基于交点有序化的简单多边形布尔运算
2019-08-22魏胜利
魏胜利,李 源
(安阳工学院 计算机科学与信息工程学院,河南 安阳 455000)
0 引 言
多边形布尔运算,即多边形间的交、并和差,是计算机图形学、计算几何中一个最基本的算法,广泛应用于几何实体造型、地理信息系统(GIS)等领域。国内外许多专家对多边形布尔运算算法进行了大量研究,并提出了相应的算法。Andereev[1]、Foley[2]、Maillot[3]等提出的算法仅适用于凸多边形。Weiler等[4]提出的算法使用树形数据结构,Vatti[5]、Greiner_Hormann[6]提出的算法使用双性链表数据结构,刘勇奎[7]提出的算法使用单链表结构。朱雅音等[8]提出了基于边的奇偶性质的任意简单多边形的布尔运算,很好地处理了各种奇异情况。闫浩文等[9]提出一种复合多边形求差的矢量算法。崔璨等[10]提出一种基于梯形剖分的多边形布尔运算方法。Rivero等[11]提出一种全新的适用于任意多边形的布尔运算,该算法用简单链表示两个多边形,得到一个同样用简单链表示的结果多边形;董未名等[12]将Rivero算法扩展到可以应用于带圆锥曲线边的平面简单多边形。朱二喜等[13]从图形内角概念开始,对多边形布尔运算重新全局化建模,实现其算法。赵军等[14-15]利用最小回路提出分别求简单和带洞多边形的布尔运算的方法。
文中在对Greiner_Hormann和刘永奎提出的算法深入分析的基础上,提出了一种基于交点有序化的简单多边形布尔运算算法。以单链表数据结构为多边形的存储结构,采用基于扫描线的线段求交算法求多边形的交点,借助邻接表实现对无序交点的有序化处理,通过一次性遍历邻接表把交点依次插入到多边形链表中,然后再分别追踪出多边形交、并、差的结果。最后将该算法与Greiner_Hormann和刘永奎算法进行了比较,结果表明该算法在执行效率方面优于上述两种算法。
1 基本概念与定义
为了便于算法的描述,先介绍一些有关多边形布尔运算的基本概念和术语。
(1)主多边形和裁剪多边形。
多边形的布尔运算包括交、并、差,多边形的布尔运算与多边形的裁剪运算没有本质的区别,都需要先对数据进行处理,才能追踪结果。裁剪运算只是得到多边形的交,布尔运算还需要后续输出并和差的结果。因此,为了便于问题的描述,借鉴裁剪运算的概念,把其中一个多边形称为主多边形,用S表示;另一个多边形称为裁剪多边形,用C表示。
(2)多边形布尔运算的表示。
对于多边形S和C,定义S与C的交表示为S∩C,S与C的并表示为S∪C,S与C的差表示为S-C,C与S的差表示为C-S。
(3)多边形边的方向与内外区域的关系。
如果多边形边的方向是逆时针,则沿着多边形边界方向前进,左侧区域为多边形的内部;相反如果多边形边的方向是顺时针,则沿着多边形边界方向前进,右侧区域为多边形的内部。如无特别说明,这里所述的多边形都是按逆时针方向存储的。
(4)进点和出点的定义。
设I是多边形S和C的一个交点,如果沿着S的边界方向在I点从C的外部进入C的内部,则称I为C的一个进点。反之,如果S在I点从C的内部到C的外部,则称I为C的一个出点。
例如,对于图1所示的多边形S和C及其交点I,若S的边为逆时针方向,则I3、I1为C的进点,I2、I4为C的出点;若S的边为顺时针方向,则I3、I1为C的出点,I2、I4为C的进点。
(5)基点。
所谓基点就是按照多边形边的方向交点所在边的起点。例如,在图1中,对于多边形C来说,C1就是I4和I3的基点。
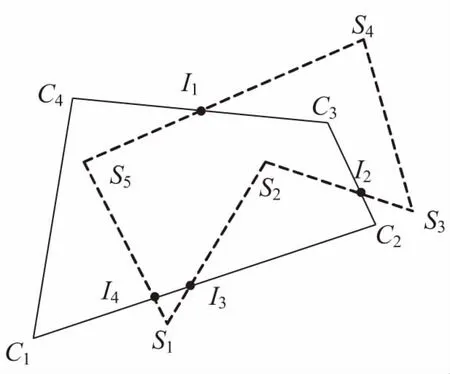
图1 相交多边形
2 算法的数据结构
多边形布尔运算算法需要一个合适的数据结构来存储多边形及交点,并能够在其上进行正确追踪布尔运算的操作。Weiler算法中把输入的多边形组成一个树形结构,Greiner_Hormann算法采用双向链表的结构,每个多边形由一个双向链表来表示,并依此把所求得的交点分别按多边形顶点的有序序列插入到主多边形和裁剪多边形的两个双向链表中。刘勇奎对Greiner_Hormann算法进行了改进,采用循环单链表来存储多边形,同时仅为交点分配一个存储空间,与Greiner_Hormann中的双向链表结构相比,因减少了一个指针域而节省了存储空间,且仅为每个交点建立1个节点的存储空间,并分别插入到两个多边形的单链表中。而Greiner_Hormann算法为每个交点建立两个存储空间,然后再分别将每个交点插入到对应的多边形链表中。刘勇奎算法设计了两种不同的数据结构分别存储多边形顶点信息和交点信息,但又把以这两种不同结构表示的多边形顶点和交点插入到同一个链表中,这在采用带有指针类型的高级语言编程时是无法实现的,因为这类编程语言要求链表中的节点必须具有相同类型的结构。可以把刘勇奎算法中所设计的两种不同的数据结构归结为一类,即每个单链表节点中含有两个指针,其中一个指针只有当该节点为交点时才有意义。这样既保留了刘勇奎算法中单链表的优点,又便于编程实现。
