一种非独立同分布下K-means算法的初始中心优化方法
2019-06-06潘品臣吕奕锟
潘品臣,姜 合,吕奕锟
(齐鲁工业大学(山东省科学院) 计算机科学与技术学院 ,济南 250353)
1 引 言
聚类算法是数据挖掘中重要的研究内容之一,它是一个将物理或抽象对象的集合分组为由类似的对象组成的多个类的分析过程.基本的聚类方法包括:基于划分的方法、基于层次的方法、基于密度的方法、基于网络的方法以及基于模型的方法等等[1].K-means算法最早由MacQueen提出的[2],是典型的基于划分的聚类算法之一,它具有简单、快速的优点.但是,传统K-means算法也存在着一些缺陷,其中最主要的便是对于初始中心点的选取比较敏感,不当的选择容易陷入局部最优且聚类结果准确率低.针对这一缺陷,很多研究者提出了改进的方法,例如:Likas等人提出了一种全局K-means算法[3],它是一种增量式的聚类算法,通过一个确定的全局搜索过程,每次动态地添加一个聚类中心,从合适的初始位置执行K-means算法.袁方等人为了消除K-means算法对初始聚类中心点选择上的敏感性,提出了一种优化聚类中心的方法[4],此方法计算每个数据对象所在区域的密度,选择相互距离最远的k个处于高密度区域的点作为初始聚类中心.翟东海等人针对聚类时容易出现局部最优、聚类结果不稳定、总迭代次数较多等问题,提出了最大距离法[5]来选取初始簇中心.邢长征等人针对现有的基于密度优化初始聚类中心的方法在聚类中心的搜索范围大、消耗时间久以及聚类结果对孤立点敏感等问题,提出了一种基于平均密度优化初始聚类中心的adk-means算法[6].邹臣嵩等人提出了一种基于最大距离积与最小距离之和的协同K聚类算法[7],该方法解决了传统K-means算法聚类结果随机性大、稳定性差,以及最大距离乘积法迭代次数多、运算时间长等问题.唐东凯等人针对K-means算法对初始聚类中心和离群点敏感的缺点,提出了一种优化初始聚类中心的改进K-means算法[8],该方法首先计算数据集中每个对象的离群因子并进行升序排序,使得中心点的位置靠前,然后引入取样因子,从而得到候选初始中心点集,最后利用Max_min方法的思想在候选初始中心点集上选取k个聚类初始中心.
目前对于初始中心点的改进都是建立在独立同分布基础上进行的,然而数据中的属性之间或多或少会存在相互作用和关系,是非独立同分布的.非独立同分布思想最早是由Cao在2011年提出的[9].随后又有不少研究者将此思想应用于不同方面,例如:Wang等人在无监督学习中提出了耦合名义上的相似性度量来代替传统的欧式距离度量[10],但这仅限于类别型数据集.Liu等人分别对不平衡数据下的混合耦合KNN算法、不平衡分类数据的模糊耦合KNN算法以及用于多标签分类的耦合KNN算法进行了研究[11-13].Li等人提出了一种新的通用耦合矩阵分解模型(CMF)[14],通过引入用户与物品之间的非独立同分布耦合关系在推荐系统应用方面进行了研究.Jian等人为无监督学习定义了一个耦合度量相似度(CMS)[15],它灵活地捕获了从值到属性到对象的异构耦合关系,能够灵活地适应独立同分布和非独立同分布下的数据,但其主要研究对象还是类别型数据集.
