分块制造下硬件木马攻击方法及安全性分析
2019-08-20杨亚君
杨亚君,陈 章
(1.上海科技大学 信息科学与技术学院,上海 201210;2.中国科学院 上海微系统与信息技术研究所,上海 200050;3.中国科学院大学 电子电气与通信工程学院,北京 100049)
随着集成电路设计复杂度和先进制程节点制造成本的提高,集成电路制造全球化已成为主流的生产方式。这种设计和制造分离的模式在给设计公司带来经济利益的同时,也在多方面威胁着芯片的安全。硬件木马,一种常见的威胁芯片安全的部件,通过在芯片设计、制造或使用过程中植入恶意的部件或监测后门电路,改变芯片的功能或窃取用户的信息。硬件木马具有植入的隐藏性和难触发性的特点,这给芯片安全的研究和防护带来了很大的挑战。
传统的硬件木马的防护主要集中在硬件木马的检测:反向工程[1]将制造好的芯片去封装,并通过显微成像技术获得每层金属层的连接信息,最后将恢复的电路与原始设计进行比对,从而判断芯片是否被植入硬件木马。然而这种方法对芯片具有破坏性,且代价昂贵。逻辑测试法[2-3]则通过产生一系列测试向量,试图激活硬件木马来判断芯片是否有木马植入。由于芯片密度的不断增大和硬件木马的隐藏性,找到激活硬件木马的测试向量难度很大。侧信道分析[4-5]被认为是最有效的硬件木马检测方法。该方法通过收集芯片工作时泄露的功耗、时序、电磁及热等旁路信息,并对该信号进行放大分析,提取关键信息来判断是否有硬件木马植入。但该方法需要一个没有被植入任何硬件木马的纯净芯片做比对,这通常被认为很难获取。
硬件木马检测技术在一定程度上保护了芯片的可靠性,但仍不能从根本上解决芯片安全问题。与此同时,硬件木马防范技术,如电路模糊、实时监控及分块制造技术,旨在提高电路设计或制造过程的安全性来对硬件木马攻击进行防范。其中分块制造[6-9]被认为是最有效和有前景的。这种方式将芯片分成两部分给不同的厂商制造,使任何一方厂商都不能获得芯片完整的后端版图信息,从而保证了制造过程中芯片的安全性。文献[10]提出了基于分块制造下的芯片设计流程,验证了分块制造的可行性。然而近期的研究[11-13]表明,分块制造本身是不安全的,依然存在硬件木马攻击的威胁。基于分块制造,笔者提出了两种硬件木马攻击方法并分析了其有效性。
1 硬件木马攻击模型
1.1 分块制造和芯片安全