在基于交点有序化的简单多边形布尔运算算法中,单链表节点数据结构为:
点坐标信息:
struct Point
{
double x,y //点坐标
};
多边形顶点及后续求的交点坐标都存储到一个点坐标数组中,点的编号即为点在数组中的下标。
单链表节点信息:
struct Vertex
{
bool Intersect; //布尔型
Vertex *next1,*next2; //节点指针
bool used;//布尔型
intindex; //点编号
};
其中Intersect用于标识该节点是多边形顶点还是交点,指针域用于指向下一个节点,如果该节点是多边形顶点,则next1指向单链表的后继,next2无意义;如果该节点为交点,则next1,next2分别指向主多边形和裁剪多边形单链表的后继节点,实现同一个交点分别插入到两个多边形单链表中。used用来标识在追踪多边形布尔运算过程中该节点是否使用过。 index为该顶点在点坐标数组中的索引值。图2为对图1采用文中算法得到的的数据存储结构。
3 无序交点的有序化
多边形求交是影响多边形布尔运算效率的关键因素,Greiner_Hormann算法和刘勇奎算法都是通过测试两个多边形的全部线段对求交点,效率很低。文中采用Park[16]提出的多边形链求交算法求多边形的交点,其时间复杂度为O(n+k)logm,其中m为判断是否存在交点的线段数,n为两个多边形的顶点个数,k为交点个数。但Park算法求得的多边形链的交点是无序的。文中采用与邻接表类似的存储结构分别暂时存储主多边形和裁剪多边形的交点信息,以实现无序交点的有序化。在邻接表中,为多边形的每个顶点建立一个单链表,每个单链表中的节点存储以该顶点为基点对应的交点信息。每个单链表上附设一个表头节点,在表头节点中,除了设有指针域指向链表中第一个节点,还设有存储基点编号的信息域。建立两个数组,分别存储主多边形和裁剪多边形的表头节点。
存储交点的单链表节点的结构为:
struct IntersectPoint
{
double distancetobasepoint; //交点到基点的距离
IntersectPoint *next;//指针
int index; //点编号
} ;
表头节点的结构为:
struct BaseHead
{
int index ;//基点编号
IntersectPoint * firstpoint; //指向第一个交点
};
其中,firstpoint域指向该基点的第一个交点,next域指向该基点所对应的下一个交点,distancetobasepoint为交点到基点的距离,每个基点对应的交点按distancetobasepoint从小大到排序,这样就实现了无序交点的有序化,且有序化后的交点顺序与多边形顶点的存储顺序一致。
设图1中主多边形的顶点从S1至S4的编号分别为1到5,裁剪多边形的顶点从C1至C4的编号分别为6到9,则主多边形S上的交点有序化后的存储信息如图3(a)所示,裁剪多边形C上的交点有序化后的存储信息如图3(b)所示。
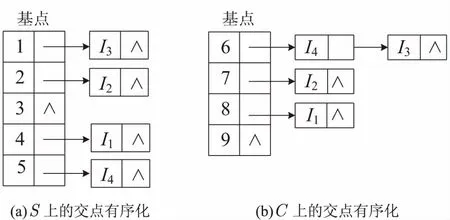
图3 多边形交点有序化
4 交点插入多边形链表
完成无序交点的有序化后,下一步需要把交点按多边形顶点的顺序插入到多边形链表中。把交点插入到多边形链表时需要设置交点的进出性,分析发现沿着S的边界,对于C的进点和出点是交替出现的,所以只需判断第一个交点是进点还是出点,其他交点的进出性则可依次确定。确定第一个交点的进出性的方法是,在S的交点信息表中,找到第一个交点I,并判断I的基点Si与多边形C的位置关系,如果Si在C的外部,则I为C的进点,反之I为C的出点。
把交点插入到S多边形链表中,先遍历S的每个交点,并在S的多边形链表中找到该交点的基点在多边形链表中的位置即可把交点按照多边形链表节点结构的形式插入到S的多边形链表中。由于与S对应的有序化后的交点顺序与S的顶点顺序是一致的,因此在查找下一个交点的基点时可在多边形链表中当前交点的后继节点中查找,而不需重新遍历链表。在插入交点的过程中,可依据第一个交点的进出性交替设置其他交点的进出性。
