基于深度学习的轮廓检测算法:综述
2019-09-10林川曹以隽
林川 曹以隽
摘 要:轮廓检测旨在提取图像中目标与背景环境的分界线,是计算机视觉研究领域中最基本的问题之一.深度学习技术作为直接从数据中学习特征表示的有效方法,近年来启发轮廓检测领域取得了显著的突破.鉴于此,本文就基于深度学习的轮廓检测研究领域的最新发展进行总结,具体包括:轮廓检测任务中采用的卷积神经网络结构,相关训练数据构造、特征压缩、上采样、代价函数和轮廓细化等关键问题,轮廓检测实验中采用的通用数据集和性能评价指标.最后,分析了基于深度学习的轮廓检测算法的挑战和未来研究趋势,以期为该领域的后续研究提供新思路及参考.
关键词:深度学习;卷积神经网络;计算机视觉;轮廓检测
中图分类号:TP391.4 DOI:10.16375/j.cnki.cn45-1395/t.2019.02.001
0 引言
目标轮廓在人类视觉系统中起着重要作用.临床医学证据表明,当负责轮廓感知的大脑视觉皮层V1和V2区受损,会导致患者完全无法识别物体[1].在目标识别、目标检测、机器人视觉和医学图像分析等计算机视觉的工程应用上,需要或依赖一个性能优秀轮廓检测算法作为前置.因此,为轮廓检测建立计算模型不仅有助于工程技术的发展,且能够启发认知科学和神经科学在初级视觉皮层的基础研究.
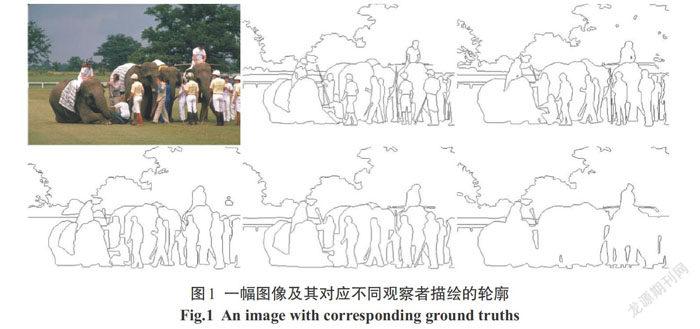
在计算机视觉任务中,轮廓的意义更倾向于人类经验上的概念而不是一个纯粹的数学定义.每个人对于同目标图像轮廓的理解和定义不尽相同,如图1中所示的不同观察者描绘的轮廓.由于人类判断是唯一可以用来说明给定视觉特征是否是轮廓的标准,那么可以认为图像中的轮廓是人类观察者对描述物体分界有意义的线条集合[2].
早期的轮廓提取研究主要致力于目标的边缘检测,其核心思路通常是基于局部梯度算子的计算. Prewitt[3]通过构造水平和垂直的局部梯度滤波器对灰度图像的卷积计算检测边缘.随后,Canny[4]提出了边缘检测的一个完整框架:首先,引入高斯滤波作为預处理以提取多个尺度下的图像表示;然后,使用局部梯度算子提取轮廓图;最后,使用非极大值抑制算法和双阈值算法对边缘图像进行细化和二值化.
为了更好整合图像整体和局部信息,一部分学者探索使用机器学习手段,把轮廓检测任务看作是一个像素级的二分类任务,通过提取图像的局部特征对像素进行分类.Martin等[5]提出了Pb算法,该方法提取了亮度(BG),颜色(CG)和纹理(TG)通道特征,并将这些局部特征作为目标像素点的分类特征,采样逻辑回归算法对像素分类.为了充分利用全局视觉信息,Arbelaez等[6]提出了一种全局Pb(global Pb,gPb)算法,该算法在多尺度Pb算法的基础上通过计算全局图像谱特征给予每个像素一个全局的概率.Arbelaez等[7]随后提出多尺度分组算法(MCG),通过构造图像高斯金字塔,提取不同尺度下轮廓特征来识别轮廓.另一部分学者模拟初级视觉皮层细胞对视野中特定区域的刺激响应,提出了生物启发性的轮廓检测方法[8- 9].这类算法通过模拟人类视觉系统中的视觉信息通路,以神经生物学和生理学的发现为依据,通过对视网膜[8-11],外膝体[12]到初级视觉皮层[8, 13-15]细胞的空间特性模拟,提出轮廓检测的计算模型.
