基于CUDA的KNN算法并行化研究
2019-06-06刘端阳郑江帆
刘端阳,郑江帆,刘 志
(浙江工业大学 计算机科学与技术学院,杭州310023)
1 引 言
分类技术在许多领域得到广泛应用,比如人工智能,网络入侵检测等.分类技术是把未知分类的样本数据经过一系列模型之后分到若干已知分类的过程[1].它先通过已有的训练数据集进行学习和分析,从这些数据的分布中找出分类的规律,逐步优化分类的模型,从而判断新数据属于哪个类别.K最近邻(KNN:K-Nearest Neighbor)算法[2]是最为流行的分类算法之一,广泛应用于数据分析、图像处理、文本分类[3]等领域.KNN算法在距离计算阶段需要计算每个测试数据点到所有训练数据点的距离,距离排序阶段需要对距离向量进行排序.如果任务的测试数据总量为m,训练数据总量为n,数据的维度为d,则距离计算的时间复杂度为O(mnd),排序阶段的时间复杂度为O(mnlogn).随着测试数据集和训练数据集规模的增加,算法的时间成本也会成倍增长,无法满足大数据时代下的快速计算需求.因此对于计算密集型的KNN算法,运用CUDA(Compute Unified Device Architecture)并行化该算法,能够节省大量计算时间.CUDA是NV-IDIA公司推出的通用并行计算架构,它采用GPU(Graphics Processing Unit)来解决复杂计算问题.CUDA提供了硬件的直接访问接口,并不依赖传统的图形API,实现GPU的访问,降低了图形处理器的编程难度.
国内外已经有很多基于CUDA架构的KNN以及其他算法的并行化研究,Jian等[4]将输入的数据分组,在每个组内进行并行计算,然后得到每个组的top-K元素队列,最后合并每个组得到全局的K个近邻,该方法降低了距离排序的时间复杂度,但是在距离的计算阶段并行度不高.Garcia等[5,6]将KNN的暴力搜索算法并行移植到GPU中执行,在距离计算阶段使用了分块的矩阵乘法,具有良好并行性,但是在距离排序阶段时间复杂度较高.Dashti等[7]在面对高维度数据时合理使用线程加速距离计算,并且在GPU中并行实现了三种距离排序方法,但是当训练集数据量很大时排序阶段的加速效果有限.Masek等[8]和王裕民等[9]使用多块GPU设备搭建了一个GPU集群,利用GPU的集群优势对KNN和卷积神经网络算法进行加速,该方法可以处理更加庞大的数据集,不过提高了硬件成本.Liang等[10]提出cuKNN算法,采用数据流的方式对输入数据进行计算,利用共享内存加速每个测试数据距离向量的排序,能够批量处理输入数据的同时也提升了性能.Barrientos等[11]提出基于CUDA的穷举排序算法解决KNN问题,在K值较高的情况下也有良好的加速比.Mayekar等[12]提出一种并行的KNN方法快速解决字符识别的问题,并且能保持较高的准确率.
基于上述国内外的研究现状,本文提出了新的KNN并行化算法(即GS_KNN).新算法充分利用了CUDA函数库以及内存体系,将算法的所有计算过程都移植到GPU中,发挥其良好的运算能力.在运算量最大的距离计算阶段,将测试数据集和训练数据集存储在CUDA全局内存中,使用Cublas函数库的通用矩阵乘计算,提高了运算速度.在距离排序阶段,针对k值的大小提出了两种优化策略,分别是基于k次最小值查找的最近邻选择和基于双调排序的最近邻选择,降低了时间复杂度.在决定分类标号阶段,采用了CUDA内部的原子加法操作,GPU全程参与计算,从而提高了整体性能.最后通过实验证明,在保证算法鲁棒性的前提下,获得了良好的加速效果.
2 背景知识
2.1 KNN算法
KNN算法是目前最为流行的分类算法之一,该算法是一种基于距离的分类,通过计算测试数据与训练数据之间的距离或者相似度来进行分类,同一类别的内部数据之间具有较高的相似度,而不同类别之间数据相似度较低.现有R={r1,r2,…,rn}是一个拥有n个点的输入训练集,其中每个点的数据维度为d,即rj=(rj1,rj2,…,rjd),而S=(s1,s2,…,sm)是与R在同一个维度空间上的输入测试集.KNN算法的目标是对于每一个si∈S,搜索距离si最近的k个R数据点,然后根据这k个数据点的类别判断si的类别.如图1所示,表示一个R大小为15,k等于4的查询例子.