按照文中采用的多边形存储结构,主多边形链表和裁剪多边形链表共享同一个交点存储单元。由于在把交点插入到S多边形链表时已经为交点分配了存储空间,所以在插入C的交点到C的多边形链表时只需修改指针的指向关系即可。但是S多边形链表中有序交点对于C多边形又是无序的。为了在常数时间内查找到每个交点的存储地址,可用哈希表存储每个交点的存储地址。在该哈希表中以交点的编号为关键字,交点的个数为哈希表的长度,哈希函数采用除留余数法,即:
H(key)=(xindex-indexmin) MODp
其中,xindex为交点编号;indexmin为交点编号的最小值;p为哈希表长度。每个交点经过哈希函数处理后都有一个唯一的值,所以不需要设计处理冲突的方法。
采用与S的交点插入的S的多边形链表中类似的方式,找到C多边形每个交点的基点在C多边形链表中的位置,并按所设计的哈希函数在常数时间内定位到交点的存储地址,修改指针的指向关系,即可将交点插入到C多边形链表中。这样把全部交点插入到多边形链表的时间复杂度为O(n+2k)。
5 追踪多边形布尔运算
把交点按照多边形顶点的存储顺序分别插入到多边形链表后即可追踪多边形布尔运算的结果。
(1)追踪多边形并。
追踪多边形并的步骤为:在主多边形S中查找第一个其后继为裁剪多形进点的节点ps,沿S的多边形链表,从ps开始逆时针遍历,当遇到交点时,则转到裁剪多边形C上继续逆时针遍历,遇到交点时,再次转到多边形S上继续逆时针遍历,重复以上步骤直至起点ps,追踪多边形并结束。从ps开始到ps结束按上述过程遍历到点集就构成多边形的并。
(2)追踪多边形交。
追踪多边形交的步骤为:在主多边形S中查找第一个为裁剪多边形进点的交点ps,将其标记为已访问,然后转到裁剪多边形C上逆时针遍历,遇到交点时,再次转到多边形S上继续逆时针遍历,重复以上步骤直至起点ps追踪出多边形交的一部分。在上述过程中,每遍历到一个节点都标记该点为已访问。在主多边形S中查找下一个为裁剪多边形进点且尚未访问的交点,重复以上过程,直至所有交点都被访问,最后各个部分组合在一起即为多边形的并。
(3)追踪多边形差。
求多边形差与多边形的并和交略有不同,如果求S-C则要求裁剪多边形C顶点按顺时针存储。追踪多边形S-C的步骤为:在主多边形S中查找第一个其后继为裁剪多边形进点的节点ps,将其标记为已访问,沿S的多边形链表,从ps开始逆时针遍历,当遇到交点时,则转到裁剪多边形C上继续顺时针遍历,遇到交点时,再次转到多边形S上继续逆时针遍历,重复以上步骤直至起点ps,追踪出多边形S-C差的一部分。在上述过程中,每遍历到一个节点都标记该点已访问。在主多边形S中查找下一个其后继为裁剪多边形进点且尚未被访问的节点,重复以上过程,直至所有交点都被访问,最后各个部分组合在一起即为多边形S-C。追踪多边形C-S则只需把上述主多边形和裁剪多边形角色互换即可。
6 实验结果
对文中提出的求多边形布尔运算的算法在VC++环境下进行编程实现,结果如图4所示。

(a)S和C (b)S∪C (c)S∩C (d)S-C (e)C-S
图4 多边形布尔运算结果
表1为相同的数据组在相同的硬软件环境下文中算法分别与Greiner_Hormann算法和刘勇奎算法进行对比的结果。

表1 不同算法实验所需的时间比较 s
从表1中可知,文中算法在求多边形布尔运算(交、并、差)时优于Greiner_Hormann 算法和刘勇奎算法。文中算法在求多边形布尔运算过程中,时间复杂度为O(n+k)logm的Park算法求多边形的交点,对于所求得的无序交点,在插入交点到多边形链表前先以邻接矩阵的形式存储多边形交点,并把相同基点的交点按交点到基点的距离从小到大排序,实现无序交点的有序化。然后再依次把交点插入到多边形链表中,把交点插入到多边形链表中的时间复杂度为O(n+2k)。实验结果表明,该算法显著提高了多边形布尔运算的执行效率。
7 结束语
对于简单多边形的布尔运算,在分析已有研究的基础上,提出了一种基于交点有序化的简单多边形布尔运算算法。借助邻接矩阵存储多边形交点,并把相同基点的交点按交点到基点的距离从小到大排序以实现无序交点的有序化,并根据顶点的进出性追踪多边形的布尔运算结果。最后该算法进行编程实现,并和Greiner_Hormann算法和刘勇奎算法进行了对比,结果证明了该算法的高效性和可行性。
