基于表情符号的情感词典的构建研究
2019-06-14林江豪顾也力周咏梅阳爱民
林江豪,顾也力,周咏梅,阳爱民,陈 锦
(1.广东外语外贸大学,广东 广州 510006;2.广东外语外贸大学 语言工程与计算实验室,广东 广州 510006;3.广东外语外贸大学 信息科学与技术学院,广东 广州 510006)
0 引 言
文本情感分析有利于观点挖掘、产品口碑分析、舆情分析等实际应用。词语作为用户表达观点的最小单元,富含情感信息。因此,构建高品质的情感词典,能有效应用于文本情感分析[1]。由于微博文本具有口语化的特点,并且来自多个领域,导致用户在微博文本中使用到的情感词差异性非常大,加大了微博文本情感分析的难度。因此,构建能应用于微博文本情感分析的情感词典具有重要的价值。情感词是组成情感词典的单元,其存在形式一般为情感词,情感倾向和情感权值。如国外知名的SentiwordNet[2]分别给出情感词的正向、中性和负向三种极性的情感权重。国内的HowNet[3]则用+1来表示词汇的正向情感,-1来表示负向情感。
现有的情感词典构建方法主要有基于情感词典的方法[4-9]、基于种子情感词集方法[10-13]、基于机器学习的方法[11-16]、基于词向量的方法[17-18]等。文献[4]提出了基于情感词典的情感特征提取及其在文本情感分析中的应用方法。Dragut等[5]以多情感词典中词汇极性不同的现象,自动构建了领域情感词典。在短文本情感特征提取中,Vo等提出了利用神经网络和情感词典结合的方法[6]。基于HowNet中情感词汇的情感信息,文献[7]提出了语义相似度和语义相关场两种计算方法,通过计算情感候选词与HowNet中情感词汇的语义相似度,得到词汇的情感倾向。同样利用HowNet,柳位平等利用义原计算的优势,根据词与正、负向种子词的语义相似度差,计算获得情感倾向[8]。文献[9]结合了HowNet和SentiWordNet,对词语进行义元分解并计算其情感值。以情感种子词集为基础,利用SO-PMI算法,在特定语料环境中,可计算获得词汇的情感倾向和权重[10-13]。基于机器学习算法,在特定语料中对词汇信息进行统计和计算,也可获得词汇的情感信息。如文献[14]提出利用页面、页面社区和页面社区的所属类别,将单词语义特征映射到这些类别上,获得词汇的类别属性。文献[15]在新闻和评论中进行对比分析,再将情感向通用领域扩展,得到通用的情感特征。文献[16]通过利用评论中的普通特征训练情感分类器,再基于spectral聚类将词汇的情感映射到扩展特征。现有的研究为情感词典构建提供了新思路,特别是在微博语料中进行情感词典构建,微博中的表情符号带有明显的情感特征,如用户喜欢([赞])表示赞同,用([泪])表示伤心等情感,可作为有效的基础情感信息,进而拓展计算词语的情感权值。
