基于深度学习的井下巷道行人视觉定位算法
2019-07-31韩江洪袁稼轩卫星陆阳
韩江洪 袁稼轩 卫星 陆阳

摘 要:自主驾驶矿井机车需要实时检测和定位行驶前方的巷道行人,激光雷达等非视觉类方法成本高昂,而传统基于特征提取视觉类方法无法解决井下光照差且光线不均匀的问题。提出一种基于深度学习的井下巷道行人视觉定位算法。首先给出基于深度学习网络的系统整体结构;其次,搭建目标检测多层卷积神经网络(CNN),生成自主驾驶机车前方视野范围内行人的二维坐标及边界框的尺寸;再次,通过多项式拟合计算出图像中行人到机车之间的第三维距离;最后通过真实样本集实施模型训练、验证与测试。实验结果表明,所提算法的检测准确率达94%,速度达每秒25帧,测距误差小于4%,实现了实时高效的巷道行人视觉定位。
关键词:深度学习;卷积神经网络;巷道行人检测;视觉定位;图像处理
中图分类号: TP391.4
文献标志码:A
文章编号:1001-9081(2019)03-0688-07
Abstract: The self-driving mine locomotive needs to detect and locate pedestrians in front of it in the underground roadway in real-time. Non-visual methods such as laser radar are costly, while traditional visual methods based on feature extraction cannot solve the problem of poor illumination and uneven light in the laneway. To solve the problem, a pedestrian visual positioning algorithm for underground roadway based on deep learning was proposed. Firstly, the overall structure of the system based on deep learning network was given. Secondly, a multi-layer Convolutional Neural Network (CNN) for object detection was built to calculate the two-dimensional coordinates and the size of bounding box of pedestrians in visual field of the self-driving locomotive. Thirdly, the third-dimensional distance between the pedestrian in the image and the locomotive was calculated by polynomial fitting. Finally, the model was trained, verified and tested through real sample sets. Experimental results show that