上述算法需要相当多的领域专业知识和精细的处理算法设计,把原始图像数据转换成合适的表示或者特征向量,来构造一个轮廓分类器或者轮廓模型.近几年来,深度学习技术[16-17]已经成为从原始数据中自动学习特征表示的高效方法.借助深度学习工具,尤其是卷积神经网络(Convolutional Neural Networks, CNNs),轮廓检测任务有显著的性能提高.如图2所示,在伯克利分割数据集中 (BSDS500),深度学习(实线)中得分最高的算法(F=0.815)比非深度学习(虚线)中得分最高的算法(F=0.744)在性能上高9.5%,且超过了人眼视觉的平均水平(F=0.803).尽管如此,轮廓检测任务依旧是一个有挑战性的任务,原因在于:
1)轮廓的高精确性问题.定性和定量结果都表明,基于CNNs的轮廓图在标准容忍度的匹配条件下,是高度“正确的”,而不是那么“精确的”[18].究其原因,是由于在CNNs的架构下逐层的池化处理,使更具抽象辨别力的网络顶层中特征的空间分辨率显著降低,导致输出的边缘图未能很好地定位.另外一个原因是,反卷积结构在上采样过程中鼓励相邻像素的响应相似,导致无法产生精确的轮廓图.
2)轮廓检测的高效性问题.现有基于CNNs的轮廓检测模型大多构造一个大型的网络来提高轮廓的性能.然而,作为一个中低层的计算机视觉任务,轮廓检测的效率直接影响到后续顶层任务的处理速度.因此,如何在保证性能的同时,简化网络参数也是一个关键问题.
3)数据集规模及其场景选取问题.比如在BSDS500数据集中,图像的大小为481×321像素,图片则大多取自人物和动物的小范围场景.然而,在更有挑战性的大规模场景和大规模图像数据集中,算法的性能依旧有很大的提高空间.
1 基于深度学习的轮廓检测算法
深度学习技术非常擅于发现高维数据中错综复杂的潜在结构,在计算机科学的研究中得到了广泛的应用.除了在图像识别[17, 19-22]和语音识别[23]中的纪录外,还在各种计算机视觉任务中取得了突破,例如轮廓检测[18, 24-31],显著性检测[32],目标检测[33-35],语义分割[36-40]和实例分割[41-42].除了计算机视觉任务外,深度学习在自然语言理解的各种任务中得到了了非常有启发性的结果,特别是主题分类,情感分析,问答系统[43]和语言翻译[44].
作为深度学习中最契合视觉任务的算法,卷积神经网络(CNNs)在多个计算机视觉任务中取得了突破性的进展.图3列出了CNNs网络结构发展的几个关键节点(时间轴下方),和基于CNNs的轮廓检测算法的时间节点(时间轴上方).其中,以HED[27]为分界点,基于深度学习的轮廓检测算法可以被分为两个阶段:基于局部区域的轮廓检测算法和基于全局端到端的轮廓检测算法.
1.1 基于局部区域的轮廓检测算法
在基于局部区域的轮廓检测算法中,CNNs被视为局部图像块的特征提取器.如图4所示,N4-field[24]、DeepContour[26]和DeepEdge[25]三种基于局部区域的算法核心步骤如下:1)以像素为中心提取大小相等的图像块;2)通过预训练后的CNNs提取图像块中的特征;3)通过提取到的特征和手工标注的真实轮廓比较,获得该图像块对应像素的轮廓概率.上述算法的区别在于:
N4-field:受到CNNs在ImageNet数据集[45]中图像识别任务上突破性进展的启发.Ganin等结合AlexNet[17]和最邻近搜索,提出了第一个基于CNNs的轮廓检测算法.如图4所示,该算法分为以下几个步骤: N×N大小的局部区域提取;对于每一个区域,通过预训练的CNNs提取出1×M维的特征向量;使用最邻近搜索算法寻找字典中该特征向量对应的真实轮廓图;对所有输出重叠的局部图像区域求平均获得最后的轮廓输出.在上述步骤中,难点在于CNN的训练和字典的构造.对于CNN的训练,N4-field随机采用局部自然图像和经过使用主成份分析(PCA)[46]算法降维后的局部真实轮廓图像作为训练数据,用以训练CNN网络.特别地,该算法使用大量随机采样真实轮廓及其降维后的特征向量,构造特征向量到局部轮廓图的字典.
DeepContour:Shen等[26]结合了N4-field和Sketch tokens算法[47]的优势提出了DeepContour.DeepContour相比于N4-field有如下改进:1)把最后的最邻近匹配过程看作一个多分类问题,提出了一个新的代价函数;2)通过K-means算法,大量随机采样真实轮廓图的局部区域,训练得到轮廓的中层特征表达,来代替原始的轮廓底层表达.
DeepEdge:在早期基于机器学习的轮廓检测算法中,由于传统的特征提取算法很难充分发掘图像的局部特征结构,轮廓检测一般被看作一个分类问题.然而,借助CNN的特征自动学习能力,Bertasius等[25]提出DeepEdge,把轮廓识别任务看作一个分类和回归问题的综合体.在算法结构上,用局部图像的多尺度采样获取图片的多尺度信息,以卷积层和第一层全连接层为共享特征,添加分类分支和回归分支,最后计算分类结果和回归结果作为最后的轮廓输出.