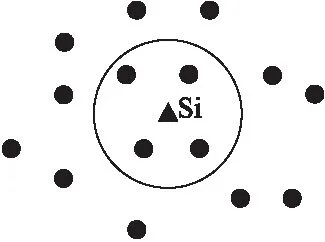
图1 KNN查询示例Fig.1 KNN query example
求解KNN算法最经典的方法就是通过暴力搜索解决,具体算法过程如算法1所示.
算法1.基于CPU的串行KNN算法
输入:包含n个点的带有分类标号的训练数据集R;包含m个点的无分类标号的测试数据集S;最近邻个数k.
输出:m个测试数据的分类.
1)计算测试集S中点si到所有rj的距离.
2)对步骤1得到的n个距离进行升序排序.
3)根据排序结果,选择前k个最小距离,得到距离点si最近的k个训练数据.
4)统计这k个训练数据的分类标号,出现次数最多的那一个标号即为点si的分类.
5)循环步骤1至4,一直到m个测试数据的分类计算完毕.
由于数据维度为d,步骤1(即距离计算阶段)的时间复杂度为O(nmd),步骤2(即排序阶段)的时间复杂度为O(mnlogn).步骤4(即决定分类标号阶段)的时间复杂度为O(mk),此值较小,可忽略不计.当训练数据集n很大时或者面对高维度数据时,运用CUDA计算架构并行化KNN算法通常可以取得很好的加速效率.
2.2 CUDA编程模型
CUDA是NVIDIA公司推出的一款通用并行计算架构,CUDA架构改变了传统的GPU编程方式,它不需要将程序任务转换为GPU图形处理任务,降低了开发难度.CUDA架构主要包括计算核心和存储器体系.每个GPU计算核心由多个流多处理器 (stream multiprocessor,SM) 组成,每个SM由多个标量处理器 (stream processor,SP) 组成.同时,GPU提供了可供线程访问的多级存储器.每个线程具有私有的本地存储器,每个线程块则有共享存储器,它对块内所有线程共享数据,并且它的生命周期与块相同,读写速度快.常量存储器和纹理存储器是只读存储器,可以针对不同的用途进行优化,全局存储器则用于接收从CPU端传入的数据.
在CUDA编程模型中,GPU被认为是能够并行执行大量线程的协处理器.一个简单的源程序包括运行在CPU上的主机端代码和运行在GPU上的内核(kernel)代码.Kernel函数通过__global__类型限定符定义,并通过Kernel<<
3 基于CUDA的KNN算法并行优化
分析串行KNN算法的流程可知,算法的时间开销大部分都在距离计算阶段和排序阶段.因此本文着重在这两个步骤上进行并行优化,并且在GP-U中进行所有计算.以下四个小节详细介绍了GS_KNN算法的优化过程.
3.1 基于Cublas的距离矩阵计算
Cublas Library是基于NVIDIA的通用函数库,它实现了Blas(基本线性代数子程序),它允许用户访问GPU中的计算单元,在使用时在GPU中分配所需的矩阵向量空间并填充数据,然后调用其中的函数可以加速向量和矩阵等线性运算.对于KNN算法中庞大的距离计算量,本文利用Cublas库中的矩阵乘法函数cublasSgemm()来加速距离计算,该函数能实现向量与矩阵,矩阵与矩阵之间的运算,并且拥有很好的加速比.
