基于双向量模型的自适应微博话题追踪方法
2019-06-06郭文忠
黄 畅,郭文忠,郭 昆
(福州大学 数学与计算机科学学院,福州 350116) (福建省网络计算与智能信息处理重点实验室,福州 350116) (空间数据挖掘与信息共享教育部重点实验室,福州 350116)
1 引 言
微博作为社交媒体的代表受到了大众的广泛关注,每天都会产生海量的数据信息.微博用户往往更加关注热点话题的进展,从而,微博的实时信息流中,用户对于话题的动态更新有着迫切的需求.话题跟踪技术作为话题检测与跟踪技术[1]的子任务之一,为互联网的信息过载[2]问题提供了良好的解决途径.话题跟踪技术,主要是对已知的某话题进行后续文本的持续跟踪,为用户提取话题的演化过程,对用户个性化推荐[3]的生成、观点的总结以及突发事件应急监测[4]等实际应用都有着重要的指导作用.
目前,微博话题追踪存在特征稀疏、话题漂移,微博向量化导致微博部分信息丢失等问题.针对特征稀疏问题,已提出多种扩展特征的方法[5-8];为了应对话题漂移问题,反馈迭代、词概率等方法[9,10]被提出;针对微博向量化问题,通常采用VSM或者词嵌入向量化方法[11,12],保留微博的新词或者语义信息.但仍存在微博向量化后丢失了微博语义或者忽略了微博中的新词,以及无法完全克服话题漂移等不足.
针对上述问题,本文提出基于双向量模型的自适应微博话题追踪方法(Self-Adaptive method based on Double-Vector model for microblog Topic Tracking,简称为SADV-TT).
本文的主要贡献如下:
1)提出双向量模型表示话题和微博,采用词嵌入的方式保留了文本的语义特性,同时利用VSM向量化的方式保留新词信息;
2)引入时间属性,提出一种自适应学习相似度阈值的策略,降低话题相关微博的漏检率,提高话题追踪算法的性能;
3)在话题追踪过程中动态更新话题模型,应对话题演化过程中的话题漂移,降低话题相关微博的漏检率和误检率.
2 相关工作
微博话题追踪方法总体可以分为基于分类的方法和基于查询向量的方法[13].
基于分类的方法是利用大量已知话题的微博语料训练分类器,实现对后续文档的分类.Lin J等[14]利用 hashtag 作为标签,为每个关注的话题训练一个语言模型,利用这些语言模型追踪 Twitter 数据流中感兴趣的话题.冯军军等[15]通过构建朴素贝叶斯网络模型,实现话题的追踪.唐孝军[16]采用随机森林分类器实现话题追踪.付鹏等[11]利用卷积神经网络构建话题追踪模型,追踪后续的热点话题微博.基于分类的话题追踪方法实现简单,但是依赖于初始样本训练,通常在话题产生的初始阶段,没有足够的可用于训练的初始样本,过少的训练样本会造成分类器的泛化能力严重降低,以至于话题追踪效果不佳.
目前使用较多的是基于查询向量的方法.基于查询向量的方法是根据先验数据集构建一个查询向量,然后计算后续微博与该查询向量的相似度,并根据相似度阈值进行判决,从而完成话题追踪.针对基于查询向量的方法通常只计算文本特征形式上的相似度,忽略了微博之间的语义信息,导致大量“语义相近、形式不同”的微博被漏检.张佳明等[13]提出一种基于词向量的微博事件追踪方法,将话题和微博分别用特征词表示,通过特征词之间的语义相似度,表示话题与微博间语义相似度,进而降低话题微博的漏检率和误检率.为了应对话题漂移现象,Zheng Yan等[12]提出利用反馈报道来补充话题模型进行增量学习的自适应话题跟踪方法.王慧[17]在改进原始向量空间模型的基础上,提出基于K-means 聚类的微博自适应话题追踪方法,在追踪话题的同时动态更新话题模型,减小话题漂移的速度.武军娜[18]提出一种新的包含静态和动态两部分的话题模型来实现话题的自适应跟踪,在话题追踪过程中话题模型的静态部分保持不变,动态部分动态更新来应对话题漂移问题.上述方法通过结合文本的语义信息或者动态更新话题模型的策略来提高话题追踪的性能,但是未考虑到话题追踪过程中相似度阈值设置偏大会导致漏检率偏大,相似度阈值设置偏小会造成误检率偏大,以及不同的话题模型相似度阈值不一定相同等问题,因此相似度阈值也应随话题模型的演化自适应学习.
