基于变分自编码器的问题识别方法
2019-09-23李寿山
王 路, 李寿山
(苏州大学 计算机科学与技术学院 江苏 苏州 215006)
0 引言
当前所有问答相关的研究都是基于正式文本的,可是在实际应用中会存在许多问答文本是非正式的情况.在非正式文本中,没有问号标志的地方经常会存在许多子问题,例如:问题“大家好 是正品吗,电池耐用吗.是全新的吗”当中并没有出现问号,根据空格、逗号、顿号、问号、感叹号和句号作为分隔符可以被划分为4个子句“大家好”、“是正品吗”、“电池耐用吗”和“是全新的吗”,第1个子句不是问题,而后面的3个子句分别是3个问题.有问号标志的地方,也不一定是问题,例如:根据上面的划分规则,问题“不是用来玩游戏?就是用来办公 买pro好还是air好”可以被划分为三个子句“不是用来玩游戏”、“就是用来办公”和“买pro好还是air好”,“就是用来办公”不是一个问题,“买pro好还是air好”是一个问题,虽然子句“不是用来玩游戏”以问号结尾,但是它并不是一个问题.
在本文中,我们关注于非正式文本的问题识别.我们从产品评论网站上收集了许多非正式文本的问题,并且人工标注了一部分问题.由于变分自编码器的广泛应用以及注意力机制在自然语言处理领域取得的显著成果,我们决定结合两者来进行问题识别.
1 相关工作
文献[1-2]利用人工设置的规则创建了一个高准确性的分句系统.文献[3]利用深度学习得出特征的表示,再将英文字符中每个字符都作为标注位,利用序列标注模型条件随机场(conditional random filed, CRF)来进行标注.文献[4]利用CRF来进行文言文的分句.文献[5]将语音识别中单词与单词之间的空格设置为边界,利用支持向量机(support vector machine, SVM)对每一个边界进行分类.文献[6]采用了递归卷积神经网络对神经心理学的记叙文本进行句子切分.文献[7]研究了中文中逗号的作用,利用SVM对逗号进行分类,从而进行分句.我们的任务与上述任务都是对一段文字进行分类,与上述任务不同的地方在于,上述文本是对断句的位置进行分类,我们的任务是判断子句是否为问题.
当前半监督方法在自然语言处理领域获得了广泛的应用.文献[8]利用狄利克雷过程混合模型来进行新闻话题检测.文献[9]利用self-training来进行中文问答模式的学习.文献[10]利用tri-training来进行多标记文档分类.文献[11]利用标签传播(label propagation,LP)来进行问答分类.我们采用半监督神经网络模型-变分自编码器来进行问题识别.
2 数据收集和标注
淘宝是中国最大的电子商务平台,我们从淘宝的“问大家”板块收集了200 000个问题文本,这些问题主要来自于数码领域.并且我们利用句子切分工具将问题文本切分成子句的集合.为了确保较好的一致性,在进行了多次的少量标注后,我们提出了一些标注规范.然后,让更多人根据该标注规范来标注整个数据集.我们根据子句的顺序来进行判断,遇到是问题的子句直接标注它的序号,如:
例1问题:是正品吗?有点不放心?万一是翻新怎么办?标注:1,3.
例2问题:像素好不好?容易发热吗 充电多久.标注:1,2,3.
例3问题:亲们 网络怎么样…不连续使用的话,可以用多久?标注:2,4.
我们一共标注了3 000个问题文本,一共切分出了5 455个子句.其中4 027个子句属于“问题”类别,1 428个子句属于“非问题”类别.对于每个问题文本,我们安排了两位标注人员来进行标注,一致性检验kappa值为0.89.为了应对两位标注人员标注不一致的情况,我们安排了一位熟练的标注人员来检查,确保标注的一致性.
3 基于变分自编码器的问题识别
3.1 长短期记忆(long short-term memory, LSTM)网络
长短期记忆(long short-term memory, LSTM)网络是一种特定形式的循环神经网络(recurrent neural network, RNN),它使用记忆门和遗忘门相结合的策略,可以解决传统RNN在长序列上存在的梯度消失和梯度爆炸的问题.LSTM结构示意图如图1所示.