不同于传统的芯片制造流程,即芯片全部由一家厂商制造,分块制造在第i层金属层(Mi)将芯片分成前序工艺(Front End Of Line,FEOL), 其包含晶体管和部分低层金属连接层,和后序工艺(Back End Of Line,BEOL)两部分,包含高层或全部金属连接层。如图1所示,前序工艺交由不可信的制造商生产,后序工艺交由可信的制造商生产,最后通过3D或硅中介集成[8,14]技术获得最终的产品。分块制造通过将部分或全部的金属连接层(即Mi以上)放在可信任的厂商制造,使得攻击者只能获取部分甚至零连接信息,从而增加了芯片在制造过程中的安全性。显然,分割层越低,越多的金属连接层隐藏在后序工艺中,前序工艺泄露的信息越少,芯片的安全性越高。
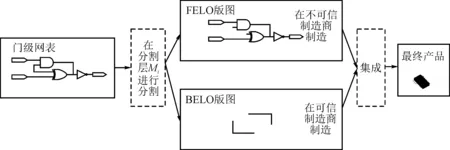
图1 分块制造流程
文献[11-13]分析了分块制造下攻击者利用前序工艺的部分信息恢复隐藏在后序工艺中电路连接的可能性。文献[11]提出了多个利用了不同近似信息的近似攻击方法,在分割层为M2时,该方法最高可以使前序工艺中82%缺失了连接的电路节点找到其可能的连接。文献[12]提出基于网络流的攻击方法,其进一步综合利用了近似信息和其他的物理信息,如后端布局布线的电容、时序限制等信息,当变化不同的分割层时,最高能恢复67%的隐藏连接。文献[13]则提出基于机器学习的方法试图恢复隐藏连接。但这些工作[11-13]均假设分割层为M2及以上,实际为了增加芯片的安全性,分割层也可以为M1。文献[10]从理论上分析了当分割层为M1时,芯片几乎是安全的:当分割层为M1时,所有的连接线都在后序工艺层生产,攻击者得不到任何连接信息,且只能看到成千上万个没有连接的独立的门。然而,笔者提出的攻击方法表明,当分割层为M1时,攻击者仍然能利用其他的信息,如从集成电路辅助设计工具中提取有用的信息来实施硬件木马的植入。
1.2 硬件木马和攻击模型
1.2.1 硬件木马
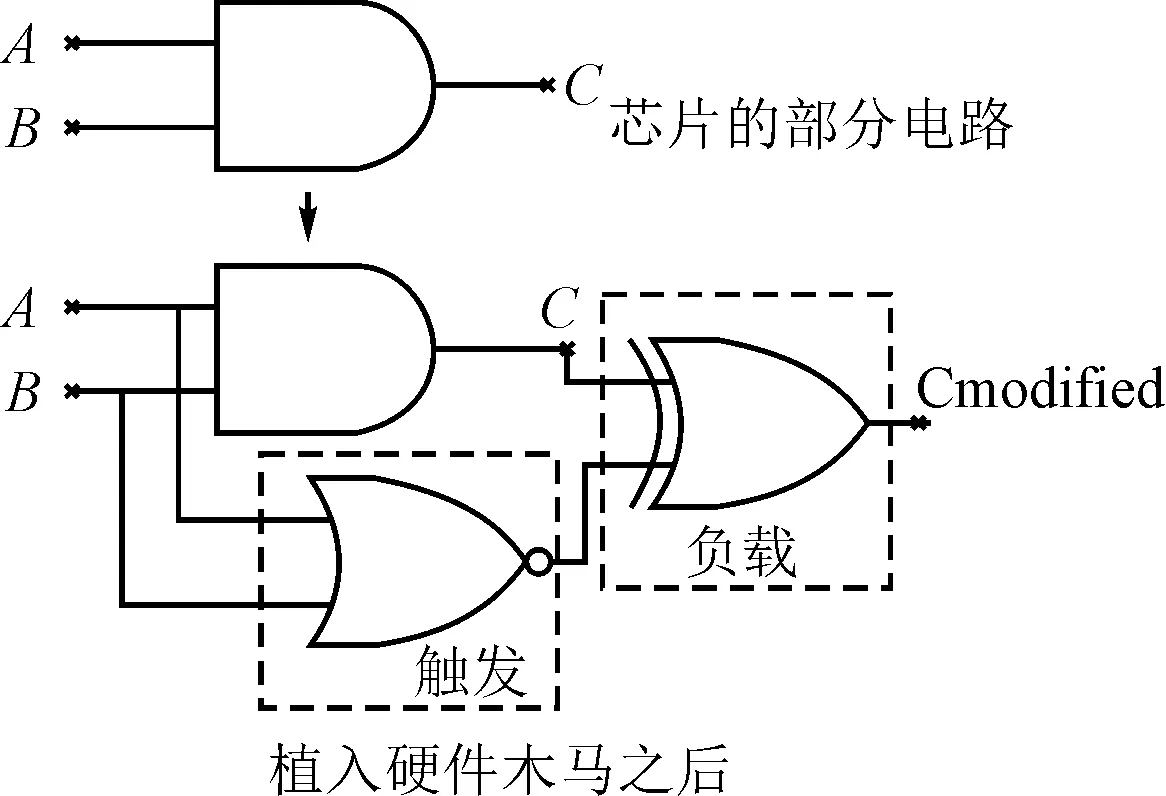
图2 典型的硬件木马
通常硬件木马包含两部分:触发电路和负载电路。当触发电路在特定输入模式下被激活时,负载电路即被激活,从而对原电路的功能造成影响。如图2 显示了对电路中某个特定门进行硬件木马植入的过程[15]:当输入A和B都为0时,触发电路被激活,导致原来的输出C由0变为 1,实现了电路功能的改变。
1.2.2 攻击模型
首先假设分块制造在制造芯片时的分割层为M1,攻击者想要在该电路的特定门(也称为目标门),即该特定门对应在前序工艺版图上的位置,植入硬件木马。由于攻击者在不可信的制造商中,其能够获得前序工艺的版图,且不能从该版图中获得电路的任何连接信息,但能识别版图中每个门的类型及正确地识别版图中的输入输出管脚。最后,为了成功植入硬件木马,攻击者能够花比较大的代价通过在设计公司的同伙获得电路的门级网表。
2 问题描述和攻击方法
2.1 问题描述

图3 问题描述示例
