基于非结构化数据处理的网络舆情监测系统
2019-06-24王晨妮王宇晨张超刘蓝静
王晨妮 王宇晨 张超 刘蓝静

摘 要:针对目前热点焦点问题更新频率高,企业对自身舆情监测不到位的情况,设计开发出一套完整体系性的企业网络舆情监测系统。该系统可针对企业的相关信息进行非结构化数据处理,同时利用情感分析及个性化处理技术,形成可视化的舆情分析报告,为企业分析预测自身舆情提供了完善的渠道。
关键词:数据抓取;非结构化数据处理;舆情分析;监测
中图分类号:TP391.7 文献标志码:A 文章编号:2095-2945(2019)13-0038-03
Abstract: In view of the high update frequency of hot focus issues and the fact that enterprises are not in place to monitor their own public opinion, a complete and systematic enterprise network public opinion monitoring system is designed and developed. The system can deal with the unstructured data of the relevant information of the enterprise, and at the same time use the emotional analysis and personalized processing technology to form a visual public opinion analysis report, which provides a perfect channel for the enterprise to analyze and predict its own public opinion.
Keywords: data capture; unstructured data processing; public opinion analysis; monitoring
目前,许多企业在进行舆情把控时,未能做到有效处理舆情信息并针对舆情做出及时的应对对策。通常企业内部鲜有专门设立的应对舆情的部门,而是其媒体部门负责对企业舆情进行分析并对外给出有效的回答。在此基础上,舆情分析系统成为了企业内部进行舆情应对的一大工具,其可帮助分析调研数据,给出统计结论,并根据分析结果给出具有一定参考性的预警预测,这在当今信息爆炸的时代背景下具有鲜明的商业可拓展性。而本文所述的研究具有更实际的意义,从技术层面对目前的舆情技术进行革新。网络舆情形式多元化,信息量级十分庞大,且大多均为图片、文段等非结构化的数据类型。目前市面上对非结构化数据的处理还较为薄弱,而本研究针对这一市场痛点,对文本处理的技术进行了深度优化,有效解决企业对舆情的情感判别问题。从而企业可以直观地了解舆情情况,并针对系统分析得到的统计结果得出应对方案。
1 网络舆情系统的相关技术
1.1 网络爬虫技术
在爬虫算法的基础上进行改进,主要包含网络请求模块、流程控制模块、内容解析模块和链接去重模块。其中网络请求模块主要负责根据URL链接向服务器发送http请求,并获取响应内容;流程控制模块负责组织调度各个功能模块和控制URL列表的爬取顺序;内容解析模块负责处理网络请求获得的响应,其中大部分响应为JSON格式的数据,本文采用BeautifulSoup库对返回的响应进行解析;链接去重模块主要负责对待爬取的URL进行选择,去掉重复的URL,同时对解析之后的响应内容进行文本去重化处理。
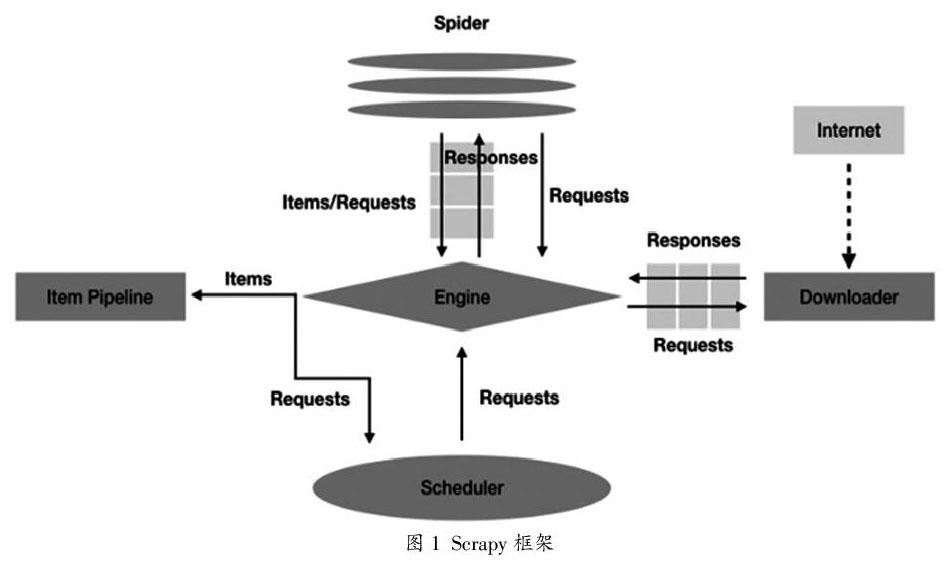
本文使用Scrapy框架具体实现网络爬虫。Scrapy使用了Twisted异步网络框架来处理网络通讯,加快数据下载速度,并包含各种中间件接口,可以灵活地实现各种需求(图1)。
1.2 非结构化文本数据挖掘技术
文本挖掘的主要目的是获得文本的主要内容特征,如文本设计的主题、文本主题的类属、文本内容的浓缩等。本系统采用互信息,信息增益,文本證据权和x2统计法等评价函数进行独立评估,对每一个特征按照给定的权值大小进行排序,选择最佳特征子集作为特征提取的结果[1]。