针对上述问题,本文提出了基于双向量模型的自适应微博话题追踪方法.首先采用双向量模型表示话题和微博;其次,计算话题与微博的相似度,即计算话题双向量模型与微博双向量模型的余弦相似度.然后,自适应学习相似度阈值并将话题和微博的相似度与相似度阈值进行比较,判定微博是否为话题相关微博.最后,自适应更新话题模型,以应对话题漂移问题.
3 基于双向量模型的自适应微博话题追踪方法
3.1 SADV-TT的基本流程
SADV-TT方法主要包括以下几个步骤:
1)构建话题双向量模型和微博双向量模型;
2)计算话题与微博的相似度;
3)相似度阈值的自适应学习和阈值比较;
4)话题模型更新.
话题追踪具体流程如图1所示.
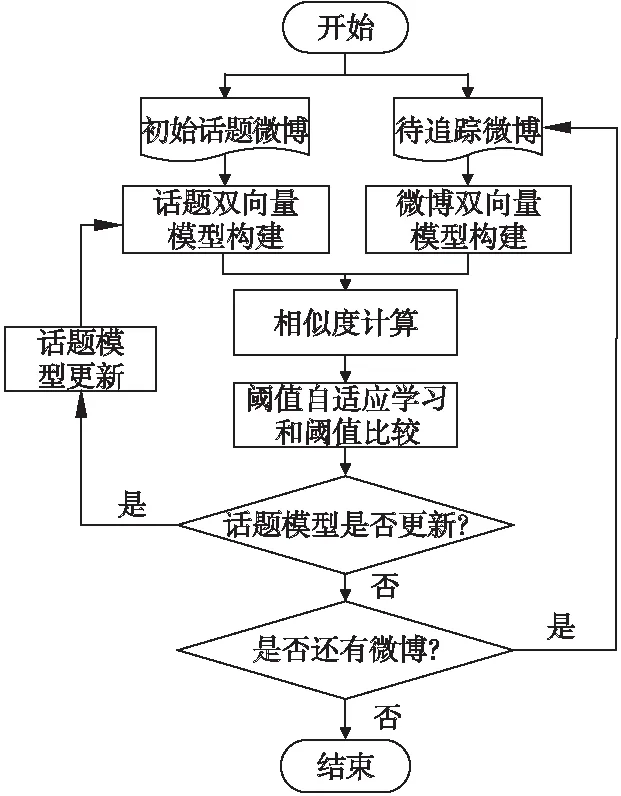
图1 话题追踪方法流程图Fig.1 Flow chart of topic tracking method
3.2 双向量模型构建
3.2.1 双向量模型构建的基本过程
双向量模型指将文本用词嵌入和VSM两种方法分别向量化,生成两个向量.
首先对文本进行特征选择,利用特征及其对应的权重值表示文本.特征选择采用基于BTM[19]主题模型的特征选择方法或者基于TFIDF的特征选择方法.基于BTM主题模型的特征选择方法,使用BTM主题模型挖掘文本中潜在的主题词分布,选择概率分布高的m个词以及对应的归一化后的概率分布值,作为文本特征表示文本.基于TFIDF的特征选择方法,采用TFIDF算法从文本中抽取TFIDF值大的m个词以及对应的归一化后的TFIDF值为特征权重来表示文本.TFIDF值的计算公式如公式(1)所示:
TFIDFw=tfw×lg(M/Mw+0.01)
(1)
其中,TFIDFw表示词w的TFIDF值,tfw表示词w在当前文本中的出现次数,M表示总文本数目,Mw表示含有词w的文本数.
文本特征集V的具体表示形式如公式(2)所示:
V={f1:ratef1,f2:ratef2,…,fm:ratefm}
(2)
其中,m表示特征词个数,fi表示文本的第i个特征词,ratefi指特征词fi的权重.
