基于Web的地形匹配系统设计与开发
2019-05-27宋敦江2
高 香,宋敦江2,梅 新
(1.湖北大学 资源环境学院,武汉 430061; 2.中国科学院科技战略咨询研究院,北京 100190)
0 引言
地理信息系统 (GIS,geographic information system),遥感(RS,remote sensing)以地理信息资源和测绘数据等为基础数据[1],包括大量的航空航天图片,遥感影像, 地形图以及各尺度的DEM(digital elevation model)数据。这些地理信息基础数据具有与其它数据不同的特性,拓扑关系强,具有自相关性,而且数据量庞大,计算复杂,处理困难。国内外学者将机器学习(Machine Learning)和深度学习算法应用于各领域大数据处理、分析,获取有用信息[2]。例如运用图像模式识别来进行大数据挖掘,构建大数据智能地质学[3]。
图像匹配技术是图像处理、分析的重要内容,其结果的精度与可靠性直接决定了后续工作能否正常进行。图像匹配它是根据目标的特殊特征,按一定相似性准则,建立未知图像与已知图像之间的匹配[4]。随着社会信息化程度逐渐提高,计算机存储和计算能力大幅度提升,深度学习技术和方法在飞速发展,图像匹配技术也趋于成熟,图像匹配是几乎所有图像分析过程中的关键组成部分。图像匹配成功应用于例如导航、指导,自动监视,计算机视觉、绘图科学、无人驾驶、医学诊断交通监控等领域[5]。
地形匹配是图像匹配的一种,在远程巡航导弹导航、潜水器导航,飞机航行跟随、地形回避,模式识别,地理定位,目标跟踪等领域具有十分重要的作用[6-7]。地形匹配制导自主、可靠、不受干扰、导航精度与航程无关,无需在导航区域建立信号中继站等基础设施,它不受气象条件和其他电子设备干扰等的影响,是GPS导航的一种有效辅助手段[8]。
地形匹配是利用已知地形数据,从基准图中提取具有不变特征或明显特征的子区,或者用已知地面控制点作为模板,在所匹配的图中搜索与模板相似的区域。当两个地图的匹配相似性测度达到最大,且超过预先规定的阈值时,判定为找到了正确的匹配位置[9]。在地形匹配过程中,基准地形(假定称为A)是全国或全球地形,待匹配地形(假定称为T)是任意一块具有明显地形特征的地形,地形匹配就是要在A中进行搜索或进行特征匹配,确定T在A中的位置,包括中心点坐标和边角拐点坐标。与地形匹配相关研究一般运用三维表面匹配算法、计算机视觉技术[10]来确定基准地形A内恢复待匹配图形T的位置和方向。但到目前为止却很少有基于深度学习来进行地形匹配的相关研究。