the accuracy of the proposed algorithm reaches 94%, the speed achieves 25 frames per second, and the distance detection error is less than 4%, thus efficient and real-time laneway pedestrian visual positioning is realized.
Key words: deep learning; Convolutional Neural Network (CNN); laneway pedestrian detection; visual positioning; image processing
0 引言
近年來,随着市场对驾驶安全和智能化需求的不断提高,无人驾驶巨大的社会和经济价值越发凸显[1]。无人驾驶系统在民用、科学研究、军事、工业等方面获得广泛应用。其中在工业方面则针对具有繁重的运输任务、有事故风险的井下工作环境来代替人工来完成采矿、运输等任务。不同于一般的驾驶环境,工业轨道运输环境受井下空间和运输矿物的影响,容易导致事故的发生,且一旦发生事故极易造成人员伤亡或引发爆炸等严重后果。因此,为了从根本上减少机车运行事故的发生,杜绝人员伤亡现象的出现,有必要对无人矿井机车前方行人进行动态感知、识别分析处理,做到及时启/停和提前预警。
行人检测技术多用于地面、街道等交通场景,以方向梯度直方图(Histogram of Oriented Gradients, HOG)、可变形部件模型(Deformable Part Model, DPM)、决策森林(Decision Forest, DF)为例,主要服务于智能交通和地面无人驾驶。由于井下环境照明条件恶劣、灰尘大、光线不均匀等,无法将地面检测方法照搬。井下传统的图像处理技术有李晓明等[2]在传统Hough变化的基础上提出了极角极径约束法,标定出轨道线,在此基础上标定出感兴趣区域,利用HOG特征结合支持向量机(Support Vector Machine, SVM)进行行人检测。这种基于传统图像处理的技术需要人工设计不同的特征提取算子,并且这些特征提取算子需要靠资深专家进行手工设计,更新迭代速度较慢且对行人的多样性变化没有很强的鲁棒性。然而,深度学习却在此领域取得了突破性的进展,行人检测作为目标检测的一个重要分支,成为研究的热点之一[3-7]。同时。在井下行人检测方面也得到应用。如郑嘉祺[8]提出了一种基于深度卷积神经网络(Deep Convolutional Neural Network, DCNN)的矿井下行人检测技术,利用YOLO(You Only Look Once)[9]目标检测算法,并针对井下特殊环境的特点对其进行改进,提高了检测速度;王琳等[10]提出了以YOLO网络为基础,结合金字塔场景解析的网络中的金字塔池化模块的检测技术,利用了图片的上下文信息,对井下行人进行实时检测;李伟山等[11]提出了改进的Faster R-CNN(Region Convolutional Neural Network, R-CNN)[12]煤矿井下行人检测方法,一定程度上提高了井下行人的多尺度的检测效果;这些方法未能充分利用井下行人数据的特点,本质上均是在二维平面对行人进行了识别、定位,并且其检测结果未能对井下机车安全行驶带来很好的保障作用,具有应用的局限性。