攻击者同时获得了电路的门级网表和前序工艺版图的物理信息,其目标为找到门级网表中的门在版图中可能的位置,以便进行硬件木马的植入。以如图3所示的电路为例,来形式化描述硬件木马植入问题。图3(a)为电路的门级网表,其中门集合Vn={1,2,3,4}。由于电路是在分割层为M1下制造的,攻击者只能从获得的前序工艺版图看到一些没有连接的门,如图3(c)所示,版图中门集合Vl={a,b,c,d}。攻击者的目标则为找到图3(a)中的门在图3(c)中可能匹配的门,即网表中的门与版图中门的映射φ:Vn→Vl。其中,φ(Vn(i))表示网表中第i个门在版图中可能的匹配。图3(b)为该电路实际正确匹配时的版图及连接。φc(1)=a,φc(2)=b,φc(3)=c,φc(4)=d。显然对攻击者,候选门φ并不一定是双映射,即网表中的门可能会对应版图中多个与其同类型的门。因为攻击者只知道版图中每个门的类型,但不知道其具体对应于网表中的哪个门。因此,攻击者认为网表中每个门的初始匹配为版图中所有与该门同类型的门,用φini(Vn(i))表示网表中第i个门的初始匹配。如图3(c)中门{a,c,d}为与非类型,{b}为异或类型,则有φini(2)={b};φini(i)={a,c,d},i=1,3,4。假设攻击者想要在与非类型的门‘1’中植入硬件木马,在不知道门‘1’在版图中正确位置的情况下,为保证成功,攻击者可以在所有与非门中植入。这种情况把所有与非类型的门,即门集{a,c,d}都看做门‘1’的候选门来进行硬件木马植入。然而,随着集成电路规模的增大,一个芯片中某种类型的门可能有成千上万个,这种植入木马的方法代价很高,且植入的木马容易被检测到。因此攻击者首先需要尽可能缩小目标门的候选门,再对其候选门进行选择性木马植入。
2.2 攻击方法
2.2.1 攻击流程
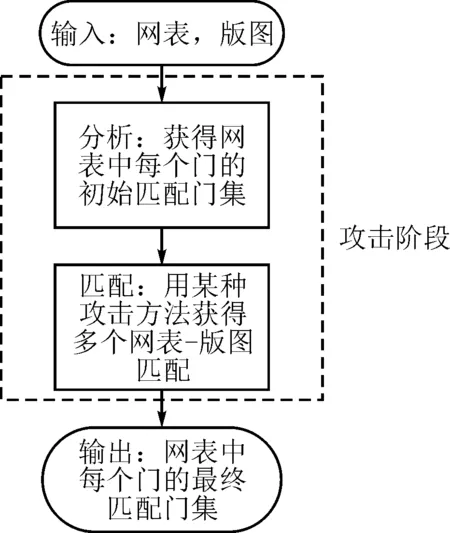
图4 攻击流程
图4为笔者提出的攻击流程。首先,需要对网表和版图中的门进行分类和编号,得到网表中每个门的初始匹配门集;其次,用某种攻击方法找到网表和版图中门的可能匹配;最后,综合通过攻击获得的多个网表-版图匹配解获得网表中每个门的最终匹配门集,即对于网表中第i个门Vn(i)的初始匹配门集φini(Vn(i))中的第j个门Vl(j),如果存在至少一个解将门Vn(i)与门Vl(j)匹配,则门Vl(j)保留在φ(Vn(i))中;否则,将其从φ(Vn(i))中剔除。
