器学习;数据去重;特征选择
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2019)23-0222-02
开放科学(资源服务)标识码(OSID):
1 引言
交互性网络技术的不断发展,使得越来越多的人通过豆瓣、微博影评等电影网站发表自己对电影的观点和看法,这些影评包含着很多用户对于电影及其相关内容的评价。因此,对于这些影评文本信息进行情感分析具有重要的商业价值。但是目前,影评领域情感分析的准确性不是很高,主要是因为影评领域相关情感词典的不完备性、机器学习方法需要完备的语料库和精确的特征选择。针对上述问题本文提出一种基于影评领域词典和机器学习相结合的情感分析方法。本文的主要工作为:1)构建完备的影评领域相关的词典;2)对训练数据集进行去重处理,并进行特征选择;3)利用NB和SVM相结合的分类方法对影评文本进行情感分类。
2 相关工作
文本情感分析技术主要分为情感词典和机器学习的方法。在情感词典方面:栗雨晴等人[1]提出一种基于双语词典的多类情感分析方法,通过构建双语多类情感词典对微博文本进行多分类语义倾向性分析。肖江等人[2]提出一种基于领域情感词典的中文微博情感分析策略,能够有效分析出微博中的情感倾向。孔伟俊等人[3]提出基于领域词典的商品评论分析策略,能够有效分析出网络商品评论的情感倾向。在机器学习方面:朱军等人[4]提出了一种改进的机器学习方法和情感词典结合的集成学习情感极性分类方法。针对旅游网络评价使用的旅游情感词汇量不多的特点,王新宇[5]提出一种基于旅游情感词典和机器学习相结合的方法。针对中文微博内容较短、口语化严重、主题分散等特点,孙建旺等人[6]提出了基于词典和机器学习相结合的方法。
3 影评情感分析
3.1 情感词典的构建
目前,影评领域情感分析方面尚未有一部通用和完备的情感词典,使得影评领域的情感分析一直不够准确。因此,本文为了使影评领域的情感分析具有更好的识别效果,将目前较好的并广泛应用的3个情感词典(知网的HowNet、台湾大学的NTUSD和大连理工大学的情感词典)进行优化和整合,构建成了一部综合基础情感词典。
此外,本文还构建了程度副词词典、否定词词典和网络用词情感词典。程度副词词典主要是采用知网的程度级别词典,共219个词,如:极其、非常、不少、半点等。本文整理构建了否定词典,共31个词,如:不、没、无、非等。网络用词情感词典主要是将“常用网络用词情感词典”和“2019网络用词”进行优化和整合,从而构建了数量为254的网络用词情感词典,如:盘它、开挂、前方高能、实锤等。
3.2 数据集去重
如果机器学习中训练数据集的相似影评文本的样本数量很多,将严重影响机器学习模型预测结果的分布和情感分析的性能。由此,本文采用文本相似度的方法,将相似度最高的影评文本进行合并,达到对训练数据集去重的目。
定义1:文本相似度(Text similarity,[TSIM] )用来计算两个文本的语义相似度,计算公式如下:
[TSIM(T1,T2)=i=1n1maxj=1,2,…,n2sim(W1i,W2j)+j=1n2maxj=1,2,…,n1sim(W2j,W1i)n1+n2] (1)
在公式(1)中,[W1i]和[W2j]分别为影评文本[T1]和[T2]中的词元素,[n1]和[n2]分别为影评文本[T1]和[T2]中词元素总的数量,[sim(W1i,W2j)]是基于知网词语的语义相似度计算公式。首先遍历训练集中的所有语句,然后将相似度最高的两条语句进行合并,达到减少机器学习中训练数据集的相似评论文本的样本数量、增加低频文本权重的目的,从而提高机器学习模型预测结果的分布和情感分析的性能。此方法能够有效降低影评文本中因某些用户的恶意评论或水军的虚假言论,导致机器学习模型预测结果的不准确。
3.3 特征选择