LSTM利用记忆单元对历史信息进行记录,并通过3个控制门来进行信息的更新.LSTM在t时刻的更新为
it=σ(Wixt+Uiht-1+bi),ft=σ(Wfxt+Ufht-1+bf),ot=σ(Woxt+Uoht-1+bo),
其中:xt为LSTM在t时刻的输入;ht-1为LSTM在t-1时刻的输出;ct为记忆单元在t时刻的候选值;W、U是参数矩阵;b是偏置向量;σ表示Logistic函数;符号⊗表示向量的Hadamard积;遗忘门ft用来决定当前时刻哪些旧信息需要从记忆单元中抛弃;输入门it决定当前时刻记忆单元中需要存储哪些新的信息;输出门ot决定了当前时刻记忆单元中哪些信息需要输出.遗忘门ft与上一个时刻记忆单元的值ct-1相乘,得到上一时刻记忆单元保存下的信息,输入门it与当前时刻记忆单元的候选值ct相乘,得到当前时刻新加入记忆单元的信息,将两者相加,得到当前时刻记忆单元的值ct.使用tanh函数将记忆单元ct的值映射到-1与1之间,起到稳定数值的作用.最后将输出门ot与tanh(ct)相乘,得到LSTM单元在t时刻的输出ht.
3.2 条件长短期记忆(condition long short-term memory, C-LSTM)网络
文献[12-13]是LSTM的一种改进版本,C-LSTM将词向量和标签值都作为输入,我们修改了LSTM的公式,将标签值y加入到输入门、遗忘门和输出门之中.所用公式为
it=σ(Wixt+Uiht-1+Viy),ft=σ(Wfxt+Ufht-1+Vfy),ot=σ(Woxt+Uoht-1+Voy),
3.3 基于变分自编码器的问题识别方法
在本节中,我们提出了一个基于变分自编码器的问题识别方法,即VAE-C,其结构如图2所示.VAE-C主要由3个部分组成:分类器qφ(y|x);编码器qφ(z|x,y)以及解码器pθ(x|y,z).