以如图3所示电路为例,假设最终通过某种攻击方法获得了N=5个匹配结果,每一个都代表一种可能的匹配,且门‘3’的N个匹配结果为{c,a,c,c,a},则综合这N个结果后,门‘3’的最终候选门为{a,c}。显然,攻击之后门‘3’的候选门的数量相对于初始候选门{a,c,d}缩小了。这是由于门‘3’的N个匹配都不包含门‘d’,因此该门被剔除了。假设攻击者原来想在门‘3’中植入硬件木马,为保证成功植入,此时只需要在门{a,c}中植入,减小了其植入硬件木马的代价和硬件木马被检测到的风险。网表-版图的可能匹配,则可以通过利用集成电路后端设计过程中泄露的不同信息得到。下面分别介绍提出的两种攻击方法。
2.2.2 近似攻击
文献[11]利用集成电路辅助设计工具在对芯片进行布局布线时,使两个相连的门尽量靠近,从而减小芯片总的线长的特性(即近似信息),提出近似攻击试图恢复隐藏的连接。如图5所示,网表中的门用下角标n来表示,如图5(a)中的门in1,表示为in1n,版图中的门用下角标l来表示,如图5(b)中的门in1, 表示为in1l。同时约定第j个门的第i个管脚命名为pini,j,如图5(a)中门‘2’的第1个管脚p1表示为pin1,2。用近似攻击恢复隐藏连接的过程如图5(b)中黑色实线部分所示。在没有任何其他信息时,近似攻击认为in1l和pin1,a相连,因为pin1,a是离in1l最近的输入管脚。
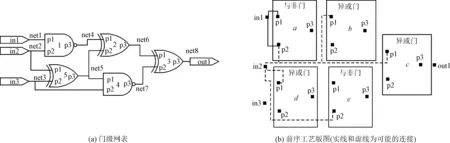
图5 攻击示例
然而,近似攻击恢复出来的电路与实际的网表可能差别很大,如文献[12]用近似攻击恢复的隐藏连接正确率只有28.55%,因此不能直接用来找到目标门在版图中可能的位置。另一方面,近似攻击只利用了局部的物理信息。实际上,尽管分割层为M1时攻击者不能从版图得到额外的连接信息,但仍可以从门级网表和集成电路辅助设计工具中提取更多有用的信息(如寄生电容和时序限制等),进而提高攻击的准确度。
基于近似攻击,笔者提出同时利用逻辑网表和近似信息的攻击方法——基于电路节点线长的近似攻击(Proximity Attack Net-based, PANet),来找到网表-版图的可能匹配。近似攻击将集成电路辅助设计工具,在进行后端布局时最小化总线长,从而使每个电路节点的线长趋于最小的特点作为近似信息,同时结合门级网表的逻辑连接对版图和网表进行匹配。其中,电路节点的线长用该节点包含的所有管脚围成的矩形的半周长作为其线长的估计(Half Perimeter Wire Length,HPWL)。最后,在介绍近似攻击详细的步骤之前有两点需要说明:首先同类型的管脚指其所属门的类型和该管脚的位置都相同的管脚。如图5(b),{pin1,a, pin1,e}是同类型的管脚,而{pin1,a, pin1,b}和{pin1,a, pin2,e}都不是同类型的管脚,因为它们所属门的类型和位置分别不相同;其次,由于攻击者知道版图中每个门的类型,任意一个管脚只能与其同类型的管脚进行匹配,且对于一个门若其任意一个管脚与另一个门的管脚做了匹配,则这两个管脚所属的门和这两个门剩余未匹配的管脚相互匹配。如图5所示,假设pin1,1和pin1,a匹配,则门‘1’和门‘a’匹配,同时{pin2,1, pin3,1}和{pin2,a,pin3,a}分别匹配。