因此,文中利用微博表情符号的情感表达作用,选择情感表情符号作为基准情感信息,利用TF-IDF和SO-PMI的计算优势,实现情感词的识别与情感权值的计算,并通过微博文本情感分析任务,验证该方法的有效性。
1 基于表情符号的情感词典构建方法
1.1 SO-PMI算法
点间互信息算法(pointwise mutual information,PMI)可用于计算语料库中两个词语之间的语义相似度。基本思想是统计词语在文本中的共现率,共现率越高其语义关联度越高,反之则语义关联度越低。给定语料库中,通过PMI算法,词语w1与w2间的PMI值可用两个词在语料库中共现的概率P(w1&w2)和两个词在语料库中单独出现的概率P(w1)与P(w2)进行表示,具体计算如式1所示。
词的语料库中出现的概率可以使用词的文档频次来计算。
(1)
情感倾向点互信息算法(semantic orientation pointwise mutual information,SO-PMI)是由PMI算法扩展而来,通过引入计算词语的情感信息,达到词语情感倾向计算的目的。给出正面种子词集WP和负面种子词集WN,则候选情感词wi的情感倾向值(SO)可采用式2计算。
(2)
SO值大于0的为正面词汇,小于0的为负面词汇。通常将情感倾向值进行线性变化,使情感词的情感权值为介于[-1,1]之间的实数,如式3:
(3)
为了过滤掉情感表达较弱的词汇,在式3中加入约束条件。设定情感阈值θ(0<θ<1),认为情感强度在θ以外的词汇为非情感词汇,具体计算如式4:
SOnew(wi)=
(4)
情感阈值θ的取值直接关系到情感词典的规模和范围。θ太小容易产生太多的噪音情感词,影响情感词典的质量;取值过大容易过滤到太多词汇,约束情感词典的规模。
文中通过大量实验,最终设定阈值θ=0.35,可取得较好的情感词典构建效果。
1.2 情感词典构建过程
情感词典构建过程中,首先选定正、负种子表情符号集合Wp和Wn。接着对微博语料Weibo_texts进行分词和TF-IDF值的计算,计算结果可用W={(w1,tf-idf1),(w2,tf-idf2),…,(wm,tf-idfm)}表示;采用阈值过滤方法,选择W中TF-IDF值高于阈值的词汇作为候选词集WL={(w1,tf-idf1),(w2,tf-idf2),…,(wn,tf-idfn)}(n≤m),WL是表示在语料中具有重要区分度的词集,但词集中词汇的情感权重未确定。该算法主要原理是通过计算词集WL中每一个词wi与Wp、Wn中各个表情符号在语料中的情感倾向点互信息,再与词wi的TF-IDF值tf-idfi相乘,得到词wi的情感特征权重;最终获得情感词典SentiNet={(w1,wt1),…,(wm,wtm)},实现了对词汇情感表达的抽象表示,方便计算机实现情感计算。具体过程如图1所示。
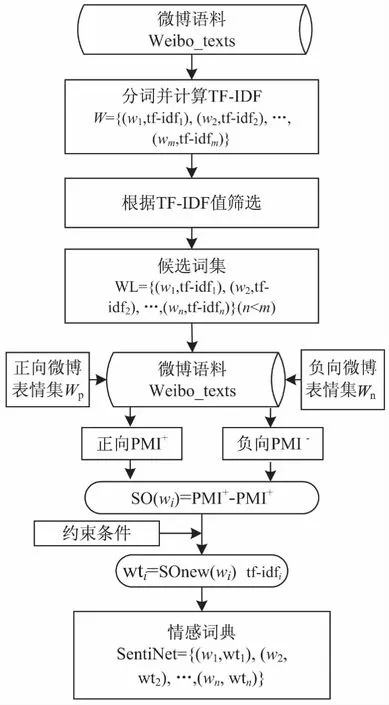
图1 基于表情符号的情感词典构建
