一种TAN分类器改进方法
2019-06-11张坤陈曦宋云傅明
张坤 陈曦 宋云 傅明


摘要:为了改善树增强朴素贝叶斯(TAN)的分类精度,对TAN结构进行了扩展,提出了一种利用可分解的评分函数构建树形贝叶斯网络分类模型的学习方法。在构建TAN网络时允许属性没有父结点。采用低阶CI测试初步剔除无效属性,再结合改进的BIC评分函数利用贪婪搜索获得每个属性结点的父结点,从而建立分类模型。对比朴素贝叶斯(NB)和TAN,提出的分类算法在分类准确率和AUC面积两个指标上表现更好,说明本文模型拥有比TAN更好的分类效果。
关键词:树增强朴素贝叶斯;分类网络;评分函数:
中图分类号:TP311.1
文献识别码:A
分类是一种常见的监督学习方法,其目标是在训练集上建立分类模型,从而为测试集实例指定合适的类别。贝叶斯网络[1]表达了一种因果关系,它用图模型理论和统计学知识来表示属性之间的概率。在贝叶斯网络中,分类是根据类别的先验分布计算后验概率,从而选择最可能的类。朴素贝叶斯(NB)分类器[2]是一种简单有效的贝叶斯网络,但由于其属性变量之间存在条件独立性假设,分类精度不佳。Friedman等人[3]提出树增强的朴素贝叶斯(TAN),它允许属性结点最多只能依赖于一个非类结点,综合性能良好,是学习效率与分类精度之间的一种折衷。
目前关于TAN分类器的研究通常从构建合适的贝叶斯网络着手:文献[4]提出一種不确定条件互信息度量方法来学习树形贝叶斯分类网络结构;文献[5]根据条件对数似然性提出一种平均树增强朴素贝叶斯;文献[6]对TAN分类器结构空间和TAN分类器结构等价类空间进行了研究,提出一个不考虑边重定向的TAN分类器学习算法。这类低阶或受限(如k-BAN[10])的贝叶斯分类模型既避免了由高维计算导致的不稳定性[7],同时也增强了网络结构中属性之间的因果关系。因此,关于TAN分类器的应用研究也较为常见,如高血压诊断模型[8]、物种丰富度的估计模型[9]等等。然而,TAN模型虽然简洁高效,但在构建网络结构时并没有进行相关属性选择或引入新属性,这对TAN分类模型的分类精度有所影响本文在保证TAN精简结构的基础上,提出扩展的TAN分类器(Extended Tree AugmentedNaive Bayes,简称ETAN),额外允许TAN模型中部分属性没有父结点。考虑到属性对类贡献程度差异,采用互信息测试进行属性选择,用于确定后续每个属性结点的候选连接。随后给出了利用可分解的评分函数来构建TAN模型的详细过程,提出一种利用改进的BIC评分函数来构建树形贝叶斯网络分类模型的学习方法( Extended Tree AugmentedNaive Bayes with the scoring function,简称SETAN).通过与其它同类分类器进行对比实验,提出的SE-TAN分类模型取得了更好的分类精度。
1 基于BIC评分函数的SETAN分类器
1.1 TAN模型
1.1.1 TAN模型
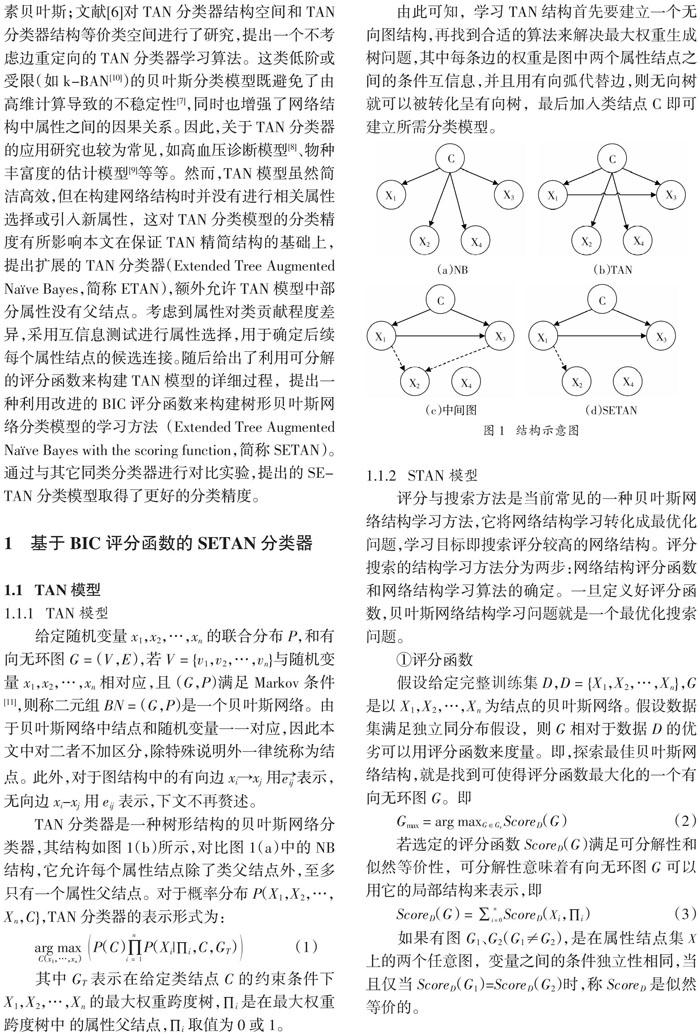
由此可知,学习TAN结构首先要建立一个无向图结构,再找到合适的算法来解决最大权重生成树问题,其中每条边的权重是图中两个属性结点之间的条件互信息,并且用有向弧代替边,则无向树就可以被转化呈有向树,最后加入类结点C即可建立所需分类模型。
1.1.2 STAN模型
评分与搜索方法是当前常见的一种贝叶斯网络结构学习方法,它将网络结构学习转化成最优化问题,学习目标即搜索评分较高的网络结构。评分搜索的结构学习方法分为两步:网络结构评分函数和网络结构学习算法的确定。一旦定义好评分函数,贝叶斯网络结构学习问题就是一个最优化搜索问题。
①评分函数
假设给定完整训练集D,D= {X1,X2,…,Xn},G是以X1,X2,…,Xn为结点的贝叶斯网络。假设数据集满足独立同分布假设,则G相对于数据D的优劣可以用评分函数来度量。即,探索最佳贝叶斯网络结构,就是找到可使得评分函数最大化的一个有向无环图G。即
常见的MDL、BIC、BDe评分函数都具备可分解性和似然等价性。文献[12]提出贝叶斯信息标准( Bayesian information criterion),简称BIC评分。BIC评分函数是在样本满足独立同分布假设的前提下,用对数似然度度量结构与数据的拟合程度。具体形式为:
②模型描述
下面给出TAN分类模型结合评分搜索方法的一般性表达式(Tree Augmented Naive Bayes with ascoring function,简称STAN)。