在上述文献中有的解决了K-means算法随机选取初始中心点的问题,但却忽略了噪声点对结果的影响;有的避免了噪声点的影响,但忽略了属性之间存在的交互关系.本文在非独立同分布下提出了一种基于双领域思想和Min_max方法相结合的优化K-means初始中心选择的方法,(即K-means algorithm based on Dual Domain idea and Min_max method within Non- Independent and Identically Distribution context,简称NonIID-DDMMK-means算法).数值数据可以基本表示为一个信息表的格式[16],其中每一列表示为指定的“属性”,每一行表示为指定的“对象”.鉴于此,本文首先考虑属性之间的相互作用关系,利用Pearson相关系数公式计算每一列本身和其他列之间的相关系数[17],即不同属性之间的交互关系.然后将属性之间的交互关系映射于原始数据每一行的对象之间,形成一个能够体现属性交互关系的新的数据集.最后利用双领域思想对Min_max方法进行优化,即在高密度领域选取第一个初始中心点,在非噪声点领域利用Min_max方法的思想选取其它初始中心点来解决初始中心点敏感的缺陷,并且能够减少迭代次数,提高聚类效果.
2 K-means算法
K-means算法是聚类分析中最常用的基于划分的算法之一,已经在许多行业领域得到很好的应用,该算法的执行流程是:
1)随机地在将要聚类的数据集中选择k个数据对象作为初始聚类中心,这里的k代表类簇数目.
2)遍历数据集中剩余的每个对象,根据相似度来决定每一个数据对象应该被分配到哪一个簇中,将每个对象分配到与其相似度最大的簇中.这里的相似性度量通常使用欧式距离来表示,两个对象之间的距离越小说明它们之间的相似度越大.
3)重新计算每一个簇的中心点,将每一个簇的均值作为新的中心点.
4)重复执行步骤2、步骤3,直到准则函数收敛,准则函数见公式(1).
(1)
这里的准则函数通常使用聚类误差平方和,其中,k为簇的个数,m为簇中对象的总个数,Oij是第i簇的第j个数据对象,Ci是第i簇的均值中心.
3 NonIID-DDMMK-means算法
NonIID-DDMMK-means算法对于初始聚类中心点的选取主要分为三个过程:
1)利用修改后的Pearson相关系数公式计算每一列属性之间的相关系数,即属性之间的交互关系.并将属性之间的交互关系映射于原始数据集的对象之间从而形成一个能够体现属性间交互关系的新的数据集;
2)利用密度参数的思想,计算出数据集中的高密度领域和非噪声点领域.其中,高密度领域用来对Min_max方法在第一个点的选择上进行确认,非噪声点领域用来对Min_max方法在其他点的选择上进行约束;
3)根据Min_max方法在双领域中选取初始聚类中心点.下面分别对这三个过程进行介绍.
3.1 形成属性间具有交互关系的数据集
之前的大部分研究都是在独立同分布基础上进行的.然而在现实的数据中,属性之间或多或少都会存在一些相互作用,传统的K-means算法忽略了这些交互关系.下面对属性间的交互关系进行形式化表示,并举例说明.
前面提到数值数据可以基本表示为一个信息表的格式,本文选取Iris数据集中的一个片段为例,6个对象具有4个属性(即萼片长度a1,萼片宽度a2,花瓣长度a3,花瓣宽度a4),分为三类,具体信息如表1所示.

表1 鸢尾花数据片段TTable 1 Data fragment T of Iris
第1步.构建新的Pearson相关系数公式
研究变量之间的交互作用的一种传统方法是通过Pearson相关系数测试变量之间的线性关系[17,18].因此,本文利用Pearson相关系数公式来计算属性之间的交互关系,计算公式见公式(2).
(2)
其中,am和an为不同的属性列,U为数据集中的对象个数,fm(u)为属性am对应的所有属性值,μm为属性am下所有属性值的均值.
但是,这里主要考虑属性之间的重要的交互关系而不是涉及所有的这些关系.因此基于p值越小相关性越显著的原则,对原本公式进行了修正,这里选用统计学中常用的0.05作为p值得划分点,修正后的公式见公式(3).