其次,采用VSM向量化方法和词嵌入向量化方法将文本特征集分别表示成向量.VSM向量化方法保留文本中的新词,忽略了文本的语义特性,而词嵌入向量化方法保留了文本特征词的语义信息,对词语的表达更加准确,但是微博文本中存在大量的新词,无法从预先训练的词向量表中获取相应的词向量,生成的向量忽略了新词在文本中的作用.综合考虑VSM向量化方法对新词有较好的处理能力以及词嵌入向量化方法存在的语义优势,将文本同时采用VSM和词嵌入两种方式向量化.因此,双向量模型由Word2Vec向量和VSM向量组成.本文采用2013年Mikolov Tomas[20]提出的Word2Vec中的Skip-gram模型在中文微博数据集上训练获得词向量.
Word2Vec向量是指将文本利用其特征词的词向量转化成的向量.将文本表示成文本中最有代表性的m个特征词的词向量与其特征权重相乘的和,如公式(4)所示.
k={k1,k2,…,kn}
(3)
(4)
其中,k表示文本向量,n表示向量维度,ki表示向量k第i维的值,m表示文本特征数目,wij代表该文本中第j个特征词的词向量第i维的值,ratej表示第j个特征词的特征权重.
VSM向量即将文本采用向量空间模型的方式表示成向量.一个特征表示成向量中的一维,在向量中的值等于特征词的特征权重.
3.2.2 话题双向量模型和微博双向量模型构建
在SADV-TT方法中,话题双向量模型包括初始话题双向量模型和追踪过程中的话题双向量模型两种.初始话题双向量模型首先从话题相关微博中随机选择x条作为初始话题微博,然后采用基于BTM主题模型的特征选择方法选择特征生成初始话题模型,并采用VSM向量化方法和词嵌入向量化方法将话题特征分别表示成向量,构建双向量模型.追踪过程中的话题双向量模型直接对话题模型中的话题特征采用VSM向量化方法和词嵌入向量化方法向量化,构建双向量模型.
微博双向量模型先采用基于TFIDF特征选择方法选择特征,然后将微博特征集向量化,构建双向量模型.
3.3 微博与话题的相似度计算
话题与微博的相关性用话题与微博的相似度来表示,相似度越大,相关性越大.微博与话题之间的相似度用微博双向量模型和话题双向量模型的相似度来表示.
双向量模型中含有VSM向量和Word2Vec向量.双向量模型之间的相似度等于两个模型中的Word2Vec向量的余弦相似度和VSM向量的余弦相似度的平均值,余弦相似度的计算方法如公式(5)所示:
(5)
其中,Simkd表示向量k和向量d的余弦相似度,ki表示向量k第i维上的值,di表示向量d第i维上的值.
话题与微博的相似度计算方法如公式(6)所示:
(6)
其中Sim表示话题与微博的相似度,simvsm表示双向量模型中的VSM向量之间的相似度,simword2vec表示双向量模型中的Word2Vec向量之间的相似度.
3.4 相似度阈值自适应学习
SADV-TT方法中的相似度阈值分为相似度最低阈值ε和反馈阈值δ.反馈阈值用于挑选与话题高度相关的微博作为反馈微博,更新话题模型.而相似度最低阈值是微博属于话题的最小边界,反馈阈值大于最低阈值.因此,如果微博与话题的相似度大于反馈阈值,则微博与话题高度相关,将其加入反馈微博集,用于生成新的话题模型.如果微博与话题的相似度大于最低阈值,则判定微博为话题相关微博.反之,如果微博与话题的相似度不大于最低阈值,则将微博判定为话题不相关微博.
一般而言,由于话题之间的差异,每个话题的相似度阈值也存在差异.因此,相似度阈值ε和δ均采用自适应学习的方式生成.对于每一个话题的初始反馈阈值,用初始话题与初始话题相关微博的相似度的平均值表示.而追踪过程中反馈阈值则与前s个时隙的反馈微博与话题的相似度的平均值相关,时间间隔越近相关性越强.阈值ε和δ的计算如公式(7)-公式(8)所示.