TAN分类器基于NB分类器对属性之间的依赖关系进行了扩展,将构造最大似然树的问题简化为构造最大权重跨度树。当给定评分函数时,在TAN无向图中,有
1.2 SETAN模型
1.2.1 理论分析
由TAN的定义和公式(7)可知,TAN结构限制每个属性结点对其父结点有如下两种连接选择:1,只有类父结点C;2,具有类父结点C和一个属性父结点。TAN的学习是在完全图中搜索弧空间,通过这种限制,减小了搜索空间;同时父结点的数量受限使得条件概率计算相应地减少。
然而,TAN结构并不能充分地表示属性结点之间的依赖关系,而且在构建网络结构时未能去除冗余的属性结点。准确地说,TAN是在维持原始属性变量集合的基础上建立低阶树形分类模型,而不是通过引入新的属性变量来放松条件独立性假设。Greiner等人[13]通过实验证明,与数据集实际分布近似或比数据集实际分布简单的网络结构都具有一定的局限性。对于前者,文献[7]已给出证明,限制父结点的数量可以有效避免具有指数复杂度的高维计算。后者的原因是,即使NB网络或TAN网络相对简单,但也可能由于存在冗余的结点和弧边而使得网络结构复杂化。因此,在建立TAN结构前进行有效的属性选择非常有必要。
另外,TAN结构仅仅强化了属性之间的因果关系,而没有考虑不同属性对类的贡献,这同样也降低了TAN模型的分类准确性。文献[14][15]的一系列对比实验证实了这一结论。
基于上述分析,本文进一步扩展了TAN网络结构,该网络结构相对于TAN能够更充分地表示在类约束下属性之间的依赖关系,同时尝试剔除对分类模型没有贡献的属性结点。
1.2.2 SETAN模型
①CI测试
由香农的信息论可知,两个随机变量Xi和xj之间的互信息为:
②改进TAN模型
为了避免贝叶斯网络分类器的高维计算,同时为了在构建SETAN结构时去除冗余结点并减少候选父结点集的搜索空间,增强分类模型的可靠性与健壮性,在TAN结构基础上,允许属性结点没有父结点。即具有如下额外两种选择:3,只有一个属性父结点;4,没有父结点。其中符合第4种情况的结点被视为对分类模型没有贡献的冗余结点。
考虑到SETAN结构中各个属性结点Xi和类结点C的相关性不同,先对类结点和属性结点进行互信息测试,如图1(c)(d)所示:
基于上述改动,每个属性结点不必将类结点纳入候选父结点集,则公式(5)中的对称性无法成立,从而无法在公式(7)中利用最小生成树算法求得SETAN结构。此时对于经过0阶CI测试后的无环图,采用BIC评分函数贪婪查找下一个局部无环图G,从而得到图l(d)所示的最终有向无环图。则有
1.2.3 算法描述
基于BIC评分函数的SETAN分类算法主要有如下改进:
1,提出SETAN网络结构,在TAN结构基础上中放松了每个属性结点的父结点选择条件,允许部分属性没有类父结点,在保证同等计算复杂度下提高了分类模型的可靠性。
2,采用低阶CI测试去除无效结点,结合上述属性依赖关系,获得各个属性的候选父结点集合,获得冗余结点,减小候选父结点集的搜索空间。
3,利用改进的BIC评分函数对局部最优无环图进行贪婪查找,从而获得最终的SETAN网络结构。进一步去除无效结点,提高算法的分类精度。下面给出构建SETAN结构图的一般性过程。
1.2.4 时间复杂度分析
SETAN分类器学习算法主要分为两个部分:
第一部分是类结点与各个属性结点之间的0阶CI测试。主要的计算耗时是互信息测试/(C;Xi),复杂度是O(Nn),N是训练集实例数量,n是属性结点数量。
第二部分是构建SETAN网络结构,主要是需要比较每个结点和其候选父结点集的连接得分,以此确定其父结点。时间复杂度是O(Nk1 +Nk1·k2),因为kl+k2≤n,ε一般取值为0.01-0.05,大多数属性结点可符合互信息测试,即k2《k1。因此,SETAN分类器最终可在O( Nn2)内完成,和TAN分类模型的时间复杂度相同。
2 实验结果与分析
2.1 改进的BIC评分函数评估
本节实验的主要目的是确定公式(9)中改进后BIC评分函数的合适的惩罚系数ξ。分别采用http://www.norsys.com提供的Asia网和Alarm网进行仿真实验。Asia网包含8个变量和8条边,Alarm网包含33个结点,46条边,样本数量均为5000。利用常见的K2算法和改进后的BIC评分函数学习贝叶斯網络结构,惩罚系数ξ分别取0.01,0.001,0.0001。实验结果如表所示,A为增加边,D为确实边,R为正确边。