(3)
第2步.计算属性间的交互关系
由第1步得到属性间修正后的公式(3),进而计算出不同属性之间的相关系数为:
α(a1|a2,a3,a4)=(0.000 0.000 0.814)
α(a2|a1,a3,a4)=(0.000 0.000 0.000)
α(a3|a1,a2,a4)=(0.000 0.000 0.976)
α(a4|a1,a2,a3)=(0.814 0.000 0.976)
可以看出就数据片段T而言,属性a2和其他属性之间的相关系数为0,即无显著相关,属性a1和属性a3之间也无显著相关.
第3步.将交互关系映射到原始数据集
由第2步得到不同属性之间的相关系数后,利用公式将属性之间的相关系数映射到对象之间,即映射到原始数据集上,具体公式见公式(4).
(4)
其中,fm(u)为属性am对应的所有属性值,ω为数据集中特征属性的个数,α(m|ni)表示属性am和属性ani之间的相关系数,即New_Cor(am,ani).

表2 新鸢尾花数据片段TcTable 2 New data fragment Tc of Iris
将第2步计算出来的属性间的相关系数,利用公式(4)映射到原始数据集的对象之间,形成一个能够体现属性交互关系的新数据集Tc,具体结果如表2所示.
3.2 生成高密度领域和非噪声领域
传统K-means算法随机地选择初始聚类中心,对于中心点的选取比较敏感,容易陷入局部最优且准确率低.Min_max方法降低了对初始聚类中心的敏感性,提高了聚类结果的准确率.但是,Min_max方法在第一个初始聚类中心点选择上依然是随机的,可能因选到离群点而影响准确率和迭代次数.针对这个问题,赖玉霞等人通过设定高密度区域[19],然后在区域内利用Min_max方法来选取初始中心点,这样能够很好解决第一个点选到离群点的问题.但是这样得到的点过于稠密,容易造成聚类冲突,从而降低了聚类结果的质量.熊忠阳等人针对这一问题,提出了一种最大距离积法[20],能够在高密度领域内选点更加合理分散,但始终基于高密度领域,所以对于聚类效果的提升还是相对有限.本文仅仅在高密度领域内选取第一个点,并且为了避免后面的选点也会因Min_max方法的思想而选到噪声点,所以又设立了一个非噪声领域,有效避免了噪声点的选择,具体步骤如下:
第1步.密度计算
数据集中对象的密度即以每个对象为圆心,以数据集中任意两点间距离的平均值为半径的圆内包含其它对象的个数.包含的个数越多,说明该对象的密度越大.
这里的半径为对象间距离总和除以从数据集中任意取两个对象的所有排序次序,具体公式见公式(5).
(5)
其中,N为数据集的总个数,d(Oi,Oj)为对象Oi和对象Oj的欧式距离.
而对象Oi的密度为:以Oi为圆心,以avgDist为半径的圆内(含圆上)所包含的对象的个数,即满足条件d(Oi,Oj)≤α×avgDist时,则说明对象Oj在以Oi为圆心的圆内,具体密度公式见公式(6).
(6)
第2步.生成高密度领域
高密度领域即高于平均密度一定倍数的数据对象组成的集合.在第1步中可以根据公式(5)和公式(6)计算出不同对象的密度,平均密度avgDens即以所有对象为圆心的圆内(含圆上)包含的对象的个数除以数据集中对象的总个数,具体公式见公式(7).
(7)
根据公式(7)计算出的数据集中对象的平均密度,可以定义高于平均密度η倍的数据对象组成的集合为高密度领域,这里的η为高密度领域的调节系数,一般η≥1.
第3步.生成非噪声领域
非噪声领域即数据集中排除噪声点(离群点)的领域,这里根据第2步中公式(7)计算出的平均密度,定义低于平均密度ε倍的数据对象组成的集合为噪声点,这里的ε为噪声点调节系数,一般0<ε<1.
3.3 选取初始中心点
NonIID-DDMMK-means算法在初始中心点的选择上主要是基于Min_max方法的思想,该方法的大体过程如下所示.
