个性化协同过滤推荐算法在教师网络研修资源中的应用
2019-06-19周传生赵望儒刘忠武
周传生, 赵望儒, 刘忠武
(1. 沈阳师范大学 计算机与数学基础教学部, 沈阳 110034; 2. 沈阳师范大学 科信软件学院, 沈阳 110034)
0 引 言
信息技术应用能力已成为互联网时代下教师专业素养的重要组成部分。《教育信息化十年发展规划(2010—2020)》[1]提出明确全面优化教师的信息化教学水平,提升教师的学习能力与教师素养,改变了教师培养形式[2]。为满足这些要求,提出了网络研修的新型学习模式。研修平台能够满足教师的学习需求,帮助教师提升知识储备,开拓知识视野,因此现今各类研修资源平台越来越多,教师对研修学习环境的需求也随之增多,因而研修平台不断优化,教师的网上研修形势越来越多样化,教育资源[3]日益增长。现今研修平台功能越来越多,但通过对现在网络研修资源应用平台的研究,发现其中存在一些问题,归纳概括出来总共分为3类:
1) 学习资源推荐个性化问题:现有的推荐模块只是根据教师的基本教学信息进行资源推荐,没有尽可能的满足教师学习的个性化需求,因而造成学习资源不能够被充分利用,再者资源没有通过更加精确化的推荐,难以发挥资源的利用价值,导致教师的无效学习时间增加。
2) 用户相似性问题:个性化推荐加强了用户之间的差别,使有相似兴趣的用户集群分离,对算法计算过程不利,推荐结果容易出现差错。
3) 学习资源重复推荐问题:在教师完成现有学习资源的学习时,系统仍然会给老师推荐学习过的内容,这浪费了推荐的机会以及老师查找其他学习资源的时间。
根据以上的问题,本文对基本的协同过滤推荐算法进行修改,并对算法进行优化,最后进行推荐去重,以解决以上3个方面的问题。
1 推荐算法
1.1 推荐算法比较
目前较多应用的推荐算法包括基于内容的推荐[4]算法,协同过滤[5]推荐算法,基于关联规则的推荐算法,混合推荐算法等。相较于其他推荐算法,协同过滤算法适用范围广,对物品的类型种类没有较多限制,不同于其他算法的经常性推荐特点,能够通过学习社群[6]挖掘用户新的兴趣点,适合个性化资源的查询,更具应用价值。另一方面,该算法更具有时效性以及智能性。对于任何项目,无论是新用户还是老用户,都能够根据用户特点即刻进行匹配,从而进行推荐。因此本文使用协同过滤推荐算法深入挖掘教师的学习特点和学习习惯,为教师推荐更加精准[7]有效的资源。
1.2 协同过滤推荐算法
协同过滤算法基本分为基于用户、基于项目的推荐。基于项目的协同过滤算法计算首先要统计收集学习者与学习资源[8]的数据集,其次通过学习者对资源的浏览记录找到相似的资源,再次把类型相似的资源给学习者。基于用户[9]推荐最简单的例子是首先将有相似电影爱好的用户Z和L记录下来,再次记录双方喜好的不同东西,其次将Z或是L喜欢的东西推荐给L或Z,供其选择。
2 个性化协同过滤算法
2.1 个性化推荐算法
要实现个性化的功能,首先要研究教师学习个性化的表现。通过研究,教师个性化的主要实现方式就是要找到个体间学习习惯的差异,从而根据学习习惯和所处环境推荐符合个体需求的学习资源与应用。郑云翔[10]提出只有个体行为上的差别才便于开发个体的学习潜力与潜能。因此,本文在协同过滤[11]推荐算法的基础上提出个性化推荐,满足教师的个性化学习需要[12],从而提升教师学习能力。
个性化学习资源推荐算法通过收集教师的研修时间与方式,以及研修内容等,得出不同教师之间研修学习的差异性。从而确立不同的个体学习体系,推荐不同且精准的学习资源。
进行算法计算前首先将资源进行分类,如下所示:
1) 按照教学科目进行分类。
2) 按照教学进程进行章节分类。
3) 按照科目内容进行知识点分类,其中词条包含同一科目下面的具体知识分支以及具体知识点,例如“古诗词,散文,代数,质数,出师表”等。
几十年前,我看过几位握了半辈子毛笔的先生写的钢笔字,被字里那样一种古朴苍劲的精神深深吸引,那种精神是与古人相通的。而今,我们这些用钢笔写了大半辈子字的人,握起毛笔写字,想要接通气脉,写出古意,的确十分困难。但也许,会有别的收获。
4) 按照浏览时间及时长分类。分为“0~30分钟,30~60分钟,60分钟以上”3类。
5) 按照下载时间及路径进行分类。分为手机APP下载以及网页下载。
6) 按照评价字数进行分类。分为“0~10个字,10~20个字,20字以上”3类。
通过记录教师对具体分类资源进行学习的学习内容、学习时间、学习环境等,得到教师的学习特征[13],从而针对不同的教师进行不同的个性化推荐。其中,针对教师较少次数学习的学习资源,通过参考教师对其的浏览记录,下载记录等情况进行综合判断后,根据实际情况来决定是否继续对其产生推荐。除此之外,为了获取更好的推荐效果了,在得到推荐列表后进行推荐去重,使资源不被重复错误得推荐。
2.2 数据准备
本文基于辽宁省云教育平台的数据进行分析与试验,首先将数据划分成5类数据集群,并如下记录集群:
数据集群1 教师分类。其中包括“教师ID,教师性别,教师年龄,教学科目”。
数据集群2 资源分类。其中包括“科目ID,科目年级,词条”。
数据集群3 教师浏览资源记录。其中包括“教师ID,资源ID,访问时间,浏览时间及时间长度,浏览次数”。
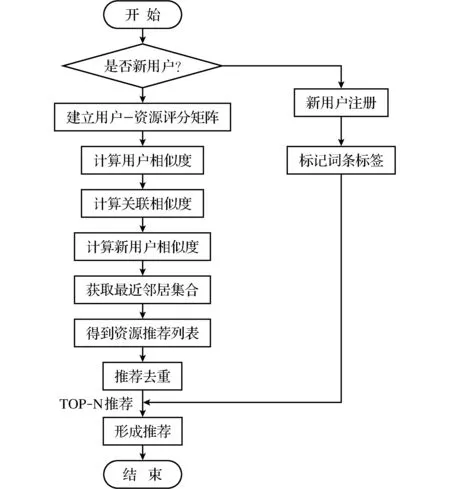
图1 算法框架图Fig.1 Algorithm frame
数据集群4 教师下载资源记录。其中包括“教师ID,资源ID,下载时间,下载路径。”
数据集群5 记录教师评价资源。其中包括“教师ID,科目ID,资源ID,教师评价,评价次数,评价字数”。
2.3 算法框架
通过教师的学习行为制定评分标准,为平台中教师阅读的资源进行评分,创建评分矩阵,利用评分矩阵计算用户相似度。由于本文引入关联相似度,因此再计算一次关联相似度,与之前的传统的用户相似度进行融合计算,得到资源推荐列表,经过推荐去重后,形成推荐。算法框架如图1所示。
2.4 算法实现
步骤1 根据数据集群中教师的个人基本信息、资源下载、资源评价、下载路径、浏览时长等信息,构建“用户-资源”评分矩阵[14],根据教师学习与分类后的学习资源的匹配度设置评分值,其中评分的分值范围为0~5分。评分方式如表1所示。