cublasSgemm()函数调用时有许多参数,调用方法为cublasSgemm(handle,transa,transb,m,n,k,*alpha,*A,lda,*B,ldb,*beta,*C,ldc),在Cublas里面所有的矩阵都是按照列优先方式存储,lda,ldb,ldc代表矩阵A,B,C的行数,矩阵A的维度为m*k,B的维度为k*n,C的维度为m*n,transa和transb代表矩阵A和B是否转置,函数实现的矩阵运算为:
C=alpha*OP(A)*OP(B)+beta*C
(1)
为了满足公式(1),GS_KNN算法的距离度量选择欧几里得距离的平方.这样,GS_KNN算法的距离计算可以转化为:
|x-y|2=x2+y2-2x*y=alpha(x*y)+beta(x2+y2)
(2)
其中,alpha取值为-2,beta取值为1.在设计CUDA核函数时,如果有m个测试数据点和n个训练数据点,数据维度为d,则矩阵A为x,代表m*d维的测试数据点矩阵,矩阵B为y,代表n*d维的训练数据点矩阵,由于x和y都是按照列优先方式存储,实际上在函数运算时矩阵A的维度为d*m,矩阵B的维度为d*n,为了得到m*n维的距离结果矩阵,需要将矩阵A进行转置,矩阵B不需要转置,所以将transa这个参数的值设为CUBLAS_OP_T代表转置,transb这个参数的值设为CUBLAS_OP_N代表不需转置.由于矩阵A的行数为m,矩阵B的列数为n,矩阵A的列数为d,所以分别将函数参数列表中的m赋值为m,n赋值为n,k赋值为d.在调用函数之前先要计算矩阵C也就是x2+y2的值,对于x2算法开启m个线程,若矩阵A在CUDA内存中的地址为p,线程编号为threadId,每个线程计算地址在p+d*threadId至p+d*(threadId+1)上的数据平方并求和,即一个测试数据点在d个维度上的平方和.对于y2开启n个线程,若矩阵B在CUDA内存中的地址为q,线程编号为threadId,每个线程计算地址在q+d*threadId至q+d*(threadId+1)上的数据平方并求和,即一个训练数据点在d个维度上的平方和.得到以上两个结果之后,在CUDA中继续开启n个线程,每个线程将一个训练数据点的平方和分别与m个测试数据点的平方和相加从而得到维度为m的向量,则n个线程计算得到m*n维的矩阵,即表达式为x2+y2的输入的矩阵C.最后将矩阵A,B和C在CUDA全局内存中的地址指针传入cublasSgemm()函数,函数返回m*n维的距离结果矩阵,每一行向量代表一个测试数据点分别与n个训练数据点的距离.
3.2 基于k次最小值查找的最近邻选择
通过计算获得每个测试数据点的距离向量后,需要进行排序.虽然有不少研究把排序算法移植到CUDA中执行,如Sintorn等[13]和Satish等[14]的研究,但算法的时间复杂度为O(nlogn),并行度不高.通过分析KNN算法可知,参数k往往远小于训练集数据量n,所以对于每一个测试数据来说,没有必要将它到训练集的所有距离都进行排序,只需要获得前k个最小距离即可.冒泡排序算法和选择排序算法,每次排序都可以选出一个最小值,k次排序就可以获得k个最小距离.虽然这两种算法的时间复杂度只有O(kn),但是它们却无法并行执行,因为每次排序都要依赖前面元素的排序结果.因此,冒泡排序算法和选择排序算法都不适合CUDA平台.
本节提出了一个基于k次最小值查找的最近邻选择方法,适合GPU的多线程环境,并且是一个基于比较网络的模型,可以在同一时刻执行多个不相关的比较操作.算法定义的一个比较器如图2所示,比较器的输入为两个任意未经过排序的数据,经过比较器之后两个输出被排序,并且上端线路的元素大于或者等于下端线路的元素,一个比较器所执行的时间为一个单位时间,时间复杂度为O(1).