(7)
εt=δt-C
(8)
其中,t表示第t个时隙,δt表示第t时隙的反馈阈值,feedsimi表示第i个时隙的反馈微博与话题相似度的平均值,εt表示第t时隙的最小阈值,C表示话题容忍度,最低阈值与反馈阈值相关,其值等于反馈阈值减话题容忍度C.
3.5 话题模型更新
为了有效应对话题追踪过程中产生的话题漂移问题,动态更新话题模型成为话题追踪必不可少的步骤.一般来说,话题追踪过程中,话题模型与上一个时隙的相关微博具有较大的相关性,通过从上一个时隙的反馈微博中提取话题特征生成动态话题模型.如果话题模型仅由动态话题模型来决定,会使与原话题相关的微博被漏检,可以通过保留初始话题模型的部分特征来克服.因此,在SADV-TT方法中,新话题模型由初始话题模型和动态话题模型以及原话题模型共同构建.话题模型构建步骤:
1)构建初始话题模型.利用基于BTM主题模型的特征选择方法从初始话题微博集中选择话题特征生成初始话题模型;
2)构建动态话题模型.采用基于BTM主题模型的特征选择方法从反馈微博集中选择话题特征,生成动态话题模型;
3)更新话题模型.原话题模型加入初始话题模型和动态话题模型的特征,如果原话题模型中已经存在某个特征,用三个模型中该特征的最大权重值更新原话题模型特征的权重值.接着将原话题模型的特征按权重值降序排列,选择靠前的T个特征及其权重值作为新话题模型更新原话题模型.
为了提高话题追踪方法的效率,SADV-TT的话题模型更新设置了时间条件和反馈微博数阈值feed.如果只要有反馈微博加入就更新话题,则会使话题更新次数过于频繁,影响追踪效率.并且,如果该时隙内加入的反馈微博数太少,则可能是噪音微博,所以不更新话题.因此,一个时隙结束后,如果新加入的反馈微博数大于feed,则更新话题.否则,不更新话题.一般来说,20个特征即可以表示一个话题,所以T取20.
3.6 复杂度分析
设初始话题微博数为x,BTM模型迭代次数k.每个时隙的微博共有M条.一条微博中文字符个数w.t表示第t个时隙,s表示相关时隙个数.
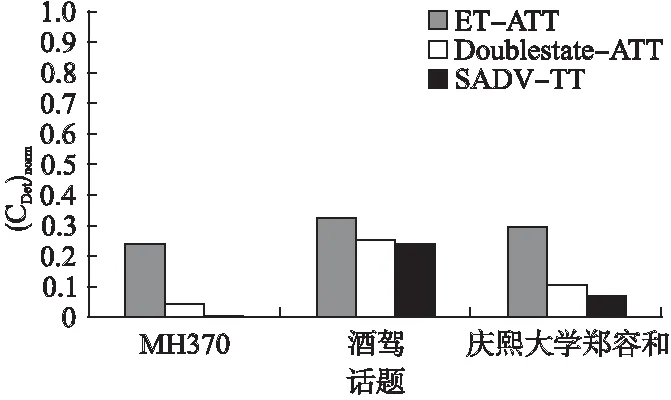
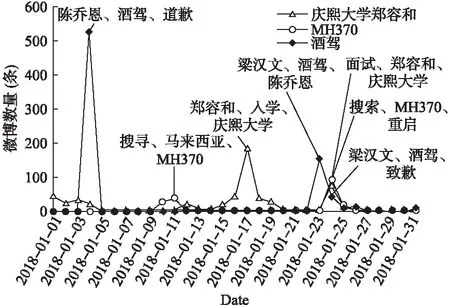
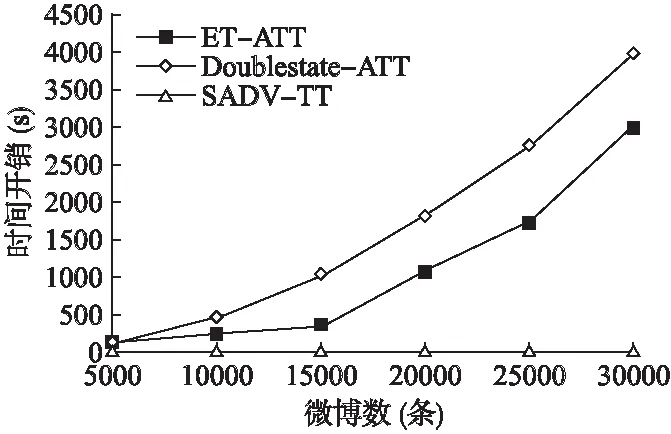
首先分析SADV-TT方法的时间复杂度.在话题和微博表示中,初始话题生成的时间复杂度为O(xkw2),微博特征生成的时间复杂度为O(Mw).因此话题和微博表示的时间复杂度为O(xkw2+Mw)=O(w(xkw+M))).话题与微博向量化的时间复杂度为O(Mw).话题与微博的余弦相似度计算时间复杂度为O(Mw).阈值自适应学习的时间复杂度为O(s),话题模型更新的时间复杂度为O(Mkw2).综上所述,总的时间复杂度为O(w(xkw+M))+Mw+Mw+s+Mkw2),在存在大量微博数据的情况下,一般有s< 接下来分析SADV-TT的空间复杂度.微博存储需要存储空间O(M);在话题和微博表示中,话题生成需要存储空间O(xw2),话题和微博特征存储需要O((M+ 1)w),话题和微博表示总的空间复杂度为O(xw2+(M+ 1)w);在话题与微博向量化中,存储话题向量和微博向量需要O(2Mw);在相似度阈值自适应学习中,需要存储微博与话题的历史平均相似度需要O(t)的存储空间.