尽管图像匹配技术发展快速,地形匹配相关研究也很多,但运用深度学习进行地形匹配相关研究却很少。将地形匹配数据,相关匹配算法进行系统集成可以使地形匹配流程系统化,能够对地形图进行快速匹配、更新。但由于地形数据数据量大,计算复杂,不能仅依赖于 CPU的计算,CPU+GPU 的硬件框架更能满足实际需求,由于GPU服务器租用昂贵,从经济因素与算法安全性因素出发,本文尝试GPU服务器和WEB服务器分离相互独立的做法。本文研究基于Java开发的地形匹配Web系统,运用当今互联网、云计算等技术优势搭建的分布式在线处理系统,解决了本地系统或局域网环境系统下的专业模型或处理算法在互联网上的应用,提供了更广泛的共享[11]。同时,该架构采用了消息调度概念及应用模式,对地形匹配算法进行了封装,复用了已有的地形匹配算法,开发效率大大提高。该系统托管在阿里云服务器中,它通过消息传递机制与另外一台GPU服务器进行通信,实现GPU地形匹配计算与地图网站的功能分离,增加了系统的可扩展性,方便进一步的升级。
1 地形匹配服务的架构设计
已有全国地形数据A(30米分辨率的DEM),对现有区域的地形等高线(数据A)(contourA.shp),任意切割一个方形区域得到子集等高线数据B,对数据B进行平移和旋转得到数据C,对数据C随机加入噪音得到数据T(contourT.shp)。地形匹配服务目标实现上传数据T,恢复或匹配、查找后确定数据T在数据A原始位置,并反馈匹配结果。考虑算法的复用性,以及进一步的改进与升级,地形匹配服务在架构设计时,采用基于“消息/订阅”模式的消息调度模式[12],对地形算法库进行了封装,将网站平台模块,消息队列传递模块等与地形匹配算法进行分离,相互独立运行工作,通过消息队列服务器建立网站与算法之间的通信,构建了地形匹配服务体系。如图1所示。
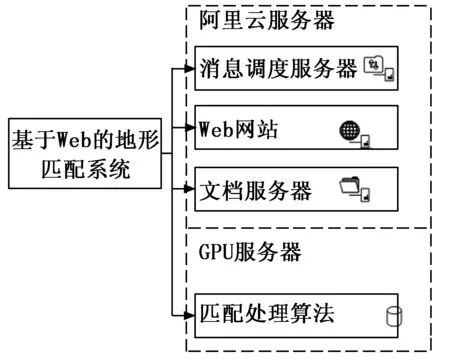
图1 地形匹配服务架构体系
如图1所示,地形匹配系统整个服务架构体系分为Web网站、消息调度服务器、文档服务器、匹配处理服务四部分,其中Web网站、消息调度服务器、文档服务器部署于阿里云服务器中,匹配处理算法部署于局域网环境。其中Web网站负责整个系统的前端的显示以及交互操作,消息调度服务器、文档服务器负责门户网站与地形匹配算法服务的沟通,匹配算法部分负责地形匹配运算。整个系统采取松耦合的模式,彼此之间保持相对独立性。
Web网站模块主要是网页部分,负责为用户提供系统应用界面,用户通过操作Web网站输入待匹配地形图片,执行匹配命令,网站获取地形匹配信息,发起执行操作,最后接收匹配处理后结果,并储存到Web网站数据库中。
