基础教育课程知识图谱构建技术框架研究
2019-09-10朱晓悦杜雨雯王家若
朱晓悦 杜雨雯 王家若
【摘 要】基础教育知识图谱能体现出知识之间的联系,以可视化方式向教师与学生反馈结构化知识,进行教学支架服务,辅助学生进行知识管理和教师教与学的设计。本文从基础教育知识图谱构建的框架出發,分实体抽取和实体关系抽取两个角度研究知识图谱构建的技术路径,并生成高中数学必修二的知识图谱。
【关键词】知识图谱 实体抽取 实体关系抽取 基础教育
中图分类号:G4 文献标识码:A DOI:10.3969/j.issn.1672-0407.2019.18.007
一、绪论
(一)研究背景与意义
在课堂教学过程中,教师通过图像、视频、互动软件等多媒体教学载体的应用,教学知识的表达有了越来越多图形化、生动化的展现方式。随着大数据与机器学习的深入发展,通过数据挖掘的方式能够发现更深层次的知识联系。知识图谱就是其中一种表达方式,知识图谱是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系:实体间通过关系相互联结,构成网状的知识结构。
(二)国内研究现状
知识图谱的应用领域一般具有“新”或“热”的特征,旨在通过对目标领域的分析把握其发展态势。因此,统计并梳理知识图谱应用领域的新关键词,可以窥见我国各时间段的研究重点及整体趋势。1.研究重点。从关键词来看,我国知识图谱应用较多的是对某学科和某主题进行知识图谱分析。如学科知识图谱:王琪等以1991-2009年间与“体育”相关的博士论文为数据,深入探讨了科学知识图谱在体育学科研究中的应用前景。如主题知识图谱:王晴用CitespaceⅢ分析2015年以前的“慕课”研究相关文献,发现当前我国“慕课”研究的热点集中在技术支持、教学效果、教学活动、教学模式等问题。2.整体趋势。时代化。通过观察知识图谱应用领域的相关关键词发现,从“数据挖掘”到“云计算”再到“慕课”,知识图谱的研究对象一直紧跟时代、与时俱进。通过研读论文发现,目前中国在学科知识图谱方面的研究还是比较缺乏的,而本项目的研究内容就关注于基础教育学科的知识数据库的建立,并通过知识图谱建立一个知识框架,以作为一个学科标准对照。
二、知识图谱构建技术框架
(一)实体抽取
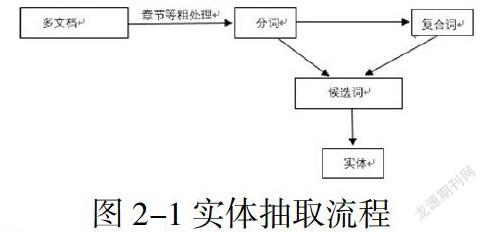
实体抽取是图谱构建中最关键的步骤,它是决定了图谱质量的关键。简单来说实体抽取就是从文本中抽取关键词,实体抽取流程大致如图2-1所示,将文本切分成独立的词,并对词进行分析(本质是聚类分析),常见方法有机器学习分析、统计分析与语义分析,由于技术水平等限制,我们采用了统计分析方式。
1.分词。分词是将连续字符串切分成词的过程,为避免漏词,本项目使用ansj分词工具中的最小颗粒度分词再进行复合词拼接,将文本中的内容切分成独立的词,并进行词性标注。同时在分词结果中进行词性过滤,考虑到汉语语法,作为关键词只保留动词相关、名词相关等词性。2.复合词拼接。需要将分割后的词拼接,以达到较高的召回率,本项目采用基于统计的规则进行拼接,主要体现在两点上:互信息与信息熵。这里简单介绍:互信息体现两个变量的相互依赖程度,常用定义如下:
其中X、Y表示相邻词语,该公式为相邻词出现的概率与作为单独词出现的概率之比的对数,数值越大则说明二者作为一个词的概率较大信息熵主要是用词语的左边界熵和右边界熵,用来判断两个词出现的顺序可能性。3.关键词抽取。在得到候选复合词之后,需要进行进一步处理得到关键词。关键词作为一篇文章中重要的词,其特点是出现频率高并且与其他文章相关度不高,综合考虑下,本项目使用简单的TF-IDF算法进行关键词抽取,TF-IDF算法用以评估某词对文档集的重要程度。计算公式如:TF-IDF=TF*IDF
(二)实体关系抽取
在提取完实体后,需要进行实体间关系的抽取。本文中,分类关系和非分类关系是两种主要的实体关系类型。分类关系中最典型的是上下位关系,它表明了上位词和下位词之间的层次关系,例如锐角与三角形。而非分类关系体现了实体之间的关联性,实体间没有层次之分,例如锐角与钝角。在获得实体间分类关系的过程中,我们利用字符串匹配法。即通过字符串匹配遍历列表中的词,提取概念之间的词串包含关系,这种概念之间的分类关系是显而易见的。在获取实体间非分类关系的过程中,本项目采用了Apriori算法。通过计算支持度(support)、置信度(confidence)和提升度,找出数据中的频繁项集,从而挖掘出数据间的关联规则。
三、结果分析
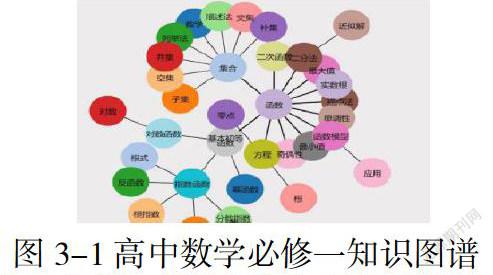
按照上述流程,采用手动+自动结合的方式,以人教版高中数学必修一为例,提取教案、课本、教材等57个纯文本文件作为语料,手动设置阈值,将最终得到的实体与实体关系通过网页D3.js展现出如下图所示结果:
由于是人工评测(实际应为由现有语料库自动评测,但限于项目人工调整阈值等因素,采用专家评估),单就实体抽取来说结果如下:抽取词共37个,实际应有实体98个,错误1个
P=97.3% R=36.7% F=53.2%
总的来看:我们过于追求准确而丢失了很多数据,导致F值有点低,且由于是人工调整阈值效率极低,需要改进方法。
参考文献
[1]刘峤等:《知识图谱构建技术综述》,《计算机研究与发展》2016年第三期.
[2]王琪,徐成立.知识图谱视野下我国体育科学研究的发展路径——基于1991~2009年体育学博士论文关键词共词网络的可视化分析[J].体育学刊,2010,17(12):118-125.