在话题模型更新中,空间复杂度为O(2Mw).综上所述,SADV-TT方法总的空间复杂度为O(M+(xw2+(M+ 1)w)+2Mw+t+2Mw).在存在大量微博数据的情况下,一般有w<=140< 实验选取漏检率、误检率和归一化跟踪代价作为微博话题追踪的性能评测指标[21],其计算方式具体如公式(11)所示. (9) (10) (11) 其中,Pmiss为漏检率,PFA为误检率,Missnum是与话题相关的微博被判断为与话题不相关的微博总数,TotalY为与话题相关的微博总数,Faultnum是与话题不相关的微博被判断为与话题相关的微博总数,TotalN为与话题不相关的微博总数.Cmiss和CFA分别是系统漏检和误检的条件概率,Ptarget和Pnon-target是先验目标概率(Pnon-target= 1 -Ptarget).在实际测评中:Cmiss=1.0,CFA=0.1,Ptarget=0.02,Pnon-target=0.98,(CDet)norm的数值越小,则表明系统的性能越好. 实验数据采用八爪鱼软件随机抓取从2018年1月1日至2018年1月30日共计30000多条微博,构成本实验原始数据.从原始数据中抽取3个话题进行跟踪,共包括1386条话题相关微博,话题名称分别为MH370、酒驾以及庆熙大学郑容和,每个话题的具体微博数目如表1所示.除上述3个话题以外其余数据均作为反例.实验以天为单位进行时隙划分. 表1 实验数据集 话题数量MH370211酒驾912庆熙大学郑容和263 在本节中,通过实验来验证SADV-TT方法的可行性和高效性.第1个实验是参数实验,通过实验确定话题相似度阈值中的容忍度C以及反馈微博阈值feed的取值.第2个实验是为了验证话题和微博采用双向量模型表示在话题追踪中的有效性.第3个实验是为了验证自适应相似度阈值学习策略以及话题模型更新策略的可行性,第4个实验是为了检验SADV-TT话题追踪方法的应用性能. 4.3.1参数实验 为了避免参数选择的偶然性,参数实验从反例数据集中再随机选择7个话题总共10个话题微博组成待追踪数据集,剩余微博数据作为反例. 最小阈值的参数容忍度C的选择会影响话题追踪的效果,如果C值设置过大,会增大误检率,如果C值设置过小,则会导致漏检率增大,因此需要进行参数实验.实验结果如图2所示. 图2 参数C实验结果Fig.2 Parameter experiment results of C 由图2可知,每个话题的(CDet)norm指标均随着C值增大先缓慢减小后快速增大,最终趋近于一个固定常数.同时,可以发现当话题容忍度C处于0.25和0.3时,话题的(CDet)norm指标较小且较稳定,因此接下来的实验中,取话题容忍度参数C=0.3. 为了验证反馈微博阈值feed是否会影响话题追踪的性能,对参数feed进行实验.feed参数从区间[1,10]以1为步长取值进行实验.图3给出feed参数的实验结果. 由图3可以看出,进行实验的话题中有些话题的(CDet)norm指标随参数feed的取值不同有变化,而所有话题的(CDet)norm指标在feed大于6时几乎保持稳定.