IEEE 802.11 DCF机制下的异构网络业务分析模型*
2019-05-20张朝柱黄文钰尹冬梅
张朝柱,黄文钰,尹冬梅
(哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001)
IEEE 802.11[1,2]系列标准协议作为无线局域网、无线自组网等领域应用最广泛的无线网络协议,能够快速通过相对简单的本地网络配置,实现包括不限于家庭、办公场所以及公共场所的无线网络的接入与共享.其中,DCF(distributed coordination function)机制得益于其全面的分布式设计以及实现的简便性与资源共享的公平性,使之成为IEEE 802.11协议最基本的信道接入方式.因此,对DCF机制进行合理的、准确的建模,成为当前计算机与通信领域的热点话题之一[3-22].
2000年Bianchi[4]首次提出利用二维稳态Markov链路模型对IEEE 802.11 DCF机制进行建模,通过对该稳态模型的求解,可以求出任意时隙的发送概率和失败概率,从而导出饱和模型的性能,并由此引发对DCF机制建模大量的深入研究.但作者假设的信道是无错的理想信道,模型中节点总处于饱和工作状态,即任意时刻都存在数据包等待发送,重传次数无限制,以及退避过程是连续的.而这一系列假设往往是不存在的.为了解决这一系列问题,众多学者基于文献[4]对DCF机制进行了深入的研究,提出了各种改进的算法模型来研究协议的吞吐量和传输时延,同时利用新的模型讨论与优化协议的相关部分.Mao等人[5]提出了一种比较全面的饱和Markov模型,考虑了重传限制以及退避冻结.Yang等人[6]提出一种改进的非饱和 Markov模型,但未考虑退避冻结引起的时隙变化等问题.Kosek-Szott等人[7]提出用非饱和Markov模型研究不同的AC(access category)接入类别的增强型分布协调功能EDCA(enhanced distributed channel access)的性能,但在时隙冻结及不饱和概率等问题上考虑不足.文献[8,9]则分别聚焦于采用反向传输机制和采用不同服务优先级下的帧聚合的性能,由于模型相对简化,因此建模不太准确.文献[10,11]进一步完善了非饱和马尔可夫模型,分析了分段分块(packet fragmentation)机制及反向传输机制的DCF机制的性能,但对于传输完成后有无数据包存在于缓存中的概率考虑不够完善.Zhao等人主要讨论了M/G/1[12]排队模型在非饱和场景下的应用,首次详细讨论了缓存大小对DCF性能的影响,同时得出与M/M/1/K模型相比,M/G/1模型能够更准确地分析非饱和工作站点的性能.文献[13,14]利用简单的Markov模型对 EDCA进行了相关的分析与讨论.文献[15,16]则聚焦于对 DCF退避机制进行适当的调整优化,并利用 Markov模型对改进的机制进行建模分析.Chen等人[17]提出了利用信号估计与检测中的理论,利用后验概率进行均值计算求出站点的不饱和概率,同时与通过不完善的非饱和Markov模型求得的不饱和概率进行了均方误差意义下的对比.
在现实场景中,异构网络是最广泛存在的,如不同的业务成分同时接入无线网络其不饱和性是不同的,因此,对异构网络的建模是至关重要的.据我们所知,只有文献[18,19]对异构混合业务成分下的DCF机制进行了建模,其中,Nguyen等人[18]采用均值分析的方法对 DCF机制的性能进行分析评估,但简单的均值分析并不能较好地模拟退避过程中的时隙冻结等问题,因而虽然算法相对简单却并不太准确.Kosek-Szott[19]则利用了 Markov模型对 DCF机制进行了较文献[18]更为准确、合理的建模,但在算法上仍存在不少的不足之处,包括但不限于未考虑传输误码率、未全面考虑最大重传次数的限制、传输概率考虑不够周到以及不饱和性的分析方法复杂且不够准确.为了进一步更为准确、完善地研究IEEE 802.11协议的相关内容,同时为参与IEEE 802.11协议的设计与分析的人员提供一定的参考价值.讨论、分析了协议[1,2]的相关内容,提出了一种较文献[19]更全面的基于Markov模型的异构混合业务下IEEE 802.11 DCF机制的性能分析模型.在模型中,充分考虑到了应用场景中饱和业务与非饱和业务混杂的实际情况,重点考虑了站点的退避冻结和有限重传次数限制问题,同时结合M/G/1排队模型[11],通过对提出的Markov模型进行稳态求解,导出了IEEE 802.11 DCF机制的吞吐量、传输时延及丢包率,同时分析、讨论了缓存对系统性能的影响.
本文第1节对IEEE 802.11 DCF机制进行较为详细的介绍及说明.第2节利用Markov对DCF机制进行合理建模.第3节针对提出的模型给出具体的计算方法与定义.第4节对提出的算法进行仿真分析,同时与近年来国内外相关的优秀算法进行比较.第5节对进行的研究工作及接下来的工作目标进行简要的总结.
1 IEEE 802.11 DCF解析
DCF是一种被 IEEE 802.11标准所采用的分布式介质接入机制,采用了基于载波侦听多路访问/冲突避免(carrier sense multiple access with collision avoidance,简称CSMA/CA)的接入模式.工作原理是:数据传输发起站点通过能量检测(ED)、载波检测(CS)和能量载波混合检测等方式来检测信道的状态,从而进行冲突规避[3].
