跨媒体深层细粒度关联学习方法*
2019-05-20卓昀侃綦金玮彭宇新
卓昀侃,綦金玮,彭宇新
(北京大学 计算机科学技术研究所,北京 100871)
在大数据时代,互联网数据以图像、视频、文本、音频等多种媒体形式广泛存在,它们是计算机感知和认知真实世界的重要载体.由于数据总量和媒体类型的迅猛增长,多媒体信息检索[1]的相关研究得以迅速发展,其中跨媒体检索[2-4]是最新的研究热点之一.跨媒体检索是指用户通过输入任意媒体类型的查询数据,检索出所有媒体类型中的语义相关数据,如图 1所示,用户可以输入“飞机”的相关图像作为查询来检索和飞机相关的图像、视频、文本、音频和3D模型.相比传统的单媒体检索,例如图像检索[5]、视频检索[6]等,跨媒体检索能够更加灵活、全面地满足用户的检索需求.然而,“异构鸿沟”问题导致不同媒体类型的数据分布和特征表示之间存在不一致性,因此难以直接度量多种媒体数据之间的相似性,使得跨媒体检索面临巨大挑战.

Fig.1 An example of cross-media retrieval图1 跨媒体检索示例
事实上,认知科学的研究表明,人类大脑能够通过多种感官信息的融合来认知外部世界[7],视觉、听觉和语言等系统能够很好地协同处理从外界接受的信息.因此,如何通过模拟人脑的认知过程,实现多媒体数据的语义互通与关联理解,是跨媒体检索需要解决的关键问题.对此,现有方法的解决思路通常是建立一个共同子空间,将不同媒体类型的异构数据映射到这个共同子空间中得到统一表征,然后通过常用的距离度量方法来直接计算不同媒体数据之间的相似性,实现跨媒体交叉检索.
根据以上思路,已有一些工作[8-10]尝试为不同媒体类型的数据学习统一表征,可以将其主要分为两类:传统方法和基于深度学习的方法.传统方法通过统计分析学习线性映射矩阵,其中,最具代表性的是典型相关分析(canonical correlation analysis,简称CCA)[11],该方法通过最大化成对媒体数据间的关联来优化映射矩阵.另有一些工作基于典型相关分析,尝试引入其他信息提升其性能,例如语义类别信息[12]等.近年来,随着深度学习在计算机视觉[13,14]等领域取得巨大进展,研究人员尝试通过深度网络的非线性建模能力来分析不同媒体类型数据间的复杂关联关系.Feng等人[8]提出对应自编码器(correspondence autoencoder,简称 Corr-AE)同时对关联关系和重建信息进行建模.Peng等人[15]提出将媒体内和媒体间的关联信息通过层次化网络的方式进行联合学习以提升检索准确率.图2给出跨媒体关联学习方法的框架示意.
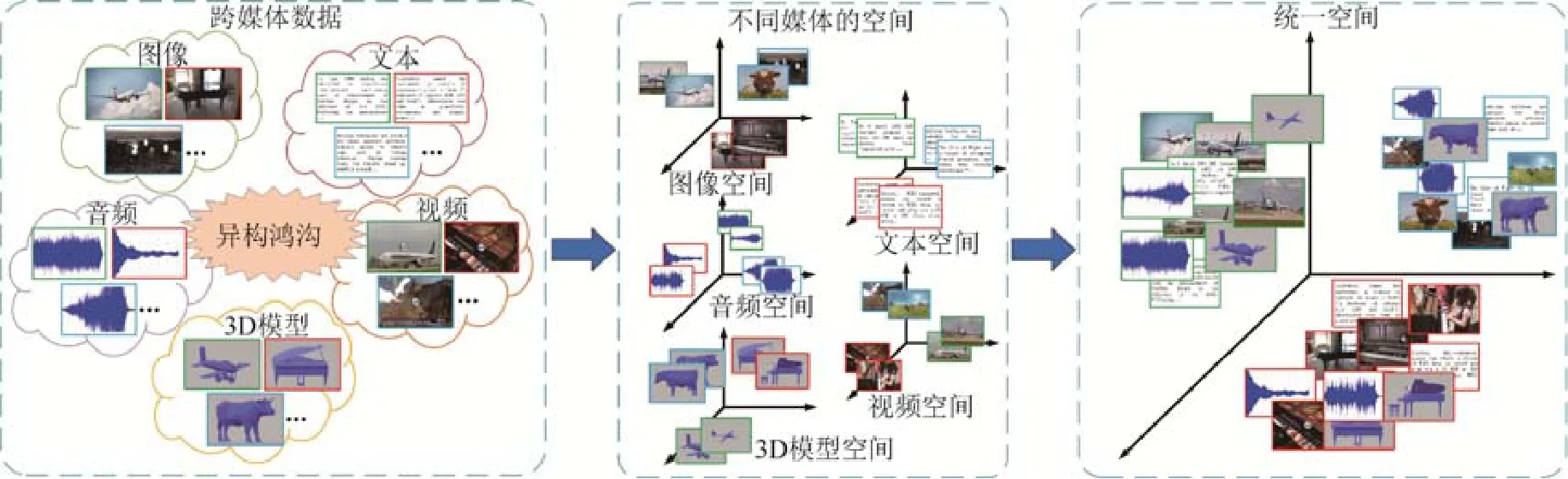
Fig.2 An illustration of the mainstream framework for cross-media correlation learning图2 跨媒体关联学习方法框架示意图
然而,上述方法一般仅针对图像和文本两种媒体类型的跨媒体检索任务,由于它们的泛化性能有限,很难将其扩展至更多种媒体类型的交叉检索,如典型相关分析及其变种方法[16-18]旨在分析两组变量之间的相关关系,尽管可以通过两两组合的方式来将这些方法扩充至多种媒体交叉检索的场景,但不仅无法在一个模型内解决问题,算法复杂度高,而且忽视了多种媒体关联的共存和互补性,导致关联信息有限,降低了检索的准确率.显然,在多种媒体交叉检索的场景下,挖掘不同媒体类型数据之间的语义关联更加困难.由于任意两种媒体之间都存在着异构鸿沟,而且不同媒体类型数据之间的关联关系也有各自独特的特性,现有方法很难将其同时建模在一个模型中.
