基于离群点检测的电类实验教学中错误数据判决算法
2019-09-03申赞伟张士文
申赞伟, 李 丹, 张士文, 张 峰
(上海交通大学 电子信息与电气工程学院,上海 200240)
0 引 言
实验教学作为高校教学内容的重要组成部分,在培养学生的动手能力和实践创新能力方面发挥着不可替代的作用[1-2]。电类实验课程是高校中许多工科专业的必修课程。以上海交通大学为例,在“工科大平台”的本科生培养模式下,电类实验课程不仅是电信学院学生的必修课,而且是船建、材料、机动等学院学生的必修课,覆盖面广。上海交通大学电工电子实验教学中心作为电类实验课程教学任务的承担者,以2018年为例,全年实验教学的授课总学时为13.31万人时,教学任务繁重;另一方面,电工电子实验教学中心还存在着实验教学人员短缺的问题。全国高校也普遍存在着实验技术人员短缺、实验教学任务繁重的问题[3-4]。电类实验教学的主要组织形式是:在给定电路元器件参数的条件下,学生按照规定的方法和步骤连接电路,并使用仪器仪表测量读取数据,通过对实验测量所得数据的分析,加深对理论知识的理解。在目前的电类实验教学中,评判学生所测实验数据的工作,需要大量人力,而且人工评判数据还存在准确度不高、临界数据难以评判等缺点。尤其是近年来随着在线教育方式(例如MOOC)在实验教学中的普及,实验教学更是突破了传统教学模式在时间和空间上的限制,具有很强的灵活性[5],覆盖学生数量进一步增加,“互联网+教育”的实验教学模式同时为实验数据的智能评判提供了良好的基础与载体。
为解决目前高校普遍存在的实验技术人员短缺、实验教学任务繁重的问题,同时也为了满足实验教学的在线教学模式的智能化需求,迫切需要一种实验数据的智能评判方法,以快速、智能并准确地识别出学生在实验中测量错误的数据。离群点检测是把数据集合中行为、模式明显与其他大多数数据不同的数据点检测出来。在验证性电类实验课程中,由于实验仪器、实验参数等条件是统一的,所以学生所测的数据中的离群点往往就是意味着测量有误的数据。因此,离群点检测的思想,可以实现对测量错误的实验数据的智能识别。
在相关离群点检测算法研究中,Knorr等[6]从距离的概念出发,提出了离群点检测算法,并给出了离群点的定义,即与大多数的数据点距离大于某一特定值的点称为离群点,并给出了基于索引(Index-based)、基于网格(Cell-based)和嵌套循环(Nested Loop)3种离群点检测算法。Ramaswamy等[7]提出了k-最近邻(K-Nearest Neighbor,KNN)的离群点检测算法,将数据集中的每个数据点p的k近邻的距离量Dk(p)按从大到小的顺序排列,排在前m位的数据点为离群点。