消息调度服务和文档服务器模块负责门户网站与地形匹配算法服务的沟通。消息队列调度服务[13]可以简单的理解为系统各部分之间建立联系的“桥梁”,它通过队列的方式实现各模块之间的消息传递,属于系统的中间组件,它将数据与计算进行分离,确保了数据的独立性,提高了算法的重用性,便于后期算法的完善。文档服务器提供了消息监听机制,后台匹配处理接收消息调度服务器发送的处理请求,进行数据从阿里云文档服务器上下载。
匹配处理服务模块主要负责地形匹配算法的实现,匹配处理后台需要集成消息队列接收处理消息,包括文件名和数据库此数据的id号。通过FTP服务器(File Transfer Protocol Server)下载对应save_name的数据,执行匹配处理,然后通过Web网站API将数据结果及状态写入到数据库表中。
2 地形匹配系统的实现
2.1 软件环境搭建
网站部分通过Java 体系开发,采用 Play框架, 消息队列采用Rabbitmq服务器,后台空间匹配采用Python开发语言。考虑系统的安全性以及算法的重要性,消息调度服务器,Web网站和FTP服务器部署在阿里云上,后台匹配算法部署在局域网内。系统实现流程图如图2所示。

图2 系统实现流程图
如图2所示,在阿里云CPU环境中安装系统依赖软件,并搭建Web网站,配置相关环境,在本地GPU环境中进行地形匹配算法的训练,以及地形匹配算法封装及应用,并配置相关环境。系统相关依赖软件如表1所示。
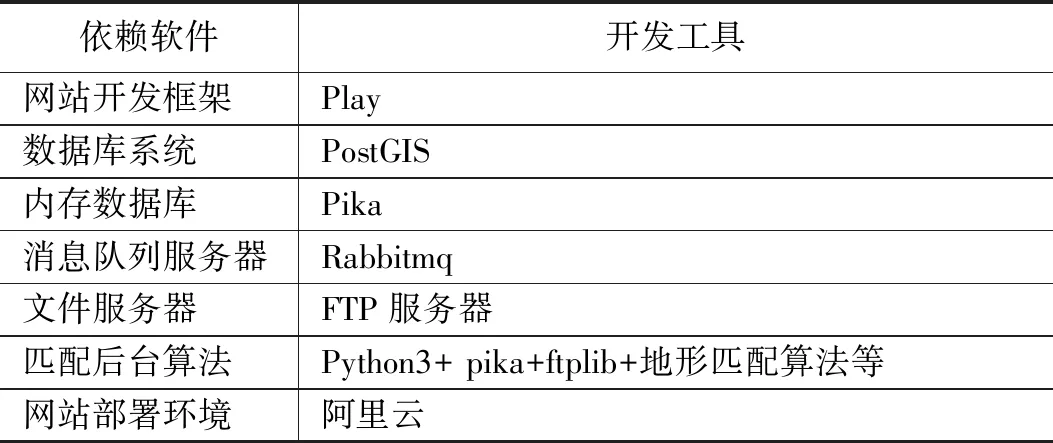
表1 系统开发平台工具
如表1所示,系统开发网站选择了play开发框架、 Postgis数据库、Pika内存数据库、Rabbitmq消息队列服务器、FTP服务器、后台算法地形匹配算法使用python3语言开发、网站部署在阿里云环境中。
Play框架(http://www.playframework.com/),它是开源Web框架,相比于其他框架,灵活性高,具有热重载(hot reload)[14]特性,修改代码,可直接刷新页面显示效果,无需重新构建,使用Play框架开发,可以快速搭建网站,大大提高了系统的开发效率。
PostGIS数据库是对象关系型数据库系统 PostgreSQL(https://www.postgresql.org/) 的一个扩展,能够有效的对空间数据进行管理与处理,地形数据属于空间数据的一种,为了便于存储空间数据的空间位置、空间关系,选用了PostGIS数据库。