事实上,描述同一语义的不同媒体类型数据存在天然的语义一致性,且数据内部蕴含着丰富的细粒度上下文信息.其中,细粒度指的是数据的局部区域或片段,上下文指的是这些区域或片段间的关联关系,如图像前景区域和背景区域之间的关系或前后视频帧之间的关系,充分利用细粒度上下文信息能够有效挖掘不同媒体数据之间的关联.例如,在多种媒体交叉检索的场景下,很可能文本的某一部分描述并未在图像中体现,但却和音频或视频的某一片段存在明显的关联.这表明,在多种媒体相互检索的任务中,不同媒体数据之间存在着丰富的语义互补关系,能够为跨媒体关联学习提供充足的线索,而且挖掘其中细粒度信息之间的语义关联尤为重要.然而,现有方法一般仅考虑了不同媒体数据的成对关联,忽略了细粒度局部上下文信息之间的语义关联.此外,现有方法一般仅使用语义类别信息来约束不同媒体数据之间的关联学习,在多种媒体的场景下,其约束能力不足以弥补多种媒体数据间的分布差异.针对上述问题,本文提出了跨媒体深层细粒度关联学习方法,同时在语义和分布两个方面挖掘多达5种媒体类型数据(图像、视频、文本、音频和3D模型)细粒度上下文信息间的关联关系.本文主要贡献如下.
(1) 提出了针对5种媒体的跨媒体循环神经网络,构建统一的网络结构联合建模不同媒体数据内部的细粒度信息,并进一步挖掘不同媒体数据细粒度局部区域或片段之间的上下文关系,充分学习各种媒体内独有的内在信息,为跨媒体关联学习提供更加细粒度的线索.
(2) 提出了基于分布对齐和语义对齐的跨媒体联合关联损失函数.一方面,通过分布对齐弥补不同媒体类型数据之间的分布差异;另一方面,通过语义对齐增强关联学习过程中的语义辨识能力.使分布对齐与语义对齐相互促进,实现对不同媒体数据的语义一致性表达,更好地在 5种媒体条件下实现细粒度跨媒体关联分析与挖掘,提升跨媒体检索的准确率.
为了验证方法的有效性,本文在两个包含5种媒体(图像、视频、文本、音频和3D模型)的跨媒体数据集PKU XMedia和PKU XMediaNet上与现有方法进行实验对比,结果表明,本文方法有效地提高了跨媒体检索的准确率.
1 相关工作
1.1 针对两种媒体的跨媒体检索方法
现有方法往往旨在解决两种媒体类型数据之间的异构鸿沟问题,通常是针对图像和文本,将其映射至统一空间得到跨媒体统一表征.其中,传统方法通过优化特定统计量来学习线性映射矩阵.典型相关分析(canonical correlation analysis,简称 CCA)[11]是第一个被广泛使用的跨媒体模型,该方法通过最大化不同媒体类型成对数据之间的关联来优化模型.一些后续工作基于典型相关分析进行了扩展,例如,Hardoon等人[17]提出核典型相关分析(kernel canonical correlation analysis,简称KCCA),利用核函数实现非线性典型相关分析.此外,Li等人[18]提出了跨媒体因子分析(cross-modal factor analysis,简称CFA)算法,通过最小化成对数据之间的Frobenius范数来优化跨媒体模型.
近年来,深度网络在图像识别[19,20]、视频分类[21]等领域显示出强大的学习能力.受此启发,一些工作尝试使用深度网络来学习统一表征以实现跨媒体检索.Andrew等人[22]提出深度典型相关分析(deep canonical correlation analysis,简称 DCCA)方法,通过两个子网络的输出关联来优化模型.Feng等人[8]构建对应自编码器(correspondence autoencoder,简称 Corr-AE),通过中间层来链接两路子网络,同时对关联关系和重建信息进行建模.Wei等人[23]提出的深度语义匹配(deep semantic match,简称Deep-SM)模型使用卷积神经网络来建模图像数据,从而进一步挖掘语义关联信息.Peng等人[15]提出了跨媒体多网络结构(cross-media multiple deep network,简称CMDN)模型,将媒体内和媒体间的关联信息通过层次化网络的方式进行联合学习以提升检索准确率.他们在此基础上进一步提出了跨模态关联学习(cross-modal correlation learning,简称CCL)方法[24],通过多任务学习的方式挖掘不同媒体类型数据的粗细粒度信息.Huang等人[25]提出了基于混合迁移网络的跨媒体统一表征(cross-modal hybrid transfer network,简称CHTN)方法,实现了从单媒体源域到跨媒体目标域的知识迁移.此外,对抗式学习也被应用在跨媒体检索中[26].
