类不平衡数据的卡方聚类算法研究
2019-10-08刘欢胡德敏
刘欢 胡德敏


摘 要: K-means型算法在处理类不平衡数据时趋向于形成大小相同的簇,是“均匀效应”。针对这一问题诸多研究者提出了不同的聚类算法,这些方法针对簇样本数量不平衡特性,存在精度和效率问题。本文以卡方距离为基础提出了一种类平衡数据的聚类算法,利用均值消除受簇均值水平影响的特性度量样本相似性,解决类不平衡数据中“均匀效应”问题,给出了聚类目标函数,形成一种EM型聚类优化算法。在UCI实际数据集上进行了实验,结果表明本文所提出的算法提高了类不平衡数据的聚类精度,降低了“均匀效应”对聚类结果的影响。
关键词: 数据挖掘;类不平衡;卡方距离;聚类;均匀效应
中图分类号: TP301 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.04.002
本文著录格式:刘欢,胡德敏. 类不平衡数据的卡方聚类算法研究[J]. 软件,2019,40(4):0710
【Abstract】: The k-means algorithm tends to form clusters of the same size when processing class unbalanced data, which is the "uniform effect". To solve this problem, the researchers proposed different clustering algorithms, which aimed at the unbalanced characteristics of the number of cluster samples, and did not directly solve the "uniform effect" from the perspective of clustering objective function. In this paper, based on the chi-square distance, a kind of clustering algorithm for balanced data is proposed, which USES the mean value to eliminate the characteristics affected by the mean value of the cluster to measure the sample similarity, so as to solve the problem of "uniform effect" in the class unbalanced data. Experiments are carried out on the actual dataset of UCI. The results show that the algorithm proposed in this paper improves the clustering accuracy of class unbalanced data and reduces the influence of "uniform effect" on the clustering results.
【Key words】: Data mining; Class imbalance; Chi-square distance; Clustering; Uniform effect
0 引言