1) 基于注意力机制的分类器, 如图2(a)所示.
首先,我们采用LSTM对问题进行编码,从而获取每个词向量的上下文信息,公式为H=LSTM(X),然后,通过公式计算得到句子的注意力权重α,并归一化,α=softmax(tanh(WAttH+bAtt)),最后,我们将α与HT相乘,并连接一个隐藏层,从而进行分类,公式为y=sigmoid(WHid(αHT)+bHid),其中WHid(αHT)+bHid的维度是1,并且由于是二分类,所以输出层的隐藏函数使用sigmoid函数.
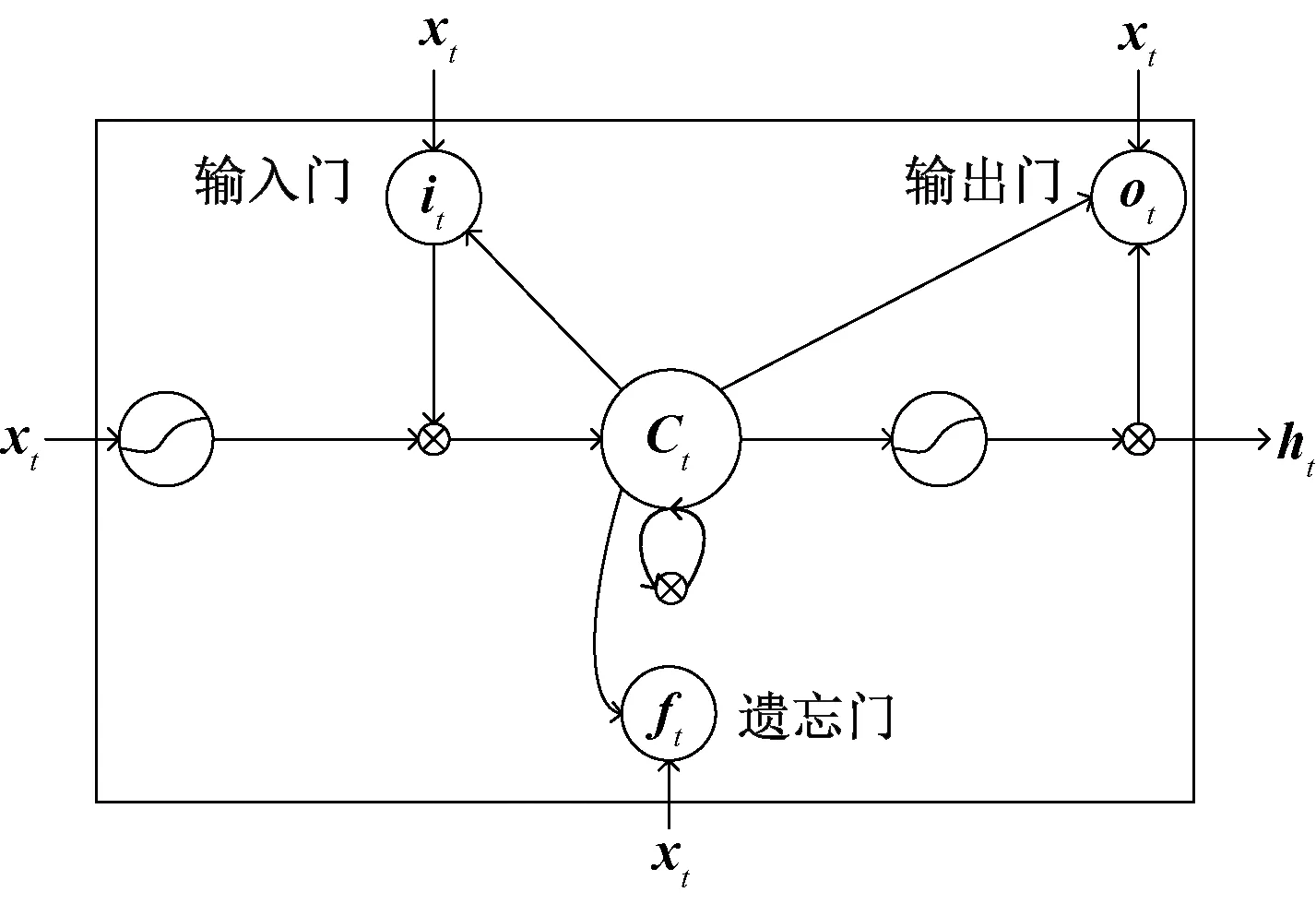
图1 LSTM结构示意图Fig.1 Structure of LSTM
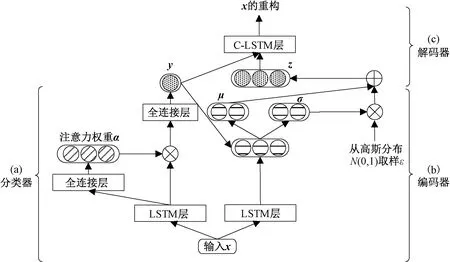
图2 基于变分自编码器的问题识别模型Fig.2 Question detection model based on variational auto-encoder
2) 编码器,如图2(b)所示.
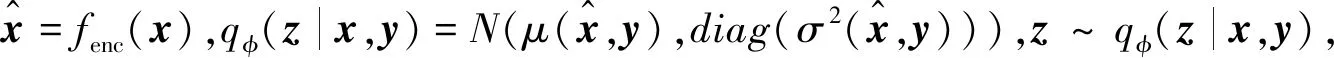
3) 解码器,如图2(c)所示.
解码器是给定隐变量z和标签值y,生成x的概率分布的条件生成模型为pθ(x|y,z)=D(x|fdec(y,z)).其中fdec(·)是解码函数,用来参数化概率分布D.D是输入数据的高斯概率分布.本实验中采用上文介绍的C-LSTM作为解码器,可以通过C-LSTM构建分类器和自编码器之间的联系,通过标签来引导自编码器学习出样本的共性,从而重构出正确的样本,并且更新分类器的参数.