Input:数据集O,聚类个数K
Output:K个初始聚类中心点C
Step1.从数据集中随机找一个点O1作为第一个初始中心点C1,即C1=O1;
Step2.遍历数据集中的其他对象,分别计算各个样本点与第一个初始中心点C1的距离,找到一个距离C1最远的点O2作为第二个初始中心点C2;
Step3.遍历剩余的所有对象,分别计算它们与C1和C2的距离,记为di1和di2.令其中较小值为min(di1,di2),并将较小值都存入集合D中.接着,计算集合D中所有距离的最大值为max(min(di1,di2)),记为O3;
Step4.重复上面的操作,直到找到K个初始中心点.
可以发现Min_max方法在第一个点的选择上依然是随机的.针对这一问题,本文在高密度领域中对第一个初始聚类中心进行确认,这里并不是选取高密度领域内密度最大的点作为第一个初始聚类中心点,而是选择高密度领域内距离样本集中心最远的点作为第一个初始聚类中心点,这样的选点更加符合聚类分布的特点.样本集的中心即样本中所有对象的均值,具体见公式(8).
(8)
在第一个初始聚类中心确认之后,使用Min_max方法对剩余的点进行选取,这里本文设立了一个非噪声领域,不仅可以防止选到的点为噪声点而影响聚类结果的情况,也可以防止所有的点都在高密度领域内选取,而导致的选点过于稠密,容易造成聚类冲突,从而降低了聚类结果的质量等问题的发生.
3.4 NonIID-DDMMK-means算法描述
综合上述3个过程,下面给出NonIID-DDMMK-means算法的整体描述:
Input:数据集O,聚类个数K
Output:完成聚类的K个簇
Step1.对数据集O,根据3.1小节中的计算过程来计算每一列属性之间的相关系数,并映射到数据集的对象之间,形成新的能够体现属性间交互关系的数据集.
Step2.将得到的数据集按照3.2小节中的步骤来计算出它的平均密度,并调节η和ε的值来生成合适的高密度领域和非噪声领域.
Step3.按照3.3小节中的思想,在高密度领域中选取一个距离样本集中心最远的点作为第一个初始中心点,然后在非噪声领域使用Min_max方法选择其它初始中心点,从而得到K个初始聚类中心.
Step4.从Step 3中得到的初始中心点出发,执行K-means算法,得到聚类结果.
4 实验结果与分析
实验环境:硬件:Intel(R)Core(TM)i7-6700 CPU@3.40GHz,8GB的内存;软件:VirtualBox虚拟机(Linux系统),集成开发软件Python3.6,Pycharm2017.实验采用的数据集:本文选用UCI中的Iris、Parkinsons、Blood数据集.

表3 测试数据集信息Table 3 Details of test data
在独立同分布下采用传统K-means算法(OR-K),原始Min_max方法(OR-MMK)以及文献[5-7]中的算法对三个数据集进行聚类测试.在非独立同分布下采用传统K-means算法(CR-K),原始Min_max方法(CR-MMK),文献[5,19,20]中的方法以及本文算法(CR-DDMMK)对三个数据集进行聚类测试.为提高数据可比性,在进行聚类测试之前,我们对原始数据集T和具有交互关系的数据集Tc的每一列进行归一化,这里采用Z-Score标准化.其中Iris、Parkinsons、Blood数据集的信息特征如表3所示.
4.1 验证聚类准确率的提升
实验中对独立同分布下的OR-K算法、OR-MMK算法以及文献[5-7]中的算法和非独立同分布下的CR-K算法、CR-MMK算法以及本文的CR-DDMMK算法在三个数据集上进行验证比较,这里本文取20次实验的平均值,具体结果如图1所示.

图1 聚类准确率对比Fig.1 Contrast of clustering accuracy
从图1中可以看出非独立同分布下的聚类准确率整体要高于独立同分布下的结果.其中,Iris数据集在非独立同分布下的CR-K算法低于独立同分布下的OR-MMK算法以及文献[5-7]中的算法主要是因为其受初始中心点影响较大,不当的初始中心点可能会导致聚类结果准确率较差.为了进一步的验证,本文对Iris数据集下的OR-K算法和CR-K算法进行详细对比,具体如表4所示.