1.2 针对多种媒体的跨媒体检索方法
目前仅有很少的工作针对多于两种媒体的交叉检索任务,其中,Zhai等人[27]尝试构建图模型来学习映射矩阵,首先将 5种媒体同时在传统框架中建模,并进一步提出了联合表示学习(joint representation learning,简称JRL)方法[10],加入语义信息和半监督规约来构建统一空间.此外,Peng等人[28]提出构建统一的跨媒体关联超图,同时利用了不同媒体的细粒度信息并结合半监督规约来学习跨媒体统一表征.然而,由于以上方法均使用传统框架学习线性映射,难以充分挖掘多达 5种媒体类型数据之间的关联关系.而某些基于深度学习的方法,如深度语义匹配模型,尽管可以通过增加子网络的方式将其扩展至多种媒体,但其仅考虑了数据内部的语义类别信息,难以挖掘多种媒体之间复杂且多样的关联关系.
本文旨在弥补上述缺陷,联合建模多达 5种媒体类型数据的细粒度上下文信息,同时实现不同媒体数据类型数据之间的语义对齐和分布对齐,从而提升5种媒体交叉检索的准确率.
2 本文方法
本文方法的网络结构如图3所示.首先,构建针对5种媒体数据的跨媒体循环神经网络,通过将不同媒体类型数据的局部区域或片段序列输入到循环神经网络中建模数据内部的细粒度上下文信息.然后,在循环神经网络之上设计跨媒体联合关联损失函数,通过语义对齐和分布对齐相结合的方式,联合优化异构数据到统一空间的映射,从而学习更加精确的细粒度跨媒体关联.
首先介绍本文的形式化定义,其中,D={DI,DT,DA,DV,DM}为包含 5种媒体类型的跨媒体数据集,{xi,xt,xa,xv,xm}∈D分别代表数据集中图像、文本、音频、视频和3D模型数据.此外,定义l∈{i,t,v,a,m}表示任意一种媒体类型,这样,{xl,yl}∈D分别代表数据集中的任意媒体类型的数据及其类别标签.跨媒体检索旨在给定任意一种媒体类型的数据,返回与其语义相关的所有媒体类型的检索结果.
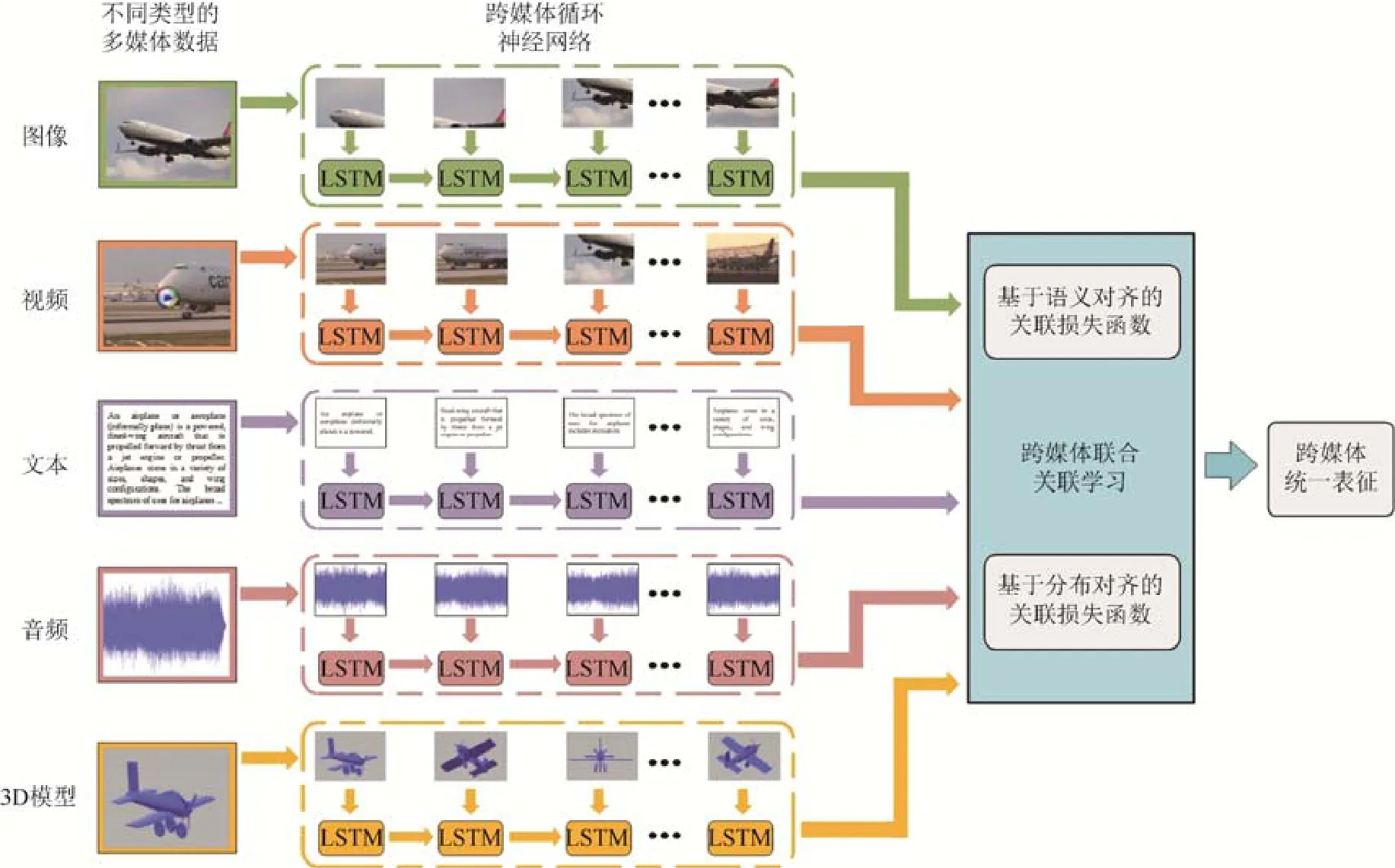
Fig.3 An overview of our proposed FGCL approach图3 本文方法整体框架示意图
2.1 跨媒体循环神经网络
为了充分利用多种媒体类型数据中丰富的细粒度上下文信息,本文构建了多路循环神经网络,将每种媒体类型数据的局部区域或片段的序列输入到循环神经网络来学习细粒度特征表示.对不同媒体类型数据分别进行分割并获取细粒度特征序列的具体策略将在第2.3节中详细加以介绍.
