改进近似动态规划法的攻击占位决策*
2019-08-27姜龙亭寇雅楠张彬超
姜龙亭,寇雅楠,王 栋,张彬超,胡 涛
(1.空军工程大学航空工程学院,西安710038;2.解放军95974部队,河北 沧州061000;3.解放军95356部队,湖南 耒阳421800)
0 引言
近年来,无人机技术发展迅猛,已经在经济和军事领域有了一定的应用。目前,大多数的空战任务主要是由有人机来完成。但是由于近距空战激烈的对抗性和动态特性,人在回路的无人机以及有人机在面临复杂的战场情况时,常常因为误判态势造成空战失利。同时,由于自主决策系统能将飞行员从紧张、激烈的对抗任务中解脱出来,对武器装备的发展以及人类的发展进步都具有深远的意义。因此,研究具有自主机动决策的无人机成为各军事强国争先发展的重点。
自主空战决策[1]是指对抗过程中,为了实现优势态势和最小化我机面临的危险,实时地计算出无人机的最优机动策略。目前,学者们针对无人机自主决策问题提出了许多方法。主要有微分对策法、影响图法、专家系统法和强化学习法。基于微分对策法[2-4]的决策系统由于受限于具体的数学模型,可移植性较差;影响图法[5]在一定程度上对空战给出了合理的决策行为,但是没有通过全局的战场态势信息构建决策模型,无法满足高强度的空战需要,很难应用到实战中;专家系统法[6-7]通过建立态势与机动策略的映射关系来模拟飞行员的决策过程,但是专家系统难以构建完备的规则模型,并且通用性较差;神经网络法[8-9]求解得到的机动决策无法从模型本身进行合理解释,并且需要大量的实战训练样本数据。
本文主要针对空战过程的攻击占位决策问题进行研究。由于近似动态规划法[10-14]具有良好的泛化能力和在线学习能力,本文在前期研究的基础上,通过对战场环境和战术使用原则的分析,建立基于近似动态规划的空战机动决策模型。文献[10]通过对近似动态规划法的研究,解决了航模的追逃问题,但是真实的空战过程有着不同与航模的高机动性的特点。文献[13]虽然通过近似动态规划法对水平飞行的空战接敌问题进行了研究,但是在占位决策过程中,由于未考虑飞机的过冲问题,智能体在机动决策后容易进入敌方攻击区内。针对上述存在的不足,本文通过对空战过程分析,提出惩罚因子对近似动态法进行改进,建立改进的近似动态规划模型,避免了攻击占位过程中的“过冲”现象。
1 问题描述
正如著名军事理论家杜黑所言:空战就是以夺取制空权为最终目的对抗过程。作战双方的作战目的就是在避免被对方击落的情况下,占据攻击对方的战术优势位置。这种战术优势位置随着敌我双方的相对位置在空间里连续变化。为了清晰描述态势的动态变化过程,某一时刻红蓝双方的几何占位态势信息如图1所示。

图1 红蓝双方几何占位态势图



算法1:状态转移函数计算方法
初始化:


For i=1:5(仿真步长为Δt=0.375 s)


算法1中,st为当前时刻输入的状态信息,根据状态转移方程求解,st+1即为下一时刻的状态信息。
求解自主攻击的占位决策问题实质上是一个序列决策问题。即基于当前的态势信息给出一种最优的机动决策序列,也即求解空间状态与机动行为之间的一种映射,使得飞机快速朝着攻击的优势位置飞行,最终完成攻击敌机的任务。
2 近似动态规划法
2.1 近似动态规划法基本框架
由于动态规划法具有良好的泛化和在线学习能力,在解决序列决策问题上有着很大的优势。利用动态规划法求解序列决策问题时,需要建立长期收益与状态之间的映射关系。对于离散的低维度状态空间,各个状态的长期收益可以保存在查询表内。但是,随着战场环境和空战任务的日益复杂,基于查询表式的长期收益显得捉襟见肘。尤其是在解决具有连续性状态空间的空战决策问题更是容易出现“维数灾难”。为了解决状态维数高造成的问题,近似动态规划法基于函数拟合的思想,以连续函数逼近长期收益的状态值函数。通过严密的数学推导,对长期收益值函数进行逼近优化,由此获得状态空间与长期收益值之间的映射关系。
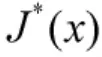

则近似值函数可作为线性回归的观测值,即


为了清楚地对空战状态进行描述,采样状态的特征集合记为:

其中,M为状态特征的数目。
基于函数拟合的思想,采样状态和近似值函数可以抽象为一个多元线性回归问题,即

使用标准最小二乘估计进行计算,

由此可得,第i次迭代后的长期收益值函数为:
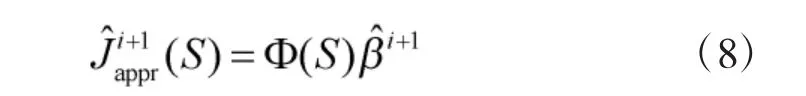

2.2 奖励函数
空战过程中,红蓝双方在各自的战术策略下首先隐蔽接敌,然后攻击占位。通过控制飞机快速进入敌方的尾后区域,并截获跟踪目标,直至发射导弹。为了准确控制飞机快速占据攻击敌方的优势位置,本文从空战的隐蔽接敌和攻击占位两个阶段对上述提出的奖励函数进行定义。因此,奖励函数R(s)包括即时奖励函数G(s)和态势奖励函数A(s)两部分。
一是即时奖励函数。即将敌方的尾后区域定义为占位的目标区域,通过奖励进入占位目标区域的状态引导飞机进入攻击位置。目标区域(见图2)往往与飞机的性能密切相关。在本文中,主要考虑飞机的提前角ATA、进入角AA和双方的相对距离r。因此,依据文献[10]的分析,即时奖励函数G(s)定义为:
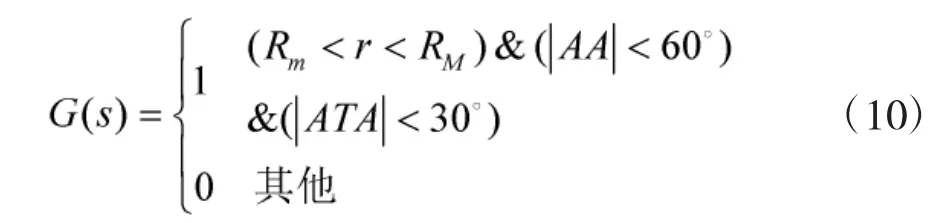

图2 蓝方攻击优势区域示意图
图2所示虚线区域表示当蓝方飞机的进入角小于60°,提前角小于30°,两机距离在武器系统的作用范围内时,无论蓝方采取何种机动,蓝方都占据优势地位,并且可以以较高的命中率发射导弹。近似动态规划法通过即时奖励函数G(s)对优势攻击位置奖励,将引导蓝方飞机快速进入定义的优势攻击位置。
二是态势奖励函数。即当飞机在隐蔽接敌过程中对空战态势优势的奖励。飞机在空战过程中可以通过态势奖励函数引导飞机向空战区域机动。态势奖励函数A(s)的定义将弥补即时奖励函数不连续性的缺点。由于本文只考虑平面等高度下的空战对抗,且双方速度假设恒定,因此,态势奖励函数主要与敌我双方的相对角度和距离相关。态势奖励函数A(s)定义为:


结合即时奖励函数和态势奖励函数,近似动态规划法中的奖励函数R(s)定义为:
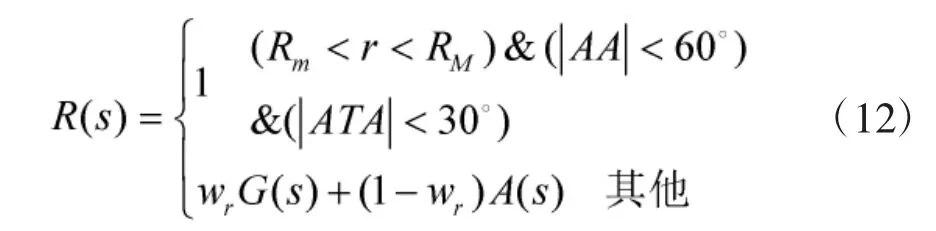
其中,wr为即时奖励函数与态势奖励函数之间的权重因子。即时奖励函数引导飞机进入攻击占位优势区域;态势奖励函数在整个状态空间发挥作用,在空战过程中,引导飞机朝着优势区域飞行。
2.3 惩罚因子
理想的空战决策问题需要在获得奖励的同时也要平衡在机动过程中存在的风险。由于近似动态规划法在机动决策时,仅考虑了如何将飞机引导至己方优势区域,依据几何关系定义了优势函数,未对飞机的危险区域进行定义,并且因为策略搜索算法有限的前瞻性,较短的搜索范围也容易陷入局部最优,仿真分析和飞行机动决策过程中容易造成“过冲”,使得飞机处于敌方的优势区域内。当蓝方处于红方的优势区域时间越长,相对距离越近,蓝方被红方击中的几率也就越大。为了克服上述存在的不足,本文针对“过冲”问题和距离太近引起的“碰撞”问题,结合空战实际问题,定义了与奖励函数对应的惩罚函数P(s)。
空战过程中,进入敌方攻击区的概率也是随机的,为了描述这种随机性,定义了风险概率pt(s):
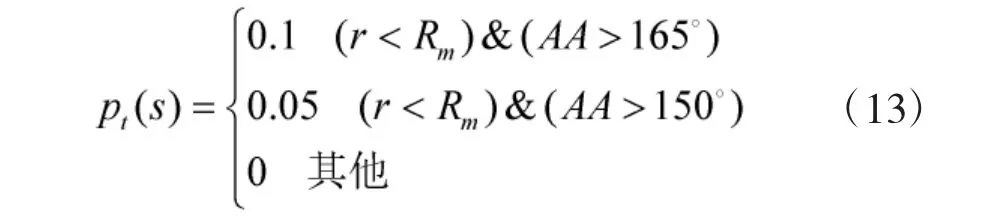
为了避免距离太近引起的两机相撞问题,对pt进一步改进,改进后的风险概率P(s)为:

例如,当飞机的相对距离小于武器的最小发射距离,AA=180°时,危险概率P=0.1。也就是说在现实世界中飞机进入敌方飞机的攻击区域,被敌方攻击的概率是0.1。随着双机距离逐渐接近,危险概率P(s)越来越大。危险概率P(s)将阻止蓝方飞机进入红方的攻击区域。
为了防止飞机在飞行过程中因“过冲”进入敌方的攻击区域,本文基于惩罚函数对长期收益值函数式(9)进行了修正:
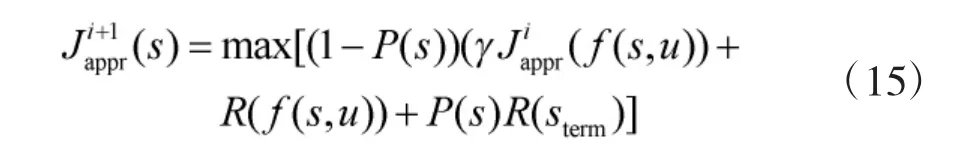
如果当前状态P(s)>0时,则表示蓝方飞机处于敌方的攻击区域内。通过减小长期收益值,引导蓝方飞机进行快速摆脱。也即蓝方飞机一旦进入敌方的优势区域内,将快速机动至敌方的攻击优势区域外。
改进后的近似值函数计算如算法2:
算法2:改进的近似值函数计算


2.4 状态采样
近似动态规划法逼近长期收益值,需要对空战博弈的状态空间进行采样。采样稀疏对近似值函数Jappr(s)与值函数J*(s)的误差有着至关重要的影响。只有最大限度地减小最优值函数与值函数的误差,求解的机动策略才最接近最优的机动策略。从这个角度出发,高密度的采样将比低密度的采样更接近最优解,但是采样数的增多必然带来计算量指数增加。并且,采样数目的增多,执行贝尔曼迭代所需要的时间也大幅增加,必然会对机动决策的实时性产生很大的影响。从这个角度出发,采样的状态数目应该是越少越好,低密度的采样将会使得智能体的运算速度较快,决策的实时性将得到提升。因此,为了平衡机动策略的误差与决策实时性这一对矛盾,必须合理地选择采样点。在重要的状态空间区域,有必要进行精细的状态采样;在很小几率出现的状态空间区域,则没必要划分太精细。为了确保空战过程中最有可能出现的区域得到充分的采样,本文对飞机空战过程进行轨迹采样[10]。


2.5 机动策略提取
在红蓝双方仿真对抗过程中,红方采取最大最小策略进行机动决策,蓝方采取近似动态规划方法进行机动决策。则蓝方的机动策略为:

算法3:机动策略提取
输入:si

基于改进的近似动态规划法可以依据最优的长期收益值进行决策,而不是通过有限的前瞻策略进行决策,并且以惩罚函数对收益值函数进行修正。因此,基于ADP的机动决策不仅能反映空战全局的最优决策,而且还能有效避免“过冲”问题和“碰撞”问题。
3 仿真分析
仿真1假设红方飞机未能有效感知战场态势,依然保持初始航向和初始机动策略飞行。蓝方飞机根据所处战场态势,使用基于ADP的机动策略。红蓝双方初始状态信息见表1。