为了减少数据通信过程中由于碰撞导致的传输失败的几率,DCF机制将 CSMA/CA接入模式与随机退避过程相结合.当站点有数据需要进行传输时,站点需要进行随机退避.在退避过程中每当侦听到信道空闲且空闲时隙满足一个IEEE 802.11协议定义的最小时隙长度slottime时,需要将退避计数器的数值减1;而每次侦听到信道繁忙,需要冻结退避计数器计数状态,若是侦听到一次成功传输时需等待一个分布式协调功能帧间间隔DIFS(DCF inter-frame space)时长或侦听到一次失败传输时则需等待一个扩展帧间间隔 EIFS(extended interframe space)时长,才可以重新进行退避计数.如此反复进行,直到计数器值减至0,才可以发起数据的传输.而每次传输失败后,需进行二进制退避,直至将退避窗口设置为最大;每次传输成功或重传次数达到系统所设置的最大值,需要将退避窗口大小设置为最小.直到站点有新的数据包需要传输时,站点需要重新从最小退避窗口中随机选择退避时隙进行随机退避过程[3].同时,退避时间可表示为
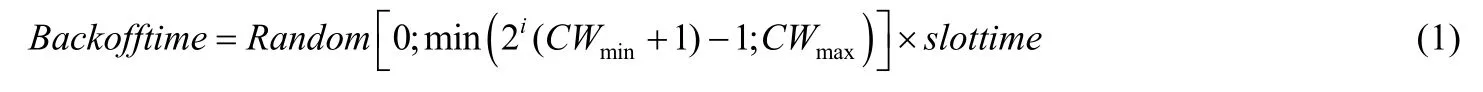
其中,i表示重传次数,CWmin为最小退避窗口值,CWmax为最大退避窗口值.
根据对DCF机制退避过程的有效分析及合理讨论,可以得出Markov链路模型能够充分描述契合DCF机制的退避过程,因此可以利用Markov模型对DCF机制进行准确、合理的建模.同时,为了简化分析过程,在建模过程中采用了6条通用的假设:(1) 同业务模式站点的数据到达率相等且服从相互独立的泊松分布;(2) 不存在无限 buffer,缓存大小是相等的;(3) 只考虑由多普勒频移造成的数据传输错误;(4) 站点的侦听范围和传输范围相同;(5) 系统由一个 AP和多个 station组成,不考虑隐藏终端和暴露终端问题,故而数据传输只需考虑基本模式;(6) 任意站点发起数据通信时发生碰撞冲突的概率,与站点之前所处状态无关.
2 Markov模型分析
定义二维随机变量(s(t),b(t)),s(t)表示当前t时刻计数器所处的退避阶数,b(t)表示当前t时刻计数器的值.根据上一节的分析假设,可以建立一个离散的二维马尔可夫模型用于分析DCF机制的退避过程.如图1所示.
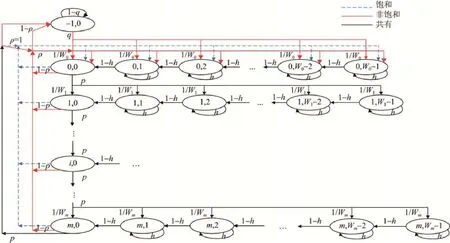
Fig.1 Markov chain model图1 马尔可夫链路模型
定义二维的平稳分布随机过程bi,k=limt→∞P{s(t) =i,b(t) =k},i∈ [- 1 ,0,...,m];k∈ [ 0,1,...,Wi- 1 ],其中,退避阶数i表示由于之前过程中数据传输已经失败了i次,当前处于等待发起第i次重新传输的随机退避阶段;退避计数器值k,为当前第i次重传随机退避过程中的退避计数器所记录的值,m则表示定义的最大重传次数值,m′是一个由最小和最大退避窗口大小所确定的值.其中,Wi可由式(2)确定.
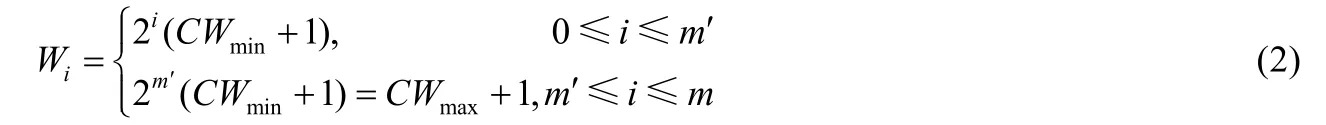
需要指出的是,状态(-1,0)是非饱和工作站点的一个特殊状态:当站点数据传输成功或达到最大重传次数限制而丢包之后,有 1-ρ的几率缓存中不存在数据等待发送,从而在接下来的一个时隙不能进入随机退避过程.同时,在接下来的这一空闲时隙中,存在1-q的概率无数据达到,从而维持这一状态,相反地,存在q的概率进入新的随机退避过程.可以看出,本质上饱和工作模式下的DCF退避过程仅仅是非饱和工作模式下的一种特殊情况.
对于整个Markov模型,根据图1,其一步转移概率可归纳整理为
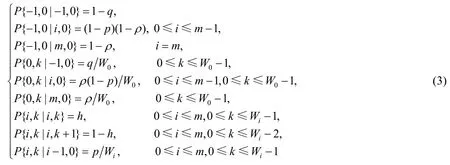
其中,p表示在数据发送的过程中由于数据碰撞或者数据传输错误而引起的传输失败的概率;h是对于一个退避过程中的站点由于其他任意站点发起数据传输而造成其退避计数器冻结的概率.