表1 评分表Table 1 Evaluation form
步骤2 根据评分矩阵使用余弦相似度公式[15]计算用户相似度。
步骤3 计算直接关联相似度。直接关联相似度是根据教师之间重复浏览情况进行计算。用A表示用户a阅读的资源集合,B表示用户b阅读的资源集合,C表示与用户b重复阅读资源数量最多的用户资源集合,A∩B表示用户a和b重复阅读的资源总数,S1表示直接关联相似度,其表示为公式(1):
(1)
步骤4 计算间接关联相似度。间接关联相似度是根据不同学校之间相同年级及科目教师之间的关联度。一些教师之间存在没有浏览过相同资源的情况,但可以通过同一学科,同一年级的相似情况得到间接的关联度。S2表示用户A和B的间接关联相似度,其中T表示相似的教师,U表示相似教师的数量,公式如下:
(2)
步骤5 计算综合关联相似度。其中β1,β2分别表示直接关联度和间接关联度的权重,且β1+β2=1。用S表示关联相似度,则公式如下:
S=β1S1+β2S2
(3)
步骤6 将用户相似度与关联相似度融合,得到新的用户相似度,其中α为用户相似度因子,得到的新的用户相似度用newsin(u,v)表示,其公式如下:
newsin(u,v)=∂sin(u,v)+(1-∂)S
(4)
步骤7 根据步骤6计算的用户相似度,形成邻居集合,根据邻居集合形成资源推荐度,推荐度按照从大到小的组成一个Top-N数量集推荐给用户。

(5)

(6)
3 实验结果与分析
实验采用的数据集为教育云平台的数据集群,从数据集中随机选出多名用户,通过学习行为统计他们的资源评分,首先设定预测评分的阈值,评分阈值由推荐准确率(MAE)的值来进行试验与确定。其值越小,则证明推荐度较为精准,反之则为无效推荐。
(7)
其中T表示预测资源的数量,分子表示资源的预测评分。将资源数量设为固定值,改变评分的值,获取阈值。计算结果如表2所示。

表2 MAE值Table 2 MAE value
通过表2的数值,得到当资源评分为3时MAE[16]的值最小,为了更加客观的体现准确度,将以资源评分为3时通过算法获得推荐的资源的数量,以及根据各类评分得到的资源数量的值带入到以下2个公式进行检验计算。2个指标分别为:召回率[17]和误识别率。

其中召回率越高越准确。

其中,误识别率越低越准确。通过计算,得出召回率的值召回率为58%,误识别率为20%,并与其他平台进行对比,数值上体现了该算法的进化与优势。
4 结 语
个性化协同过滤算法根据教师的研修习惯,为不同教师推送各类精确资源,满足每个教师的资源需求,同时在应用个性化推荐的同时也没有减弱用户之间的联系,既满足了教师的个体需求又增添了交互性。因此,本研究为了提升平台的个性化推荐,做了一些修改,提高了平台的灵活性。