VAE-C模型通过已标注样本和未标注样本联合训练更新模型参数,目标函数为
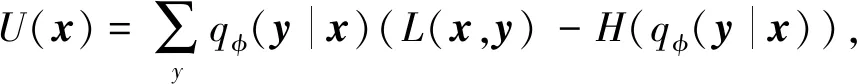
4 实验
4.1 实验设置
① 数据设置.采用第二节内容介绍的数据集作为实验数据.该数据包含5 455个子句.我们将数据随机分为训练集(每个类别的80%)和测试集(每个类别剩下的20%).此外,将来自训练集的10%的数据作为开发集,用于学习算法中的参数调整.② 词切分和词向量训练. 采用Jieba(https:∥pypi.python.org/pypi/jieba/)来进行分词,并且采用word2vec[14]来训练词向量.训练词向量的数据来自数码领域,共计200 000条问答对.词向量维度设置为100.③ 句子切分. 采用斯坦福大学自然语言处理实验室公布的CoreNLP(https:∥stanfordnlp.github.io/CoreNLP/download.html)工具来进行句子切分.④ 模型参数. 实验中所有模型使用深度学习开源框架Keras(http:∥Keras.io/)搭建,后端使用Theano(http:∥deeplearning.net/software/theano/)进行计算.模型中所有的超参数都是通过开发集的性能来进行调整.LSTM的单元数为128,C-LSTM的单元数为100.Batch size设置为64.采用Adam[15]作为优化器,优化器的学习率为0.001,迭代次数为30.
评价标准和显著性测试:我们用标准的精确率(P)、召回率(R)、F值和准确率来评价性能.我们采用t测试来评价两个方法间的显著性程度.
4.2 基线模型
最大熵(MaxEnt)是全监督方法,利用已标注样本的词特征训练的最大熵分类器.LSTM是全监督方法,利用已标注样本的词向量训练的LSTM分类器.Self-training[9]是半监督方法,利用整个特征空间构建分类器,并用其迭代加入置信度最高的样本扩充标注样本集合.Tri-training[10]是半监督方法,利用3个有较大差异的强分类器,采用“少数服从多数”的策略来产生伪标记样本. 标签传播(LP)[11]是半监督方法,利用已标注样本,通过标签传播方法预测未标注样本的类别,将这些已经确定类别的样本全部作为训练样本,训练分类器.
4.3 我们的方法
ATT是全监督方法,具体实现中,只利用了图2(a)所示的基于注意力机制的分类器.VAE是半监督方法,具体实现中,将图2(a)所示的基于注意力机制的分类器替换成了一个全连接的LSTM分类器.VAE+ATT是半监督方法,具体实现中,同时利用了注意力机制和变分自编码器,与图2保持一致.
4.4 结果
表1和表2给出了不同问题识别方法的总体性能及每个类别上面的性能,所有的半监督方法均添加了一倍的未标注样本.