由定义可知,当时间t→∝时,Markov链服从平稳分布,此时根据图1、式(3)以及稳态过程中流出概率等于流入概率的逻辑关系,可得:
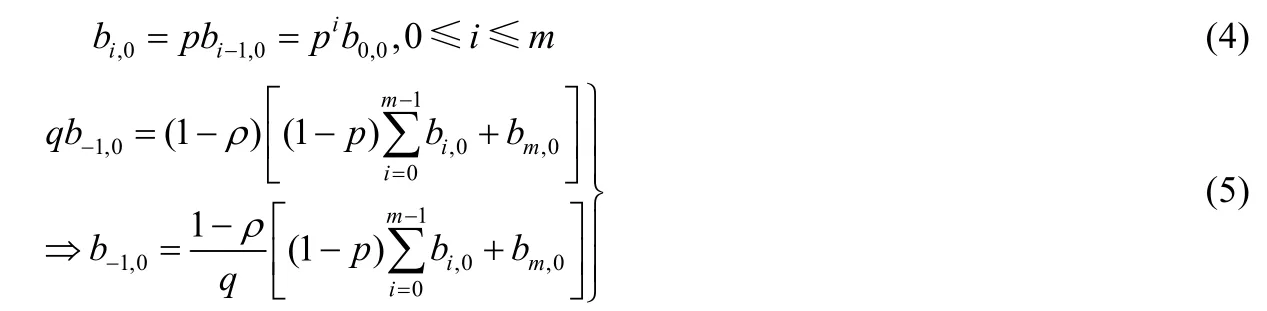
同时,状态(i-1,0)到(i,k)的退避过程可表示为
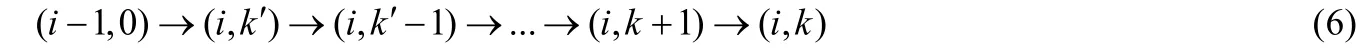
根据式(6)、图1及流出概率等于流入概率,可进一步归纳分析得出二维稳态随机变量bi,k与bi,0的逻辑关系:
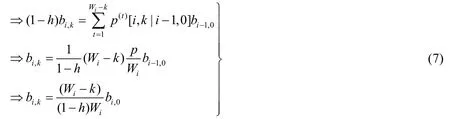
最后,根据Markov过程的归一化条件可知:

联立式(2)、式(4)、式(5)、式(7)以及式(8),可以解出状态b0,0在任意时隙的传输概率为
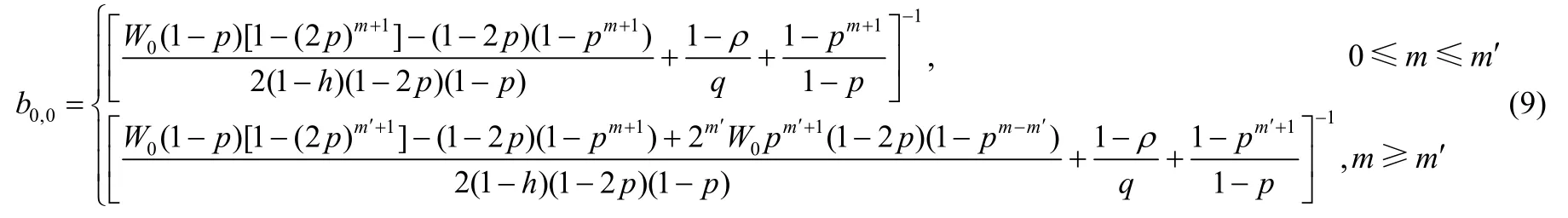
由式(4)、式(9)可归纳出任意工作模式站点在任意时隙有数据传送概率的概率τ:
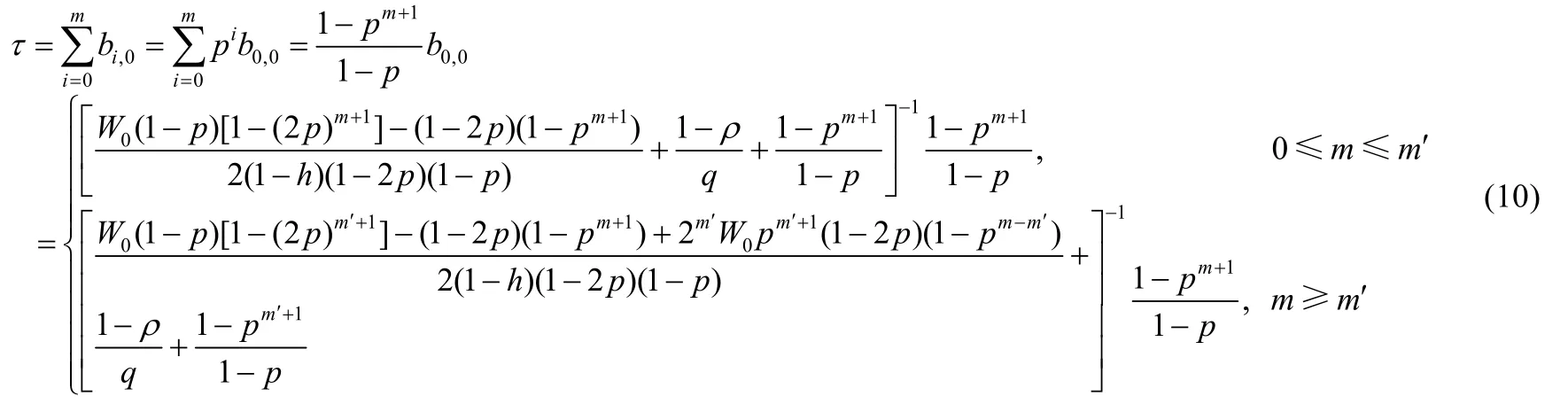
由讨论可知,饱和模式是不饱和模式的一种特殊情况,即随着站点不饱和概率的减少,站点将进入饱和工作模式,因此,此时ρ=1,且q=0.故对于饱和工作模式的站点,其任意时隙有数据传输的概率可以进一步写作:

其中,饱和站点在任意时隙有数据传输的概率为τ′,传输失败概率为p′,退避过程计数器冻结概率为h′.此时,在任意时隙有数据发送概率与Szczypiorski等人[20]提出的饱和算法模型中的数据发送概率是一致的.