根据图1,利用TF-IDF值的重要性度量和情感表情符号的情感强度,实现了情感词的权值计算。算法描述如下:
算法:基于种子表情符的情感词典自动构建算法。
输入:微博语料集Weibo_texts;正向表情符号集Wp;负向表情符号集Wn;
输出:SentiNet。
步骤1:初始化Senti2vec=Ø;
步骤2:将Weibo_texts进行分词、去标点符号等预处理,计算词汇的TF-IDF值,得到词集W={(w1,tf-idf1),(w2,tf-idf2),…,(wm,tf-idfm)};
步骤3:对每一个(wi,tf-idfi)((wi,tf-idfi)∈W),如果tf-idfi≥a(a∈[0,1]),则(wi,tf-idfi)→WL;得到WL={(w1,tf-idf1),(w2,tf-idf2),…,(wn,tf-idfn)}(n≤m);
步骤4:对每一个(wi,tf-idfi)((wi,tf-idfi)∈WL),在Weibo_texts中计算获得SO(wi);如果SO(wi)满足式4中的情感词范围,则计算SOnew(wi),进而采用式5计算获得wti;
wti←SOnew(wi)×tf-idfi
(5)
步骤5:输出SentiNet={(w1,wt1),…,(wm,wtm)}。
模型的输出SentiNet,在情感权值计算过程中,一方面考虑了TF-IDF值的重要性度量,另一方面以种子表情符号的情感信息作为基础,实现更好的融合。种子表情符号不受语料的领域约束,使得提出的方法能在情感权值计算方面更具有适应性。
2 实验结果与分析
2.1 语料采集与预处理
文中使用的微博语料来自北京理工大学搜索挖掘实验室张华平博士的微博开放语料(Weibo_texts),包含了500万条微博语料,用于情感词典的构建。同时,从新浪微博上采集的4 130个用户的298 295条个人微博。过滤不含有表情符号的微博和不含情感词的微博,最后人工筛选4 000条并对语料进行情感极性标注,作为微博文本情感分析实验语料。语料为平衡语料,其中正、负向情感的微博语料各2 000条,用于微博情感分析实验,验证构建的情感词典在情感分析应用中的有效性。
2.2 种子表情符号的选择
种子表情符号的有效选择是情感词典构建的基础。文中主要采用以下两种选择规则:一是微博语料中的高频表情符号,有利于提高表情符号的使用覆盖率;二是情感极性比较明显的表情符号,有利于提升情感词极性计算结果的准确性。
通过调用新浪微博API获取到1 999个微博表情,对采集到的微博语料中的表情符号进行频率统计,选择出现频率较高并且情感明显的表情符号作为种子表情符号集,共44个表情符号,其中正、负向种子表情符号各22个(见表1)。

表1 种子表情符号
2.3 情感词典构建结果及其验证