上述得到的每种媒体类型数据局部区域或片段的特征序列蕴含了丰富的细粒度信息,进一步将其输入到循环神经网络中来充分挖掘不同媒体类型数据内部的细粒度上下文信息.本文采用了长短时记忆(long short term memory,简称 LSTM)网络[29],LSTM 网络作为一种特殊的循环神经网络,能够利用记忆单元(cell)及门限(gate)的更新有效地学习序列数据中的长期依赖,并充分保存历史时间步中的信息.本文将上述每种媒体类型数据的特征按照序列逐步输入到LSTM网络中,并根据如下公式逐步更新网络:
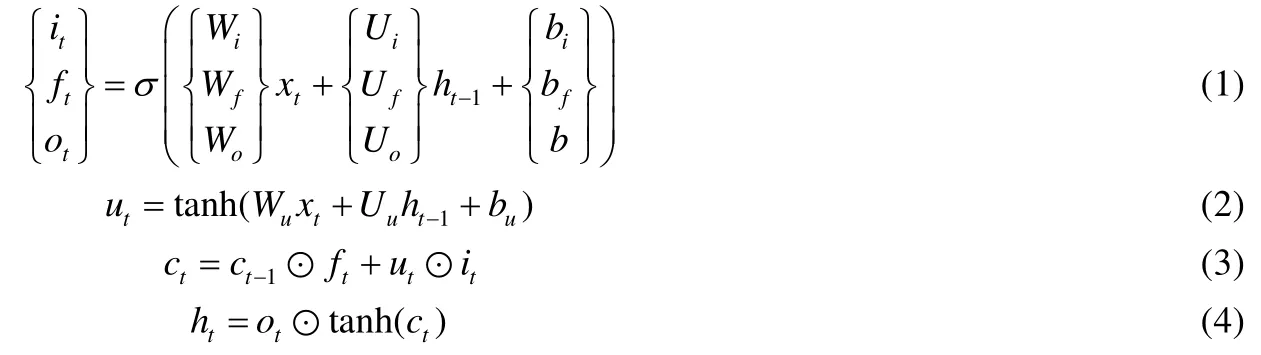
其中,x表示输入序列,i,f,o和c分别表示输入门、遗忘门、输出门和记忆单元,⊙表示元素相乘,而σ表示Sigmoid激活函数,W和U为循环神经网络中待学习的参数.将输出序列通过全连接层就可以得到每种媒体数据固定维数的序列特征,随后将序列特征取平均得到,其中,j为序列长度.这样,每个任意媒体类型数据的特征hl都包含了丰富的细粒度上下文信息,为进一步挖掘跨媒体细粒度关联关系提供了重要线索.
2.2 跨媒体联合关联学习
在得到包含细粒度上下文信息的不同媒体特征之后,如何更好地将其映射至统一空间中成为解决 5种媒体类型数据间交叉检索的关键问题.具体地,本文在上述循环神经网络顶层提出了基于分布对齐和语义对齐的跨媒体联合关联损失函数,通过弥补不同媒体类型数据之间的分布差异,同时充分利用了数据的语义类别信息增强关联学习过程中的语义辨识能力,能够更好地在5种媒体的条件下实现细粒度跨媒体关联的分析与挖掘.
首先,我们设计了基于语义对齐的关联损失函数.将第2.1节得到的不同媒体类型的数据表征hl通过全连接网络(fully-connected network)映射到统一的语义空间中,并采用如下损失函数来约束不同媒体类型数据之间的语义关联:
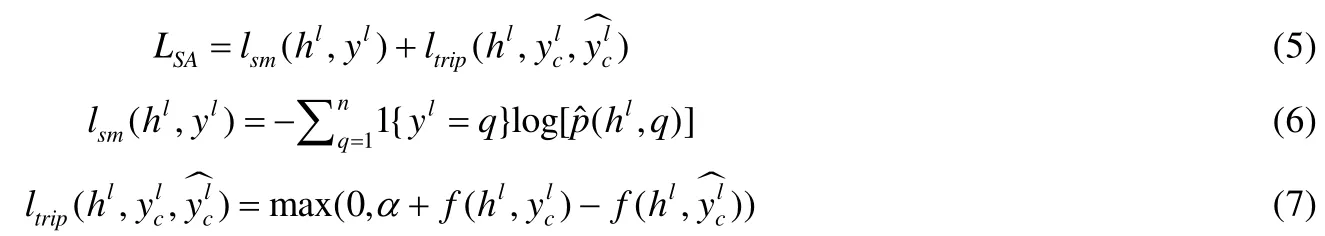
其中,lsm(hl,yl)为交叉熵损失函数项,yl为hl的语义类别标签,共有n个类别.当yl=q时,1{yl=q}值为1,否则,其值为表示预测该样本属于第q个类别的概率.