3 异构网络成分分析
3.1 异构模型概率分析
假设处于不饱和工作状态的站点数为n,处于饱和工作状态的站点数为n′,则对于指定的站点(非饱和或饱和工作站点),在其退避过程中,由于其他任意站点发送数据而造成退避计数器冻结的概率可以分别归纳为

其中,τ由式(10)确定,τ′由式(11)确定.同时,由文献[11]可知,对于衰落信道,多普勒频移造成的误码率FER及其引起的站点数据传输过程失败的概率pe可分别表示为
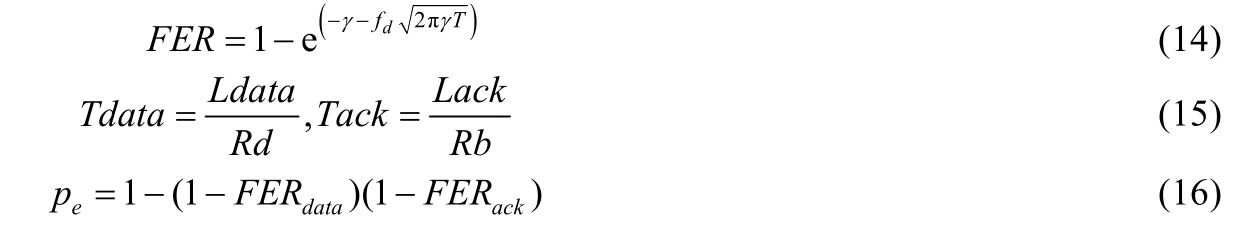
其中,γ是由接收机性能决定的阴影衰落余量,fd是通过移动速度与载波频率计算出的最大多普勒频率,T是由帧的大小及采用的传输速率所确定的帧传输时间.Tdata、Tack是数据帧及ACK(acknowledgment frame)帧分别采用数据传输速率Rd及基础传输速率Rb传输所消耗的时间.因此,站点数据传输失败的概率可分别写作:

在任意时隙,有数据成功传输,可以认为有任意的唯一站点进行数据传输,其他站点都处于退避状态或者(-1,0)状态,且传输过程没有发生帧错误.Ps、Ps′分别表示任意时隙有非饱和或饱和站点发送成功的几率:

对于一个指定的节点(饱和或者非饱和节点),在其退避的过程中,侦听到有任意站点成功传输数据的概率(受饱和节点或者非饱和节点分别是否有数据传输成功影响),故可根据式(19)、式(20)分别归纳为

对于任意时隙,不存在站点进行数据传输的概率可归纳为

一个指定的节点(非饱和节点或饱和节点),在退避过程中,侦听到不存在其他站点发送数据的概率可表示为

3.2 状态(–1,0)有数据包到达的概率
由于(-1,0)时隙极其短暂,能够进入缓存的数据包个数远小于2,结合M/G/1排队模型[12],可以利用文献[12]得出的M/G/1模型中的K=2时的情况对其进行准确、合理的分析,因此,此时有数据到达的概率可以归纳为

其中,λ是指站点的数据包平均达到率,是一个在相当长的时间段内确定的平均值;Eslot是一个仅对非饱和工作状态的站点而言所定义的时间均值,由其他节点的3种工作状态所确定的平均单位时隙的值.对于基础模式有:
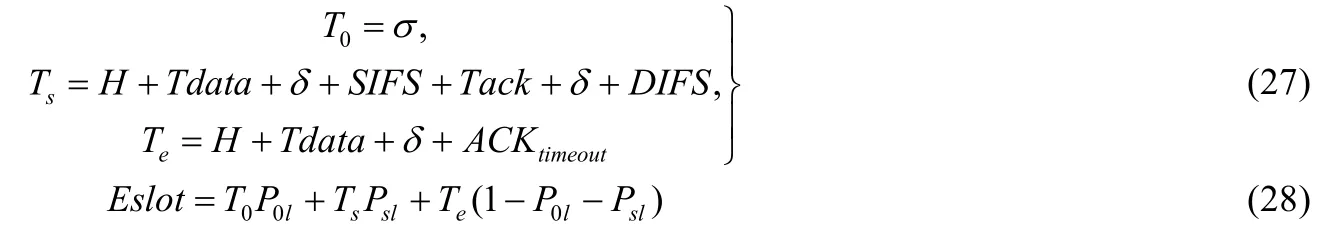
其中,T0、Ts、Te分别表示站点侦听到其他任意节点处于退避状态即无数据传输的空闲时隙大小、侦听到有站点传输且成功所需等待的退避冻结时间、侦听到有站点传输且失败所消耗的退避冻结时间.H是所传输的帧的额外开销,包括PLCP物理帧头以及MAC帧头的开销;σ是IEEE协议定义的一个系统空闲时隙大小;δ表示信息传输过程中的时延;ACKtimeout是由于传输冲突或者传输错误造成的系统等待时间,对于基础模式,两者所需时间相等;SIFS(short inter-frame space)为协议设定的短帧间间隔.