为此,本文将行人检测与视觉测距算法相结合,进行测距得到巷道行人距离机车的实际距离。当前视觉测距的方法有单目测距和双目测距。双目测距[13]需要使用两个不同角度的相机从不同角度获取两幅图像,然后通过物体匹配和几何原理,得到三维信息;然而,双目视觉测距成像速度慢,系统复杂,不能实现实时计算,于是,单目视觉测距[14-15]凭借自身原理简单、检测速度快的特点,成为视觉测距的主流技术。但是,目前还未有成熟且公认的高精度井下行人视觉测距算法,所以,本文提出了一种基于深度学习的井下巷道行人视觉定位算法,实时检测机车前方视野范围内行人,并计算出行人与机车之间的距离,旨在从根本上减少机车运行事故的发生,杜绝人员伤亡现象的发生。
本文整体结构如下:第1节介绍井下巷道视觉定位检测系统模型;第2节介绍井下巷道行人检测模型的设计原理及详细网络结构;第3节介绍测距方法原理;第4节给出实验结果及分析;第5节阐述论文结论。
1 视觉定位检测系统模型设计
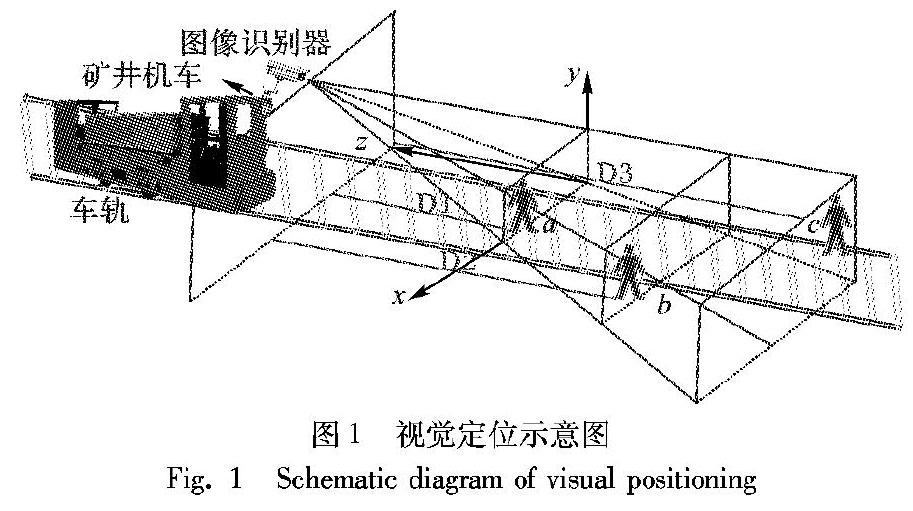
井下巷道行人的视觉定位检测结构如图1所示,机车视频图像处理器作为无人自主驾驶机车感知部件,需要动态地对拍摄到的轨道正前方视野画面进行识别得到行人信息,并传递给控制部件完成启/停、加减速等操作,达到无人自主驾驶的目的。上述图像识别器的关键作用为视觉定位,图像识别器要动态获知视野范围内有无行人,若有则给出其“三维坐标”,即(x,y,z)。如图1:b处于安全区域内,行车通过无影响;c处于预警区域内,需鸣笛示警;a处于危险区域,应立即停车,进而提高无人驾驶机车的安全性能。
为实现上述目标,本文将行人检测算法与测距算法相结合,设计整体算法系统模型(如图2所示),系统主要分为井下巷道行人检测模型与测距模型,行人检测模型要解决的核心问题是,检测出图像中任何位置出现的不同尺度大小和各种姿态的行人,并确定他们在二维图像上的位置及大小,整个检测流程舍去了候选框提取分支,直接将特征提取、候选框,回归和分类在同一个无分支的卷积网络中完成,使得网络结构变得简单;测距模块负责将行人检测模块得到的检测结果中的行人的宽,高输入到实验训练时已经拟合完成的距离曲线中,计算出图像中机车前方行人距离机车的实际距离。最后输出一张标有目標行人及行人距离机车的实际距离的图片,实现巷道行人检测的“三维定位”。
2 行人检测网络
井下巷道行人检测算法借鉴YOLO的基本思想,从而实现自己的检测效果。YOLO的核心思想是系统将输入图像分成S×S的网格。如果目标的中心落入某个网格单元中,那么该网格单元就负责检测该目标。每个网格单元都会预测B个边界框和这些框的置信度分数。这些置信度分数反映了该模型对那个框内是否包含目标的概率,以及它对自己的预测的准确度的估量。在形式上,将置信度定义如下:
如果该单元格中不存在目标,则置信度分数应为零。否则,置信度分数等于预测框与真实标签框之间联合部分的交集。每个边界框包含5个预测:x、y、w、h和置信度。(x,y)坐标表示边界框的中心相对于网格单元的边界的值,而宽度和高度则是相对于整张图像来预测的。置信度预测表示预测框与任意实际边界框之间的IOU。每个网格单元还预测C个条件类别概率Pr(Class|Object),这些概率以包含目标的网格单元为条件。在测试时,将条件类别概率与每个框的预测的置信度值相乘即可得到每个框的特定类别的置信分数:
这些分数体现了该类出现在框中的概率以及预测框拟合目标的程度。
2.1 锚点框选取
在井下巷道行人检测网络训练过程中,图像中的锚点尺寸对于行人检测的位置预测影响重大,故选择出符合数据集的锚点框尤为关键。相对于手工挑选锚点框尺寸,本文在数据集边界框上运行k-means聚类算法,让网络自动找到最好的锚点框,提高收敛速度,提高行人检测的位置精度。随着迭代次数的不断增加,网络学习到行人特征,预测框参数得到不断调整,最终逼近真实框。分析井下特定的图像数据,井下行人服饰相对统一,相对于路面或者生活中的人,行走姿态相对单一,得到与图像中行人边界框较好的先验的9种锚点尺寸。
K-means聚类采用欧氏距离衡量两点之间的距离。聚类的目标函数为:
2.2 网络结构
本文提出的基于深度学习的井下巷道行人视觉定位算法中行人检测模型(如图3所示),网络模型由53个卷积层,2个上采样层和一个检测层组成。模型前端是用来提取图片特征向量的卷积神经网络(Convolutional Neural Network, CNN),其中运用了残差网络更好地提取特征。后端通过卷积生成不同大小的特征图,采用3种尺度预测,将之前生成的9种聚类,按照大小分给3个尺度,这样做充分利用不同卷积层得到的特征图分辨率不同的特性,即低卷积层分辨率高,有利于检测小目标,高卷积层感受野大,有利于检测大目标。同时,在卷积层利用1×1、3×3卷积核,提取细节特征,更有利于检测小目标行人。具体网络参数如表2。
表2中空格表示此层网络无此参数,在实际网络结构中,编号为11、12、13层网络组成一个模块连续循环4遍,编号为15、16、17层网络也组成一个模块连续循环4遍,编号19、20、21层网络组成一个模块连续循环2遍,此目的为了更好地提取图像特征。
2.3 损失函数
损失函数(loss function)是用来估量模型的预测值与真实值的不一致程度,损失函数越小,模型的鲁棒性就越强。在训练过程中,由于大多数样本都是简单易区分的负样本即背景样本,类别不均衡,致使训练过程中不能充分学习到正样本的特征信息,其次简单的背景样本太多,易分背景样本会产生一定幅度的损失,加之数量巨大,最终会对损失函数起到主要的贡献作用,从而导致梯度更新方向发生变化,掩盖正样本的作用。
针对上述问题,本文结合focal loss function[16]作为解决类别不均衡的更高效的替代方法。它能动态地缩放交叉熵,随着正确类别的置信度增加,其中的尺度因子衰减到零。直观感受,这个缩放因子可以自动减小训练过程中easy example的贡献的比例并快速聚焦hard examples。使用的交叉熵损失函数如下:
这个缩放因子可以自动降低训练时easy example贡献的比重,快速地focus hard examples的模型。由于使用的交叉上损失函数如下:
3 基于行人检测的实时测距方法
实时测距方法基于单目视觉来检测机车与前方行人的距离,从而为无人驾驶机车智能化控制输入参数。摄像机拍摄到的场景图像是三维空间场景在二维平面的投影,而在利用机器视觉对巷道前方道路情况进行识别过程中,则需要一个逆向求解的过程,即从二维图像还原成路面真实图像。此过程就是巷道前方道路深度信息的获取。根据小孔成像原理,将单目视觉系统简化为摄像机投影模型(如图4所示)。