通过三元组的形式,约束属于相同语义类别的不同媒体类型数据,使其距离其对应类别的特征向量尽可能地近,同时距离其他类别的特征向量尽可能地远.由于类别标签通过 Word2Vec模型来映射,其映射后的特征向量本身带有语义信息,通过将不同媒体数据映射到其类别向量周围,使得不同媒体数据映射后的统一表征保留其对应类别的语义信息,同时保证它们的语义一致性.因此,通过基于语义对齐的关联损失函数,能够有效地增强统一表征的语义辨识能力,促进细粒度的跨媒体关联挖掘.
进一步地,我们设计了基于分布对齐的关联损失函数.具体地,我们采用最大均值差异(maximum mean discrepancy,简称 MMD)[31]损失函数来优化不同媒体类型数据之间的分布差异.最大均值差异被广泛使用在迁移学习和域自适应中,是衡量两个数据分布差异的重要标准.其基本原理是针对两个不同分布的样本,通过寻找在样本空间上的连续函数,使不同分布的样本在该函数上函数值均值的差值最大,从而得到最大均值差异MMD.通过最小化 MMD损失,可以减小不同分布之间的差异,达到对齐分布的效果.基于上述思想,我们定义了如下基于分布对齐的关联损失函数:

其中,i,j表示任意两种不同的媒体类型.而任意两种媒体类型数据之间的MMD损失函数定义如下:
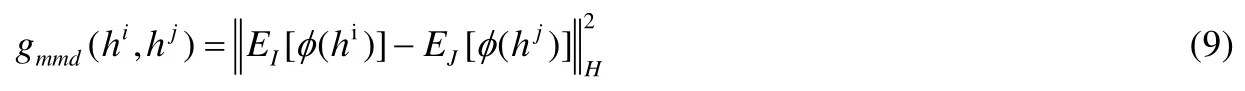
其中,MMD损失函数是在再生希尔伯特空间(reproducing kernel Hilbert space,简称RKHS)的平方形式.通过最小化上式,可以减小hi和hj之间的分布差异,达到不同媒体类型之间的分布对齐.综上,基于语义对齐和分布对齐的跨媒体联合关联损失函数定义如下:

通过最小化上述损失函数,不仅可以增强跨媒体统一表征的语义辨识能力,在统一空间中将不同媒体类型的数据约束至其语义中心,同时可以减小 5种媒体之间的数据分布差异,从而有效学习不同媒体类型数据细粒度上下文信息之间的关联关系,提高跨媒体检索的准确率.
2.3 实现细节
本文提出的网络在Torch框架上得以实现.具体地,对于每个图像样本xi,将其缩放后输入VGG-19卷积神经网络[32],通过最后一个池化层(pool5)来提取出49个不同区域的局部特征,每个特征维数为512维,然后按照人眼观察的顺序组成序列.对于每个文本样本xt,首先按照段落或语句将其切分成片段,然后利用文本卷积神经网络[33]对每个片段提取300维特征,最后按照文本片段本身顺序组成序列.对于每个音频样本xa,按照固定时间间隔将其分割成片段,对每个片段分别提取128维Mel频率倒谱系数特征(mel frequency cepstrum coefficient,简称MFCC)形成序列.对于视频,对每一个视频帧提取VGG-19网络[32]全连接层(fc7)的4 096维图像特征,然后按照其原本时间顺序组成序列.对于 3D模型,我们采用 47个不同角度来观察 3D模型数据,然后使用光场描述子(light field)[34]对每一个角度提取 100维特征,再依照文献[28]将其组成序列.总的来说,针对特征选择,本文旨在探究跨媒体关联学习问题,特征选择并非本文重点,且本文的模型可以支持多种输入特征.针对序列选择,对于带有内在序列性质的媒体类型,如文本、音频和视频,我们按照其天然顺序将区域片段组成序列.对于序列性质不明显的媒体类型,如图像和 3D 模型,我们按照固定顺序组成序列,且其细粒度数据之间的顺序对关联学习的最终结果影响不大.使用上述固定切分方式不仅能够有效地保留某些媒体数据的细粒度单元,也降低了模型的复杂度.此外,在实验过程中,我们将跨媒体循环神经网络的输出,即统一表征的维数设置为 300维,语义对齐关联损失函数(见公式(7))中的边界参数α设置为1,网络训练的学习率固定为1e-4.
本文模型训练过程需要 25个 epoch,时间复杂度和其他基于深度网络的跨媒体检索方法相当,并且由于算法充分挖掘了跨媒体细粒度数据之间的上下文关系,泛化能力较强,输入特征可以直接使用预训练的深度网络或是传统特征而不需要进行微调,这也缩短了算法的运行时间.空间复杂度上,一方面循环神经网络的自身性质决定了不同时刻输入循环神经网络的数据经过同一个神经元,大大节省了参数量.另一方面,较低的统一空间维度(300维)也减少了模型的空间复杂度.