Breuing等[8]从密度的概念出发,提出了局部离群因子(Local Outlier Factor,LOF)算法,核心思想是考察每个数据点与其周围的数据点的分布特征,得到每个数据点的LOF值,然后将LOF最大的若干个数据点输出为离群点。以上现有的离群点检测算法中,数据集中的每一个数据都需要与数据集中的其他数据进行较复杂的关系运算,因此都存在着时间成本高的问题[9-10];不仅如此,现有的离群点检测算法是依据数据点与周围数据点的分布特征(如密度、距离等)来判断该数据点是不是离群点[9-11],判断标准比较模糊宽泛,因此误判率会比较高;现有的算法还有一个弊端:算法对初始参数的选择非常敏感,初始参数选择不合适,算法将不能得到预期的检测效果[12]。
结合电类实验教学的特点,本文依据均值漂移(Mean Shift)的思想和距离的概念,提出了一种离群点检测(Mean Shift Outlier Detection,MSOD)算法。MSOD算法以给定的实验参数条件下的理论计算值作为初始点,沿着概率密度的梯度方向不断迭代,最终均值漂移算法收敛在数据最稠密的位置。与数据最稠密的位置的距离大于某一特定值的数据被判定为离群点,即为测量有误的实验数据。与现有的离群点检测算法相比,MSOD算法不仅提高了离群点的判断的正确率,而且还大幅度降低了时间成本,克服了对初始参数的敏感性。
1 MSOD离群点检测算法
1.1 相关定义
定义1距离。对于数据集D中任意两个数据对象xi和xj,数据集中对象的属性集为(p1,p2,…,pm)。xi={xi1,xi2,…,xim},xj={xj1,xj2,…,xjm},则xi和xj之间的距离dis(xi,xj)为:
(1)
定义2数据集D的中心点c。以理论计算值为起始点,沿着概率密度的梯度方向最终到达的概率密度最大的位置为数据集的中心点c,也就是数据最密集的位置。
定义3离群点。对于数据集D中的数据对象x,如果x与数据集的中心点c的距离大于某一特定值,则x称为数据集的离群点。
定义4数据预处理。原始数据的不同属性的单位量度的差异可能会造成不同属性的数值差异过大,这样就会导致较小数值的属性在最终的计算中被淹没[13],因此对原始数据进行预处理至关重要。
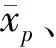
(2)
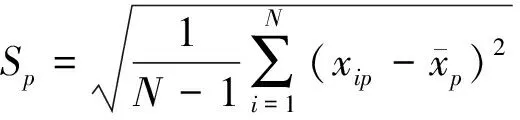
(3)
数据预处理之后的数据集D的p属性的数值表达式为:
(4)
定义5均值漂移向量的基本形式。在m维空间Rm中任取一点x为参考点,Sk是以x为球心、以h为半径的高维球区域,k为落入Sk区域的样本数据的数目,Sk区域中的样本点y满足以下关系:
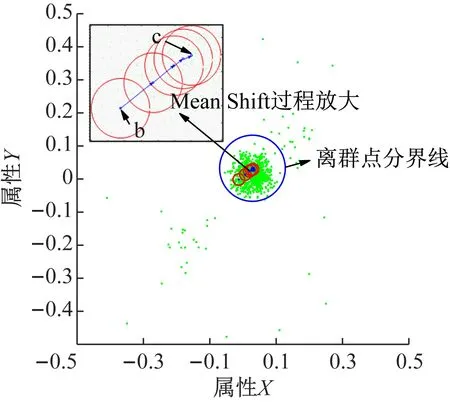
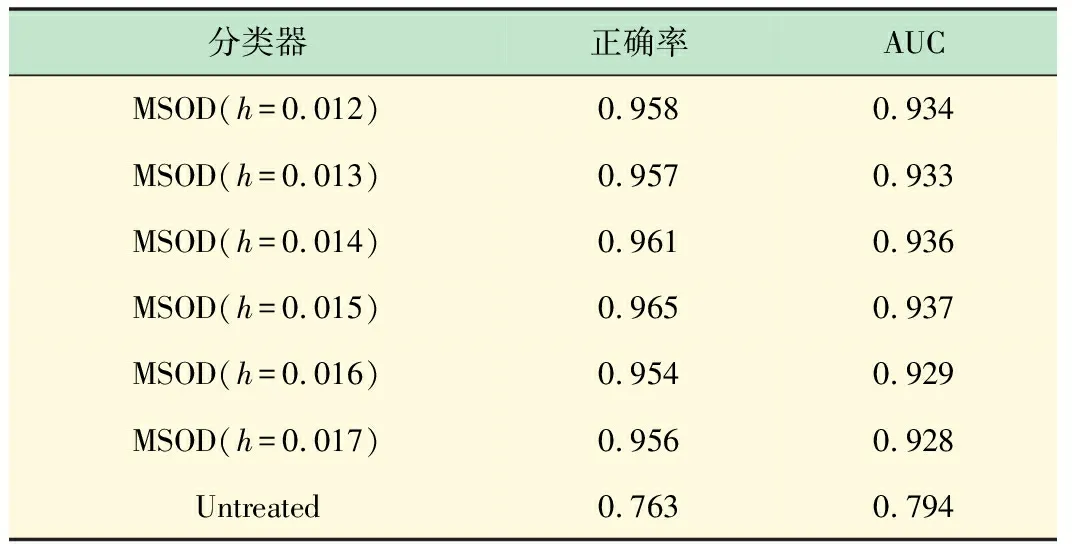
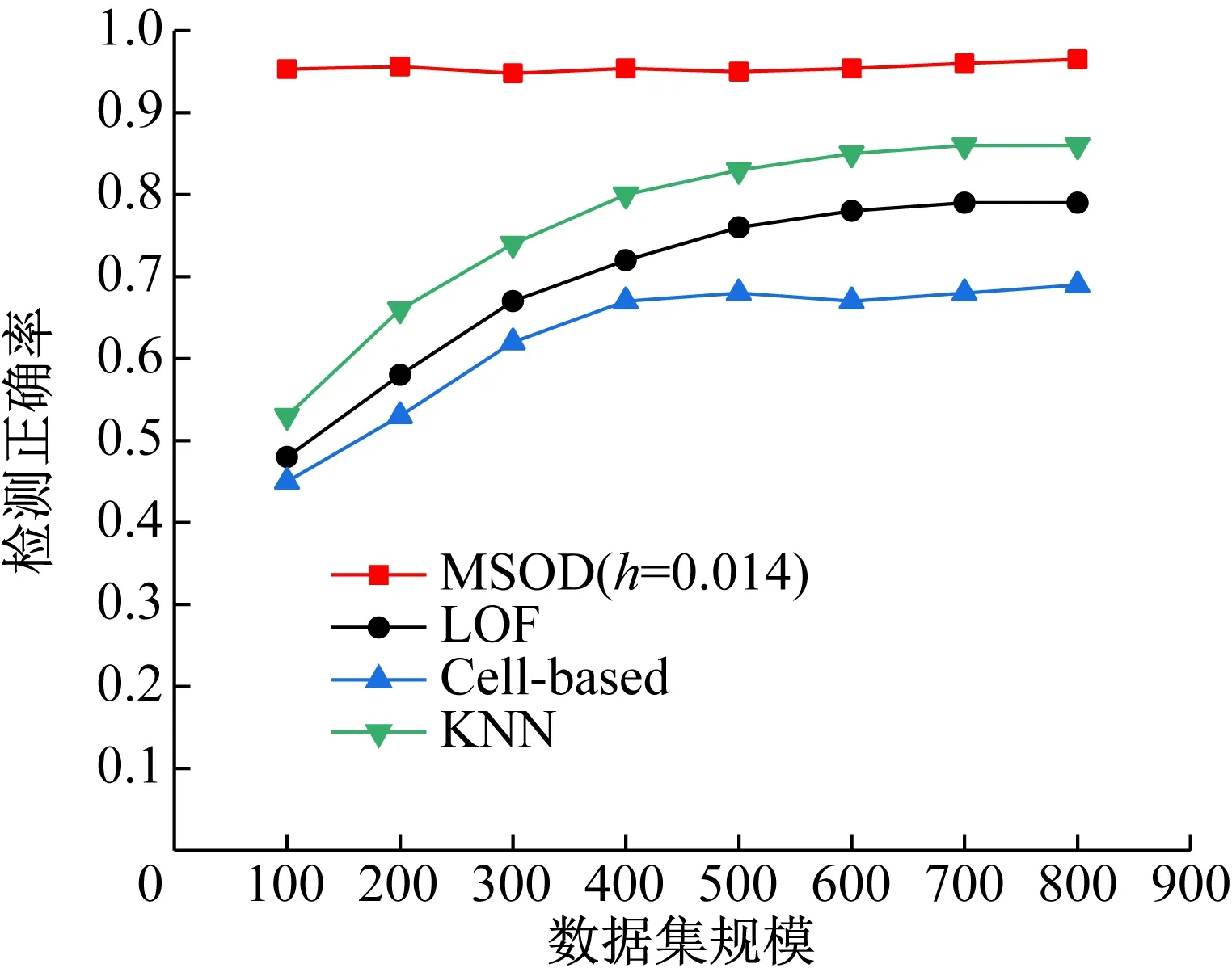
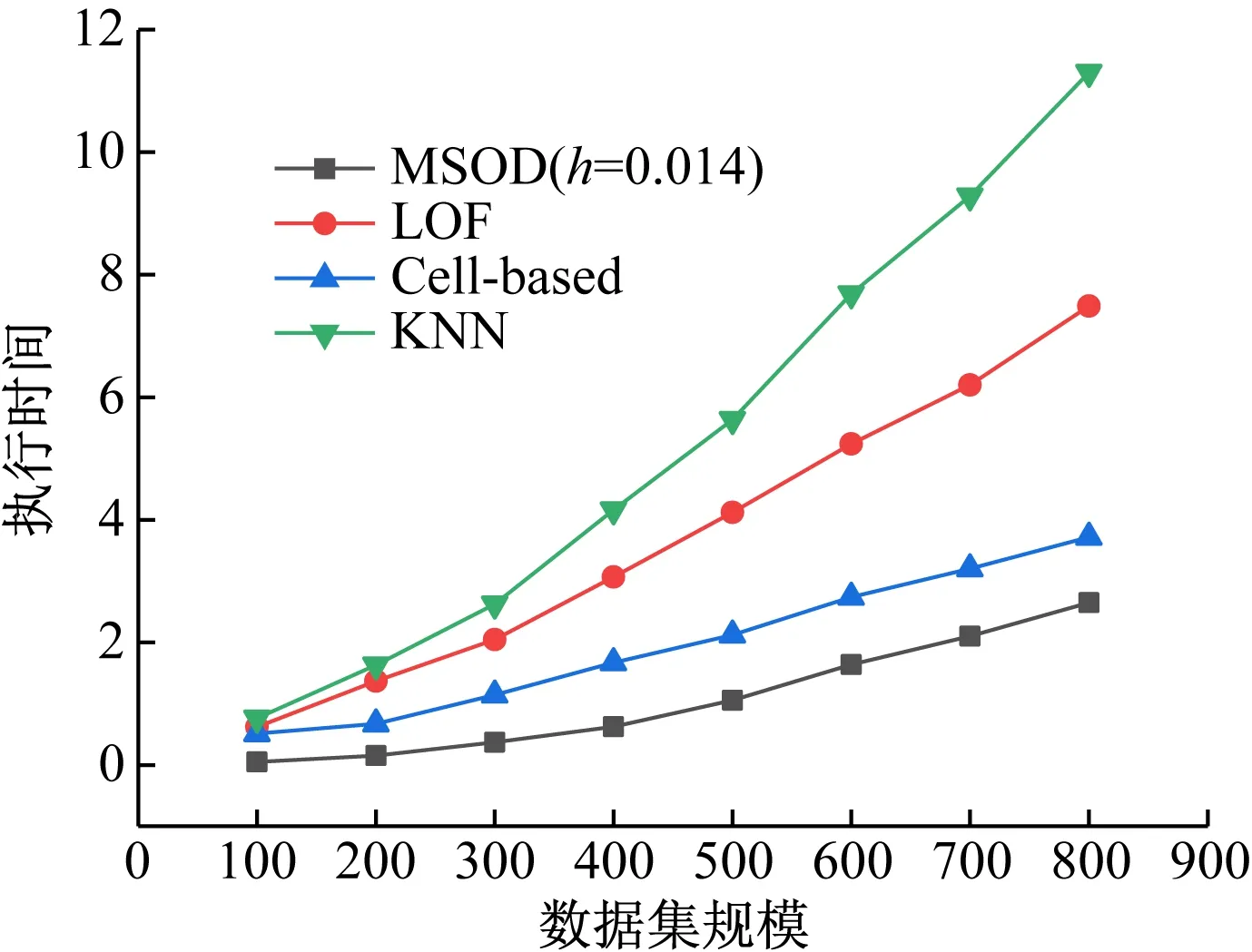
Sk(x)={y:(y-x)·(y-x)T (5) Mean Shift向量的基本形式为: (6) (xi-x)为落入高维球区域的样本点xi与球心x的位置偏移量。因此Mh(x)为球心x与落入球内的k个样本点xi(xi∈Sk)的偏移向量的求和,即是概率密度的梯度。 定义6均值漂移向量的扩展形式。对于Mean Shift向量的基本形式Mh(x),落入球内的样本点xi(xi∈Sk)无论与球心x的距离远近,xi对Mh(x)的影响是一样的。这样会导致球心x收敛速度比较缓慢。样本点xi离球心x越近,其对于球心x周围数据分布特点的统计价值就越大[14]。因此,在Mh(x)中对不同位置的样本点xi给予不同的权重很有意义。将高斯核函数引入Mh(x)中,可以在Mh(x)中对不同的样本点xi赋予不同的权重,均值漂移向量的扩展表达式为: (7) 式中,h高斯核函数的表达式为: (8) 结合MSOD算法相关定义的描述,给出算法的执行步骤。 输入:数据集D={x1,x2,…,xN},高维球Sk的半径h。 输出:离群点集O。 第1步根据式(2)、(3)、(4)对数据进行预处理; 第4步以c为球心,以h′为半径,本算法中h′取0.1,作一个高维球S′,数据集D中落在区域S′之外的样本点即为离群点。 在MSOD算法中,对数据进行预处理的时间复杂度为O(N);迭代确定数据集D的中心点的运算过程中,每次迭代的时间复杂度为O(N),所以总的时间复杂度为O1(N)+O2(N)+…+Ot(N),其中t为迭代次数;得到数据集D的中心点之后,以距离中心点的远近为标准判断是否是离群点的运算过程的时间复杂度为O(N)。结合电类实验教学的特点,在MSOD算法中,选择理论计算值作为迭代运算的起始点,MSOD算法迭代开始时的数据点与中心点的距离较近,MSOD算法经过较少次数的迭代便可以得到最优解。与现有的离群点检测算法相比,MSOD算法的迭代次数t很小,所以MSOD算法的时间成本大幅度下降。 本实验所使用的数据集为上海交通大学电工电子实验教学中心所开设的实验“验证叠加定理”中的学生所测的实验数据,数据的属性数目为2,一共是866组数据,从中选择800组数据为研究对象。在本实验中,MSOD算法运行在8.00GB内存、3.6GHz、八核CPU、操作系统为Windows 10的主机上,算法实现语言采用Matlab。 