如图4中(b)所示,距离计算,在直观意义上,当距离确定时,较大行人在图片上相对较大,对于一个物体,更远的距离意味着物体的像素尺寸更小。对于行人来说,距离和图像中行人的像素大小成反比。
根据所去矿井统计井下行人的平均身高为173cm,在这里将井下巷道的行人身高记为173cm。根据以上结论,将巷道行人的身高看作固定参数,用H表示,用行人检测算法模块得到的行人边界框的高bh表示巷道行人在图像平面上的像素高度。用D表示相机与对象行人之间的实际距离。所以,井下巷道行人与相机间的实际距离遵循以下等式:
H是固定的,c是一个常数,对于不同的相机c是不一样的,故实验使用多组D和bh拟合函数曲线,最后可以得到相机的c。
为了保证检测的准确性,当检测到的行人的宽度bw与高度bh的比值超过特定阈值时,即行人可能处于蹲坐状态,则采取将行人高度强行提高3倍,以避免测距发生错误。
4 实验
本文实验主要分为两部分:一部分是井下巷道的行人检测实验,负责检测图片中井下巷道行人及行人边界框位置,为后期距离计算提供数据源;另一部分是测距实验,负责计算行人距机车的实际距离。
4.1 数据集扩增
本文中的矿井实验数据来自于桃园煤矿和新集煤矿的井下机车摄像头所拍摄的井下巷道视频,视频按照每秒30帧将视频转换为13400张分辨率为1280×720的图片,由于深度网络的训练数据量巨大,这些图片的数量远远不足,于是在训练之前,对图片进行扩增,主要使用的扩增方式有以下几种(如图5)。
1)旋转变换(rotation):随机将图像旋转一定角度。
2)翻转变换(flip):对图像作翻转变换。
3)缩放变换(zoom):缩小或放大图像。
4)对比度变换(contrast):通过改变图像像元的亮度值来改变图像像元的对比度。
5)裁剪变换(cropping):裁剪出图像中的目标物体。
扩增后数据集共19450张,其中训练集13410张,测试集3020张,验证集3020张。数据集包含了各种尺度的行人,以及昏暗条件下的图片数据,有利于增强网络的鲁棒性。
4.2 井下巷道行人检测实验
4.2.1 网络训练
整个训练过程使用随机梯度下降及反向传播算法来学习网络参数。训练的批处理大小batch为16,subversion为4,动量(momentum)为0.9,权重衰减,(decay)为0.0005,最大迭代次数为75120次。实验基于Ubuntu 16.04,64 位操作系统,使用的深度学习框架是Pytorch,GPU为GeForce GTX 1080i,初始化网络训练的学习率为0.001,经过3000次迭代后,将学习率调整为0.01,迭代10000次后将学习率调整为0.001,迭代35000次后调整学习率为0.0001,迭代60000次后调整学习率为0.00001。
训练过程中模型的损失函数收敛曲线如图6,由图可知,损失函数随着迭代次数的增加越来越接近于0,网络是稳定收敛的。
4.2.2 评价指标
召回率(Recall): 是测试集中所有正样本样例中,被正确识别为正样本的比例,计算公式如下:
其中:TP(True Positives, TP)为正样本被正确识别为正样本的数量,FN(False Negatives, FN)为正样本被錯误识别为负样本的数量。
精确度(Precision):在识别出来的图片中,TP所占的比率,计算公式如下:
其中FP(False Positives, FP)即负样本被错误识别为正样本数量。