上述算法借助CNN的学习能力取得了良好的轮廓检测性能,但该类基于局部区域的方法存在几个显著的缺陷:
1)高计算成本.CNN由于其结构特点非常适用于并行计算,在现代计算机体系中,CNN通常使用GPU而不是CPU来加速计算(GPU通常比CPU在计算时间上少一到两个数量级).然而,基于局部区域的方法在采样(CPU),CNN特征提取或分类(GPU),字典构造或匹配(CPU)上频繁的数据交换使得该类算法的计算成本很高.另外,大部分移动设备的存储和计算能力有限,就更难以承受如此高的计算时间或空间成本.
2)高测试成本.在基于局部区域的方法中,如果出现性能或轮廓效果不佳的情况,很难判定算法产生瓶颈的原因.在设计算法和测试的过程中,是采样窗口问题、CNN特征提取或CNN结构设计问题,还是字典构造问题需要逐个调试或测试.
1.2 基于全局端到端的轮廓检测算法
由于基于局部区域的轮廓检测算法存在上节提到的两个缺陷,学者们更倾向开发统一的轮廓检测策略.需要说明的是,本文所提的基于全局端到端的轮廓检测算法,主要是采用CNN结构直接预测图像中每个像素是否是轮廓的概率,而不涉及局部采样和后续匹配.这类方法简单、高效且能充分发挥CNN的学习能力从而提高轮廓检测的精确度.由于整个检测过程采用单个网络,因此可以直接在检测性能上实现端到端的优化.图5给出的几种基于全局端到端的轮廓检测算法,主要是直接使用单个CNN做全局的特征学习,通过特征层的压缩和上采样解码出原始分辨率的轮廓图.
HED:受到全卷积神经网络(Fully convolutional networks,FCN)[36]算法的启发,Xie等[27]在2015年提出了第一个端到端的轮廓检测算法Holistically-Nested Edge Detection(HED).该算法相比较于基于局部区域的轮廓检测算法,通过一个更大规模的CNN提取图像的全局特征,通过上采样算法还原原始图像的分辨率.整个网络可以通过反向传播算法直接训练,极大地提高了实用性同时降低了计算和测试成本.具体地,HED算法的网络结构分为编码和解码网络:
编码网络:该算法中编码网络的任务与一般的CNN类似,主要是图像的特征提取;与AlexNet[17]网络相比去掉了全连接层,而仅仅保留卷积层,降低了网络参数的同时还对后续解码网络中图像原始分辨率重建有积极的意义.
解码网络:由于CNN结构上的特殊性,尤其是逐层的池化会降低图像在高层的分辨率,因此,还原出原始分辨率的图像就是解码网络的关键任务. HED网络的上采样使用传统的双线性插值算法,在上采样前,特征图像通过一個卷积核为1×1大小的卷积层压缩到单通道,而在最后则通过算法融合每一个分辨率的特征作为结果输出.
RCF:Liu等[30]以HED网络为基础,提出了RCF网络.该网络在HED的基础上(相同分辨率的特征图下仅仅最后一个卷积层进入解码网络),对于相同分辨率的每一个卷积层都进行特征压缩,从而更大幅度地提高地网络的特征表达能力.在几乎没有提高时间和空间计算成本的同时,大幅度提高了轮廓检测的性能.
CEDN:相比较于HED网络,Yang等[29]提出了CEDN网络,该网络创新的通过特征的逐层解码来构造解码网络.尽管网络参数数量要远多于HED,但该逐层解码的方法能更细致的重建上采样过程中丢失的细节信息,且在大规模的图像数据集PASCAL VOC 2012中取得了远高于HED的性能表现.
CED:Wang等[18]在线性的编码-解码结构[29]的基础上提出了CED网络,该网络增加了额外的残差连接以保证解码结果能尽可能的综合图像编码的全部特征.相比较于HED和CEND,该算法在轮廓的精度上有很大提高.
COB: Maninis等[48]在COB网络中,以HED结构为基础,研究出了3种不同类型的轮廓图:高尺度(粗糙的)的轮廓图、低尺度(精细的)轮廓图和多方向的轮廓图.通过多尺度UCM算法[6]得到输出结果.
综合上述算法来看,基于全局端到端的轮廓检测算法的改进集中在解码网络部分,主要通过对网络的研究,从各方面探索解码网络对轮廓检测性能的影响,主要包括对特征图的直接解码[27,30],构造逐层的解码网络[18, 29]和提取编码特征中不同的信息[48].
2 关键问题
在基于深度学习的轮廓检测任务中,除了主体网络构造外,还有一些能直接影响检测效果的关键问题需要研究.本文从数据扩展、模型细节、代价函数以及轮廓细化这4个方面来描述构造一个完整的轮廓检测算法需要的重要部分.需要注意的是,本节做的描述仅仅以该领域最流行的算法为基准,而不涉及其研究历史和趋势.