3.3 非饱和站点完成一个周期的数据传输后有数据立即传输的概率
由文献[11]讨论的相关成果可知,站点完成一次数据传输后进入(-1,0)状态的概率为 1-ρ,反之,开始新的随机退避的概率为ρ,有:
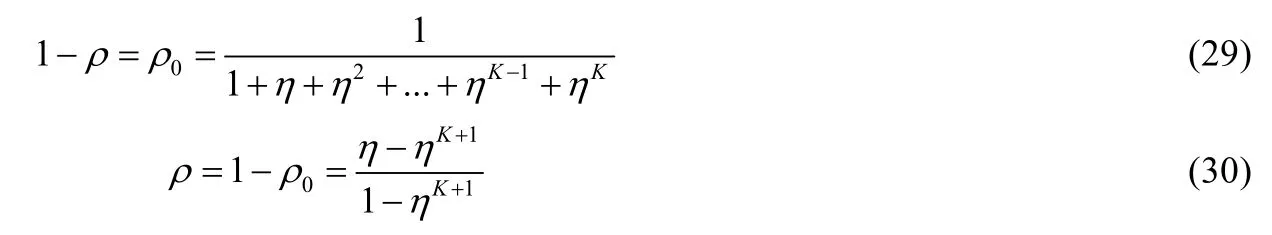
式中,η=λD,D是指一个数据发送周期的平均时长,即数据的平均服务时长,K表示缓存的大小.由图1可知,一个服务周期的平均时长主要由3部分时间构成:成功传输所需的平均时间、成功传输前经历的失败过程所耗的平均时间以及退避过程中所花费的平均时间.同时,由第 1节讨论分析内容可知,在退避过程中一个空闲时隙的等待时长是必然发生的.定义站点在退避过程中计数器减 1所需时间为Es,退避过程所消耗时间为Tbakoff,可得:
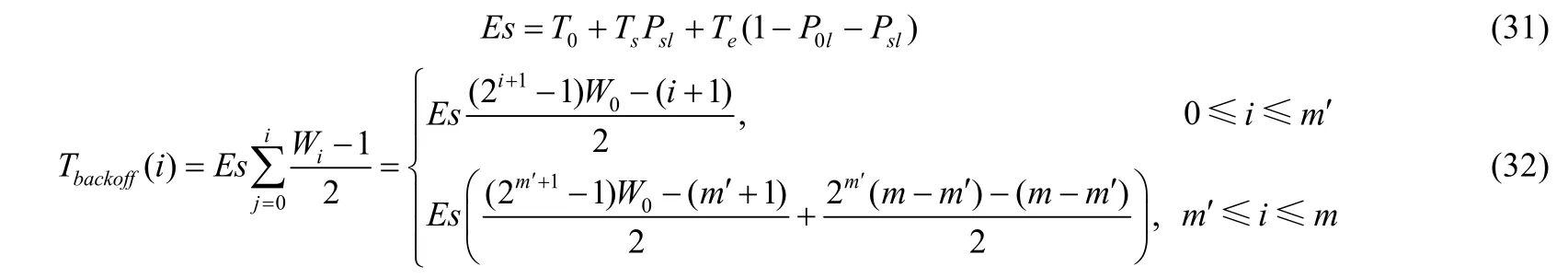
因此,非饱和工作站点的平均服务时长D可由成功传输过程中所消耗的加权均值时间与因重传次数达到最大重传次数限制且重传失败所花费的加权均值时间相叠加组成:
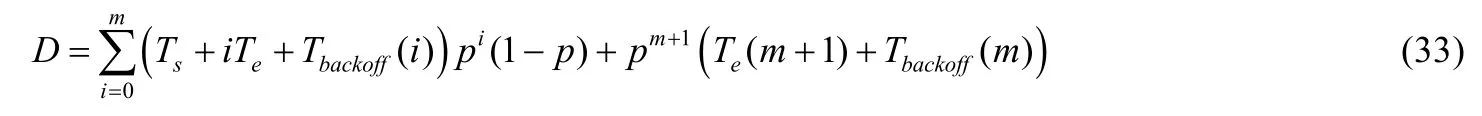
3.4 系统吞吐量
定义归一化的系统吞吐量 TH(throughput)为任意单位时隙内任意站点发送的有效数据载荷E[d]与任意时隙的时隙均值E[s]的比值.吞吐量与节点数关系如图2所示.