Rabbitmq(http://www.rabbitmq.com/)是开源消息传递中间组件,可在多平台,多操作系统中运行,具有可靠性,使消息和消息队列具有可恢复性,消息队列调度服务机制进行数据的传递,将数据与后台算法进行分离,确保了数据的独立性,提高了算法的重用性[15]。
Ftp服务是通过Internet利用FTP服务器和FTP客户机实现的是一种高效可靠的文件传输服务,客户端进行FTP会话,服务器与客户端之间连接建立双向的传输文件的连接,实现计算机与计算机之间实现相互通讯[16]。此系统在阿里云上配置了FTP服务器,建立了后台匹配处理与前端网站间的数据传输机制,后台匹配平台接收消息调度服务器发送的处理请求,连接到在阿里云主机上的FTP服务器程序进行数据的下载。匹配处理后将处理后的结果返回给前端网站。
Pika是类似于Redis的一款开源的存储系统,它的优势在于Pika 是多线程的结构,因此在线程数比较多的情况下,某些数据结构的性能可以优于 Redis,由于系统需要储存的为全国范围内的地形图,数据量较大,若选择Redis会因内存过大恢复时间长,而Pika正好解决了用户使用Redis内存过大恢复时间长的问题。
匹配后台算法采用Python开发语言,利用深度学习算法对全国地形数据进行训练,之后模糊匹配,再利用机器视觉方法进行精确定位。pika,ftplib是python的内置的标准模块,Pika包进行消息接收,ftplib包提供了强大的对FTP服务器的操作,通过它连接并操作FTP服务端使用。
地形匹配系统中消息调度服务器,Web网站和FTP服务器部署在阿里云(https://www.aliyun.com/?utm_content=se_1000301881)上,后台匹配算法部署在局域网内,具体配置如图3所示。
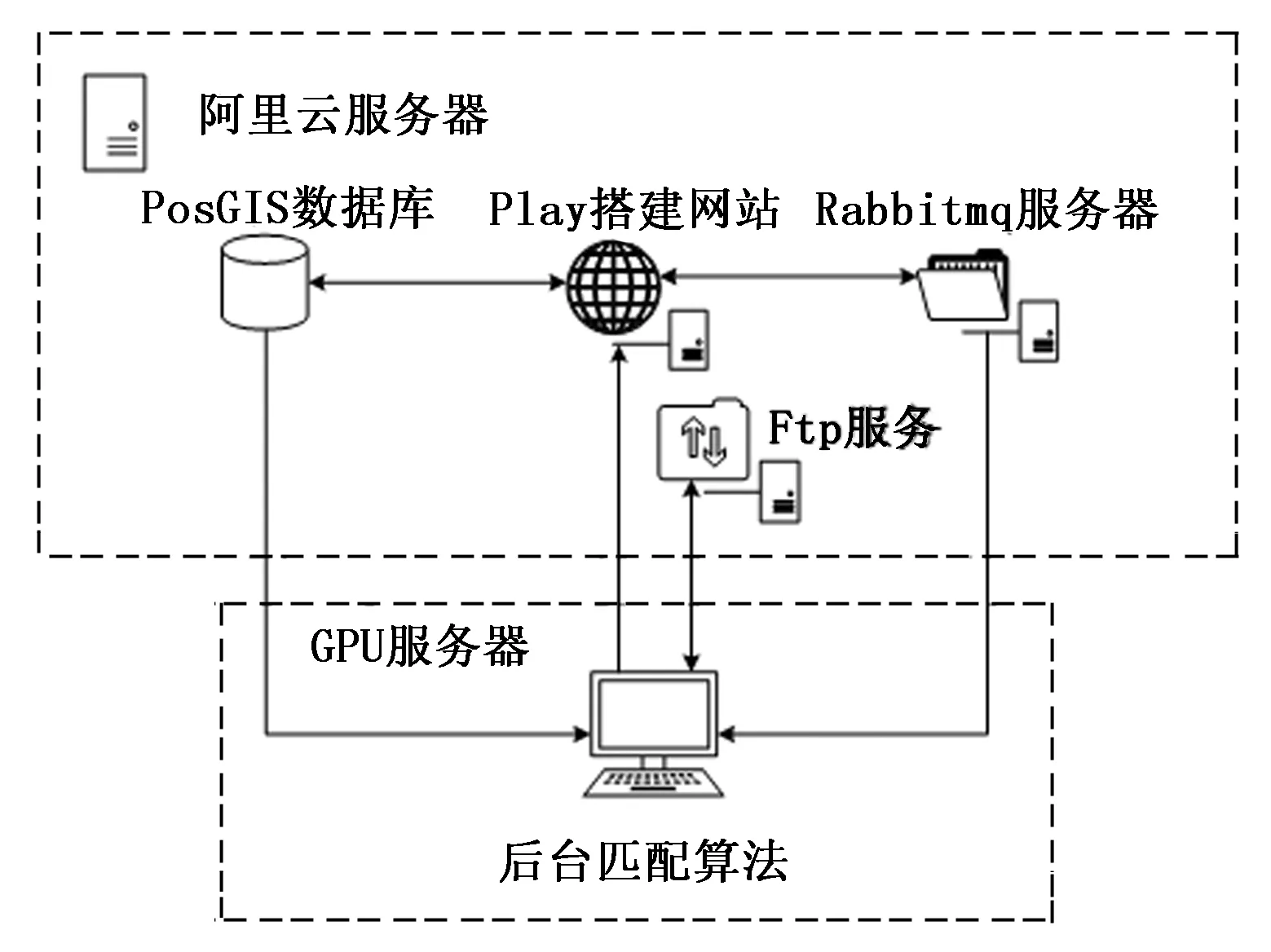
图3 系统部署图
如图3所示,地形匹配系统Web网站部署在阿里云上,远程登录阿里云服务器,进行PostGIS数据库、消息队列服务器 Rabbitmq、文件服务器 FTP服务等依赖软件的安装。并运用Play框架搭建网站,修改配置文件application.conf进行相关服务配置。修改配置信息如下所示:
file_path=["C:zkydataimg"]
save_file_path=["C:zkydataimg"]
mq = ["47.105.32.162"]
file_path为输入文件路径,save_file_path为保存文件路径 mq为阿里云公网IP地址。然后构建消息队列服务,新建队列(queue),命名为web_pro1,全国地形数据A存放于PostGIS数据库中。