聚類分析已经广泛的用于商务智能、图像模式识别、生物学与安全等诸多领域。现如今的聚类算法大致可划分为如下几类[1,2],基于划分聚类算法、基于层次聚类算法、基于模糊聚类算法、基于密度聚类算法等。例如划分算法是将数据对象集划分成不重叠的子集(簇),使得每个数据恰在一个子集中[3]、层次聚类是对给定数据集进行层次分解,直到满足相关条件为止。经典聚类算法能较好处理常规数据(例如球形数据),然而现实生活中业者面临着更多复杂的数据,例如类不平衡数据。这类数据的一个典型特点是在数据集中不同簇的样本数量有较大差异。(例如,在有两个簇的数据集中一个簇样本数量有5000个,另外一个簇的样本数量有50个。)类不平衡数据的研究是当前数据挖掘领域一热点[4,5]。
K-means作为经典的聚类算法[6],其在对任意类不平衡数据集进行聚类分析时,将其划分为2个簇,则两个簇的样本数量趋于相同,此为 K-means 算法的“均匀效应(uniform effect)”[7]。为解决类不平衡数据在聚类时产生的“均匀效应”问题,现研究者提出多种方法[8-11],例如:基于样本抽样,即在聚类之前对数据集进行欠采样或过采样的处理,例如,HE H, GARCIA E A[8,9]等人提出的解决问题的方法即是在预处理后的数据上进行 K-means聚类的,但是该方法的过采样是通过不断复制少数类来使数据的规模不断变大,由于此类方法使数据集中的样本数量增加,从而导致计算开销的增加、算法性能下降等问题。过采样只是在数据集中抽取子集,从而容易导致缺失相关数据中潜在的价值信息;第二类方法在聚类中考虑不同簇的样本量差异,例如,HARTIGAN JA, WONG MA等人[11]引入簇的样本数量,提出了两种改进基于迷糊聚类的目标函数的优化方案,以及借助多代表点[10]以此区分数据集中的不同的密度区域,但是该方法在低维数据和高维数据,算法的执行效率较低;针对上述方法在解决类不平衡数据的效率和精度问题,提出一种基于卡方距离的聚类算法从聚类目标函数的角度出发,解决“均匀效应”问题的方法,卡方距离在在度量相似性时候引入了样本的均值,而均值能表征样本的分布情况。本文针对类不平衡数据的“均匀效应”问题,用卡方距离度量数据离散程度,根据相似度度量给出了聚类目标函数(基础),并给出一种EM型聚类优化算法,最后通过UCI实际数据集验证,算法精度提高36%~68%。
1 K-means算法的“均匀效应”
经典的K-means算法是一种划分型聚类算法,其优化目标定义为:
K-means常通过EM算法[12]进行优化,具体算法过程如下:1、首先输入样本;2、再选择初始的K个簇中心点,3、标记距离簇中心最近的簇;4、将样本划分至距离最小的簇;5、更新簇中心点的坐标,算法重复上述3-5步骤,直到满足停止条件算法终止,得到局部最优解的数据集簇划分。
文献[7]分析K-means算法的“均匀效应”问题以及其产生的原因。如下图1、图2示例所示:图中两个簇的数量以及密度均有较大的差异。
通过K-means算法对上图数据集进行聚类得到的聚类结果如图2所示,由此可知两个簇的样本数量以及密度趋于相同,此现象即为K-means型算法的“均匀效应”问题。
针对均匀效应,当前的研究者给出了不同的方法,例如,KUMAR N S, RAO K N[9]等人提出以两个簇的数据为基础,利用特征选择将样本数较多的簇中部分样本删除掉,然后将两个簇形成平衡数据集,最后利用K-means对处理后平衡数据集进行聚类的;LIANG J, BAI L[13]等人提出通过样本集中进行采样,然后利用K-means对样本集进行聚类,给出聚类后样本簇标号,生成相似矩阵,经过指定次数的反复处理后利用谱聚类对相似矩阵进行聚类;JAIN A K[11]指出分别以模糊c均值和模糊c-har?monic均值算法为基础,利用簇中数据的隶属度之和表示簇中样本数量,然后在聚类目标函数中引入簇的样本数量,最后给出了根据目标优化函数求解定义的算法。