表1 红蓝双方初始态势信息表
仿真如下页图3所示。
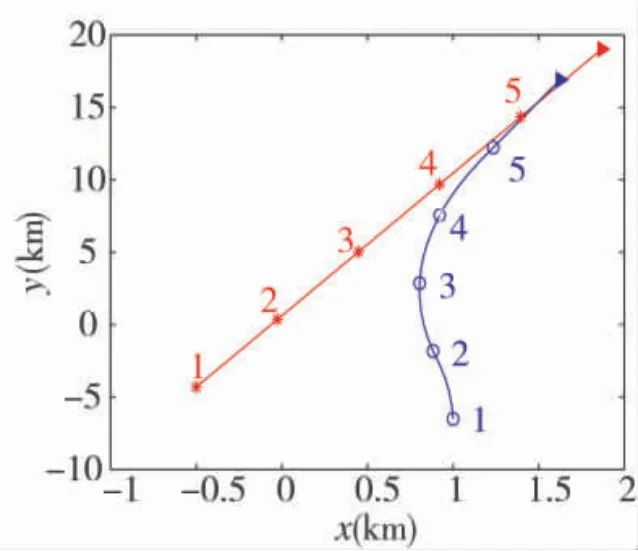
图3 仿真验证1结果
从图3可以看出,在红方保持机动方向不变的情况下,蓝方通过ADP机动策略能够很快机动至红方的尾后攻击区域,有效占据攻击优势。
仿真2假设红方飞机能有效感知战场态势,并且根据战场态势以最大最小的机动策略与蓝方飞机进行对抗。蓝方飞机根据所处的战场态势,使用基于ADP的策略进行机动决策。红蓝双方初始初始状态信息见表1。
仿真如图4所示。

图4 仿真验证2结果
从图4可以看出,在红方采取最大最小策略进行机动,蓝方通过ADP机动策略能够很快机动至红方的尾后攻击区域,有效占据攻击优势。
仿真3假设红方飞机能有效感知战场态势,并且根据战场态势以最大最小的策略进行机动决策,蓝方飞机根据所处的战场态势,在使用基于ADP的策略与红方飞机对抗时存在“过冲”机动,于是使用改进的ADP策略确保不处于红方的优势区域,并且快速占据优势攻击位置。红蓝双方初始状态信息如表2所示。

表2 红蓝双方初始态势信息
仿真如图5所示。
从图5中可以看出,当红方采取最大最小策略,蓝方采取ADP策略时,蓝方由于提前采取左转机动,在第4次机动决策后,造成“过冲”现象,此时红方呈尾追态势,若锁定目标,即可对蓝方实施攻击。在同样的初始条件下,蓝方依旧采取最大最小策略,红方采用改进之后的ADP策略时,最优机动决策则是先维持初始航向,然后再采取左转盘旋机动。通过仿真可以发现,蓝方在第5次机动决策后,占据尾追攻击的优势态势,有效避免了“过冲”问题。

图5 仿真验证3结果
4 结论
本文基于近似动态规划法理论对水平飞行、定速、一对一空战自主攻击占位决策方法进行了研究。基于近似动态规划理论建立了空战自主攻击占位的决策框架。针对空战环境的高维度状态空间,基于函数拟合的思路构建近似值函数,对空战过程的长期收益逼近优化,给出了自主攻击占位决策的策略学习方法;对传统的近似动态规划决策方法存在的“过冲”和“碰撞”问题,提出了惩罚因子对近似动态规划法进行改进。仿真结果表明,改进的近似动态规划法在自主攻击占位决策中,可以有效避免发生“过冲”和“碰撞”问题。
基于改进的近似动态规划法在自主攻击占位决策时,近似值函数的优劣对策略学习有着至关重要的影响。确定合理的长期收益值函数将能逼近最优的值函数,进而得到最优的机动策略。同时,在进行策略学习时,蓝方机动策略的优越性依赖于红方飞机的智能化水平。红方的智能化水平越高,蓝方学习到的机动策略将更具鲁棒性和智能性。因此,在后续的研究中,提高蓝方飞机机动策略的智能性以及逼近最优的值函数,将进一步提升飞机的自主空战能力。