因此接下来的实验中,反馈微博阈值参数feed取值为10. 4.3.2话题模型表示方案的对比实验 为了测试双向量模型表示方法在话题追踪中的有效性,对SADV-TT方法中的话题和微博向量化步骤进行改造,形成不同的话题追踪方法:采用基于TFIDF特征选择方法的双向量模型的方法称为TFIDF-TT方法;采用基于BTM主题模型进行特征选择并采用词嵌入的方式向量化话题和微博的方法称Vector-TT方法;采用基于BTM主题模型提取特征然后采用VSM方法向量化话题和微博的方法称为VSM-TT方法;采用基于BTM主题模型特征选择方法的双向量模型的方法称为DoubleVector-TT方法.在相同实验数据下将DoubleVector-TT方法与TFIDF-TT方法、Vector-TT方法以及VSM-TT方法进行比较,以验证双向量模型表示方法的可行性.相似度阈值参数设置:TFIDF-TT=0.2,Vector-TT=0.45,VSM-TT=0.04,DoubleVector-TT=0.2.表2给出的是4种方法在3个话题上的平均漏检率、平均误检率以及平均(CDet)norm指标. 图3 feed参数实验结果Fig.3 Parameter experiment results of feed 表2 话题模型表示结果比较 话题追踪方法漏检率误检率(CDet)normTFIDF-TT0.05880.02320.1724Vector-TT0.1264 0.0035 0.1433 VSM-TT0.1365 0.0096 0.1836 DoubleVector-TT0.0729 0.0122 0.1327 由表2可以看出,DoubleVector-TT方法 与TFIDF-TT方法相比,综合指标(CDet)norm下降了0.0397,主要原因是前者采用基于BTM主题模型的方法进行特征选择,BTM主题模型通过对词对集进行主题建模,结合了文本中词共现属性,克服了微博短文本的特征稀疏问题.而基于TFIDF的特征选择方法会将每条微博中都出现的重要特征词权重赋值为0,导致话题建模效果差,最终影响话题追踪性能.因此,话题双向量模型中的特征选择方法采用基于BTM主题模型的方法.DoubleVector-TT方法与Vector-TT方法相比,平均误检率增加了0.0087,但是平均漏检率降低了0.0535,最后,综合指标平均(CDet)norm指标降低了0.0106.与VSM-TT方法相比,DoubleVector-TT方法平均误检率虽然牺牲了0.0026,但是平均漏检率降低了0.0636,最后,综合指标平均(CDet)norm指标也降低了0.0509.总体上来说,DoubleVector-TT方法优于Vector-TT方法和VSM-TT方法,因此双向量模型文本表示方法有助于提高话题追踪的性能. 4.3.3相似度阈值自适应学习及话题模型更新 本实验的目的是检验相似度阈值自适应学习策略以及话题模型更新策略的有效性.为了区分SADV-TT方法是否实现话题模型更新,将未实现话题模型更新步骤的SADV-TT方法简称为DV-ATTA方法.