利用文中提出的算法构建获得情感词汇13 814个,其中正向词汇6 885个,负向词汇6 929个。将构建的情感词典应用于微博语料情感分析实验。实验数据为人工标注的平衡微博语料,共4 000条,正负向微博文本各2 000条。随机取正向语料100条和负向语料1 000条构建平衡训练语料库。其余的语料用于微博文本情感分类器的测试。
基于支持向量机(SVM)这种监督式学习的方法,构建了微博文本情感分类器。分类过程中,首先对微博文本进行分词等文本预处理操作;接着基于传统的向量空间模型(vector space model,VSM)对文本进行向量表示,对出现在SentiNet中的词汇用情感权重表示,其他的用0表示,向量的维度是SentiNet的长度。
同时直接利用SentiNet中词汇的情感权值对微博语料进行情感分析,主要采用情感加权(SO-SUM)和情感乘积(SO-MUL)的方法,也就是将每一条微博进行分词等预处理后,直接扫描出现在SentiNet中的情感词,将每个情感词的权值分别进行求和与乘积运算,最终每条微博的情感值大于0,则分类为正向,否则为负向。
为了进一步验证情感词典,与国内知名的HowNet情感词典进行对比。评价指标采用微平均F1值。采用折叠交叉实验的方式,迭代10次,最终取平均值作为实验结果,如表2所示。
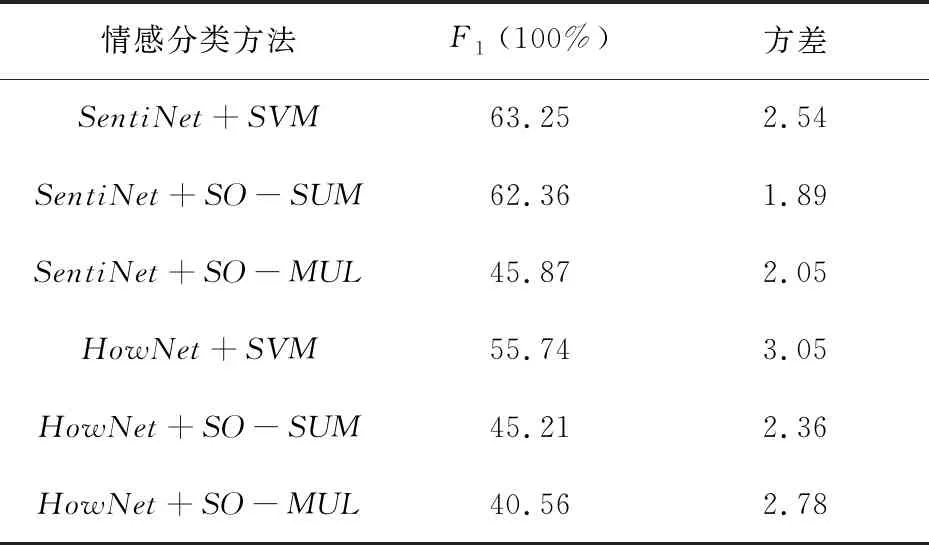
表2 微博文本情感分类结果
观察语料和实验结果发现,由于微博口语化、转折词、程度副词等对分类效果也有一定的影响,为了验证所构建情感词典的有效性,对这些影响暂不考虑。因此,仅获取了微博文本中出现的情感词作为情感特征,导致总体的F1值偏低。采用SentiNet+SVM的方法可取得较好的分类效果(F1=63.25%)。对比分析了SentiNet和HowNet两种情感词典在分类中的效果,如图2所示。
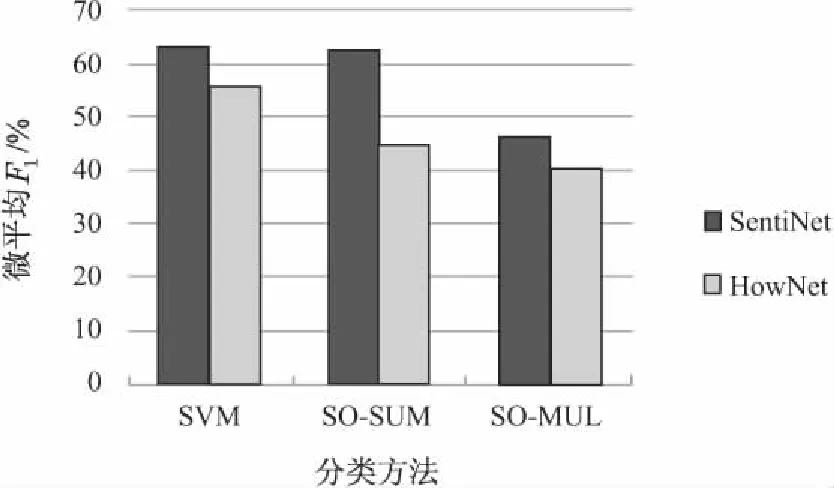
图2 微博情感分类结果对比
从图2中可以看出,同样的分类方法SentiNet可取得比HowNet更好的分类性能。主要原因是,SentiNet是从语料中计算获得,情感词汇的覆盖面更广泛一些,能提取到更多有效的情感特征。SO-SUM方法与分类器SVM方法效果相当,说明文中的情感权重计算结果是有效的。同时,SO-SUM方法具有不需要训练,可直接应用于大规模的语料分类的优势。实验结果表明,文中方法能对词汇中的情感词汇进行有效的表示。
3 结束语
基于词汇的TF-IDF值,选择语料中具有重要度区分的词汇作为候选情感词集。提出基于种子表情符号和SO-PMI算法的权重计算方法实现情感词汇的情感权值计算,最终构建情感词典SentiNet。该方法融合了情感词的重要度衡量优势和种子表情符号集的情感表达优势,在大量微博语料中实现了情感词的权值计算。基于微博文本情感分析的实验证明了该方法的可行性,构建的SentiNet有效。下一步将研究表情符号和情感词汇相结合的种子词集,分析种子情感集合对情感词典构建的影响,进一步提升SentiNet的规模和质量。