接着进行匹配算法运行环境的搭建,在后台匹配算法中进行Rabbitmq环境配置,在匹配算法中输入消息队列登录名称,以及登陆密码和Rabbitmq服务器配置网站url,并进行FTP环境的配置,使后台匹配算法能够获取消息队列message信息,需包括网站url,获取时间以及文件名称。
2.2 地形匹配算法封装
系统地形匹配的目标是实现输入任意变换后的地形数据T执行匹配命令,匹配后得到T在全国地形数据A的具体位置。
地形匹配过程分成两个子过程:
1)第一个子过程是先对总图A用深度学习的残差网络模型(ResNet)进行训练学习,再进行模糊匹配,找出子图T在A中的大概位置T’;
2)第二个子过程是利用计算机视觉OpenCV里的尺度不变特征变换(Scale-invariant feature transform,SIFT)方法对T进行精确定位,精确确定T与T’的相对位置。匹配结果示意图如图4所示。

图4 匹配结果示意图
如图4中所示T1、T2待匹配地形图为数据总图变换后的子图。P为T1、T2重叠部分,A、P为未重叠部分。
为了便于算法后期的完善和升级,提高算法的复用性,我们对地形匹配算法进行了封装。匹配算法通过集成消息队列接收消息体名称和队列名称,获取处理请求,得到文件名和数据库此数据的id号。通过FTP服务器下载对应save_name的数据,执行匹配处理,形成标准算法库。并将处理后的结果通过Web网站API将数据结果及状态写入到数据库表中。
算法库的封装,实现了后台算法与前端网站的分离,后台匹配算法只负责算法方面的开发,前端网站只需通过消息调度机制与后台算法建立联系,提高了匹配系统的效率,以及系统的复用性。
2.3 地形匹配系统页面设计
地形匹配系统页面设计遵循简洁,醒目的原则,主要包括导航栏模块,地图显示模块,地形图片输入模块,以及执行处理模块。如图5所示。

图5 页面设计图
如图5,页面右侧模块设计用户输入待匹配地形图,左侧设计执行匹配命令按钮,并显示匹配信息,中间模块显示地图,并显示匹配成功结果。
2.4 地形匹配结果输出
地形数据经过地形匹配算法匹配后,数据的输出形式为匹配地形图在参考全国地形数据A上的坐标信息,即四个顶点的经纬度信息,并将坐标信息通过Web数据接口传送给前端网页,并显示在前端网页地图中。
2.5 地形匹配处理流程