图1中以h取0.014为例显示了MSOD算法的执行过程。绿色点为叠加原理实验中所测量的数据标准化处理后所得的二维数据集,一系列的红色圆代表Mean Shift过程中Sk区域位置的不断变化。以给定参数条件下叠加定理的理论计算值作为迭代的起始点,记为b,Sk区域的圆心沿着Mh(x)的方向(图中的蓝色箭头)不断迁移,最终迭代的停止位置c点为数据集的概率密度最大的位置,即数据最密集的位置。数据最密集的区域为大多数学生正确地进行操作所测量的数据的聚集区域。数据最密集的区域之所以偏离理论值,是由于实验中仪器仪表、电路器件的误差以及环境因素的影响,导致正确测量所得到实验数据与理论值有所差别[15]。MSOD算法可以依据数据集的概率密度特点找到偏离理论值后的数据聚集的位置。一般情况下,理论值与实测数据集密度最大的位置距离较近。由图1可见,Mean Shift过程仅仅经过5次迭代就达到收敛标准,快速找到了数据集概率密度最大的区域,直观地表明MSOD算法的时间成本很小。 以Mean Shift过程的终止点c为圆心,以h′为半径作出如图1中所示的蓝色圆,依据经验h′取0.1。该圆为离群点分界线。圆外的点判定为离群点,圆内以及圆上的点判定为非离群点。 图1 MSOD算法的执行过程示意图 MSOD离群点检测算法可以认为是一种二元分类器,它将数据分为离群点和非离群点两类,可以使用受试者工作特征(Receiver Operating Characteristic,ROC)曲线来衡量其分类性能[16],即 MSOD算法的准确率。在ROC曲线的相关概念中,若一个数据点实际为离群点并且被MSOD算法预测为离群点,则为真离群点(True Positive,TP);若一个数据点实际为离群点但是被MSOD算法预测为非离群点,则为假非离群点(False Negative,FN);若一个数据点实际为非离群点但是被MSOD算法预测为离群点,则为假离群点(False Positive,FP);若一个数据点实际为非离群点并且被MSOD算法预测为非离群点,则为真非离群点(True Negative,TN)。真离群点率(True Positive Rate,TPR)可以定义为TP/(TP+FN),表征分类器预测的离群点中实际离群点占所有离群点的比例;假离群点率(False Positive Rate,FPR)可以定义为FP/(FP+TN),表征分类器预测的离群点中实际非离群点占所有非离群点的比例。分类器将数据点x预测为离群点的确信度(Certainty Factor, CF)为: (9) 式中,c为数据集的中心点,即数据集概率密度最大的位置。由式(9)计算数据点x的CF值,进而求出数据点的TPR和FPR,以FPR为横轴,以TPR为纵轴,即可画出ROC曲线。