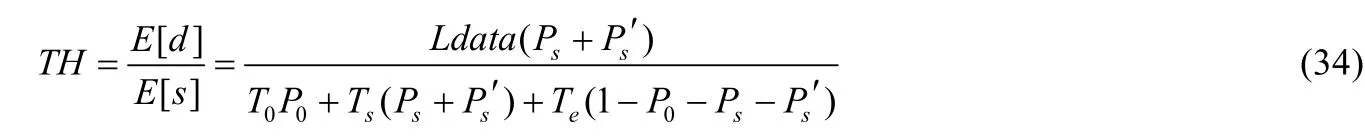
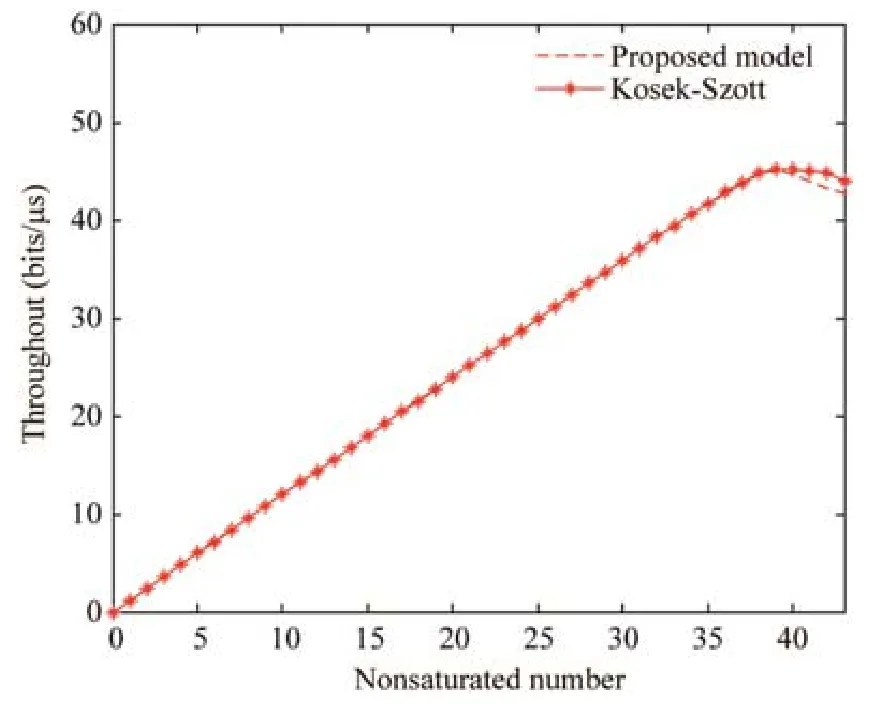
Fig.2 Throughput and number of nodes图2 吞吐量与节点数关系
3.5 平均传输时延
定义平均传输时延为从站点进入退避过程开始,到成功收到接收站点回复的ACK确认帧,确认数据成功传输为止,为数据的传输时延,即一次成功的数据通信所消耗的平均时间.与式(33)相似,可以分别归纳出非饱和站点及饱和站点的平均传输时延:
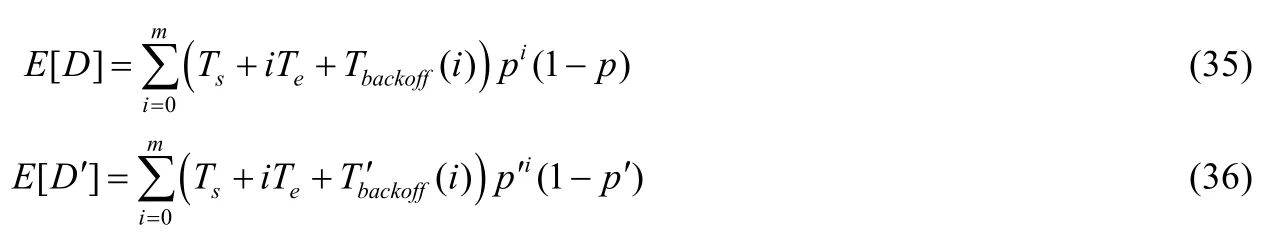
3.6 传输丢包率
由于数据到达率服从泊松分布,且缓存状态与之前状态过于相关,故服务时长内缓存溢出丢包率的是极其复杂的,只考虑当前状态而不考虑之前状态是不准确的.因此本文只讨论给出了由于站点达到最大重传次数限制而丢包的传输丢包率,对于非饱和工作站点及饱和工作站点的传输丢包率可分别表示为

4 数值分析及仿真实现
仿真的参数来源于IEEE 802.11ac[2]协议的相关部分,见表1.需要特别指出的是,在进行算法比较时,不同模型间的对比将采用包括但不限于对算法部分内容进行置零等方法,使提出的算法与对比算法在参数及变量上保持一致,以尽可能地消除不必要的干扰.

Table 1 Summary of IEEE 802.11ac parameters表1 IEEE 802.11ac DCF参数设置
本文提出的算法在图 2中与 Kosek-Szott[19]提出同样聚焦于异构混合成分网络的算法进行了对比.在仿真的过程中提出的算法在参数设置上与文献[19]完全相等,即不考虑最大重传次数大于最大窗口的阶数,不考虑误码率等情况.同样地,与文献[19]中讨论的方式相同,为了便于仿真以及增加多组对比,只对非饱和工作模式下的DCF模型进行了分析比较.结合文献[19]中的相关成果,可以得出,在不饱和节点逐渐增多的过程中,由于传输碰撞概率的增加不饱和性减小而饱和概率增加,提出的算法结果优于文献[19]中的结果,更接近于 DCF机制的实际吞吐量,这主要得益于概率归纳更准确以及服务时长考虑更完善.同时,在建模过程中,本文提出的算法对不饱和性的计算是通过概率的大小来表示的,故在算法实现的过程中,随着不饱和节点数或数据包达到率的增加可以自动同步计算新的不饱和性.而文献[19]中的算法由于其采用的是M/M/1/K排队模型,且在不饱和性的处理上将其与单位时隙平均达到的数据包个数相等同,因此,随着系统趋于饱和,需要计算不饱和模式与饱和模式之间的连接点并适时地利用饱和算法来计算饱和模式下的任意时隙有数据发送的概率.因此,这种算法相对提出的算法更加复杂,且文献[19]中数据包达到率被定义为服从泊松分布,因此,简单地用平均值来处理系统不饱和性的方法也是不太准确的.