平均精度(Average-Precision, AP):Precision-Recall 曲线下面的面积,通常来说一个越好的分类器,AP值越高,分类器性能越好。
漏检率(Miss Rate, MR):与召回率相对应,召回率与漏检率相加和为1。
平均每张图片误检数(False Positives Per Image, FPPI):平均每张图片误检测数目,公式如下:
其中Nimg为图片总数目。当评估一个识别方法性能时,通过设置不同的分数阈值,可以得到不同组(MR, FPPI)值,从而可以画出MR-FPPI曲线。
4.2.3 行人检测结果对比及分析
为进一步测试本文网络模型的检测性能,分别使用Faster R-CNN、YOLOv1和本文算法,在验证图片以评估模型检测性能,改变识别阈值IOU,阈值的变化同时会导致精确度与召回率值发生变化,从而得到曲线。得到精确度召回率曲线性能对比如图7,算法检测时间和平均精度(AP)对比数据如表3。
由图7可得,本文算法在召回率相同的情况下,检测准确度都高于Faster R-CNN、YOLOv1算法。
由表3所示,本文提出的算法检测时间仅仅需要0.04s,且准确度达到94%,达到了准确而又快速的实时检测效果。
本实验还以平均每张图片误检数(FPPI)作为横坐标,漏检率(MR)作为纵坐标,对Faster R-CNN、YOLOv1和本文算法进行性能对比,如图8。
从图8中可以看出,平均每张图片的误检数与漏检率呈现负相关,在对应的FPPI相同情况下,本文算法的漏检率较低,即检测性能最好。
4.3 测距实验结果
部分拟合数据如表4所示。
根据表4中的拟合数据,拟合函数如下:
测距误差是影响距离精度的重要因素之一,通过使用同一相机的另一组数据测试该方程,利用行人行走时对多个实际距离进行测距实验,并人工计算测距误差。定义测距误差为:
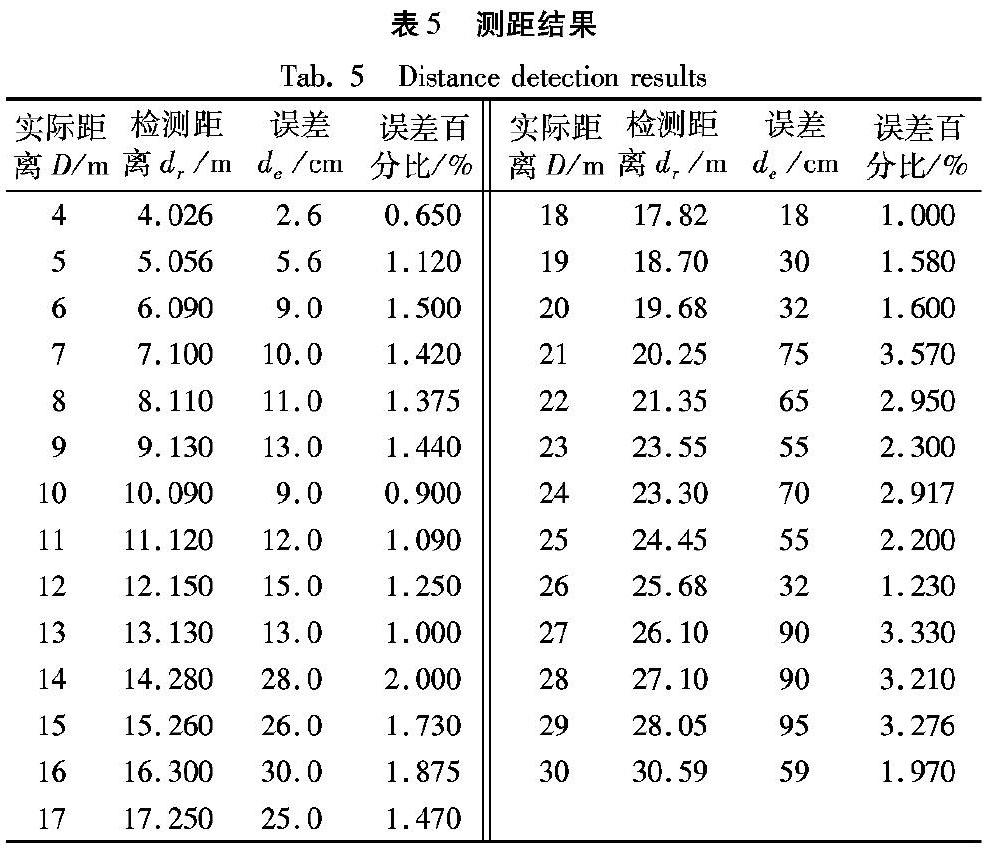
其中:D为行人到机车实际距离,测量距离为dr。式(17)计算得到每一次的误差de,同时计算出每组测量数据的误差百分比,对实际距离值D、测量值dr、误差de、误差百分比进行对比验证,结果如表5。
表5结果表明,本文算法误差控制在4%以内,证明它具有很好的适用性。
4.4 实验结果展示
图9展示了本文网络在输入不同井下场景图片时的检测结果。从图9可以看出,井下巷道行人检测定位算法取得了很好的检测及测距效果。
5 结语
针对井下巷道行人检测及距离测量问题,提出了基于深度学习的端到端的系统检测模型。在行人检测模块设计中,采用残差网络提取细粒度特征,并提取多尺度特征;同时,改进损失函数提高行人所在位置区域的精度。针对机车前方行人的距离测量问题,利用大量数据训练拟合函数,最终得到测距结果。但是,本文的研究对于整体网络复杂度相对较高,测距方法对于被遮挡行人测距检测误差较大,仍有提高空间,下一步的研究重点将放在以下两点:1)保证检测精度的前提下,降低网络复杂度;2)提升测距精度。
参考文献 (References)
[1] 乔维高,徐学进.无人驾驶汽车的发展现状及方向[J].上海汽车,2007(7):40-43.(QIAO W G, XU X J. The development situation and direction of the driverless vehicle [J]. Shanghai Auto, 2007(7):40-43.)