用图5中的电路来说明近似攻击的攻击过程。首先匹配输入输出门。由1.2.2节可知,攻击者可以获得门级网表,且输入输出门在版图中的位置可以直接得到,即门{in1n,in2n,in3n,out1n}与门{in1l,in2l, in3l,out1l}分别匹配。之后每次随机地选择一个还存在未匹配管脚的电路节点(初始为任意输入输出管脚所在的电路节点),接下来对这个电路节点的所有未匹配的管脚依次用近似信息找到其在版图中的位置,即近似攻击把在版图中使得该节点的线长最短的同类型管脚看作是该管脚可能的匹配。如图5(a)和5(b)虚线部分所示,假设初始选择in2n,其所在电路节点为net2,且net2中未匹配的管脚有{pin2,1,pin1,5},近似攻击首先对pin2,1进行匹配,再对pin1,5进行匹配。对于pin2,1,其可能匹配对象为其所有未匹配的同类型管脚,即{pin2,a, pin2,e}, 此时近似攻击选择pin2,a为其匹配的管脚,因其使得版图中net2的线长(in2l, pin2,a围成的矩形的半周长)更短, 则门‘1’即与门‘a’匹配。接着匹配pin1,5,其可能的匹配对象为{pin1,b,pin1,c,pin1,d},同样,当把pin1,5匹配为pin1,d时,net2的线长最短(此时为in2l,pin2,a,pin1,d围成的矩形),则门‘5’与门‘d’匹配。以上过程一直重复,直至所有的门都匹配完成,即得到一个网表-版图的可能匹配。
2.2.3 遗传算法攻击
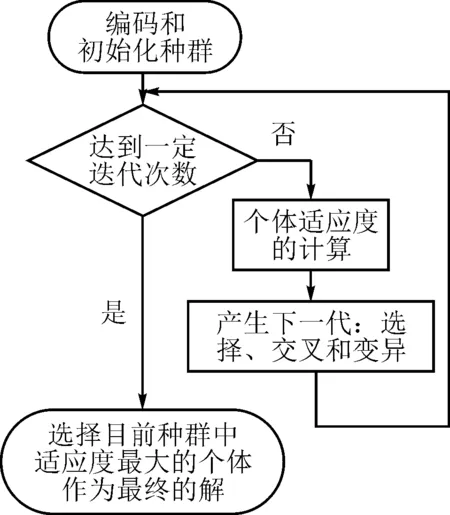
图6 GA攻击流程
在对电路进行布局布线时,主要的目标是最小化总线长,不同于PANet 利用了版图的局部信息,基于遗传算法的攻击(Genetic Algorithm based attack, GA)通过最小化总线长来获得网表-版图的可能匹配,即利用了全局连接信息。提出的基于遗传算法的攻击方法的攻击流程如图6所示。
