基于差分进化和森林优化混合的特征选择
2019-06-06林达坤黄世国林燕红洪铭淋
林达坤,黄世国,林燕红,洪铭淋
1(福建农林大学 智慧农林褔建省高校重点实验室,福州 350002)2(生态公益林重大有害生物防控福建省高校重点实验室,福州 350002)
1 引 言
特征选择在机器学习中扮演重要角色.通过特征选择可以提高模型预测精度、减少计算时间.但选择最优特征子集是一个NP-hard问题.当特征的数量为n时,其特征子集的数量为2n.应用穷举方法评价每个特征子集的效果将产生大量计算,现有计算能力一般难以满足计算需求.因此,许多学者提出众多特征选择算法旨在寻找近似最优解.特征选择方法一般分为嵌入式、过滤式和封装式.过滤式特征选择只考虑数据集的内在性质,在选择过程中不考虑目标评价问题.封装式特征选择通过评价不同特征子集寻找近似最优的集合.嵌入式特征选择则是将特征选择作为组成部分嵌入到学习算法.由于封装式特征选择一般比过滤式特征选择具有更优的评价结果[1],因此,基于元启发机制的特征选择方法一般采用封装式特征选择.
与传统特征选择方法(如序列向前算法和序列向后算法)易陷入局部最优相比[2],基于元启发机制的算法,特别是群智能计算方法由于其很强的全局搜索能力,在特征选择中得到广泛研究.目前,许多群体智能优化算法都已被成功应用到特征选择中.Babatunde等[3]在2014年提出一种基于二进制遗传算法的特征选择,结果表明该算法能够有效剔除无用特征并提高分类精度.但遗传算法的局部搜索能力较差,在进化后期搜索效率较低.Kennedy和Eberhart在1997年提出粒子群优化(Particle swarm optimization,PSO)的二进制版本[4].Emary等在2015年提出二进制灰狼优化(Binary grey wolf optimization,BGWO),结果表明该算法能够在特征空间中搜索到合适的特征组合[5].但该算法存在着收敛速度快,易早熟等缺点.Mirjalili在2015年提出基于蜻蜓算法(Dragonfly algorithm,DA)的特征选择[6].该算法在特征选择过程中也存在早熟、求解精度不高等问题.Ghaemi等在2014年提出森林优化算法(Forest optimization algorithm,FOA)[7],在2015年将其应用于特征选择中,结果表明森林优化算法具有较好的性能[8].但该算法的局部搜索方式趋向于穷举式搜索,存在着计算量大、收敛速度慢等问题.
由于各种群体智能优化算法有其优点也有不足,采用单一的算法有时难以获得满意的效果.近年来,一些学者综合多种群智能优化算法的优缺点,将其混合用于特征选择,取得了较好的效果.李虹等将遗传算法与粒子群优化算法结合,提出了混合粒子群优化算法,结果表明该算法具有较强的全局搜索能力,能够有效避免粒子群优化算法早熟收敛的问题[9].Khushaba等将蚁群算法与差分进化算法结合,进一步提升了蚁群算法的开发与探索能力,实验结果表明该算法能够取得较高的分类精度[10].Zawbaa等将灰狼优化算法与蚁狮优化算法结合,且将其用于小样本高维数据集的特征选择,结果表明该算法具有良好的降维效果与分类精度[11].
本研究针对森林优化算法收敛速度慢的问题,采用智能算法混合策略,提出基于差分进化和森林优化混合的特征选择.利用差分进化算法较快收敛的特点,在森林优化算法前期引入差分进化算法使其加快收敛.同时,针对森林优化算法局部搜索计算量大的问题,利用局部搜索中每棵树的取值仅改变一位的特点,给出了更有效的距离计算方法,进一步提高了算法的性能.
2 基于森林优化算法的特征选择
特征选择是指从已有的M个特征中选择N个特征使得系统的特定指标最优化.针对分类问题的特征选择,通常是产生一条二进制编码.“1”代表选择相应特征,“0”代表去除相应特征.
森林优化算法是模拟利用种子传播找到生存条件优越的栖息地来搜索问题的最优解.一棵树代表问题的一个可能解,由所有树构成的森林则代表问题所有解.该算法有5个步骤:初始化森林、局部播种、种群限制、全局播种、更新最优树.具体步骤如下.
Step1.初始化森林:产生n棵树,每棵树都以一维数组[v1,v2,…,vD,Age,Fitness]表示,其中D为问题的维数,变量V的取值为1或0,Age代表树的年龄,其初始值为0,Fitness为适应度值(评价树的好坏).
Step2.局部播种(Local seeding):每棵年龄为0的树产生LSC棵与父代完全相同的树,然后随机选中每棵新树的某一维(不包括Age与Fitness),将其值取反.将森林中的老树的年龄加1且新树的年龄设为0.
Step3.种群限制:森林中当树的年龄大于最大年龄数(Life time)将该树从森林中剔除并放入候选种群.当森林中保留下来的树的数量超过区域限制时,则剔除适应度值较差的树并将其也放入候选种群.
Step4.全局播种:从候选种群中随机选出一定数量的树.对每棵被选中的树随机选中GSC维,将其值取反.
Step5.更新最优树:将森林中适应度值最大的树作为最优树,并将该树的年龄设为0,以便于最优树能在下次迭代中进行局部播种.
3 基于差分进化和森林优化混合的特征选择
具有反馈机制的二进制差分进化(Binary Differential Evolution with Feedback Strategy,BFDE)[12]是二进制差分进化算法的变种,能获得更好的降维和分类效果.森林优化算法中的局部播种方式是一种精细搜索方法,计算量大,算法收敛速度慢,同时,差分进化具有较快的收敛速度,因此本研究在森林优化算法早期迭代阶段利用BFDE算法进行特征选择,后期则继续利用森林优化算法进行特征选择,以充分发挥森林优化算法局部搜索的优势.我们提出的新算法命名为差分进化和森林优化混合的算法(Differential Evolution Based Forest Optimization Algorithm,DEFOA).
3.1 具有反馈机制的二进制差分进化
BFDE的具体步骤如下:

(1)
S(xi,j,t)=1/(1+e-xi,j,t)
(2)

BFDE的变异操作方式为DE/current-to-best/1,具体操作如公式(3)所示.
(3)
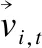
算法 1.
输入:种群大小N,最大迭代次数T.
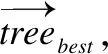

2.评价二进制种群Pbt.
fori=1 to N
利用公式(4)、(6)对种群Pt进行交叉变异操作产生新向量Gi,t,同时将界限控制在[xmin,xmax]之间.

End fori
利用公式(1)、(2)更新并评价二进制种群Pbt.
利用公式(5)进行反馈操作.
End for t
4.将二进制种群Pbt的每个个体xbi,t看作森林优化算法中的树,额外增加一维Age,Age初始值全为0.
fori=1 to N
对Age为0的xbi,t进行局部播种产生LSC棵Age为0的新树,xbi,t老化Age值加1.
评价每棵新树.
End fori
进行种群限制,清除前次迭代产生的候选种群,形成新的候选种群.
利用公式(7)、(8)对候选种群进行反馈调节.
对候选种群进行全局播种,评价新树并加入到二进制种群Pbt中.
为维持种群大小N,再次进行种群限制.
更新最优树.
End for t
(4)

BFDE在原有差分进化的基础上引入了反馈操作,利用公式(5)将二进制种群Pbt的信息反馈到原始种群Pt中.
(5)

3.2 差分进化和森林优化混合的特征选择
(6)
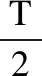
(7)

(8)
i=1,…,N,j=1,…,D.DEFOA的伪代码如算法1所示.
3.3 针对局部搜索阶段改进的K最近邻算法
在基于智能计算的封装式特征选择算法的更新迭代过程中,每更新产生一个新粒子需要对其进行评价.该评价过程计算量大,增加了算法的计算时间.特别是在DEFOA和FSFOA[8]的局部播种阶段会产生大量相似的粒子(新树与老树只有一维不同).若为了评价这些相似粒子,均利用分类算法重新训练,必将显著增加算法的计算量.
针对局部播种阶段这一特殊情况,本研究引入一种改进的K最近邻算法(K Nearest Neighbor,KNN)[13],以降低DEFOA算法的计算量,提高运行速度.该KNN用于森林优化时作如下改进:1)在局部播种时,Age为0的树所对应的样本距离被保留.2)评价新树时,只需计算值发生改变的维数所对应的样本距离.
改进的KNN的优点在于老树进行局部播种时无需重新计算新树所对应样本总距离,只需计算值发生改变的一维所对应样本距离与老树相加减即可,大大地减少了原本的计算量.
4 实验与结果
4.1 数据集
为了评价DEFOA的性能,使用不同的数据集进行实验.所使用数据集的具体信息如表1所示,共10个数据集.除SRBCT来自http://www.gems-system.org.外,其它数据集均来自UCI machine learning repository(http://archive.ics.uci.edu/ml/datasets.html).其中,Wine、Zoo、Dermatology的特征维度较低,Sonar、Movement、HilVally_noisetrain属于中维度数据集,Musk1、Arrhythmia、LSVT和 SRBCT属于高维度数据集.