2.1 数据扩展
深度学习模型往往需要大规模的数据训练模型权重,而由于带标注的数据集收集和创建困难,现有的大多数数据集往往缺乏大规模的样本,因此通过算法在一定程度上扩展数据也是该领域研究的重要问题,主要是在不损坏图像原有结构的基础上,用随机局部区域剪切、随机方向旋转、随机比例图像缩放、随机因子的亮度、对比度变换等方式为图像添加椒盐噪声.几种典型的数据扩展方法及其扩展后的效果如图6所示,在进行数据扩展后,每一幅原始图像都能产生相当多的训练数据,从而在一定程度上提高网络的泛化能力.
2.2 模型细节
本小节从模型预训练、卷积的特征压缩、上采样3个部分来描述在轮廓检测任务中需要注意的模型细节.
模型预训练:基于全局端到端的轮廓检测算法通常包含图5所示的编码网络,这些编码网络大多取自图像识别任务中的网络模型,例如VGGNet[19]或ResNet[20]等图3中时间轴下方的网络.在使用这些网络结构时,利用网络在超大规模图像数据集ImageNet上训练好的权重来初始化目标任务的网络权重,这类方法即为模型的预训练,预训练步骤能在一定程度上提高网络训练的收敛速度和预测的泛化能力.
卷积特征压缩:在CNN的多层结构中,卷积层可以用来提取特征且进行特征通道的扩展,而对于轮廓检测任务而言,由于期望输出为单通道的灰度轮廓图,并没有包含过多的通道数,所以需要特定的结构来做特征通道的压缩,比如使用卷积核为1×1的卷积层来压缩特征通道.1×1的卷积核能捕获单个像素位置上所有通道的信息,相比于一般的3×3的卷积核,1×1的卷积核在特征压缩的同时能极大的减少模型参数从而提高训练速度.
上采样:由于CNN的结构特性,图像经过不断池化的处理后,会得到更抽象但是分辨率也更低的高层特征表达.为了构造端到端的学习模型,需要构造以上采样为核心的解码网络.在解码网络中,常用的上采样算法被分为两类:非参数化方法和参数化方法.非参数化方法为传统的插值算法,包括双线性插值,双三次插值等;参数化方法指的是算法参数是可以通过端到端的网络训练得到而不是手工设计,常用的有反卷积算法[37]和亚像素卷积[49]算法.在实际应用中,参数化的算法效果在大规模训练数据的帮助下略优于非参数化算法,但從时间和效率的权衡来考虑,目前基于CNN的轮廓检测算法中大多使用非参数化方法中的双线性插值算法作为上采样方法.
2.3 代价函数
作为一个像素级二分类任务,轮廓检测有着其独特的难点:训练样本类别数分布极不均衡.在轮廓图中,图像的轮廓-背景像素比很小,大约在0.05~0.10的范围内.这意味着在训练样本中大约90%~95%的样本都是背景而只有5%~10%的样本是轮廓,这种情况会导致采用反向传播算法更新模型变量时,梯度会沿着样本数量多的部分偏离,在大多情况下导致模型的训练集收敛后,检测出来的全是背景像素.因此,解决样本数量不平衡对CNNs的框架下训练的影响也是该领域研究的一个重要分支.
在早前基于局部区域的方法中,由于仅仅选取一个图像块,使得传统的交叉熵代价函数能够有效的训练网络.然而在端对端的轮廓检测任务中,样本不均衡的问题严重阻碍了网络的训练.因此,在使用传统交叉熵的基础上,Xie等[27]在HED模型中提出了一个有效的代价函数来解决样本不均衡的问题,通过统计每一个训练批次中正负样本数量和其比例,动态地计算一个加权系数平衡正负样本间的比重,以此解决样本分布不均衡的问题.
其中,x、y分别表示训练的输入图像和输入标签;P(x)为sigmoid函数,β为对应正负样本加权具体为 β=| Y-|/|Y|,这里|Y-|和|Y|分别表示图像中所有标注轮廓点的个数和图片中所有像素的个数.在训练过程中,标注的轮廓和背景像素通过统计当前批次的正负样本比例,计算不同的加权以保证在轮廓图样本分布不平衡时的有效训练.
随后,Liu等[30]在RCF网络的工作中改进了这个代价函数.首先,在多人标注问题上,对于少于一定阈值的某个像素点,阻塞其梯度传播.其次,使用一个额外参数,在正负样本比例的基础上加权,具体公式如下
其中,α = γ(1-β), γ是在HED代价函数中正负样本比例的基础上的一个加权.式(2)通过阻塞多人标注样本中小于η的值,在实际训练中会使得代价波动更加平稳.