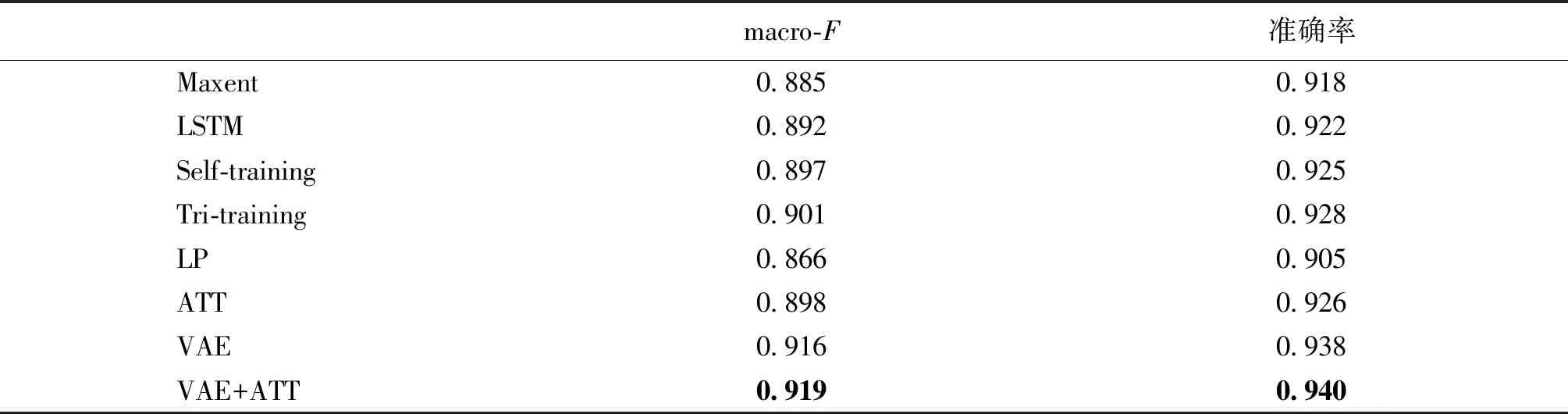
表1 不同问题识别方法的整体性能Tab.1 Overall performances of different approaches to question detection
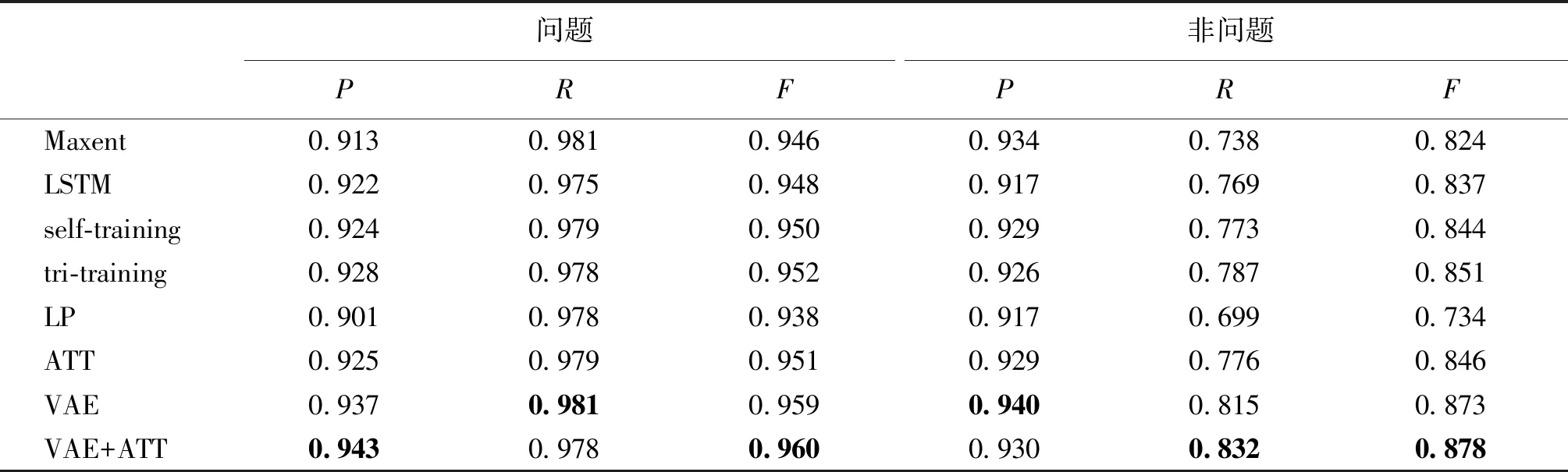
表2 不同问题识别方法在每个类别中的性能Tab.2 Performances of different approaches to question detection in each category
从表2中我们可以发现:在全监督方法中,我们提出的ATT模型相较于两种基线方法MaxEnt和LSTM在F值和准确率上均有一定的提升.在半监督方法中,LP的性能较差,两个指标均比全监督方法差.但是我们提出的方法均显著好于所有的基线方法,特别是在“非问题”这个类别中,VAE+ATT模型的R值和F值比最好的基线方法Tri-training分别提升了0.045和0.027.此外,VAE+ATT的性能在F值和准确率上均优于VAE.该结果表明了问题识别中采用注意力机制的重要性.测试结果表明我们的方法带来的性能提升具有统计显著性(p-value<0.05).