表1 数据集Table 1 Datasets
4.2 参数设置
为了评估DEFOA的性能,DEFOA和现有的特征选择方法进行比较.本研究主要选择了6种算法:BFDE、FSFOA、BGWO、GA、BPSO和BDA.实验采用的是K作为分类器,K值设为5.10折交叉验证的分类错误率的平均值AE将作为适应度值,具体计算过程如公式(9)、公式(10)所示.
(9)
(10)
所有算法由美国MathWorks公司出品的MATLAB(R2014b)编程实现.所有实验均在3.6 GHz CPU和8GB RAM的Intel Core i5机器上独立运行10次.所有算法的迭代次数设为100,种群大小为50.在DEFOA中,F值设为0.9,CR值设为0.6.对于DEFOA与FSFOA的共有参数,“Life time”为15,“Transfer rate”为5%,LSC与GSC依赖于问题的维数,一般LSC为数据集维数的20%,GSC为数据集维数的40%.GA的交叉概率为0.8,变异概率为0.1.BPSO的学习因子c1和c2值都为2,其惯性权重区间为[0.4,0.9].
为进一步提升所有算法的性能,在进行实验前对数据集进行0-1标准化.具体如公式(11)所示,其中X代表原始变量值,X*代表标准化后的变量值,max是变量的最大值,min是变量的最小值.
(11)
4.3 结果与分析
图1表明FSFOA与DEFOA使用改进的KNN作为分类器后的运行时间减少率,易看出改进的KNN能够显著降低算法的运行时间.这也进一步证明引进的KNN能够有效解决森林优化算法局部播种计算量大的问题.
表2展示了DEFOA与其它算法的分类性能对比结果.Mean代表算法独立运行10次结果的平均值,Std代表其标准差.Rank是对算法在不同数据集上的性能对比排序结果,Mean值越小则排名越前,若Mean值相同,则Std值小的排前.从表2可看出DEFOA除在数据集Wine的排名在第2位外,其它数据集排名均在第1位,且其对应的标准差相对较小,说明DEFOA的分类性能较为稳定.Average Rank是对算法在不同数据集上排序值总和的平均值,根据Average Rank可得出每个算法的总排名.从表2易得出DEFOA的分类性能比其他6种算法好.