综上,研究者在以交叉熵为主体的代价函数改进中,针对样本不均衡的问题,提出了各自的解决方法.其中,HED网络使用了不同的正负样本加权以保证在轮廓图样本分布不平衡时的有效训练.针对多人标注中轮廓在局部混乱的问题,RCF网络在HED网络的基础上,通过阻塞一部分人数较少的标注,提高了多人标注训练中的稳定性.
2.4 轮廓细化
轮廓细化作为标准后续处理的关键步骤,主要目的是使输出轮廓图仅仅保留单像素边缘.目前轮廓细化算法有非极大值抑制[4]和形态学细化[50].如图7所示,模型输出的轮廓图是一幅很“粗”的轮廓图,而细化后的轮廓图仅仅保留了最优方向上的单像素边缘,有利于算法性能评估.
3 数据集和评价指标
3.1 数据集
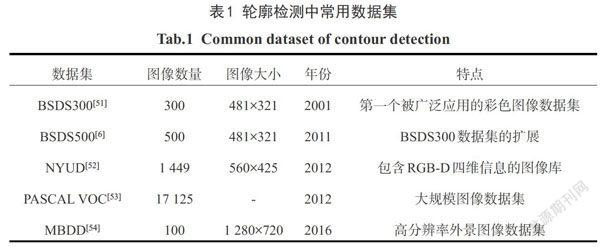
数据集在整个轮廓检测研究中发挥了关键作用,是该领域取得重大进展的最重要因素之一.表1总结了目前流行的数据集的简要信息和特点.
BSDS[6]为伯克利图像分割数据集,从早期BSDS第一个版本BSDS300[51]开始就是轮廓检测领域最流行的数据集,最新的BSDS500版本[6]包含200张训练图片,200张测试图片和100张验证图片,每一幅图都有对应的5~10幅手工标注的真实轮廓.NYUD[52]主要包含室内场景图像.每幅图片除了RGB三个颜色通道信息外,还包含场景深度信息.Gupta等[55-56]在数据集仅仅提供原始分割标注的基础上,为数据集在轮廓检测任务中的推广做了关键的工作:1)把数据集分为381幅训练图像,654幅测试图像和414 幅验证图像;2)使用HHA编码(H——水平视差,H——对地高度和A——表面法向量的角度)把原始深度信息转换成可视化的三通道表示;3)以数据集给定的语义分割标注为基准,构造了一个有效的图像轮廓标注集.PASCAL VOC 数据集[53]是著名的图像检测和图像分割数据集,且在2012年发布了最新版本.在该数据集中,Yang等[29]使用密集的条件随机场算法构造了一个有效的轮廓标注集,使得该数据集能被使用于轮廓检测的性能评价中.MBDD[54]为多尺度轮廓检测数据集.虽然仅仅包含100张图片,但每一幅图有高达720p的分辨率,对于现有的轮廓检测算法而言依旧是一个挑战.同时MBDD数据集包含两种不同类型的轮廓标注,分别为注重大尺度物体间分界的“轮廓(boundary)”分支,和注重精细边界的“边缘(edge)”分支.
3.2 评价指标
一个良好的评价指标是模型公平比较的重要保证,本节将介绍轮廓检测任务中最普遍的评价指标.该指标通过结合信息检索社区常用的精确-回归(Precision-Recall,P-R)曲线,由Martin等[5]在2004年完善且推广到多标注的真实轮廓的性能评价体系中.定量的指标由模型的最优精确度和回归度确定:[F=(PR)/[(1-α)P+αR]],其中α為权重,一般取0.5.P和R分别代表精确度和回归度,具体地,P = TP/( TP + FP);R = TP/(TP + FN),这里 TP,FP和FN分别代表轮廓像素的正确检测个数,错误检测个数和遗漏检测个数.
为了公平的比较模型的泛化能力,在F值的测量标准下,一般使用3个定量的指标去评价模型优劣:1)对于给定的阈值T,整个数据集将会得到一个平均的最优F值,被称作最优的数据集尺度(optimal dataset scale,ODS);2)数据集中每一幅图像都单独给定一个最优阈值T,综合后的最优F值被称作最优的图像尺度(optimal image scale,OIS);3)在给定一个阈值范围下t =[0 ,1.0],数据集的平均精度(average precision,AP).此外,在不同的阈值条件下t =[0,1.0],整个数据集精确度P和回归度R可以被描述成P-R曲线,例如图2所示.