(1)编码和初始化种群。假设电路有|Vn|个门,则一个个体有|Vn|个基因片段。同时,若第i个基因片段的值为j,即表示网表中第i个门Vn(i)与版图中的第j个门Vl(j)匹配。因此,一个个体即表示一个可能的网表-版图匹配。值得注意的是,由于一个网表-版图匹配是双映射,因此不存在版图中的同一个门与网表中的两个或多个门同时匹配,也即一个个体的所有基因都不相同。如图5所示,|Vn|=5,则该电路的个体基因长度为5,假设某个体的编码为x={a,c,d,e,b},则表示网表中的门{1,2,3,4,5}分别与版图中的门{a,c,d,e,b}匹配。最后随机生成Ngroup个个体,即随机产生Ngroup个可能的网表-版图匹配作为初始种群。
(2)个体适应度的计算。一个个体x表示一个可能的网表-版图匹配,即一个可能的版图布局,则根据网表的连接关系,该个体对应的布局的总线长可以表示为
(1)
其中,Nnet表示网表中电路节点的个数。为了最小化总线长,可用总线长的倒数来表示该个体的适应度ffitness,即
(2)
显然,适应度越大,该个体对应的解的总线长越短。
(3)产生下一代群体。为了保证每次迭代使得解朝全局最优的方向进行,主要通过三步来产生下一代群体:①保留上一代适应度为前10%的个体直接作为下一代。②用轮盘赌的方法随机选择两个个体作为父母进行交叉,得到剩余90%的新个体。不同于一般的交叉过程,随机选择父母的部分基因片段进行交换得到新的个体,交叉方法可定义为:每次首先随机选择一个类型的门,然后交换父母个体中所有该类型的门对应的基因来得到新个体。这种交叉方法既避免了获得的新个体的基因出现重复,又保证了新个体表示的网表-版图匹配解中每个门只与其同类型的门匹配。如图5中,假设两个父母的基因型分别为P1={e,b,d,a,c},P2={e,b,c,a,d},且交叉时选择的门类型为异或门,则此时父母需要进行交叉的基因片段是基因型为异或门的所有基因,即基因型为{b,c,d}的基因片段,因此P1和P2交叉之后得到的新个体为Pnew={e,b,c,a,d}。③对新个体进行变异。与交叉过程类似,为了保证变异之后的个体的基因不重复,且其表示的匹配解中门只与其同类型的门匹配,每次以概率为Pmutating随机选择该个体中基因型对应的门类型相同的两个基因,进行交换作为变异。例如对于新个体Pnew,假设选择的是其第1个和第4个基因,显然这两个基因值满足对应的门类型相同,即分别对应为门‘e’和门‘a’且都为与非门,因此新个体Pnew变异之后的基因为Pnew={a,b,c,e,d}。
(4)迭代一定次数后,选择该群体中适应度最大的个体作为此次攻击最终的匹配解。遗传算法中判断迭代停止的方式一般有两种:①利用迭代差,即迭代前后适应度的精度是否满足预设的精度;②事先统计出进化的次数。由于实验使用的基准电路的规模差别较大,如果使用迭代差作为终止条件,则不能很好地权衡最优解与算法运行效率。而基准电路有一定的共性,可以通过事先对某几个电路进行分析,统计得到每个基准电路进化的次数。因此,可用是否达到迭代次数Ng作为终止条件。