图3、图4给出了加入不同比例未标注样本时各半监督方法的准确率和F值.从图中我们可以发现,LP模型在样本提升时性能也得到一定提升,不过还是落后别的半监督方法很多.self-training和tri-training性能较为接近,在添加样本时存在一定小范围波动,性能逐渐收敛.VAE和VAE+ATT的性能明显好于别的所有的半监督方法,随着未标注样本数目的增加,模型性能得到了一定的提升,不过模型的性能在添加三倍样本时达到收敛.并且VAE+ATT的性能稳定高于VAE.实验结果表明,变分自编码器和注意力机制的结合可以有效提升问题识别的性能.
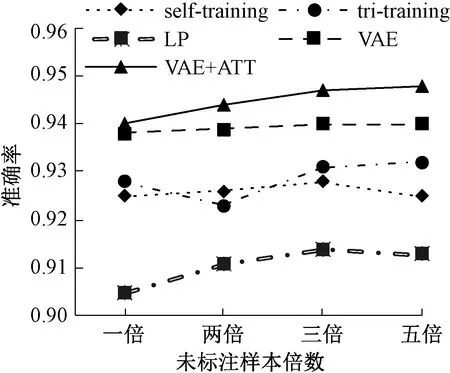
图3 不同半监督方法的准确率Fig.3 Accuracy of different semi-supervised methods
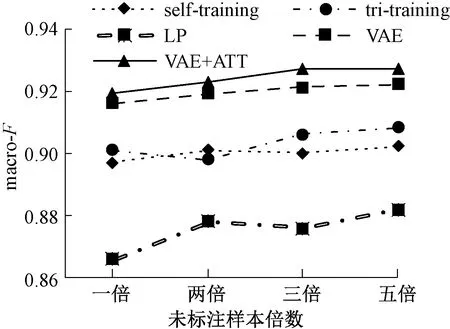
图4 不同半监督方法的macro-F值Fig.4 Macro-F of different semi-supervised methods
4.5 注意力机制以及样例分析
为了更好地理解注意力机制,并且检验注意力机制是否可以获取问题句子中的关键信息,我们对注意力权重α进行了分析.如:“不要买垃圾电脑”的注意力权值分别为:不要-0.31、买-0.22、垃圾-0.29、电脑-0.18;“大学学CAD用可以吗”的注意力权值分别为:大学-0.06、学-0.04、CAD-0.02、用-0.06、可以-0.37、吗-0.45;“手机像素怎么样”的注意力权值分别为:手机-0.19、像素-0.19、怎么样-0.62.从而我们可以看出注意力机制可以挑选出和分类较为相关的词:“可以”,“吗”以及“怎么样”这些词和“问题”这一类较为相关.“不要”以及“垃圾”这些词和“非问题”这一类较为相关.
为了理解未标注样本对于分类效果的提升,我们抽取出了样例进行分析.在全监督分类的时候,分类器将“运存不是3 g吗,怎么玩王者荣耀还这么卡”的第一个子句“运存不是3 g吗”分类为问题文本,其实这是一句强调句,并不是问题.在半监督分类时,分类器添加了“屏幕不是4 K的嘛,为啥包装盒上写的2 K”和“不是固态硬盘的吗?为什么我是机械的?”这两个未标注样本,这两个样本中的“屏幕不是4 K的嘛”和“不是固态硬盘的吗”都是强调句,通过学习这些特征,分类器可以进行正确分类.
5 结束语
本文构建了一个问题识别语料库,用于研究非正式文本的问题识别方法.在此基础上,本文提出了一种基于变分自编码器的问题识别方法.该方法结合了变分自编码器以及注意力机制,可以充分利用海量的未标注样本来提升模型性能.实验结果表明,本文提出的方法能够显著提升问题识别的性能.下一步工作中,我们将测试本文的方法在其他领域或其他语言的问题识别任务中的有效性.此外,我们将进一步修改分类器,或者采用其他深度学习的半监督方法,如生成对抗网络来提升问题识别的性能.