3.3 性能趋势
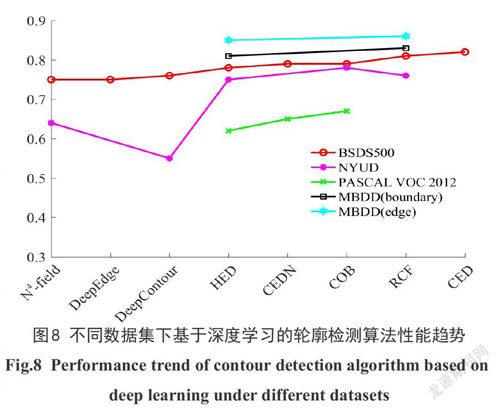
近几年基于深度学习的轮廓检测算法在BSDS、NYUD、PASCAL VOC和MBDD上的性能趋势如图8所示,表2总结了轮廓检测算法在不同数据集下的定量性能和增长率(该数据集下性能最低到最高的模型).首个基于深度学习的轮廓检测模型提出后,通过两年时间的研究,算法在BSDS上的性能从N4-field的0.75提高到CED的0.816,提高了8.8%,并且开始更多的使用高分辨率(NYUD和MBDD)和大规模(PASCAL VOC)的图像数据集,且取得了较好的效果.
如果以BSDS500数据集的性能表现为基准,基于深度学习的轮廓检测算法在PASCAL VOC图像数据集中的性能表现要远低于平均水平,原因在于该数据集中图片的选取范围广、场景复杂多变且目标物体繁多.这也是轮廓检测算法在更大规模的数据集和真实的场景中的必然挑战,也是进一步的研究要攻克的难点之一.
4 研究趋势
本节从3个方面讨论基于深度学习的轮廓检测算法的难点,和其潜在的研究方向:1)在监督学习下提高轮廓检测的精细度;2)在更弱的条件下(半监督或弱监督)轮廓检测的性能;3)轮廓检测算法对其他计算机视觉任务的促进(目标检测,语义分割或场景重建等).
在监督学习条件下,提高大规模图像数据集的轮廓检测性能和提高轮廓检测算法精细度是目前研究的难点和热点.问题的研究关键在于编码网络,解码网络和代价函数设计.在编码网络方面,现有模型大多基于VGGNet,而在更复杂的ResNet和DenseNet的基础上设计更加复杂的编码网络使得模型特征提取更加充分,对轮廓的表达能力更强,以此调高模型的泛化能力是当前研究的热点.研究解码网络使得算法尽可能保留图像细致的特征信息来预测边缘输出,提高在更严格的限制条件下的轮廓提取性能,是当前轮廓检测任务中的难点.在代价函数方面,改进现有的代价函数,使得轮廓检测性能在精确度和覆盖率平衡的基础上,对多人标注的真实轮廓融合问题是未来可进一步研究的方向.
在半监督(有标注样本稀少)或弱监督(标注不完整)条件下,现有的轮廓检测模型该如何保持监督学习下的性能,还鲜有研究人员探索.尽管如此,轮廓检测的半监督和弱监督学习可以借鉴语义分割和实例分割[57]在该方向的经验,探索关于轮廓检测的模型.
轮廓作为视觉的底层任务,能有效地作为一些实用任务提升性能,在目标检测[7]、超分辨率处理[58]和实例分割[59]等任务中,轮廓约束均被证实能有效的提高其目标任务的性能.因此,如何利用一个好的轮廓图提高其他计算机视觉任务的性能也是一个潜在的研究热点.
5 结论
随着深度学习的发展,大多数计算机视觉和图像处理任务都利用了深度学习强大的特征学习能力,从而在很短的时间内大幅度地提高了任务在不同数据集下的性能指标.本文以轮廓检测算法为核心,对目前基于深度学习的轮廓检测算法进行了系统的总结、对比和分析.同时对基于深度学习的轮廓检测任务的研究趋势进行了展望,以期为基于深度学习的轮廓检测研究提供有效参考.
参考文献
[1] ZEKI S. A vision of the brain[M]. Oxford:Blackwell Scientific Publications,1993.
[2] PAPARI G,PETKOV N. Edge and line oriented contour detection: state of the art[J]. Image and Vision Computing,2011,29(2):79-103.
[3] PREWITT J M. Object enhancement and extraction[J]. Picture Processing and Psychopictorics,1970,10(1):15-19.
[4] CANNY J. A computational approach to edge detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,1986(6):679-698.
[5] MARTIN D R,FOWLKES C C,MALIK J. Learning to detect natural image boundaries using local brightness,color,and texture cues[J]. IEEE Transactions on Pattern Analysis and Machine Intelligenc, 2004,26(5):530-549.
[6] ARBELAEZ P,MAIRE M,FOWLKES C,et al. Contour detection and hierarchical image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(5):898-916.
[7] ARBEL?EZ P,PONT-TUSET J,BARRON J T,et al. Multiscale combinatorial grouping[C]. IEEE Conference on Computer Vision and Pattern Recognition,2014:328-335.
[8] GRIGORESCU C,PETKOV N,WESTENBERG M A. Contour detection based on nonclassical receptive field inhibition[J]. IEEE Transactions on Image Processing,2003,12(7):729-739.