从表1的实验结果可以看出,ξ= 0.01时,Asia网络和Alarm网络结构缺式边数量相对比较多,没有增加边,说明惩罚系数偏大,导致数据和网络结构欠拟合;ξ= 0.0001时,网络结构增加边相对较多,导致数据和网络结构过拟合;而当ξ= 0.001时,各项数据比较合理,说明数据和网络结构拟合较好。
2.2 SETAN分类性能评估
实验数据选取UCI资源库中6个具有代表性的离散数据集,每个数据集的数据信息如表2所示。实验环境在Windows7操作系统上进行,集成开发环境Intellij Idea,Weka 3.8,硬件配置为Intel?Core(TM)i5-2410MCPU@2.30GHz,内存4GB。实现了NB分类器、TAN分类器和SETAN分类器。
实验的主要目的是验证在同等时间复杂度下SETAN分类算法的有效性,本文采用一组常见的分类指标进行性能评估:准确率(Accuracy)、召回率( Recall)、精确率(Precision)、F1值(F1 -measure)、AUC面积(AUC)。结合表3给出如下相关定义:
所用的CI测试阈值ε一般取值为0.01-0.05,BIC评分函数的惩罚系数ξ取0.001。在实验中采用十折交叉有效性验证的方法,对于数据集中的缺失值,将其作为一个单独的值来处理,实验结果取平均值。表4给出了本文提出的SETAN算法与NB、TAN算法的详细实验结果。
从表4可以看出,5个评价指标所得的结果大致相同,准确率越高,其它4个指标相应越大。从各个评价指标上看,首先,SETAN在多分类或二分类数据集上相对有更好的分类效果;对于类别分布不均衡的数据集(如Balance、Car、Nursery),SETAN的各项分类指标均明显优于NB和TAN分类器;其次,SETAN分类模型也适用于不同数据规模的数据集,但在SPECT、Connect数据集上的分类精度较差,说明属性数量对分类模型的影响比较明显。其原因是,对于具有22个属性的SPECT数据集,80个样本相对于网络复杂度而言数据集规模太小,分类模型欠拟合导致各项分类指标不佳;而对于Connect数据集,样本数量和属性数量均较大,相应的计算复杂度较高,导致评分搜索得到的模型指标不太理想。
总之,在数据规模、类别分布、属性数量这三个因素上,数据集的规模和类别分布对3种分类器的影响都比较小,而属性数量会明显影响分类效果。属性越多,分类准确率相应下降,但SETAN相比NB和TAN模型来说仍然占有优势。而且注意到,对于类别分布不均衡的数据集(如Balance,Car,Nursery),SETAN的分类准确率有明显改善。
为了更直观地看出提出的SETAN算法与TAN、NB算法的分类效果差异,图2给出了三种算法的AUC面积的polar图。由于三种算法在Mushroom数据集上的AUC面积非常接近,因此图2没有给出。在图2中可以明显看出SETAN在各个polar图中面积都是最大的;此外,SPECT属于二分类的小数据集,所以在图3中给出了三种算法的ROC曲线图。可以看出,在处理属性数较多的小数据集SPECT时,SETAN算法的分类结果也具有一定的参考价值。
3 结论
提出一种基于评分搜索的树增强朴素贝叶斯分类器改进方法。考虑到属性对类贡献程度有所不同,该分类算法在此约束条件下利用低阶CI测试获得候选无效属性,随后通过改进的BIC评分函数结合K2算法的方式确定网络结构中弧边的方向,并去除无效属性,进而构建分类模型。本方法额外允许属性没有父结点或只有一个属性父结点,从而构建了一种更好的树形贝叶斯网络结构,去除了冗余属性,增强了分类模型的可靠性。该算法和TAN分类模型的时间复杂度相同。实验结果表明,与NB、TAN分类器相比,SETAN的分类准确率更高。下一步尝试在大规模数据集上进行该分类算法的分布式并行化研究。
参考文献
[1]
PEARL J. Probabilistic reasoning in intelligent systems: networksof plausible inference [J]. Computer Science ArtificialIntelligence, 1991, 70(2):1022-1027.
[2] MURALIDHARAN V,SUGUMARAN V.A comparative study ofNalve Bayes classifier and Bayes net classifier for fault diagnosisof monoblock centrifugal pump using wavelet analysis [J].Applied Soft Computing, 2012 , 12( 8 ):2023-2029.
