应用随机森林模式识别的土壤肥力评价
2019-07-23田钰朝徐明德
田钰朝,徐明德
(太原理工大学 环境科学与工程学院,山西 太原 030024)
土壤是地球陆地表层五大生态圈层进行生物、物理、化学能量迁移转化的多界面矿质综合体,作为人类生存发展和维系生态系统正常运转的基质,土壤肥力质量演进对于陆地生态系统具有深刻意义[1].土壤肥力意指其为植物生长提供所需的营养成分、环境条件的能力[1-2],由于广受时空维度的随机性与结构因子的非均质反馈,土壤质量属性分布模式呈现一定复杂性,因此探究其综合质量特征,可揭示环境因子的影响速率与方向,深刻认识土壤发育格局与元素生物地球化学过程[3].
肥力质量测评在于客观反映区域土壤养分综合水平,为土壤质量管理、环境调控提供决策依据.对此,学者们进行了广泛探索,其以单一指标表征的养分丰缺度作为基本评价测度,在归一了各指标间的量纲差异后建立参评指标与肥力质量间的模糊关系,以综合指数大小反映土壤肥力量级[4-5].代表性的测评方法有主观分析法和客观评判法,前者有诸如层析分析[6]、D数理论[7]、专家赋权法[5]等;后者有多元统计[8]、主成分分析[9]、地积累指数法[10]、熵权综合评判[11]、TOPSIS[12]等.但是上述方法均以线性函数描述指标因子与肥力量级之间的关系,在评价过程中权重分配极易受到某种单一指标的数据噪声影响,在肥力量级划分的过程中存在一定的主观性,因而评价有失客观性与现势性.而基于机器学习的模式识别理论能够较好规避上述问题[13].近年来机器学习在各学科领域中获得广泛关注,其中随机森林算法(Random Forest,RF)以其独有的优势在遥感解译、语义识别、文本分类等模式归并领域取得了良好应用效果.鉴于此,本文阐述了RF在土壤肥力测评中的应用原理、过程,以期为土壤肥力自动化测评提供参考依据.
1 材料与方法
1.1 研究区概况
试区位于广东中山市,属于珠江三角洲平原,地理坐标介于113°11′~113°31′E,22°19′~ 22°43′N,北临北回归线,属于典型的南亚热带湿润季风气候,年均温度21.8 ℃,降水量在1 300~1 600 mm之间,雨热资源丰沛.区域地形平坦,海拔在100~300 m之间,土壤由河口冲积母质发育而来,属于地带性红壤,质地偏粘.试区为水田和旱地,主要种植叶菜、蔬菜、瓜果.
1.2 土壤样品制备
样品采集时间为2013年10月.按网格布点,网格尺度为100 m*100 m,采集0~20 cm表层土壤,每份样品采样量为2 kg左右,样点共计64个.样品带回后经风干、去杂、捣碎、过筛等实验流程,对其土壤有机质(SOM)、全氮(TN)、速效氮(AN)、全磷(TP)、速效磷(AP)、速效钾(AK)等6项属性予以测定,测定方法按照土壤农化分析一般方法进行[14].
1.3 随机森林算法
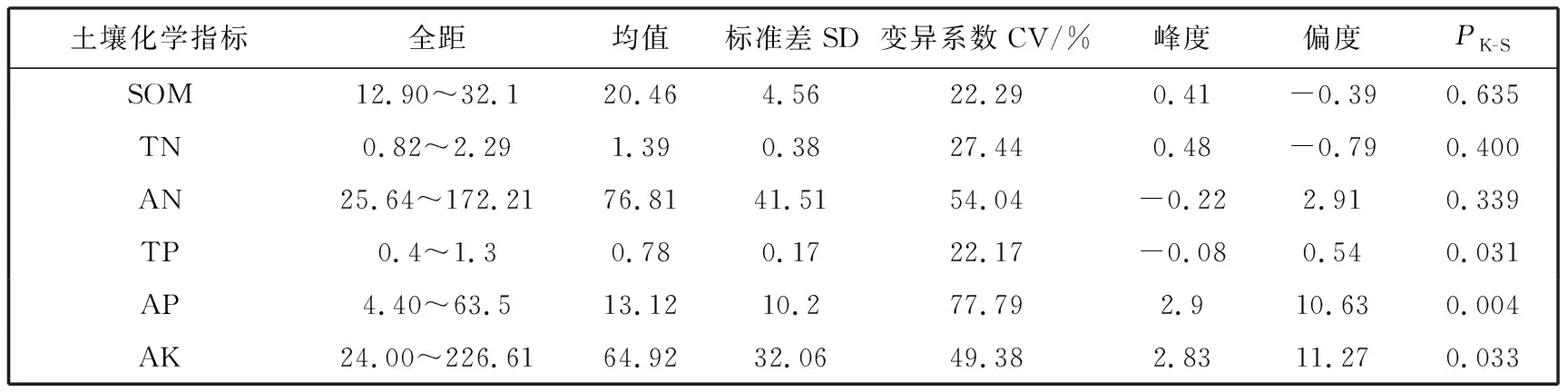
Breiman等将随机森林发展了分类回归树模型并提出组合树构成的监督学习算法[15],其基于随机子空间(random subspace)和自助聚集(bootstrap aggregating)理论,从原始m个训练样本中抽取n个训练集(n 本文将土壤肥力评价视作模式识别问题,模式类别参照《土壤环境质量评价标准》[17],各量级下养分指标因子以叶节点输入,把相应的肥力量级作为模式识别结果输出,通过训练二者间类别对应关系,对目标样本进行分类预测. 构建的机器学习模式识别的土壤肥力评价模型,关键在于依据土壤养分指标与肥力等级之间的联系构建分类规则,即将土壤单一养分与综合肥力评价问题转化为模式识别问题.模型构建步骤如下: Step 1:明确目标识别模式,本文中即为土壤肥力量级模式.土壤肥力量级模式是根据土壤环境质量分级标准(GB15618-1995)确定区域土壤养分指标及分级标准,其具体分级标准如表 1 所示.