图1 新型KNN的计算效率Fig.1 Computational efficiency of new KNN

表2 算法分类性能对比Table 2 Comparison of classification performance in algorithms
为进一步验证DEFOA对分类性能的影响,将DEFOA与其它特征选择算法进行t检验,结果如表3所示.其中“+”表示DEFOA性能显著大于其它算法,“=”表示两者相似.易看出DEFOA除在数据集Wine、Zoo、Dermatology上与其它特征算法性能相似外,在其它数据集上的性能皆显著高于其它算法.因此,DEFOA在中维度和高维度数据集上具有良好的分类性能.
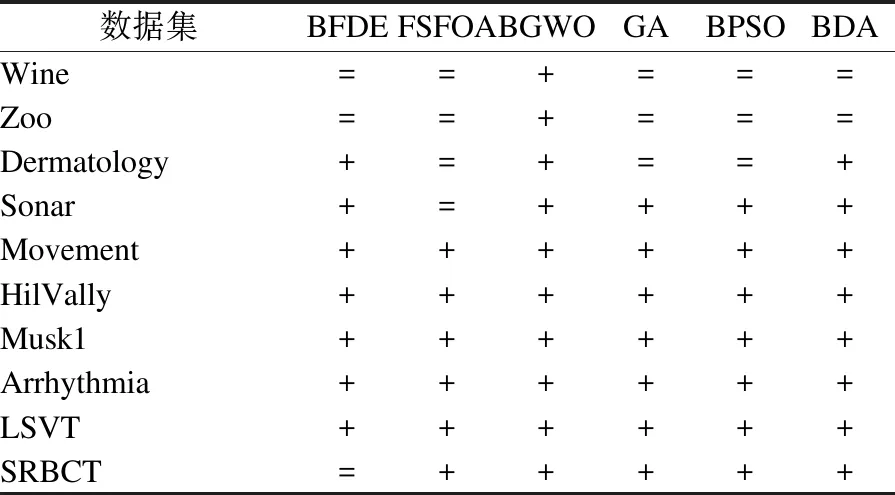
表3 DEFOA分类性能的t检验Table 3 T test for classification performance of DEFOA
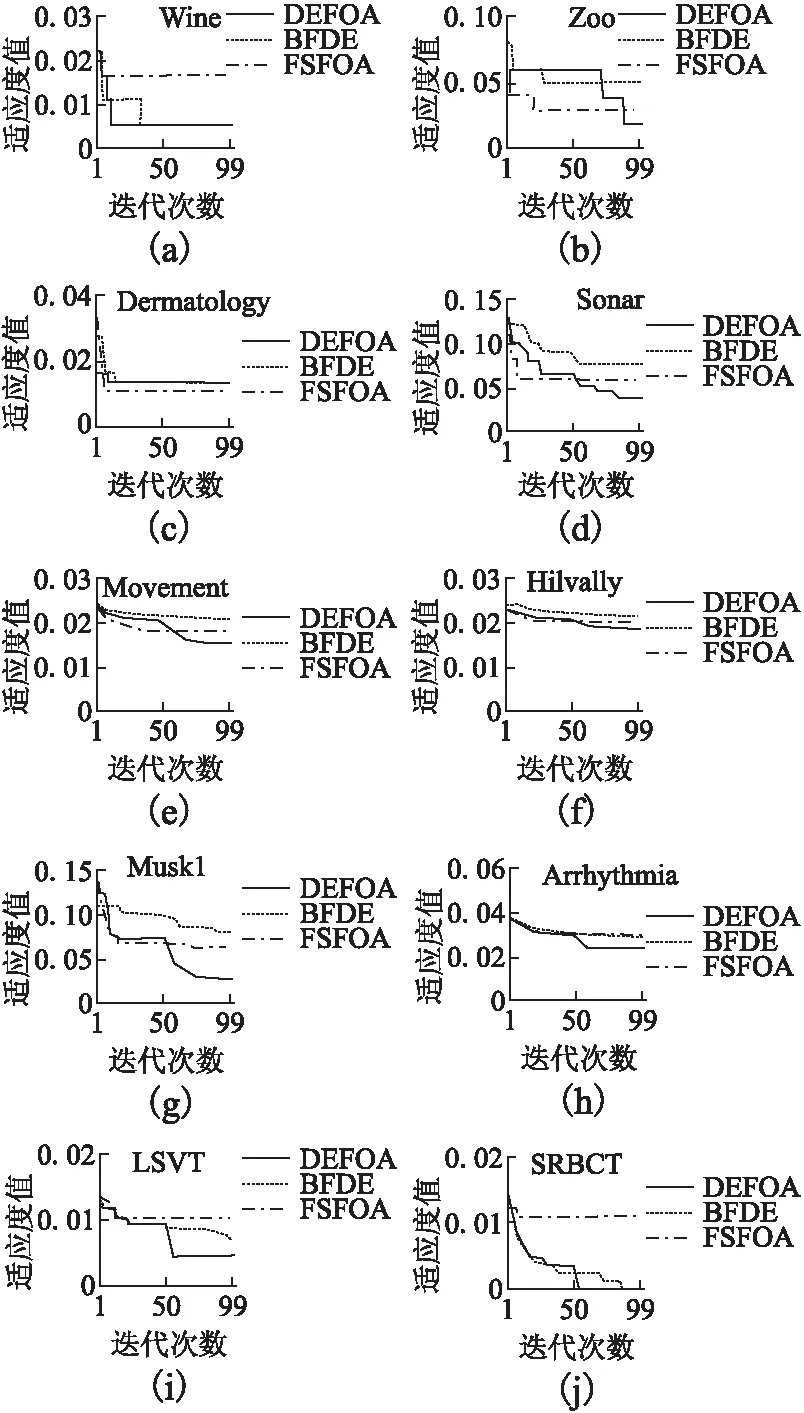
图2 算法收敛图Fig.2 Convergence diagram of algorithms
图2是不同算法在不同数据集上的收敛图.易看出DEFOA在各数据集上均能获得较好适应度值且具有更稳定的收敛速度.
5 结 语
本研究针对森林优化算法的局部播种计算量过大的问题,在森林优化算法的前期迭代中使用差分进化算法代替局部播种,提出差分进化和森林优化混合的算法.经实验验证,该算法具有良好的分类性能与稳定的收敛速度.此外,还引入一种改进的KNN代替传统的KNN作为分类器,实验结果表明改进的K最近邻算法能极大降低所提出的混合算法与森林优化算法的运行时间.