对于文本特征数高,特征相互关联,冗余严重的特点,本系统采用基于支持向量机的文本分类技术[2]。
而在中文信息处理的过程中,分词是中文信息处理从字符处理水平向语义处理水平迈进的关键,本系统主要采用基于词典的分词方法[5]。
基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG),采用了动态规划查找较大概率路径, 找出基于词频的较大切分组合。对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
1.3 数据库技术
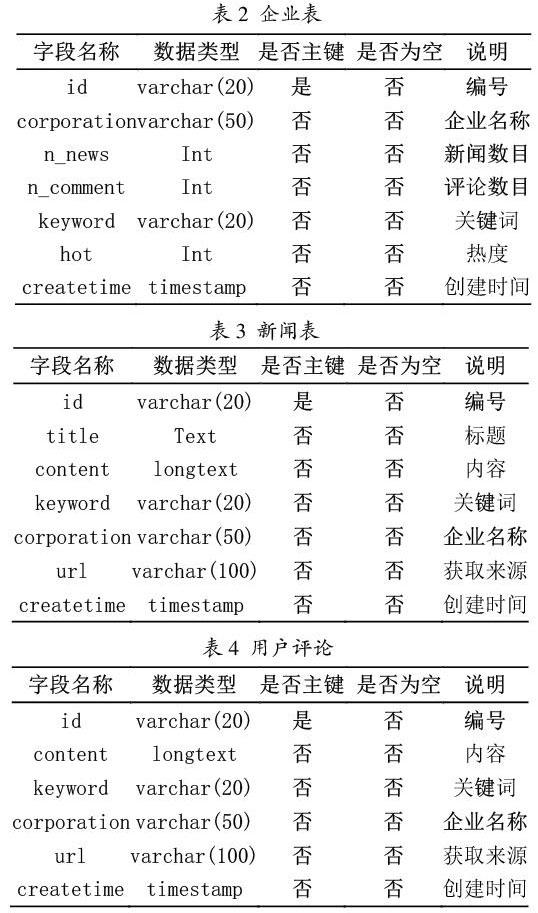
数据库存储技术在网络舆情监测系统中非常重要,在数据爬取和Web建站过程中都要用到数据库。在数据库中,数据一般以表的形式进行数据的存储和管理。
1.4 Web建站技术
本文采用的MTV模式与传统的MVC模式有所不同。MTV模式包括模型(Model)、模板(Template)和视图(View),其中,模型同样负责业务对象与数据库的映射关系,模版负责如何把页面展示,而视图负责业务逻辑,并在适当时候调用模型和模版。在工作过程中,Django框架接收用户的请求和参数后,通过正则表达式匹配URL,转发给对应的视图进行处理,视图再调用模型处理数据,最后调用模版返回界面给浏览器。
2 系统关键模块实现
结巴分词改进:jieba分词在处理中文文本分析是比较常用的工具,实现文本jieba分词的常用流程是加载自定义词典、获取关键词、去除停用词、数据处理。jieba分词自带词典,但是由于具体应用领域的不同,可能不能包括一些专业词汇,会造成分词结果不准确,本系统通过自定义词典解决这一问题。改进专业词汇识别准确率。获取关键词主要借助jieba.cut()和jieba.lcut()两个函数完成,两个函数生成的对象不同,前者生成字符串而后者生成list。Jieba分词还提供了去除停用词功能,去除停用词后可以更精准的进行文本分析。停用词词表可以借鉴网上的中文停用词词表,需要加载本地停用词表,然后针对不同的对象采用特定的方法进行停用词去除。
本系统核心功能模块使用Python实现,词法分析接口可向用户提供分词、词性标注等功能;能够识别出文本串中的基本词汇(分词), 对这些词汇的词性进行识别标注。分别建立名词、动词、形容词的词典, 识别词性后保存到词典中, 记录数量。
3 系统测试
3.1 核心功能测试
本系统分词功能模块的测试数据为摘自新浪新闻的25篇企业新闻,总字数为6683字,使用用户词典,通过计算准确率(Precision),召回率(Recall)和两者的加权调和平均(F-Measure)来衡量模块质量,计算方法详见表5。
分词部分结果如图2。
3.2 测试环境使用结果
我们使用BosonNLP实现了对企业舆情的部分分析。上述新闻文本数据经过情感分析模块处理后计算得到了相关负面系数,见图3。
此外,我们还测试了文本关键词提取的功能,该模块可找出和目标企业相关性较强的关键词以及新闻数据的主题词,并实现对关键词的自动加权。见图4。
4 结束语
本系统基于非结构化数据处理实现的网络舆情分析系统,通过对网络上大量的非结构化信息的处理与分析,将杂乱无章的,冗余的、无意义的内容进行提取、分析从中获取有意义的,有价值的内容。对各个领域的发展提供数据支持,针对各大企业对于网络舆情获取的需要,设计企业网络舆情监测系统,针对网络上不同的企业相关信息进行非结构化数据处理,同时利用情感分析及个性化处理技术,形成可视化的舆情分析,以便企业将舆情分析运用到生产实践中。
参考文献:
[1]李志坚.基于数据挖掘的文本分类算法[J].长春师范大学学报(自然科学版),2017,36(6):47-51,56.
[2]庄世芳,林世平,陈旭晖,等.基于概念集和粗集的中文Web文本挖掘特征提取的研究[J].福建电脑,2006(2):31-32.
[3]賴娟.基于数据挖掘的文本自动分类仿真研究[J].计算机仿真,2011,28(12):195-198.
[4]张脂平,林世平.Web文本挖掘中特征提取算法的分析及改进[J].福州大学学报(自然科学版),2004,32(z1):63-66.
[5]周程远,朱敏,杨云.基于词典的中文分词算法研究[J].计算机与数字工程,2009,37(3):68-71,87.