整个体系系统统分Web网站建设、消息调度服务、后台匹配处理服务三部分。消息调度服务器,Web网站和FTP服务器在阿里云上部署。空间算法部署在局域网内,用户通过操作Web网站浏览器页面输入待匹配的地形图,执行匹配命令,消息调度机制通过接收Web网站信息将处理请求发送给后台匹配处理,匹配处理后台集成消息队列包括文件名和数据库此数据的id号接收处理消息,然后通过FTP服务器下载阿里云环境中PostGIS数据库中对save_name的数据,执行匹配处理,处理完成后,然后通过Web网站API将数据结果及状态写入到数据库表中并在Web浏览器页面中展示。具体过程如图6所示。
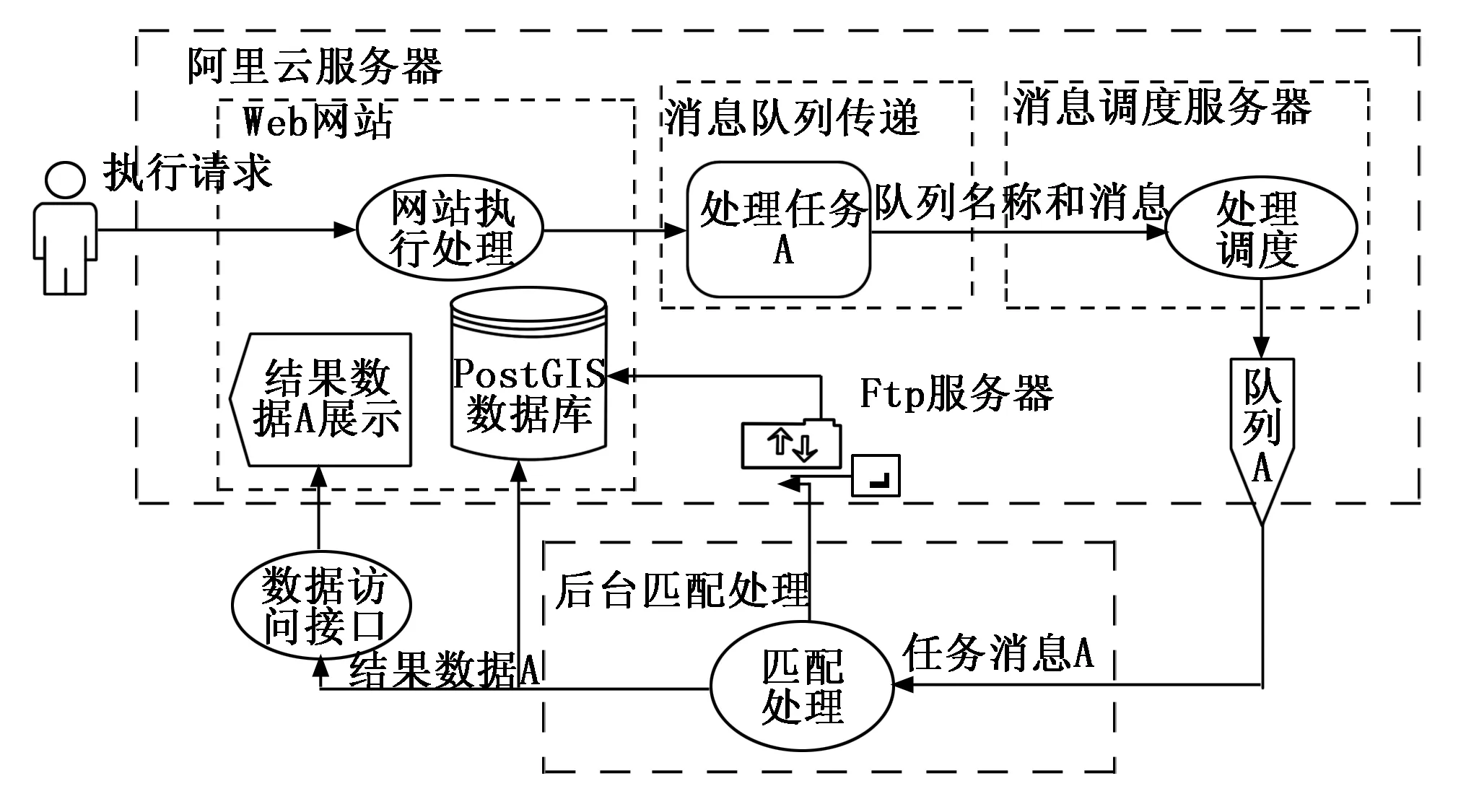
图6 系统流程图
3 应用实例分析
3.1 实验步骤和方法
在实际应用中,构建了基于Web的地形匹配系统,浏览器页面由导航栏,执行处理命令部分,地图部分,上传待匹配地形图四部分组成,用户通过操作浏览器在页面右侧上传待匹配地形数据,上传成功后,点击页面左侧执行命令,通过消息调度服务,后台匹配算法进行处理,将执行结果在浏览器地图上显示,如图 7所示。

图7 匹配成功结果截图
图7中绿色虚线位置即为待匹配地形图T所在位置。
在地形匹配系统主要实现过程分为:1)样本数据制作;2)地形匹配算法模型训练;3)地形匹配算法模型应用。本文重点在于训练好的地形匹配模型的应用。
在全国地形数据A中随机提取一方形区域T(300行*300列),并对数据进行旋转得到37个样本数据,其中包括18个副本数据,随机提取160 000批数据,得到实验数据T约为600万个样本数据。
以600万个样本数据作为训练样本,利用深度学习的残差网络模型(ResNet50)进行训练,进行模糊匹配,随机选取2 000个样本数据作为测试样本测试精度,每个训练样本返回10张地形图,利用计算机视觉OpenCV里的尺度不变特征变换方法对T进行精确定位,利用ResNet50训练模型,匹配结果精度达到97%。
将训练好的模型进行封装,应用到地形匹配系统中。在阿里云CPU环境中,搭建Web网站环境,配置消息队列服务环境、FTP服务器,以及安装数据库系统等软件。在本地GPU环境部署匹配算法运行环境。首先远程登录阿里云服务器,进行PostGIS数据库、消息队列服务器 Rabbitmq、文件服务器 FTP服务等依赖软件的安装。并通过Java 体系进行Web网站的搭建,然后构建消息队列服务,新建队列(queue),命名为web_pro1,然后将全国地形数据A存放于PostGIS数据库中,之后将封装好的匹配算法匹配算法部署在本地GPU环境部署中,在匹配算法中进行Rabbitmq环境配置,在匹配算法中输入消息队列登录名称,以及登陆密码和Rabbitmq服务器配置网站url,并进行FTP环境的配置,使后台匹配算法能够获取消息队列message信息,需包括网站url,获取时间以及文件名称。