[2] 李晓明,郎文辉,马忠磊,等.基于图像处理的井下机车行人检测技术[J].煤矿机械,2017,38(4):167-170.(LI X M, LANG W H, MA Z L, et al. Pedestrian detection technology for mine locomotive based on image processing [J]. Coal Mine Machinery, 2017, 38(4): 167-170.)
[3] LIU T, FU H Y, WEN Q, et al. Extended faster R-CNN for long distance human detection: finding pedestrians in UAV images [C]// Proceedings of the 2018 IEEE International Conference on Consumer Electronics. Piscataway, NJ: IEEE, 2018: 1-2.
[4] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2014: 580-587.
[5] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[6] GIRSHICK R. Fast R-CNN [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2015: 1440-1448.
[7] REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 6517-6525.
[8] 鄭嘉祺.基于DCNN的井下行人检测系统的研究与设计[D].西安:西安科技大学,2017:84-87.(ZHENG J Q. Research and design on pedestrian detection system under the mine based on DCNN[D]. Xi'an: Xi'an University of Science and Technology, 2017:84-87.)
[9] REDMON J, DIWALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 779-788.
[10] 王琳,卫晨,李伟山,张钰良.结合金字塔池化模块的YOLOv2的井下行人检测[J/OL].计算机工程与应用:1-9[2018-07-15].(WANG L, WEI C, LI W S, et al. Pedestrian detection based on YOLOv2 with pyramid pooling module in underground coal mine[J/OL]. Computer Engineering and Applications: 1-9[2018-07-15])http://kns.cnki.net/kcms/detail/11.2127.TP.20180410.1054.002.html.
王琳,卫晨,李伟山,等.结合金字塔池化模块的YOLOv2的井下行人检测[EB/OL]. [2018-05-21]. https://www.doc88.com/p-0714870779937.html.(WANG L, WEI C, LI W S, et al. Pedestrian detection based on YOLOv2 with pyramid pooling module in underground coal mine [EB/OL]. [2018-05-21]. https://www.doc88.com/p-0714870779937.html.)
[11] 李伟山,卫晨,王琳.改进的Faster R-CNN煤矿井下行人检测算法[J/OL].计算机工程与应用:1-16[2018-07-15].(LI W S, WEI C, WANG L. An improved Faster R-CNN Approach for pedestrian detection in underground coal mine[J/OL]. Computer Engineering and Applications: 1-16[2018-07-15])http://kns.cnki.net/kcms/detail/11.2127.TP.20180522.0944.002.html.
李伟山,卫晨,王琳.改进的Faster R-CNN煤矿井下行人检测算法 [EB/OL]. [2018-07-15]. http://kns.cnki.net/kcms/detail/11.2127.TP.20180522.0944.002.html.(LI W S, WEI C, WANG L. An improved faster R-CNN approach for pedestrian detection in underground coal mine [EB/OL]. [2018-07-15]. http://kns.cnki.net/kcms/detail/11.2127.TP.20180522.0944.002.html.)
[12] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(6): 1137-1149.
[13] 沈彤,劉文波,王京.基于双目立体视觉的目标测距系统[J].电子测量技术,2015,38(4):52-54.(SHEN T, LIU W B, WANG J. Distance measurement system based on binocular stereo vision [J]. Electronic Measurement Technology, 2015, 38(4): 52-54.)
[14] 郭磊,徐友春,李克强,等.基于单目视觉的实时测距方法研究[J]. 中国图象图形学报,2006,11(1):74-81.(GUO L, XU Y C, LI K Q, et al. Study on real-time distance detection based on monocular vision technique [J]. Journal of Image and Graphics, 2006, 11(1): 74-81.)
[15] BAO D, WANG P. Vehicle distance detection based on monocular vision [C]// Proceedings of the 2016 International Conference on Progress in Informatics and Computing. Piscataway, NJ: IEEE, 2016:187-191.
[16] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, PP(99): 2999-3007.
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2017: 2999-3007.