3 实 验
本文在两个具有挑战性的跨媒体数据集PKU XMedia和PKU XMediaNet上进行了多种媒体的交叉检索实验,两个数据集均包含多达5种媒体类型(图像、文本、音频、视频和3D模型)的数据.为了更加全面地验证本文提出方法的有效性,我们进行了两大类的实验对比,包括5种媒体的交叉检索和2种媒体(图像和文本)的相互检索,与12种现有方法进行了对比.此外,本文还进一步通过基线实验以验证本文方法各个部分的效果.
3.1 数据集介绍
下面简要介绍本文使用的两个包含5种媒体类型的跨媒体数据集,每个数据集均划分为训练集、验证集和测试集3个部分,具体划分方式见表1和表2.
数据集网址为http://www.icst.pku.edu.cn/mipl/XMedia.
PKU XMedia数据集[2]是第一个包含5种媒体类型的跨媒体数据集.数据集共有20个常见的语义类别,比如自行车、钢琴、昆虫等,数据来源包括维基百科(Wikipedia)、Flickr、YouTube等.
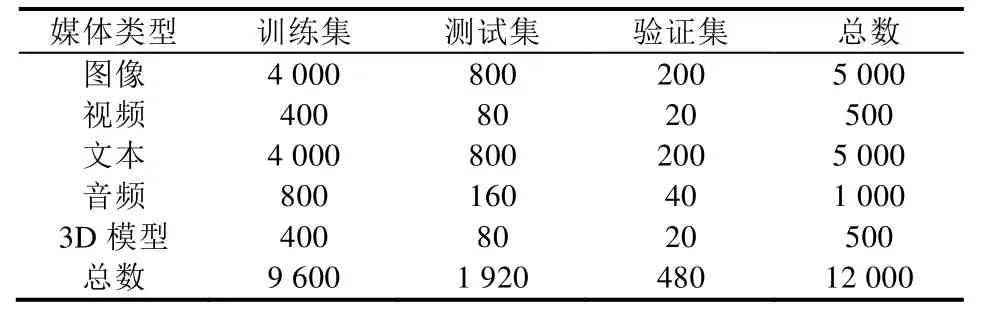
Table 1 The dataset partition on PKU XMedia表1 PKU XMedia数据集的划分方式
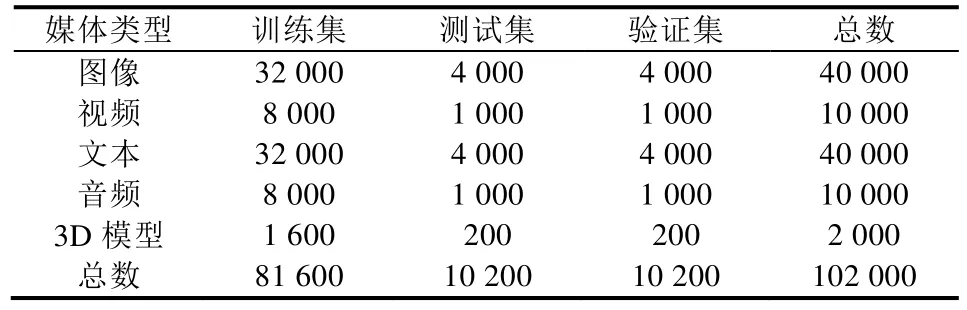
Table 2 The dataset partition on PKU XMediaNet表2 PKU XMediaNet数据集的划分方式
PKU XMediaNet数据集[2]是目前国际上最大的包含5种媒体类型的跨媒体数据集,共包含超过10万个数据样本,其规模是XMedia的10倍.共包含了200个常见类别,主要分为动物和人造物两大类.图4展示了该数据集的部分样例.数据来源包括Wikipedia、Flickr、YouTube、Freesound、Yobi3D等.

Fig.4 Quintuple-media examples from PKU XMediaNet dataset图4 来自PKU XMediaNet数据集的5种不同媒体类型数据示意图
3.2 评价指标和对比方法
不同媒体数据之间的相似度可以通过计算跨媒体统一表征之间的距离来得到,本文采用余弦距离来计算相似度,从而对检索结果进行排序.为了全面验证本文方法的有效性,我们分别设置了5种媒体交叉检索和2种媒体相互检索的实验.
3.2.1 5种媒体交叉检索
5种媒体交叉检索是指将任意一种媒体类型的查询样例作为输入,检索所有5种媒体类型数据中与之语义相关的结果.举例来说,将图像作为查询样例输入,检索测试集中图像、文本、音频、视频和 3D模型的样本,表示为图像检索全部(Image➔All).以其余 4种媒体类型作为查询的检索可以表示为:文本检索全部(Text➔All)、音频检索全部(Audio➔All)、视频检索全部(Video➔All)和3D模型检索全部(3D➔All).
本文采用平均准确率均值(mean average precision,简称MAP)作为评价指标,该指标能够同时兼顾返回结果的排序以及准确率,在信息检索领域被广泛使用.具体地,首先计算查询样本所有返回结果的平均准确率(average precision,简称AP),然后计算所有查询的AP结果的平均值得到最终的MAP值.