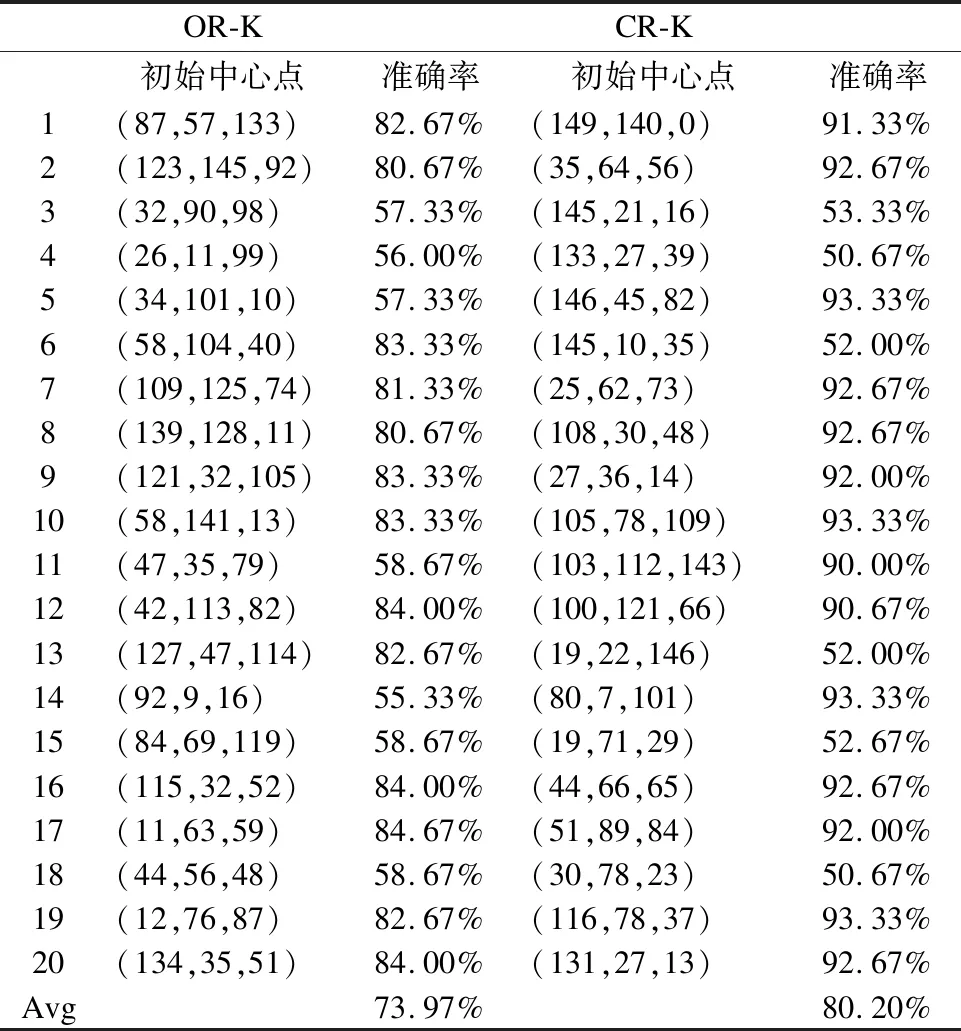
表4 两种算法在Iris数据集上的结果Table 4 Results of the two algorithms on the Iris data set
从表4中可以看出Iris数据确实受初始中心点的影响较大,不仅如此,还可以看出在独立同分布下的OR-K算法的准确率上限为84.67%,而非独立用分布下的CR-K算法的准确率上限为93.33%,这也证实了非独立同分布思想的有效性.并且本文的在非独立同分布下对Min_max方法进行优化的NonIID-DDMMK-means算法在准确率上较CR-MMK算法也有一定的提升.