[9] YANG K,GAO S,LI ETAL C. Efficient color boundary detection with color-opponent mechanisms[C]. IEEE Conference on Computer Vision and Pattern Recognition,IEEE,2013:2810-2817.
[10] YANG K F,GAO S B,GUO C F,et al. Boundary detection using double-opponency and spatial sparseness constraint[J]. IEEE Transactions on Image Processing,2015,24(8):2565-2578.
[11] 趙浩钧,林川,陈海杰,等. 基于颜色拮抗和纹理抑制的轮廓检测模型[J]. 广西科技大学学报,2018,29(4):6-12.
[12] AZZOPARDI G,RODRIGUEZ-SANCHEZ A,PIATER J,et al. A push-pull CORF model of a simple cell with antiphase inhibition improves SNR and contour detection[J]. PLoS One,2014,9(7): e98424.
[13] ZENG C,LI Y,LI C. Center–surround interaction with adaptive inhibition: a computational model for contour detection[J]. NeuroImage,2011,55(1):49-66.
[14] AKBARINIA A,PARRAGA C A. Feedback and surround modulated boundary detection[J]. International Journal of Computer Vision,2018,126(12):1367-1380.
[15] 潘亦堅,林川,郭越,等. 基于非经典感受野动态特性的轮廓检测模型[J]. 广西科技大学学报,2018,29(2):77-83.
[16] LECUN Y,BOTTOU L,BENGIO Y,et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE,1998,86(11):2278-2324.
[17] KRIZHEVSKY A,SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[C]. Advances in Neural Information Processing Aystems,2012:1097-1105.
[18] WANG Y,ZHAO X,HUANG K. Deep crisp boundaries[C]. IEEE Conference on Computer Vision and Pattern Recognition,2017:3892-3900.
[19] SIMONYAN K,ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. International Conference on Representation Learning,2015.
[20] HE K,ZHANG X,REN S,et al. Deep residual learning for image recognition[C]. IEEE Conference on Computer Vision and Pattern Recognition,2016:770-778.
[21] SZEGEDY C,LIU W,JIA Y,et al. Going deeper with convolutions[C]. IEEE Conference on Computer Vision and Pattern Recognition,2015:1-9.
[22] HUANG G,LIU Z,VAN DER MAATEN L,et al. Densely connected convolutional networks[C].IEEE Conference on Computer Vision and Pattern Recognition,2017:3.
[23] HINTON G,DENG L,YU D,et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. IEEE Signal Processing Magazine,2012,29(6):82-97.
[24] GANIN Y,LEMPITSKY V. N4-fields: neural network nearest neighbor fields for image transforms[C].Asian Conference on Computer Vision,Springer,2014:536-551.
[25] BERTASIUS G,SHI J,TORRESANI L. Deepedge: a multi-scale bifurcated deep network for top-down contour detection[C].IEEE Conference on Computer Vision and Pattern Recognition,2015:4380-4389.
[26] SHEN W,WANG X,WANG Y,et al. Deepcontour: a deep convolutional feature learned by positive-sharing loss for contour detection[C].IEEE Conference on Computer Vision and Pattern Recognition,2015:3982-3991.
[27] XIE S,TU Z. Holistically-nested edge detection[C].International Comference on Computer Vision,2015:1395-1403.
[28] KOKKINOS I. Pushing the boundaries of boundary detection using deep learning[C].International Conference on Representation Learning,2016.
[29] YANG J,PRICE B,COHEN S,et al. Object contour detection with a fully convolutional encoder-decoder network[C].IEEE Conference on Computer Vision and Pattern Recognition,IEEE,2016:193-202.
[30] LIU Y,CHENG M M,HU X,et al. Richer convolutional features for edge detection[C].IEEE Conference on Computer Vision and Pattern Recognition,IEEE,2017:5872-5881.
[31] MANINIS K K,PONT-TUSET J,ARBEL?EZ P,et al. Convolutional oriented boundaries: from image segmentation to high-level tasks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,27:1676-1688.
[32] LI G,YU Y. Visual saliency based on multiscale deep features[C].IEEE Conference on Computer Vision and Pattern Recognition,2015:5455-5463.
[33] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C].IEEE Conference on Computer Vision and Pattern Recognition,2014:580-587.
[34] GIRSHICK R. Fast r-cnn[C].International Comference on Computer Vision,2015:1440-1448.
[35] REN S,HE K,GIRSHICK R,et al. Faster r-cnn: towards real-time object detection with region proposal networks[C].Advances in Neural Information Processing Aystems,2015:91-99.
[36] LONG J,SHELHAMER E,DARRELL T. Fully convolutional networks for semantic segmentation[C].IEEE Conference on Computer Vision and Pattern Recognition,2015:3431-3440.
[37] NOH H,HONG S,HAN B. Learning deconvolution network for semantic segmentation[C].IEEE Conference on Computer Vision and Pattern Recognition,2015:1520-1528.