本文方法与3种支持5种媒体场景或可以扩展至5种媒体场景的现有方法进行了实验对比,分别是JRL[10]、S2UPG[28]和Deep-SM[23],其中,前两种是直接支持5种媒体的交叉检索的传统方法,而Deep-SM[23]是基于深度学习的方法,其本身仅针对两种媒体相互检索,但可以通过扩充另外 3路子网络的方式来支持 5种媒体的交叉检索.为了更加公平地与现有方法进行比较,所有方法在 5种媒体上都使用了与本文相同的深度网络或描述子来提取输入特征.具体地,对于图像,我们采用在ImageNet数据集上预训练,并在目标数据集上微调的VGG-19卷积神经网络[32]提取4 096维全连接层特征(fc7).对于文本,我们依照文献[33]中的方式通过文本卷积神经网络对其提取300维的特征.对于音频,我们对音频帧分别提取Mel频率倒谱系数特征(mel frequency cepstrum coefficient,简称MFCC),然后取平均获得128维MFCC特征.对于视频,我们通过平均每一个视频帧的VGG-19网络全连接层特征(fc7)得到4 096维特征.对于3D模型,我们将47个角度的光场描述子特征(light field)[34]拼接得到4 700维特征.
3.2.2 两种媒体相互检索
由于现有方法往往仅针对两种媒体的跨媒体检索任务,且以图像和文本相互检索为主,为了更全面地与现有方法进行实验比较,本文也进行了图像和文本相互检索的实验,包括两个检索任务:图像检索文本(Image➔Text)和文本检索图像(Text➔Image).实验结果评估同样采用了第3.2.1节中提到的MAP指标,这里需要说明的是,本文中的 MAP值通过计算每个样例返回的所有检索结果得到,与 Corr-AE[8]以及 ACMR[26]中仅使用前 50个返回结果的计算方式不同.图像文本相互检索的实验对比了 12种现有方法,包括 6种传统跨媒体检索方法:CCA[11]、CFA[18]、KCCA[17]、JRL[10]、S2UPG[28]和LGCFL[9],以及6种基于深度学习的跨媒体检索方法:Corr-AE[8]、DCCA[22]、Deep-SM[23]、CMDN[15]、CCL[24]和 ACMR[26].为了实验的公平对比,如第 3.2.1 节中所述,所有对比方法的图像和文本都使用了相同的输入特征.本文代码已经发布在https://github.com/PKU-ICSTMIPL,对比方法JRL[10]、S2UPG[28]、CMDN[15]和CCL[24]的发布代码也在此目录下.
3.3 与现有方法的实验结果对比
3.3.1 5种媒体交叉检索
5种媒体交叉检索的实验结果见表3和表4.从对比结果可以看出,本文提出的方法在两个数据集上均超过了所有对比方法,跨媒体检索的准确率有比较明显的提升.以 PKU XMediaNet数据集为例,平均检索准确率从0.303提升到0.366.对比方法中,基于深度网络的Deep-SM方法未能超过另外两种基于传统框架的方法JRL和S2UPG,因为其只考虑了粗粒度的全局语义信息,没有考虑不同媒体数据之间的分布差异.而本文方法充分挖掘了不同媒体数据内部的细粒度上下文信息,同时结合语义对齐和分布对齐来优化不同媒体数据到统一空间的映射,更好地克服了5种媒体之间的异构鸿沟问题.

Table 3 Results of cross-media retrieval with five media types on PKU XMedia dataset表3 PKU XMedia数据集上的5种媒体交叉检索结果

Table 4 Results of cross-media retrieval with five media types on PKU XMediaNet dataset表4 PKU XMediaNet数据集上的5种媒体交叉检索结果
3.3.2 两种媒体相互检索
图像文本相互检索的实验结果见表5和表6,本文提出的方法在两个数据集上同样超过了12种对比方法,表明本文方法在两种媒体相互检索的场景下同样具有很好的效果.对比方法中,传统方法和基于深度学习的方法的检索准确率并没有很大的差异,一些传统方法甚至超过了部分基于深度学习的方法,例如JRL[10]、S2UPG[28]和 LGCFL[22].另一方面,CCL[24]方法采用多任务学习的方式同时考虑粗细粒度的信息,在对比方法中取得了最好的结果.而本文方法不仅充分挖掘了数据内部的细粒度信息,还考虑到了它们之间的上下文关系,有效地学习了两种媒体类型数据之间的关联关系.