ROC曲线越凸且越靠近左上角,表明该分类器分类越准确。可以进一步量化,ROC曲线的下夹面积(Area Under the Curve,AUC)越大,表明分类器性能越好。 在MSOD算法中,需以Sk区域的半径h作为输入值,同时研究h的不同取值对MSOD算法性能的影响。在图2中作不同分类模型的ROC曲线,包括h取不同值时的MSOD算法的ROC曲线,以及以理论值作为离群点分界圆的圆心对数据集进行分类的ROC曲线(“Untreated”曲线)。从图2可以看出,对于MSOD算法的ROC曲线,当h从0.012一直增加到0.017时,ROC曲线都非常靠近左上角,所以MSOD算法的分类效果都很好。表1中进一步量化了不同分类器的预测正确率和AUC值,由表1可见,对于MSOD分类算法,当h在[0.012,0.017]范围内取不同的值,AUC的大小都在0.930左右,并且离群点检测的正确率都在0.960左右。这表明在MSOD算法中,初始值h的不同取值不会对MSOD算法的性能产生影响,表明MSOD算法具有健壮性,有效地克服了现有算法对初始参数敏感的缺点。 图2 不同分类模型的ROC曲线比较 分类器正确率AUCMSOD(h=0.012)0.9580.934MSOD(h=0.013)0.9570.933MSOD(h=0.014)0.9610.936MSOD(h=0.015)0.9650.937MSOD(h=0.016)0.9540.929MSOD(h=0.017)0.9560.928Untreated0.7630.794 相比之下,图2中的“Untreated”曲线离左上角距离较远,并且表1显示其AUC只有0.794,与MSOD算法相比,其AUC比较小,分类效果较差。进一步地,从表1中可以看出,其离群点检测正确率只有0.763。这表明,假如直接使用理论值作为离群点分界圆的圆心,以数据点离该理论值的远近作为评判标准来判决数据点是不是离群点,这样的分类效果较差,将会导致大量数据误判。 图3显示了在不同的数据集规模下,MSOD算法与现有的离群点检测算法的正确率比较结果。可以看出,现有的离群点检测算法中,如LOF和KNN算法,其核心思想是通过数据点与其邻近数据的分布特征来判断数据点是否是离群点,其判断标准比较模糊宽泛。Cell-based算法也是仅仅考察数据点与其邻近的数据点的距离,没有整体研究数据集的分布特征。所以现有的离群点检测算法得到的可能是局部最优解,而不是全局最优解,其正确率仅在0.7-0.8的范围内,而且在数据集规模较小的情况下,由于参考样本缺乏,检测正确率更低,比如在数据集规模为100时,正确率仅为0.5左右,完全无法对离群点进行有效检测。