图2 K次最小值查找的比较器
Fig.2 Comparator of K-min search
对于一个测试数据,经过距离计算之后得到它对n个训练数据的距离向量{d0,d1,…dn-2,dn-1},需要从该距离向量中选择出k(k≤n)个最小距离,根据排序网络的比较器需要两个输入,算法将该向量以dn/2处的位置一分为二,然后d0和d0+⎣n/2」(符号⎣」表示向下取整)输入比较器做判断之后得到max{d0,d0+⎣n/2」}和min{d0,d0+⎣n/2」}.与此同时,d1和d1+⎣n/2」做比较得到max{d1,d1+⎣n/2」}和min{d1,d1+⎣n/2」},dn/2之前的一个元素d⎣n/2」-1和d⎣n/2」-1+⎣n/2」比较得到max{d⎣n/2」-1,d⎣n/2」-1+⎣n/2」}和min{d⎣n/2」-1,d⎣n/2」-1+⎣n/2」},当n为奇数时,最后一个数dn-1无须经过比较自动进入下一轮迭代.这些两两元素之间的比较是互不相关的,符合CUDA并行执行的特性.在经过第一轮比较器之后会产生两个子向量l1和l2,如果n为偶数,则向量如下所示:
l1={max{d0,d0+⎣n/2」},max{d1,d1+⎣n/2」},…
max{d⎣n/2」-1,d⎣n/2」-1+⎣n/2」}}
(3)
l2={min{d0,d0+⎣n/2」},min{d1,d1+⎣n/2」},…
min{d⎣n/2」-1,d⎣n/2」-1+⎣n/2」}}
(4)
如果n为奇数,则子向量l2为:
l2={min{d0,d0+⎣n/2」},min{d1,d1+⎣n/2」},…,
min{d⎣n/2」-1,d⎣n/2」-1+⎣n/2」},min{dn-1}}
(5)
产生两个子向量l1和l2需要经过「n/2⎤(符号「⎤表示向上取整)次比较器的使用,在CUDA中这「n/2⎤次比较可以同时执行,对于要寻找到本轮迭代中的最小值来说,它必定存在于子向量l2中,循环迭代上一步的过程,继续将向量l2一分为二输入比较器,直至l2中只存在一个元素时结束迭代,此时最后的这个元素就是本轮迭代中得到的最小值.经过上述的第一轮最小值选择操作之后,距离向量变为{e0,e1,…en-2,en-1},并且en-1这个元素是该向量中的最小值,也是算法选择出的第一个最近邻元素,然后继续对{e0,e1,…en-2}向量做如上操作,就能得到第二个最近邻元素.经过k次最小值查找之后,就可以查找出初始距离向量中的k个最近邻元素,由于每轮迭代中可以在CUDA中开启多线程并行查找,将原本时间复杂度为O(n)的比较阶段降为O(1),所以一次最小值查找的时间复杂度就等于迭代次数O(「log2n⎤),那么整体k次最小值查找的时间复杂度就是O(k「log2n⎤),相比于其它排序算法拥有更低的时间复杂度.
综上所述,基于k次最小值查找的最近邻选择算法的详细步骤如下:
1)将全局存储器中的m*n的距离矩阵拷贝至共享内存.
2)当n的值小于1024时,在CUDA中开启m个线程块,每一个线程块负责一个测试数据点距离向量的排序,每个线程块内部分配「n/2⎤个线程,每个线程负责两个对应位置上数据的比较器选择,留下值较小的数据并更新到共享内存上.
3)每一轮迭代通过syncthreads()函数同步块内的所有线程,同步完成之后继续对子向量l2进行比较器选择,在完成O(「log2n⎤)次迭代之后,每个线程块零号线程对应位置上的共享内存存储的数据就是本轮最小值.
4)经过k次选择就得到属于该测试数据的k个最近邻.
当n的值较大时,由于CUDA架构的硬件限制,则每个向量需要使用「n/1024⎤个线程块负责计算,通过找出这些线程块输出数据中的最小值从而得到最近邻数据.
3.3 基于双调排序的最近邻选择
通知分析可知:基于k次最小值查找的最近邻选择算法,当k值比较大时,经过k次查找所需要的时间也越大.从时间复杂度上分析,如果k值接近于训练集数据量n时,该方法的时间复杂度就变为O(nlogn),与快速排序的时间复杂度相同,相当于将距离向量完全排序,因此它不适应k值较大的情况.本节介绍了一种基于CUDA的双调排序算法,它同样能够利用多线程特性来并行执行,适合于k值比较大的排序场合.