在Web网站中点击上传图片或直接拖拽,将实验数据T导入到网页中,点击网页左侧执行匹配按钮,通过消息队列将待匹配信息传送到后台,匹配处理后台需要集成消息队列接收处理消息,包括文件名和数据库此数据的id号。通过FTP服务器下载对应save_name的数据,执行匹配处理,计算待匹配地形图在参考全国地形数据A上的坐标信息,即四个顶点的经纬度信息,然后通过Web网站API将数据结果及状态写入到数据库表中,并将坐标信息通过Web数据接口传送给前端网页,并显示在前端网页地图中。
基于Web的地形匹配系统采用了消息调度概念及应用模式,对地形匹配算法进行了封装,复用了已有的地形匹配算法,实现GPU地形匹配计算与地图网站的功能分离,增加了系统的可扩展性,方便进一步的升级。
但系统同时存在不足,例如地形匹配过程中上传地形数据必须和数据库中全国地形数据A同一比例尺才能进行匹配。
3.2 实验数据基础
系统匹配数据为全国地形数据A(30米分辨率的DEM ),共计约1000块,每块空间范围为108 km*108 km(3 600行*3 600列),存放在postgis数据库中。
待匹配实验数据T由Web网站输入,是从全国地形数据A随机提取一方形区域T(300行*300列)得到数据B,数据B经过旋转、平移等得到实验数据T。
4 总结及展望
文章研究构建了基于Web的地形匹配系统, 对匹配算法进行了封装,Web网站通过消息调度服务器建立于后台匹配之间的信息传递与沟通,三部分分工合作,极大的提高了系统开发效率,匹配算法基于深度学习的地形匹配(Deep Learning-based Terrain Matching, DLTM),匹配样本来自于数据集任意一块旋转,变换,加噪后的子集。相比于其他地形匹配研究,文章有如下优点:
1)文章将机器学习运用于地形匹配算法之中,并对算法进行了封装,可直接调用。
2)文章将地形匹配数据,相关匹配算法进行系统集成,使地形匹配流程系统化,能够对地形图进行快速匹配、更新。
3)文章将GPU地形匹配计算与地图网站的功能分离,将消息调度服务器,Web网站和Ftp服务器部署在阿里云服务器,匹配处理算法部署于局域网环境内本地GPU服务器中,极大的降低了租用GPU服务器的成本,同时确保了数据的独立性,提高了算法的重用性,便于后期算法的完善。
但文章中地形匹配算法无法应用于不同尺度地形数据的相互匹配和多分辨率的地形匹配。今后将对不同尺度地形数据的相互匹配、解决多分辨率的地形匹配、基于切割等高线方法的地形匹配、基于地学信息图谱的地形分类、辅助地形匹配、全球影像的自动定位等问题进行研究。