实验通过比较SADV-TT方法与DV-ATTA方法以及DoubelVector-TT方法在3个话题上的平均漏检率、平均误检率以及平均(CDet)norm指标来评估方法的优劣,进而检验相似度阈值自适应学习策略以及话题模型更新策略的有效性.其中DV-ATTA方法和SADV-TT方法的相关时隙设置为4.表3给出反馈阈值δ自适应学习以及话题模型更新的实验结果.由于最低阈值仅与反馈阈值差一个常量C,表3也可以同时表示最低阈值的实验结果. 表3 自适应学习相似度阈值和自适应更新话题 话题追踪方法漏检率误检率(CDet)normDoubleVector-TT0.0729 0.0122 0.1327 DV-ATTA0.0855 0.0050 0.1101 SADV-TT0.0825 0.0044 0.1041 由表3可知,DV-ATTA方法与DoubleVector-TT方法相比,平均(CDet)norm降低了0.0226.因此,动态学习话题相似度阈值的策略对话题追踪的性能具有积极作用.相比DV-ATTA方法,SADV-TT方法的平均漏检率、平均误检率以及综合指标平均(CDet)norm均有降低.因此,话题模型更新策略可以应对话题追踪过程中存在的话题漂移问题. 4.3.4话题追踪应用性能实验 本实验为了验证SADV-TT方法在话题追踪中的应用性能,将其与张佳明等[13]提出的方法(下文简称为ET-ATT方法),以及武军娜[18]提出的Doublestate-ATT方法进行对比.算法参数设置如下:ET-ATT方法中的初始话题关键词个数和微博关键词个数分别取8和7,相似度判决阈值取0.05;Doublestate-ATT方法中的反馈阈值和相关阈值分别取0.2和0.05,滑动文本窗长度取5.图4给出SADV-TT与其他方法在话题追踪应用性能上比较的实验结果. 由图4可知,从3个话题上的归一化跟踪代价指标来看,SADV-TT方法最优,Doublestate-ATT次之,ET-ATT最差.主要原因是ET-ATT方法的话题模型和相似度阈值在话题追踪过程中均不更新,追踪过程中造成了严重的话题漂移问题,同时该方法采用特征词的词向量表示话题以及微博,保留了微博的语义信息,但忽略了微博中的新词信息.Doublestate-ATT方法考虑了话题模型的动态更新,克服了话题模型不变性带来的话题漂移问题,因此优于ET-ATT方法,但是相似度阈值不变性也会导致话题漂移,同时,Doublestate-ATT采用TFIDF方法表示话题和微博,保留了新词信息但忽略了语义信息.而SADV-TT方法在话题追踪过程中动态更新话题模型的同时更新话题相似度阈值,在一定程度上克服了话题模型不变性和相似度阈值不变性带来的话题漂移问题,而在话题和微博向量化表示方面,SADV-TT方法采用双向量模型,保留语义信息的同时也保留了新词信息,因此效果更优. 图4 性能比较实验结果Fig.4 Experimental results of performance comparison 为了更好地记录话题的演化过程,每次更新话题模型时,SADV-TT方法从话题特征中提取3个权重值最大的特征词表示话题.图5给出3个话题的演化过程. 图5 话题演化结果Fig.5 Topic evolution results 由图5可以看出MH370、酒驾以及庆熙大学郑容和这3个话题在2018年1月期间的演化过程.