对于Parkinsons和Blood数据集,从图1中可以看出其受初始聚类中心的影响相对较小,独立同分布下的OR-MMK算法和文献[5-7]中的算法对于聚类准确率的提升效果不明显,而非独立同分布下的CR-K算法和CR-MMK算法以及本文算法都较OR-K算法有一个大幅的提升,这主要得益于非独立同分布思想的有效性.并且可以发现本文算法较CR-MMK算法在这两个数据集中同样有进一步的提升,这也证实了本文算法的有效性.
4.2 验证聚类效果的提升
实验中对非独立同分布下的CR-K算法、文献[19,20]中的方法以及本文算法在非独立同分布下的三个数据集上进行验证比较,取20次实验的平均值,聚类平方误差和越小说明聚类效果越佳.由于Iris数据集与其它两个数据集的数值范围相差较大,所以将其分开展示,具体如图2-图3所示.


图2 Iris聚类效果对比Fig.2 Contrast of clustering effect on Iris图3 Parkinsons和Blood聚类效果对比Fig.3 Contrast of clustering effect on Parkinsons and Blood
从图2中可以看出,在非独立同分布下的Iris数据集中用文献[19,20]中的方法能够有效降低聚类平方误差和,提升聚类效果.同时,验证了文献[20]中的方法较文献[19]的确有所提升,但是选点还是有些稠密,因此可以发现本文的算法在使用双领域思想后能够较文献[20]有更进一步的提升.
从图3中可以看出,在非独立同分布下的Parkinsons和Blood数据集中用文献[19,20]中的方法同样能够降低聚类平方误差和.其中,文献[19]方法和文献[20]方法得出来的值是一样的,这主要是因为这两个数据集的初始聚类中心点的个数为2,两个文献中的方法在取前两个初始点时的思想是相同的.在这两个数据集中,本文的算法较前两者仍然有进一步的提升,这也验证了双领域思想对于聚类效果提升方面的有效性.
4.3 验证运算效率的提升
实验中对非独立同分布下的CR-K算法、CR-MMK算法、文献[5]和文献[19]中的方法以及本文算法在非独立同分布下的三个数据集上进行验证比较,取20次实验的平均值,迭代次数越少说明运算效率越高,具体结果如图4所示.

图4 迭代次数对比Fig.4 Contrast of iteration number
从图4中可以发现,在Iris数据集中迭代次数整体呈一个下降趋势,但是在Parkinsons和Blood数据集中,CR-MMK算法、文献[5]和文献[19]中的方法较最初的CR-K算法有一些波动,这主要是因为Min_max方法以及最大距离的方法在取第二个点时很容易取到噪声点,并且过于稠密的初始中心点也会影响运算效率.而本文的方法设立了双领域,并在第一个初始中心点的选择上更加符合聚类分布的特点,所以迭代次数要更少,运算效率更高.
5 结 论
针对传统K-means算法在进行数据聚类时,往往忽略了数据集中属性之间的交互关系以及其对初始中心点的选取比较敏感,不当的选入容易导致局部最优、聚类不稳点、收敛速度慢等问题,本文提出了一种非独立同分布下基于双领域思想和Min_max方法相结合的优化K-means初始中心选择的方法.该方法首先通过修改后的Pearson相关系数公式来计算不同属性之间的交互关系并映射到原始数据集的对象之间,从而形成能够体现交互关系的新数据集.然后通过设立双领域来避免选到噪声点以及选点过于稠密等问题.最后利用优化后的Min_max方法找到全部初始中心点并完成聚类.实验表明,本文提出的NonIID-DDMMK-means算法具有较高的准确率、较好的聚类效果以及相对较少的迭代次数.因此,本文提出的非独立同分布下的聚类算法是有效的,可行的.