综上所述,上述研究者的算法会存在一定程度的效率和精度问题。综上可知,上述研究者的算法多侧重在解决样本的不平衡性上,并没有从聚类目标函数出发解决“均匀效应问题”,而聚类算法的一个重要基础是聚类目标函数。本文以此为切入点,本文分析了ALOISE D, DESHPANDE A [14]等人在聚类研究时,利用卡方距离进行相似性度量。卡方距离在度量相似性时候引入了样本的均值,均值能表征样本的分布情况,而类不平衡数据的一个特点是不同簇样本数量有较大差异。本文以卡方距离为基础定义了聚类目标函数,新的目标函数中通过引入样本的均值以消除均匀效应的影响,以此提高类不平衡数据聚类精度。
2 基于卡方距离的聚类算法
2.1 基于卡方距离的相似度度量
相关研究表明,卡方距离度量能够度量数据相似性[14],本节引入卡方距离度量类不平衡数据中相似性,以此降低“均匀效应”对聚类的影响,卡方距离如式(3)所示。
式(3)在欧式距离的基础上引入了样本的均值度量样本v_ij与v_j的相似性,而v_j能表征样本的分布信息,在度量样本与vj的相似性时候通过引入v_j消除样本不平衡性带来的影响。在划分型聚类算法中常用均值作为簇的代表点,(3)式可以看作是样本点与簇代表点的相异度,通过引入v_j消除簇均值的影响,这才不平衡数据中可以消除样本不平衡性带来的影响。基于卡方距离的相似度度量公式如式(4)所示。
公式(4)中以簇中均值作为簇的代表点。基于样本各特征之间相互独立假設,(4)式对各特征分开算。
在本文中选取图1的中点m,并与基于欧式距离的相似度度量公式进行比较,以此来解释基于卡方距离的相似度度量公式的样本点与不同簇之间的相似度。
表1为两种不同度量公式的计算结果。传统的K-Means聚类用欧氏距离,计算结果为||dc1||与||dc2||,样本点d与簇中心c1的相异度小与d与c2的相异度,d被划入到c1所代表的簇中;L(d,c1)与L(d,c2)为本文度量公式计算结果,表1中L(d,c2)小与L(d,c1),d将划入第二个簇中。样本点d的真实的簇标签是第二个类,表明本文提出的相异度公式能更准确的划分d点。
2.2 聚类算法
通过公式(4)提出的相似度度量公式 ,给出类不平衡数据的聚类优化目标函数如下公式(5)所示。
本文算法是一种划分型算法,划分型算法实质是聚类目标函数最佳值求解的过程,因此本文的目标是最小化公式(5)。公式(5)引入了卡方距离,但仍然是一种欧式距离的求解,这种聚类算法的求解是NP难问题[15],这使得其最优值的求解是困难问题,针对这类问题研究者常用的方法是求其局部最优值。因此,本文采用了传统的迭代法来求解目标函数的局部最优值。算法过程描述如下:
输入:数据集DB,簇数目K;
输出:簇划分C。
第一步:初始化操作,随机选取簇中心点;
第二步:利用公式(3)进行簇的更新;
第三步:利用公式(4)更新簇中心点;
第四步:迭代次数增加并判断中心点是否变化,如果中心未变化或者迭代次数大于阈值算法停止否则返回第二步。
2.3 算法分析
传统的K-Means算法每次迭代的时间复杂度为O(KND),其中k为簇数目,N为样本数量,D为样本维度,本文算法在结构上与k-means算法类似,假设算法经过P次迭代停止,则基于卡方距离的聚类算法时间复杂度为O(KNDP)。因为算法在每步迭代的过程中都是在求最小的欧式距离划分,因此聚类目标函数值降低每次迭代都在降低,此外目标函数存在下界,因此在P次有限的迭代下基于卡方距离的聚类算法是收敛的。
2.4 实验分析
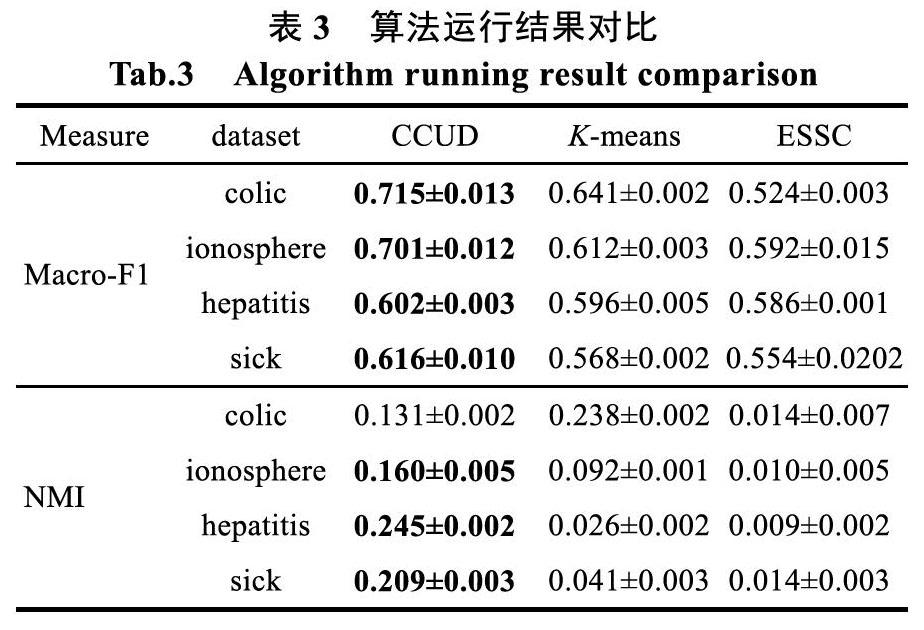
本研究从UCI Machine Learning Repository (http://Archive.ics.uci.edu/ml/datasets.html)数据集中选用了4个真实数据,分别是colic、ionosphere、hepatitis、sick,相关信息如表2所示。