在图3和图4中,提出的算法与两种只聚焦于同质网络成分的算法在相同参数条件下进行了仿真比较.
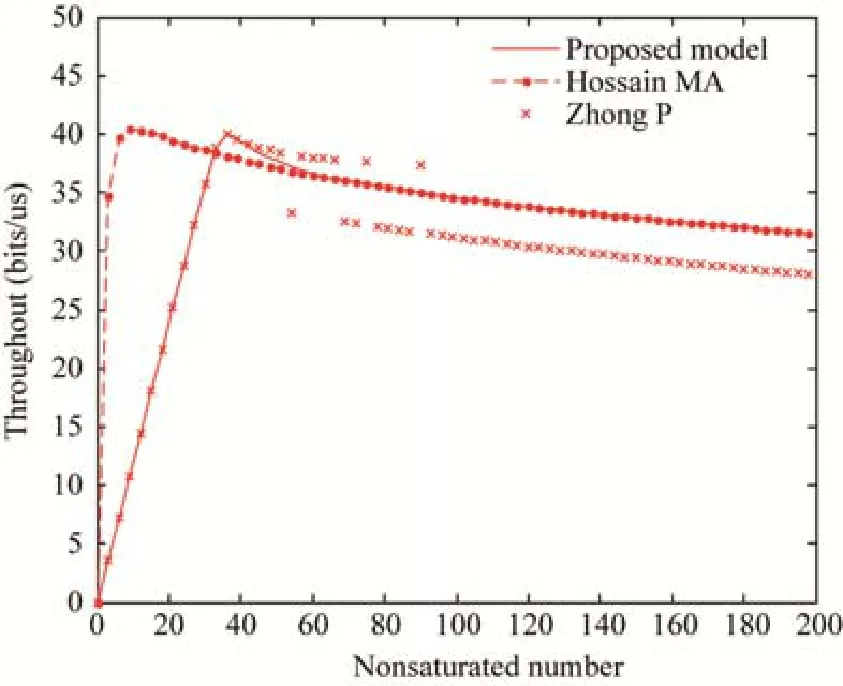
Fig.3 Throughput and number of nodes (m>m′)图3 吞吐量与节点数关系(m>m′)
相较于Hossain等人[11]提出的算法,由于本文充分考虑了数据排队等待的不同状态时长,分别给出了不同q值和ρ值,而文献[11]中简单地将二者等同,故而在系统进入饱和前,提出的算法对非饱和状态的结果处理得更好,与 Zhong等人[21]提出的算法仿真结果趋于一致,而文献[21]中的成果同样验证了这一结果是准确的.但是随着不饱和节点的增加,系统进入饱和状态,提出的算法与文献[11]中的算法仿真结果保持一致,反观文献[21],由于模型稳态求解的结果有误,以及对退避过程考虑不够全面,当m>m′时,仿真结果出现剧烈的波动;当m=m′时,3种算法仿真结果保持基本一致.
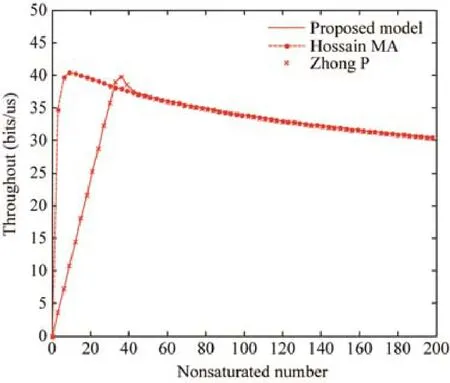
Fig.4 Throughput and number of nodes (m=m′)图4 吞吐量与节点数关系(m=m′)
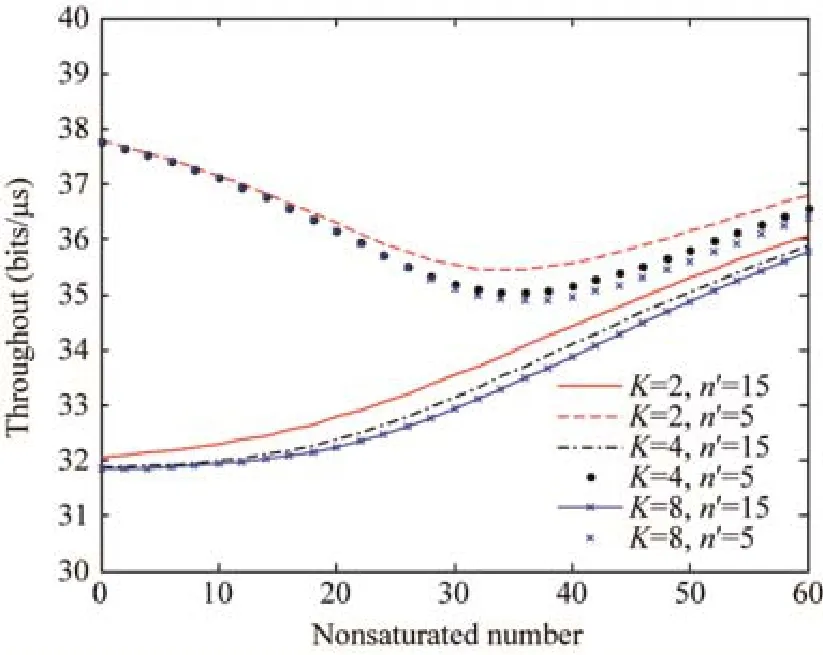
Fig.5 Throughput under heterogeneous traffic sources图5 异构业务下的吞吐量
因此,相较于文献[11,19,21]中的算法,本文提出的算法更加准确、全面,同时保持了相对的简单.故而能够更好地模拟与分析包括单一的同质网络业务成分和异构网络业务成分在内的IEEE 802.11 DCF机制的性能.