[3]
FRIEDMAN N, GEICER D,GOLDSZMIDT M. Bayesian network classifiers [J]. Machine Learning , 1997 , 29( 2-3 ) :131-163.
[4] CAN H,ZHANC Y , SONG Q. Bayesian belief network for positiveunlabeled learning with uncertainty [J]. Pattem Recognition Letters , 2017 , 90 : 28-35.
[5]
JIANC L, CAI Z, WANC D , et al. Improving tree augmented NaiveBayes for class probability estimation [J]. Knowledge -BasedSystems, 2012.26:239-245.
[6]王中鋒,王志海. TAN 分类器结构等价类空间及其在分类器学习算法中的应用 [J]. 北京邮电大学学报 ,2012,35(1):72- 76.
[7] WONG M L.LEUNG K S. An e~ficient data mining method forlearning bayesian networks using an evolutionary algorithm-basedhyhrid approach [J]. IEEE Transactions on EvolutionaryComputation, 2004 , 8(4) :378-404.
[8] OUYANG W W,LIN X Z,REN Y.et al. TCM syndromesdiagnostic model of hypertension: Study based on tree augmentedNaive Bayes.[J]. IEEE , 2011:834-837.
[9] MALDONADO A D,ROPERO R F,ACUILERA P A,et al.Continuous bayesian networks for the estimation of speciesrichness
[J]. Progress in Artificial Intelligence, 2015 , 4
( 3 -4):49-57.
[10]冯月进,张凤斌,最大相关最小冗余限定性贝叶斯网络分类器学习算法[J].报:自然科学版 , 2014,37(6):71-77.
[11] ROBINSON R W. Counting unlaheled acyclic digraphs [M]//Combinatorial Mathematics V. Springer Berlin Heidelberg, 1977:28-43.
[12] SCHWARZ G. Estimating the dimension of a model[J]. Annals ofStatistics, 1978 , 6( 2 ):15-18.
[13]
GREINER R , ZHOU W.Structural extension to logistic regression:discriminative parameter learning of belief net classifiers [J].Machine Learning, 2005 , 59( 3) :297-322.
[14] MADDEN M G. On the classification performance of TAN andgeneral Bayesian networks [J]. Knowledge -Based Systems,2009 , 22( 7 ) :489-495.
[15] DRUCAN M M,WIERING M A. Feature selection for Bayesiannetwork classifiers using the MDL -FS score
[J]. IntemationalJournal of Approximate Reasoning, 2010 , 51(6) :695-717.