[38] PINHEIRO P O,LIN T Y,COLLOBERT R,et al. Learning to refine object segments[C].International Journal of Computer Vision,Springer,2016:75-91.
[39] CHEN L C,PAPANDREOU G,KOKKINOS I,et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2017.
[40] LIN G,MILAN A,SHEN C,et al. Refinenet: multi-path refinement networks for high-resolution semantic segmentation[C].IEEE Conference on Computer Vision and Pattern Recognition,2017.
[41] ROMERA-PAREDES B,TORR P H S. Recurrent instance segmentation[C]. European Conference on Computer Vision,Springer,2016:312-329.
[42] REN M,ZEMEL R S. End-to-end instance segmentation with recurrent attention[C]. Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),Honolulu,HI,USA,2017: 21-26.
[43] BORDES A,CHOPRA S,WESTON J. Question answering with subgraph embeddings[J]. ArXiv Preprint ArXiv:1406.3676,2014.
[44] SUTSKEVER I,VINYALS O,LE Q V. Sequence to sequence learning with neural networks[C]. Advances in Neural Information Processing Aystems,2014:3104-3112.
[45] DENG J,DONG W,SOCHER R,et al. Imagenet: a large-scale hierarchical image database[C].IEEE Conference on Computer Vision and Pattern Recognition,Ieee,2009:248-255.
[46] WOLD S,ESBENSEN K,GELADI P. Principal component analysis[J]. Chemometrics and intelligent laboratory systems,1987,2(1-3):37-52.
[47] LIM J J,ZITNICK C L,DOLL?R P. Sketch tokens: a learned mid-level representation for contour and object detection[C].IEEE Conference on Computer Vision and Pattern Recognition,2013:3158-3165.
[48] MANINIS K K,PONT-TUSET J,ARBEL?EZ P,et al. Convolutional oriented boundaries[C]. European Conference on Computer Vision,Springer,2016:580-596.
[49] LEDIG C,THEIS L,HUSZ?R F,et al. Photo-realistic single image super-resolution using a generative adversarial network[J]. ArXiv Preprint ArXiv:1609.04802,2016.
[50] 岡萨雷斯,伍兹. 数字图象处理[M]. 3版.阮秋琦,阮宇智,译.北京:电子工业出版社, 2017.
[51] MARTIN D,FOWLKES C,TAL D,et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics[C]. International Comference on Computer Vision,IEEE,2001:416-423.
[52] SILBERMAN N,HOIEM D,KOHLI P,et al. Indoor segmentation and support inference from rgbd images[C]. International Journal of Computer Vision,Springer,2012:746-760.
[53] EVERINGHAM M,ESLAMI S A,VAN GOOL L,et al. The pascal visual object classes challenge: a retrospective[J]. International Journal of Computer Vision,2015,111(1):98-136.
[54] M?LY D A,KIM J,MCGILL M,et al. A systematic comparison between visual cues for boundary detection[J]. Vision research,2016,120:93-107.
[55] GUPTA S,ARBELAEZ P,MALIK J. Perceptual organization and recognition of indoor scenes from RGB-D images[C]. IEEE Conference on Computer Vision and Pattern Recognition,IEEE,2013:564-571.
[56] GUPTA S,GIRSHICK R,ARBEL?EZ P,et al. Learning rich features from RGB-D images for object detection and segmentation[C]. International Journal of Computer Vision,Springer,2014:345-360.
[57] ZHOU Y,ZHU Y,YE Q,et al. Weakly supervised instance segmentation using class peak response[J]. ArXiv Preprint ArXiv:1804.00880,2018.
[58] LEE S H,JANG W D,KIM C S. Contour-constrained superpixels for image and video processing[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017:2443-2451.
[59] KIRILLOV A,LEVINKOV E,ANDRES B,et al. Instancecut: from edges to instances with multicut[C]. IEEE Conference on Computer Vision and Pattern Recognition,2017:9.
Deep learning for contour detection: a survey
LIN Chuan, CAO Yijun
(School of Electric and Information Engineering, Guangxi University of Science and Technology,
Liuzhou 545006, China)
Abstract: Contour detection is designed to extract the boundary between the target and the background in the image, and is one of the most basic problems in the field of computer vision research. In recent years, deep learning technology, as an effective method to learn feature representation directly from data, has made a significant breakthrough in the field of contour detection. In view of this, this paper summarizes the latest developments in the field of contour detection based on deep learning, including the convolutional neural network structure in contour detection tasks; some key issues related to contour detection, including training data construction, feature compression, up sampling, cost function and contour thinning; general data sets and performance evaluation indicators. Finally, the challenges and future research trends of contour detection algorithms based on deep learning are analyzed, in order to provide new ideas and references for the follow-up research in this field.
Key words: deep learning; convolutional neural network; computer vision; contour detection