从表中可以看出,该标准将SOM、TN、AN、TP、AP、AK等主要土壤养分的丰缺度划分为6个量级,对应于不同的肥力等级,籍此作为肥力评价的标准与依据. Step 2:样本数据生成与处理.在各组肥力评价标准的标准值范围内内插生成500组训练样本,并将各指标数据进行归一化处理,以剔除量纲、噪声影响. Step 3:应用RF算法构建土壤肥力评价模型.该评价模型由6个参评因子组成,模式类别为6,将生1 200组样本数据进行建模训练. 表 1 六种参评土壤养分的分级标准 Step 4:参数设置与模型优化.模型参数对于模型的精度有着显著影响,RF模型中的ntree和mtry参数需要进行优化选取,一般需要取整[18]. Step 5:模型应用.对试区64组土壤养分数据运用土壤肥力质量评价模型进行识别,进行土壤肥力质量的综合评价. 土壤养分指标数据基本处理分析在Excel 2016中进行,运用RStudio中的Randomforest程序包进行建模训练与分类预测[19],于 ArcGIS 10.2 平台进行肥力量级空间分布可视化. 试区中土壤养分指标描述性特征如表 2 所示.从表中可以看出,试区土壤化学指标均具有中等程度的变异性,其中TP、TN和SOM的变异系数较小且相差不大,其值分别为22.17%、27.44% 和22.29%;AN、AP和AK的变异性较强,其值分别达到54.04%、77.79%和49.38%.SOM是土壤质量的基础,其含量与土壤肥力质量密切相关,试区土壤的SOM均值达到 21.04 g/kg;氮是环境和气候变化的重要因素,作为植物生长的三大营养元素之一,试区中TN和AN的含量分别为1.39 g/kg和76.81 mg/kg;磷不仅影响着土壤微生物活动及作物生产力,也对碳氮等元素的矿化等生态过程具有重要意义,试区中TP和AP含量分别为 0.78 g/kg 和 13.12 mg/kg;钾是公认的作物生长限制因素,速效钾为其直接来源,试区中AK含量相对缺乏,仅为64.92 mg/kg.综合来看,研究区土壤6种化学指标中,SOM,TN,AN,TP和AP含量属于Ⅲ级中等水平,AK处于Ⅳ级较缺乏水平.从其分布特征来看,各养分指标序列中SOM,TN和AN未能通过5%水平kolmogorov-smirnov检验,即表明这3种养分指标在试区土壤中的分布不服从正态分布;TP,AP和AK通过5%水平kolmogorov-smirnov检验,即表明这3种养分指标在试区土壤中的分布服从正态分布. 表 2 土壤化学指标描述统计 根据土壤养分实测指标数值大小将土壤的肥力进行量级划分,其空间分布如图 1 所示.虽然试区采样距离较小,但土壤属性在微域空间上亦表现出空间异质性.SOM以Ⅲ和Ⅳ级为主,呈带状分布;TN以Ⅱ和Ⅲ级分布占优,量级跨距在 Ⅰ~Ⅴ 级之间;AN则空间连续性差,以点、块状分布为主,分属于Ⅰ~Ⅴ级;TP高量级(Ⅰ、Ⅱ)区为中南部,低量级呈离散分布特征;AP具有较好的连续性,以Ⅲ级肥力为主,呈条带状分布;AK以Ⅲ级分布较为均一,集中于北部片区. 图 1 土壤养分量级空间分布Fig.1 The classification standard of six kinds of the evaluated soil nutrients 土壤为地球化学元素矿质综合体,存在复杂的生物、物理、化学方面的能量流动.试区6种土壤养分指标的皮尔逊相关性结果如表 3 所示.从表中可以看出,土壤磷素与SOM、氮素之间呈负相关,SOM与TN、AN、AK,AP与TP、AK呈正相关关系,并在0.05或0.01水平上(双侧)达到显著程度,结果表明其来源具有同质性,试区为菜园地,耕作施肥为该地土壤肥力的主要来源.其中TN与SOM的相关系数高达0.813,分析主要原因是由于前者是后者的重要的物质源. 