如酒驾话题,1月4日陈乔恩酒驾成为微博的热门话题,1月24日梁汉文酒驾引起热议,1月25日梁汉文对酒驾事件致歉. 为了验证SADV-TT方法的时间性能,将其与ET-ATT方法及Doublestate-ATT方法在不同的数据量上进行对比实验.结果如图6所示. 图6 时间性能比较实验结果Fig.6 Time performance of topic tracking methods 由图6可以看出,ET-ATT方法和Doublestate-ATT方法的时间消耗随着数据量的增加而增大.这主要是由于ET-ATT方法采用特征词列表的形式表示微博和话题,通过特征词之间的语义相似度,表示话题与微博间语义相似度.由于微博和话题均含有多个特征,假设话题关键词有l1个,微博关键词有l2个,一条微博就需要l1×l2次相似度计算,因此增加了算法的运行时间.Doublestate-ATT方法每次有新的反馈微博加入时,马上就动态更新话题模型并且新微博加入时需要在已追踪的所有微博上计算词的TFIDF值,因此随着微博数量的增大,算法运行时间快速增加.SADV-TT方法时间开销小,并且呈平缓增长的趋势.主要原因是SADV-TT方法将微博按照时隙划分,微博表示时仅与单个时隙内的微博相关,减少了时间开销.在相似度计算时,SADV-TT方法先将话题和微博采用双向量模型转成向量,再对话题双向量模型和微博双向量模型计算相似度,减少了相似度计算次数.同时,SADV-TT方法中,话题模型的更新也是以时隙为单位.因此,SADV-TT方法相比ET-ATT和Doublestate-ATT这两种方法,时间开销大幅减小. 本文提出了一种基于双向量模型的自适应微博话题追踪方法.首先采用组合词嵌入和VSM方法的双向量模型表示话题和微博,保留微博和话题的语义特性的同时解决了新词问题.其次,自适应学习相似度阈值,降低话题相关微博的漏检率,提升追踪算法的性能.最后,在追踪过程中,自适应更新话题模型,能够有效地应对话题发展过程所产生的漂移.在真实的微博数据集上的实验结果表明:该方法能够降低话题相关微博的漏检率和误检率,最终降低话题跟踪代价.下一步将在更大规模的语料上进行实验,测试基于双向量模型的自适应微博话题追踪方法的话题追踪性能.4 实 验
4.1 度量标准
4.2 数据集
Table 1 Experimental data set
4.3 实验和结果
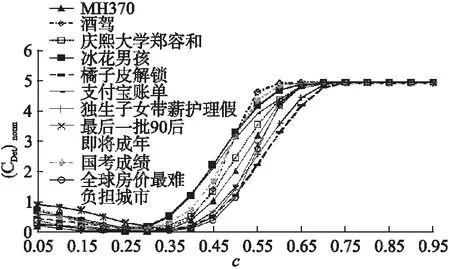
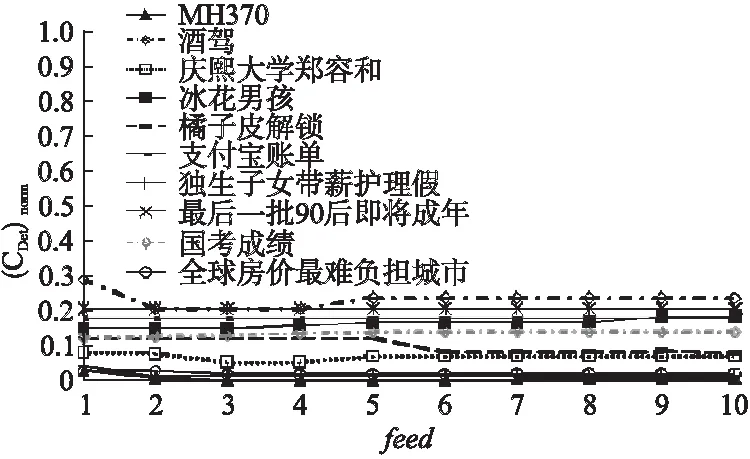
Table 2 Topic model representation results compare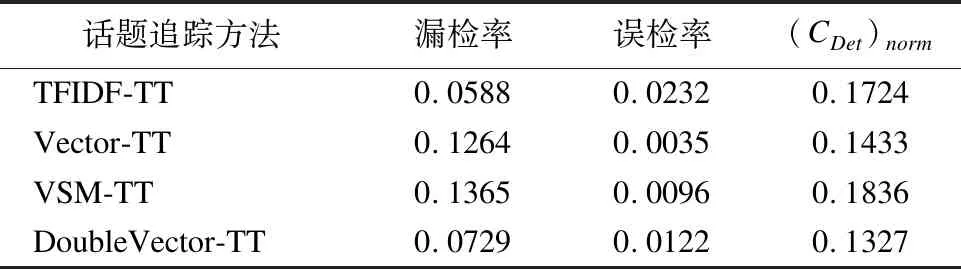
实验结果
Table 3 Experimental results of adaptive learning similarity
thresholds and adaptive updating topic models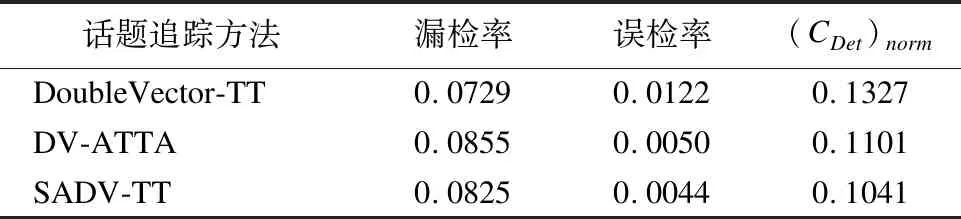
5 总 结