本算法定义一个序列s=(a0,a1,…,an-1),如果满足条件a0≤a1≤…≤an/2-1并且an/2≥an/2+1≥…≥an-1,那么称序列s就是一个双调序列.算法将任意一个长度为n(n为偶数)的双调序列s分为相等长度的两段s1和s2,将s1中的元素和s2中的元素一一比较,即a[i]和a[i+n/2](i 经过距离计算得到的m*n的距离矩阵,使用基于双调排序的最近邻选择算法的详细步骤如下: 1)对于每一个测试数据对应的距离向量l,其长度为n,算法中双调排序输入的序列长度为2a(a>0),当n的大小不足2a时,补足最少个数的元素使n=2a,补足的元素统一为能够表示的最大数. 2)将数据拷贝至共享内存,同时开启若干个线程块负责距离序列的双调排序,块内总共进行a轮迭代,前a-1轮进行相邻两个单调性相反的序列合并,并分别按相反单调性递归进行双调排序. 3)第a轮时合并前面两个长度为n/2的单调序列,开启n/2个线程做两两元素的比较,按此方式迭代a轮,每轮都会开启n/2个线程参与计算,直至最后一轮迭代时是长度为2的序列相比较,即可得出最后单调递增的距离序列. 图3 构建双调序列示意图Fig.3 Diagram of a bitonic sequence 基于双调排序的最近邻选择算法的时间复杂度为O((logn)2),所以当k较大时,该方法的时间复杂度是优于基于k次最小值查找的最近邻选择算法. 基于CUDA的决定分类标号的具体步骤如下:在CUDA中开启m个线程块,每个线程块负责一个测试数据分类标号的统计,在共享内存上开辟一个数组,数组长度为训练数据集的类别个数.块内开启k个线程,每个线程统计自己对应位置上数据的类别标号,采用CUDA内部的原子加法操作统计,即atomicAdd()操作,在类别数组上取数据并执行加法操作.最后同步线程块内线程,得到最终记录数组,数组当中数字最大的类别即为该测试集最终的分类. 综合前面各节所述,GS_KNN算法的详细步骤如算法2所示,算法流程如图4所示. 图4 GS_KNN算法流程图Fig.4 Flow chart of GS_KNN algorithm 算法2.基于CUDA的GS_KNN算法 输入:m个点的测试数据集,n个点的训练数据集,以及最近邻个数k. 输出:m个测试数据的分类结果 1)在CPU主机端初始化测试数据集,训练数据集和最近邻个数k的内存空间. 2)在GPU设备端分配测试数据集,训练数据集以及最近邻个数k的内存空间. 3)将主机端数据拷贝至设备端. 4)利用CUDA调用基于Cublas通用矩阵乘的距离计算内核函数,得到所有测试数据集数据到训练数据集的距离矩阵. 5)随机抽取一个测试数据的距离向量,分别进行基于k次最小值查找和基于双调排序的最近邻选择排序算法的实验,得到时间T1和T2. 6)如果T1小于T2,则选择基于k次最小值查找的最近邻选择算法,进行距离排序.否则,选择基于双调排序的最近邻选择算法来排序. 7)进行基于CUDA的决定分类标号,得到每个测试数据的分类结果. 8)将最后的分类结果从GPU设备端返回拷贝至CPU主机端并输出. 本文所使用的实验平台为Intel Core i5-4590 CPU,主频3.30GHz,内存8GB,GPU为NVIDIA GTX750 Ti,计算能力为5.0,拥有5个流多处理器,640个SP.软件环境为Windows 10,Visual studio 2010和CUDA7.0. 本文实验所使用的第一个数据集为程序生成的模拟数据,可以指定测试集大小、训练集大小、每个样本的类别以及它的属性维度.第二个数据集为KDDCUP1999提供的网络入侵检测数据集,该数据集包含大量真实的网络入侵数据,数据集中每个元素包含41个维度的属性,每个维度属性为浮点类型的数据,总共有24种攻击类型.由于每个维度上的度量单位不同,需要对输入数据进行标准化和归一化,本文使用Wang等[15]的方法进行数据的预处理. 