基于电路节点线长的近似攻击每次都随机地从未完全匹配的电路节点中选择一个进行匹配,基于遗传算法攻击的解则跟种群的初始值有关,因此两种攻击方法每次得到的解不同。同时,每次运行得到的解都是最有可能的匹配。因此为了使每个门的可能匹配门出现,需要得到足够多可能的匹配。3.2.1节显示运行次数N的值与基准电路中门的类型和数量有关,需要在实验中确定。
3 研究结果
3.1 衡量指标
通常,连接正确恢复率可以衡量恢复隐藏连接的正确率,汉明距离可以衡量恢复出的电路功能与原功能的差距[7]。文中攻击者的主要目标是缩小网表中每个门的候选门,同时保证每个门的候选门尽可能包含其正确匹配的门。当某个门的候选门数量很小,但其候选门不包含其正确匹配的门时,对于想要在该门植入硬件木马的攻击者,该植入是无效的。显然,连接正确恢复率和汉明距离都不能直接衡量文中提出的攻击方法的准确性和有效性。用文献[16]提出的有效匹配门集比(Effective Mapped Set Ratio, EMSR)和匹配门集平均剪枝比(Average Mapped Set Pruning Ratio, AMSPR)来作为衡量指标。有效匹配门集比fEMSR可表示为
(3)
其中,|Vn|为电路中门的个数,φ(Vn(i))为网表中第i个门的候选门,φc(Vn(i))为网表中第i个门的正确匹配的门。若φ(Vn(i))包含φc(Vn(i)),则|φ(Vn(i))∩φc(Vn(i))|为1;否则,为0。有效匹配门集比衡量了攻击的有效性,其值越大,攻击者得到的有效候选门越多,攻击越有效。
匹配门集平均剪枝比fAMSPR可表示为
(4)
其中,φini(Vn(i))为网表中第i个门的初始候选门。显然,匹配门集平均剪枝比反应了攻击方法对初始门的剪枝效果,其值越大,攻击方法得到的候选门的平均尺寸越小,攻击越有效。
3.2 实验结果
用ISCAS-85基准电路[17]来验证提出的攻击方法的有效性,其中用俄亥俄州立大学提供的开源工艺库对该电路做综合,用FastPlace3[18]对电路做布局。实验平台为8 Intel Core i7-3770 CPU@3.4 GHz和24 GB内存的Linux主机。
3.2.1 GA迭代次数和参数设定
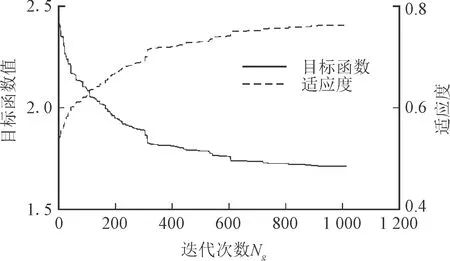
图7 遗传算法目标函数和适应度与迭代次数