表 3 土壤养分之间的相关性 2.3.1 随机森林模型的参数设置 本研究中,选取的模型变量为上述6个土壤养分指标,而mtry参数的最优参数应为变量个数的方根值,因此,本研究mtry参数值选择为3.ntree的优选集中于500~1 000之间.当mtry为3,ntree的值由80增加到1 000时,RF模型中的出包错误率(Out of bag,OOB)变化曲线如图 2 所示.从图 2 可知,当ntree的值大于100后,RF模型的OOB已经较小且变化趋于稳定.因此,本研究最终确定RF模型汇总mtry为3,ntree为500.训练结果表明,建模混淆矩阵错误率为0,精度达100%,表明该模型能够准确地对新样本数据进行分类预测,且具有良好的模式识别能力. 图 2 RF模型表现与参数Fig.2 The distributions of soil fertility grades 2.3.2 模型验证 应用训练好的RF模型对试区64组土壤养分指标数据进行模式归类,并在ArcGIS 10.2平台上予以直观呈现,结果如图 3 所示.从图 3 中可以看出,试区土壤肥力分属Ⅱ、Ⅲ、Ⅳ和Ⅴ共4个量级,各量级样点依次为15、21、19和9个,表明以中量级肥力为主.其中Ⅱ级肥力分布于试区北部和中部,Ⅲ和V级呈邻近分布,Ⅴ级集中于边缘地带.试区面积较小,而肥力特性分布不均衡,表明土壤空间异质性普遍存在,其中在微观田块尺度,作物类型及其耕作水平的差异是引起肥力差异性的主源. 图 3 试区土壤肥力分布Fig.3 The distribution of soil chemical fertility in research area 通过对比RF模型对土壤肥力的自动化评测结果与实际土壤肥力量化等级的结果,可以发现: 1) 训练样本的科学性.采用线性内插生成肥力量级区间内的样本数据构建训练样本,具有一定的随机性,对此有学者认为这种随机样本的建模结果存在不确定性,因而对RF预测模型性能产生一定影响[20].该试验以每组肥力量级区间生成500组随机数,丰富的样本能够较好地填充肥力量级准则区间,提高了模型的一般性,从而保证了应用RF模型进行预测时对目标样本数字的分类识别精度.而且,肥力量级评价准则明确界定了单一肥力数值与其等级,符合评价规则的随机样本经RF的bagging抽样处理,能很好地去除噪声,提升模型稳健性.因此,RF模型对该样本数据容忍度高,经过参数优化便能够有效提高模型精度. 2) RF模型对土壤肥力量级的识别.如表 1 所示的肥力量级评价规则明确,据此构造的训练样本具有良好的可分性(本实验中训练模型精度为100%).然而实际中某一样品土壤的多种肥力指标并不很好地服从某一特定肥力量级分级规则,如图2所示,1号样点的SOM、TN和AN属于Ⅱ级,TP、AK为Ⅳ级,AP属于Ⅲ级,其不同维度属性隶属于不同量级区间,增加了分类预测的复杂度.对此,RF模型在提取样本进行递归分裂时以纯度最优原则为前提,直至裂分出余量值最大、纯度最小的类别.在这一过程中,维度属性即肥力指标特性对RF模型泛化较为敏感,对于每一颗决策树,都可以得到OOB误差估计;通过增减维度指标估算OOB的增量可得出维度因子的重要性,然而在每颗决策树中其重要性是不一致的[21]. 运用随机森林机器学习算法将土壤肥力评价转化为模式识别问题,其内积函数能够模拟肥力量级与各养分指标间的多分类非线性映射关系.在模型的构建中,随机森林模型能够根据需要调节属性特征与自身形态,通过充分训练获得肥力量级识别能力,在解决了线性不可分问题的基础上,进而实现了评价结果的客观性.依靠随机森林模型维数扩充灵活的特点,可实现土壤肥力自动化评价,因而具有广泛的适用性.1.4 应用随机森林算法的土壤肥力评价流程

1.5 数据处理
2 结果与分析
2.1 土壤养分指标丰缺度评价

2.2 土壤养分指标相关性分析

2.3 应用随机森林的土壤肥力评价


3 讨 论
4 结 论