4.2.1 固定m,k,改变n,d对加速的影响 本实验采用模拟数据,设定测试集的大小m为1200,训练集n的大小为210到215,这样可以方便线程的访问,测试集与训练集的维度d相同,k的值设为25.由于k值较小,所以经过评估后算法采用基于k次最小值查找的最近邻选择.选择了两种算法来与GS_KNN算法作对比.第一种算法选用了基于CPU的超快近似最近邻搜索算法库,即ANN-C++[16],另一种选用了BF-CUDA算法.改变n和d的大小,实验结果如表1所示,可以看出GS_KNN算法在相同数据集上的性能上要优于ANN-C++算法和BF-CUDA算法,并且随着训练集大小和维度的增加,GS_KNN算法相较于这两个算法的加速比也越来越高,当n等于215,d等于256时,GS_KNN算法相对于ANN-C++算法的加速比为145,相对于BF-CUDA算法的加速比为2.8. 4.2.2 固定m,n,d,改变k对排序的影响 实验(1)是在固定k=25的情况下进行的,为了比较k值的大小对算法距离排序阶段的影响,选取测试数据集大小为1200,测试数据集为16384,数据维度为32,第一次实验中GS_KNN算法的距离排序采用基于k次最小值查找的最近邻选择,第二次采用基于双调排序的最近邻选择,然后每次实验都不断增加k的值,观察记录距离排序阶段的执行时间,实验结果如图5所示,可以看出当k的值为46时,基于双调排序和基于k次最小值查找的距离排序所用时间相同,当k的值小于46时,k次最小值查找所需的时间要少于双调排序.随着k的不断增加,双调排序所花费的时间不变,因为不管k值如何变化,算法都会得到一个完整的排序结果,而k次最小值查找的时间开销呈线性增长趋势,因为算法的迭代次数会随着k的增加而线性增加,此时双调排序的优势会越来越明显. 表1 改变n和d时各算法运行时间比较(单位:s)Table 1 Comparison of running time of each algorithm when changing n and d (unit:s) 图5 改变k对距离排序时间的影响Fig.5 Effect of changing k on distance sorting time 4.2.3 算法准确性验证 从KDDCUP99数据集中选取5000条数据,其中4900条正常数据,100条包含攻击的入侵数据作为训练集,再选500条包含正常数据以及训练集中未知的入侵数据集作为测试集,分别运用经典的基于CPU的K最近邻入侵检测算法和GS_KNN算法,进行10次实验取检测率和误报率的平均值,每次调整k值的大小,统计结果如表2所示. 表2 入侵检测鲁棒性检测结果Table 2 Intrusion detection robustness test results 从结果来看,GS_KNN算法在检测4类攻击上与标准CPU版本的K最近邻算法相比,检测率和误报率几乎相同.造成略微差异的主要是由于在距离排序阶段,离测试数据距离完全相等而类别标号不同的训练数据被k的不同切分所导致. 本文在经典串行KNN算法的基础上,利用GPU的并行计算能力,提出了一种基于CUDA的并行KNN算法,即GS_KNN算法,该算法能有效处理大规模数据情况下的数据分类问题.算法利用矩阵乘的思想加速了距离矩阵的运算,提出基于k次最小值查找和双调排序两种策略优化距离排序,并在CUDA中完成分类标号的统计.它与经典的BF-CUDA算法相比获得2.8倍的加速比.然而本文在GPU和CPU之间的数据传输以及多GPU协同合作还有待研究,因此下一步尽可能优化数据的存储,利用GPU集群提升算法的性能.
3.4 基于CUDA的决定分类标号
3.5 GS_KNN算法的详细步骤

4 实验与分析
4.1 实验环境
4.2 实验结果

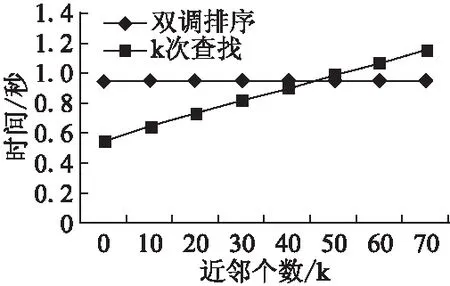
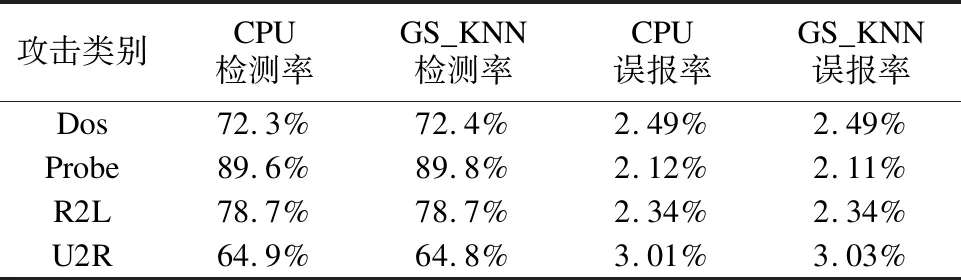
5 结 论