图7为基准电路c432b在用遗传算法进行匹配时,其目标函数和适应度与迭代次数Ng的关系。随着迭代次数的增加,种群的最优个体的适应度在增加,而总线长在减少。当达到一定的迭代次数时,目标函数值趋于稳定。因此,为了减少单次遗传算法攻击运行的时间,需要选择合适的迭代次数Ng,这里选择c432b的迭代次数为400,其他基准电路的Ng值如表1所示。最后,为了使门的所有可能匹配门出现且消除不可能的门,每种攻击方法需要运行一定的次数N。若N太小,则正确的门可能不会出现;若N太大,则会造成总体运行时间的浪费。实验结果显示,N值与基准电路中最大相同类型门的数量相关,在实验中,N值与最大同类型门数量大致相同。
表1列出了实验中每个基准电路的特性和一些参数的设定。
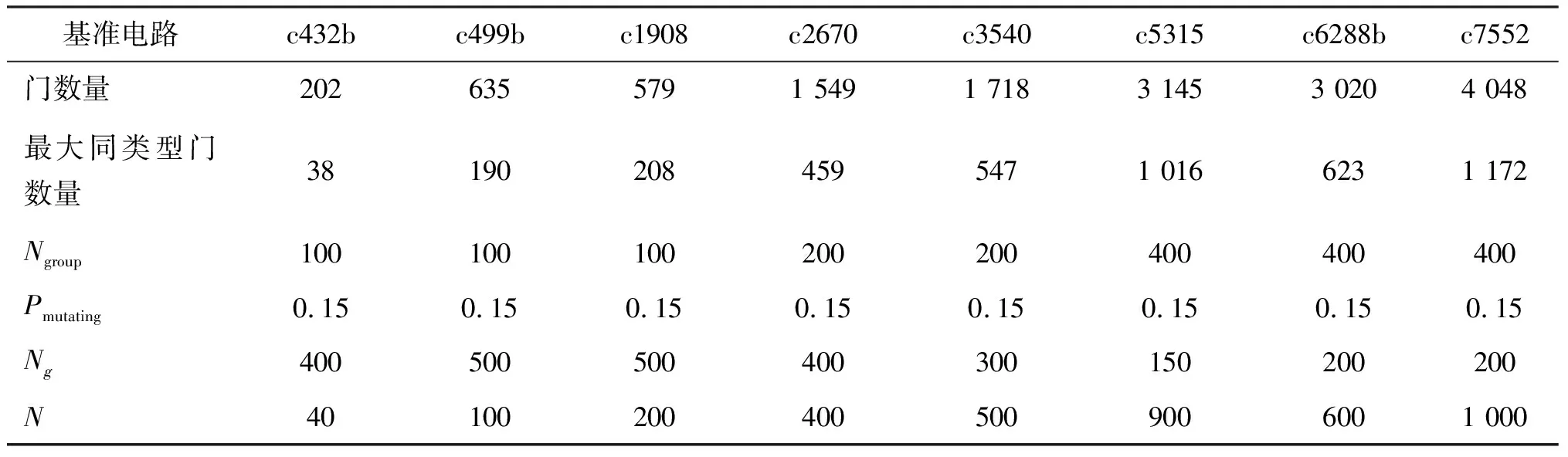
表1 基准电路门特性和实验参数设置
3.2.2 攻击效果
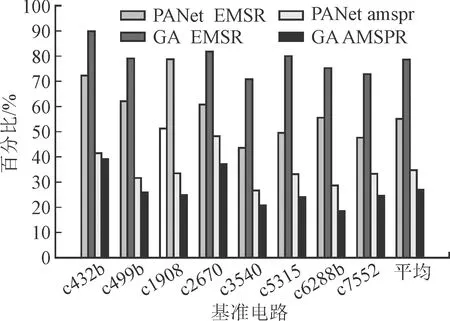
图8 攻击效果
得到基于电路节点线长的近似攻击和遗传算法攻击之后的N个网表-版图匹配解,根据攻击流程图4,可以得到网表中每个门最终的候选门。最后由式(3)和式(4)可以计算得到每个基准电路在两种攻击方法下的有效匹配门集比和匹配门集平均剪枝比,如图8所示。图8显示,PANet和GA攻击之后8个基准电路候选门的有效匹配门集比的平均值分别为55.36%、78.62%,即攻击之后最高有78.62%的候选门包含其正确匹配的门。两种方法的匹配门集平均剪枝比分别为34.65%、26.91%,即候选门的平均剪枝率最高为34.65%,表明攻击之后候选门的平均大小至少减少了1/3,极大地减少了攻击者植入硬件木马的代价。最后,两种攻击方法攻击效果的差别在于利用了不同的物理信息。遗传算法攻击利用了全局信息即集成电路工具做布局时使电路的总线长最小,而基于电路节点线长的近似攻击利用了局部近似信息,因此遗传算法攻击得到的门的候选门集范围更大,准确性更高。也证明了即使当分割层为M1时,分块制造仍然是不安全的,攻击者仍然可以利用其他的信息减小其植入硬件木马的代价,从而对芯片的安全性造成威胁。
4 结束语
笔者针对分块制造下芯片可能遭受的安全问题,不同于前人提出的攻击目标主要为恢复电路的隐藏连接。笔者首先提出了新的攻击模型:分块制造的分割层为第1层金属层,攻击者可以获得电路的门级网表,且其目标为对电路中的特定门进行硬件木马植入。之后,针对这种攻击模型提出了两种攻击方法来找到目标门在版图中的可能匹配,即基于电路节点线长的近似攻击和基于遗传算法机制的遗传算法攻击。这两种方法分别利用了集成电路设计工具对电路进行后端设计时泄露的局部和全局连接信息。实验结果表明,这两种攻击方法可以有效地减小攻击者植入硬件木马的代价,也证明了分块制造本身在防护芯片遭受硬件木马攻击的安全性是不够的。文中的不足在于,缺少相应的防御机制来提高分块制造防护芯片遭受硬件木马攻击的安全性,这也是今后需要研究的方向。