文本的特征提取是机器学习的关键步骤,可以说情感分类的准确性和效率很大程度上取决于特征值的选取。本文选择三类特征:词性、句法、依存关系。词性在影评文本情感分析中起很大的作用,因为一个影评文本是由多个不同词性的词构成的。句法特征是给出句子的组成部分、排列顺序、词性标注的特征。依存关系特征是从依存关系树中给出的依存关系和词性搭配的特征,其对影评文本情感分析起着决定性作用。在选择特征时,每类特征维度的具体含义如表1所示。
本文以“这部电影真心不错,我非常喜欢。”为例进行特征选择。
①使用中科院ICTCLAS分词技术进行处理,可以获得例句的词性特征、句法特征如下:
这部/r电影/n真心/d不错/a,/wd我/rr非常/d喜欢/vi。/wj
其中,/r表示代词、/n表示名词、/d表示副词、/a表示形容词、/wd表示标点符号、/vi表示动词。
②在ICTCLAS分词的基础上,使用哈工大语言技术平台(LTP)处理工具,获得例句的依存关系和词性搭配特征如下:
从图2中可以得到例句的5种依存关系:HED(核心)、ATT(定中关系)、SBV(主谓关系)、ADV(状中关系)、COO(并列关系)。通过上述2个步骤可以得到机器学习方法的三种基本特征模板,并作归一化处理,从而为其训练分类器。
3.4 NB结合SVM的分类方法
选择三类特征并作归一化处理,将其扩展到机器学习的特征模板中后,本文采用NB结合SVM对整个数据集進行训练得到分类器。
朴素贝叶斯(NB)分类算法具有简单、稳定的分类效果,但是条件是每个变量是相互独立的。判断一条影评的情感倾向时,若影评中有情感词出现在情感词典中,则采用NB分类方法,因为将情感词作为NB分类方法的特征时,统计特征更加合理和明显,并且可以利用NB分类方法从事先计算好的情感词的条件概率分布得到分类的结果。
支持向量机(SVM)是一种二类分类模型,利用SVM分类方法进行分类,是因为NB分类方法仅仅简单地统计影评中的词语得到概率分布,忽略了词语之间的依存关系,而SVM考虑到了影评词语之间的依存关系和句子之间的语义关系。所以本文将两种方法相结合进行互补,达到对分类结果更加准确的目的。
如图2是基于NB和SVM的情感分类流程图。第一步,对影评数据进行综合处理:首先将数据集分为正向和负向,然后对数据集进行去重处理,最后提取特征并作归一化处理;第二步,判断特征值是否在情感词典中,若在情感词典中则使用NB分类方法,反之则使用SVM分类方法。
4 实验分析
本文利用网络爬虫技术从豆瓣平台和微博影评中抓取5000条影评数据集,并对这些影评数据集进行人工情感标注。本次实验以准确率P、召回率R和F1值作为评价指标。
为了验证本文提出的基于领域词典和机器学习的情感分析的准确性,本文通过下表对测试数据进行了实验,并对结果进行分析和评价。
由上表可以得出,基于领域词典和机器学习的情感分析方法在准确率上面比基于传统的SVM和NB分类方法都要高。因此,该实验证明了基于领域词典和机器学习的情感分析方法在整体上是优于基于传统的SVM和NB分类方法,并验证了本文方法具有更高的准确性。
5 结论
实验结果表明,基于领域词典和机器学习的情感分析方法对于影评领域的情感分类具有更高的准确性,能够更加适应于影评领域的情感分析,从而解决了传统机器学习方法对影评领域情感分析不准确的问题。
参考文献:
[1] 栗雨晴,礼欣,韩煦,等.基于双语词典的微博多类情感分析方法[J].电子学报,2016,44(9):2069-2073.
[2] 肖江,丁星,何荣杰.基于领域情感词典的中文微博情感分析[J].电子设计工程,2015,23(12):18-21.
[3] 孔伟俊,胡广朋.基于领域词典的网络商品评论情感分析[J].计算机与数字工程,2018,45(1):155-159.
[4] 朱军,刘嘉勇,张腾飞,等.基于情感词典和集成学习的情感极性分类方法[J].计算机应用,2018,38(S1):95-98.
[5] 王新宇.基于情感词典与机器学习的旅游网络评价情感分析研究[J].计算机与数字工程,2016,44(4):578-582.
[6] 孙建旺,吕学强,张雷瀚.基于词典与机器学习的中文微博情感分析研究[J].计算机应用与软件,2014,31(7):177-181.
【通联编辑:唐一东】