相比之下,MSOD算法选取理论值作为迭代的初始点,一般情况下,理论数据点与数据集中心点距离较近,所以经过均值漂移以后,迭代的终止点都会沿着概率密度的梯度方向准确地达到概率密度最大的位置,所以MSOD算法更易于得到全局最优解。以与此点的距离远近作为评判数据的标准,其离群点检测的正确率会达到很好的效果。如图3所示,MSOD算法在不同的数据规模下,其检测正确率均在0.95左右。与现有的离群点检测算法相比,MSOD算法不仅实现了检测正确率的大幅度提高,而且克服了在数据较少的情况下正确率较低的弊端。 图3 数据集规模变化时不同算法的正确率比较 对于现有的LOF和KNN算法,由于需要对全体数据进行邻域查询或者计算距离,所以其运算时间成本很高。Cell-based算法的时间复杂度为O(am+N)[6],a为常数,m为数据集的维度,其时间复杂度与m成指数关系,所以也存在时间复杂度高的问题。在MSOD算法中,由于迭代的初始值与数据集中心点距离较近,仅通过较少次数的迭代就可以沿着概率密度的梯度方向快速收敛到数据集的中心点,即数据集概率密度最大的位置,所以MSOD算法的时间成本明显降低。图4给出了不同的离群点检测算法的时间性能比较结果。 图4 不同算法的时间性能的比较 从图4可以看出,MSOD算法不仅在相同的数据集规模的条件下,其执行时间明显低于其他离群点检测算法,而且随着数据集规模的增大,其执行时间增长速度较为缓慢。 本文结合电类实验教学的特点,依据均值漂移思想,提出了一种能够应用于电类实验教学中进行错误实验数据判决的MSOD算法,MSOD算法以理论值作为算法的迭代初始值,沿着数据集概率密度梯度方向迭代到概率密度最大的位置,即数据最密集的位置。以数据点与数据最密集的位置的距离来判断该数据是否为离群点,即该数据是否测量错误。结果表明,与现有的离群点检测算法相比,MSOD算法明显提高了检测正确率,同时降低了运算时间成本,并且有效克服了现有算法对初始参数选择的敏感性,也克服了现有算法在数据集规模较小的情况下无法进行有效判决的缺点。MSOD算法可以快速准确地识别出学生测量有误的数据,从而避免教学中重复繁琐的人工评判数据的工作。教师可以从应接不暇的重复性劳动中摆脱出来,便可以在有限的时间内和学生讨论进一步深入的课程问题[17],从而提高实验教学效率和质量。MSOD算法亦可进一步应用于“互联网+教育”的实验教学模式中,以实现评价学生学习效果的智能化。
1.2 算法描述
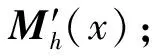
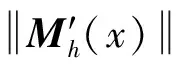
2 实验研究与性能比较
2.1 实验设计
2.2 实验结果分析

3 结 语