图5~图7中利用提出的算法对异构网络业务进行了综合性仿真,分别给出了不同大小的缓存K值、饱和节点数n′随着不饱和节点数n的增长与系统吞吐量、传输时延及传输丢包率的关系.
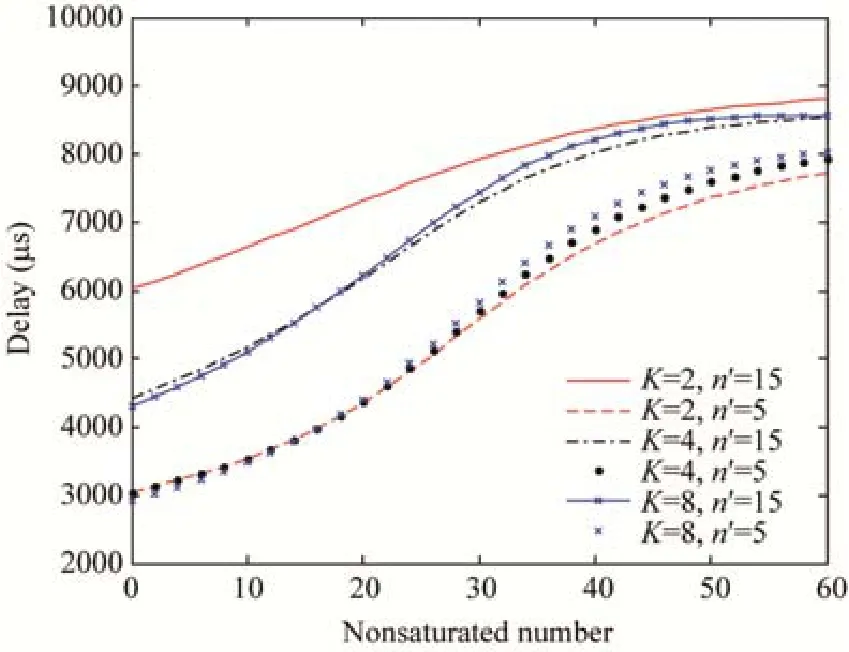
Fig.6 Delay under heterogeneous traffic sources图6 异构业务下的传输时延
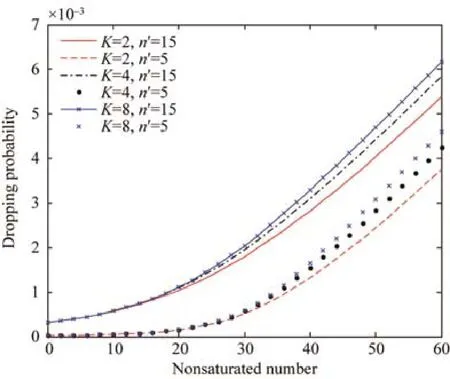
Fig.7 Dropping probability under heterogeneous traffic sources 图7 异构业务下的传输丢包率
可以看出,当饱和节点数n′一定时,吞吐量会随着K值的增长而降低,这是由于K值的增加导致非饱和节点任意时隙发送几率随之增加,从而导致吞吐量一定程度的下降;同样地,传输时延将在一定程度和范围内出现增加.当K值一定时,随着饱和节点数的增多,吞吐量由于系统过于饱和导致冲突可能性的激增,进而导致吞吐量的减少,伴随着不饱和节点的增多,饱和性能被稀释,逐渐进入非饱和阶段,吞吐量重新进入增长期,直至进入新的饱和状态,再随节点数的增加而减少;同时,由于网络中节点数的增长,数据碰撞概率增加,传输时延跟随不饱和节点数的增长而增加.对于传输丢包率,随着节点数的增加,传输丢包率趋于指数型增长.同时,随着K值的增加,丢包率也会出现轻微的增加.
5 结 语
本文提出了一种改进的全新混合Markov模型,详细分析了模型中的不同变量和概率,给出了相应的改进计算方法.结合M/G/1排队模型,以及对有错信道的思考,全面考虑了IEEE 802.11 DCF机制中的退避冻结及重传限制等,在保持模型简单的同时,能够准确地分析缓存大小、节点数量、包到达率等关键问题与系统吞吐量以及时延的关系.通过仿真与分析可以得出,本文提出的算法模型与现有算法模型相比,不仅能够更好地对异构混合业务进行合理的建模、分析,而且更加准确、简单;同时,在单一业务的工作模式下(即将另一种业务的任意时隙的发送概率置零的情况下),本文提出的算法与DCF机制仍然保持了较好的一致性.
在接下来的工作中,将进一步完善相关模型,以及对文献[22]中提到的公平性等问题进行合理、有效的讨论,同时,聚焦于对新的随机接入方式TF-R(trigger frame for random access)[23]进行分析与研究.在提出的模型上,将DCF与 TF-R接入方式进行联合建模,从而对 IEEE 802.11ac与 802.11ax混合模式场景下的性能进行有效的分析.

Table A表A

Table A (Continued)表 A(续)