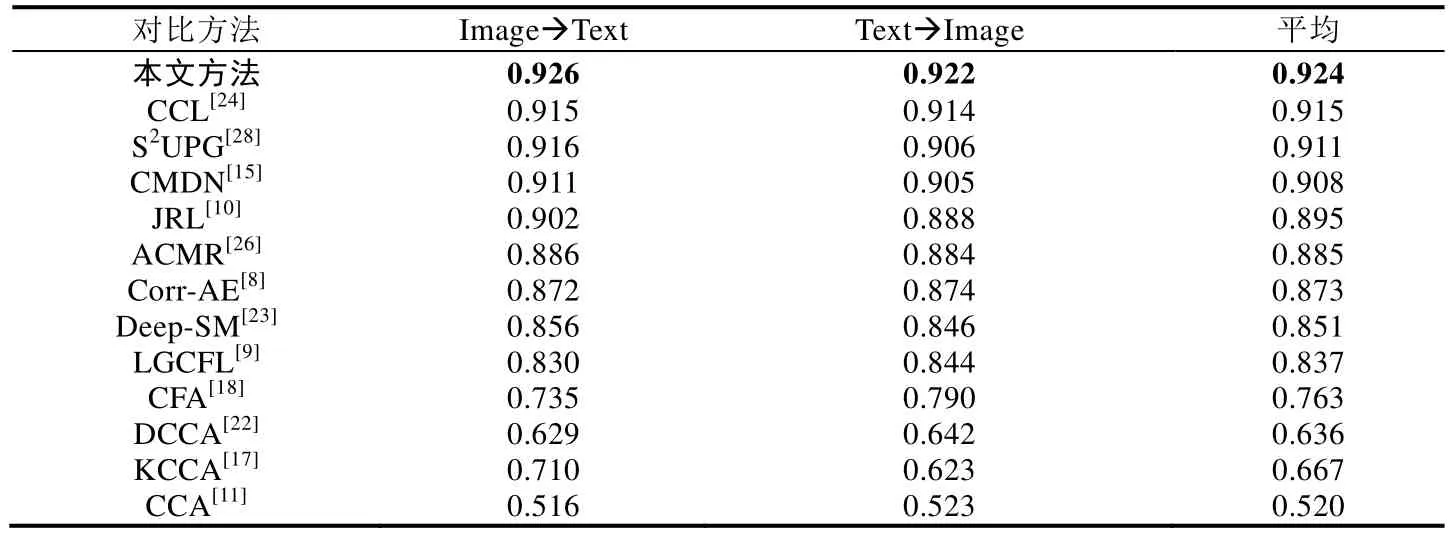
Table 5 Results of cross-media retrieval between image and text on PKU XMedia dataset表5 PKU XMedia数据集上的两种媒体相互检索结果
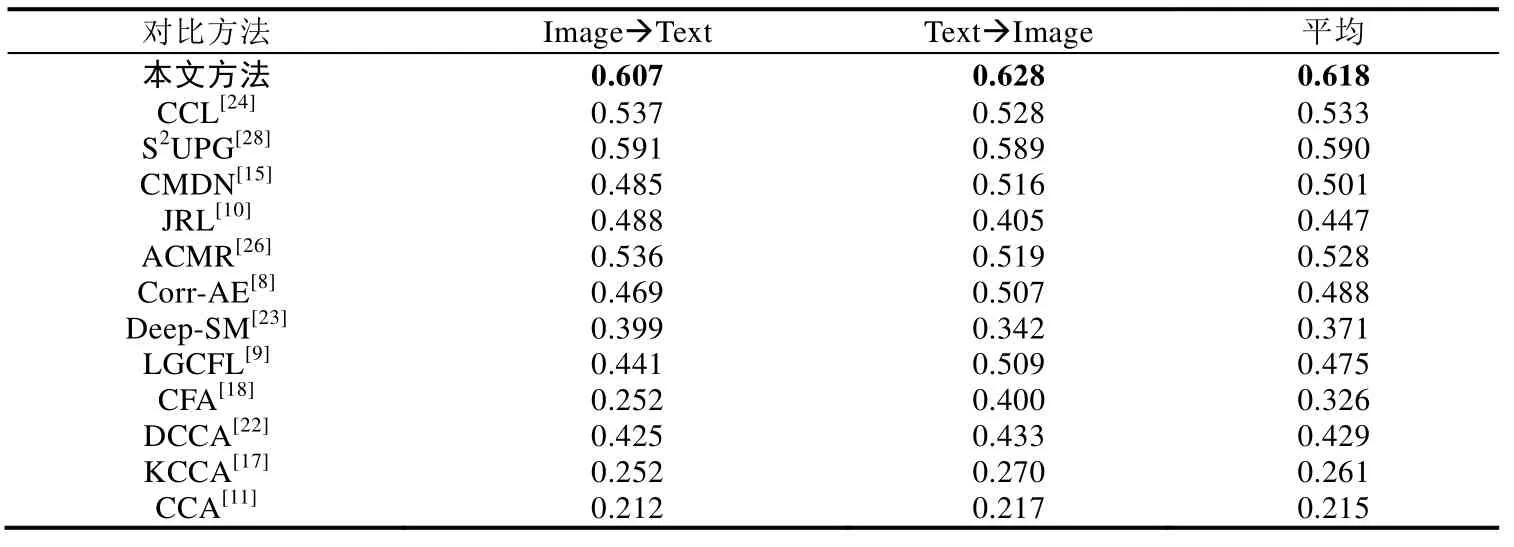
Table 6 Results of cross-media retrieval between image and text on PKU XMediaNet dataset表6 PKU XMediaNet数据集上的两种媒体相互检索结果
3.4 基线实验结果分析
为了验证本文方法各个部分的效果,我们进一步进行了基线实验的对比,其中,“无三元组损失”表示去掉语义对齐关联损失函数(见公式(5))中的三元组损失函数(见公式(7))部分,“无 MMD损失”表示去掉分布对齐关联损失函数(见公式(8)),“基线方法”表示同时去掉上述两个部分,仅使用语义类别信息(见公式(6))来约束不同媒体类型数据到统一空间的映射.从表 7和表 8可以看出,仅使用语义类别约束的平均检索准确率也同样高于 3种对比方法的结果,表明充分利用数据内部的细粒度上下文信息能够更有效地建模不同媒体类型数据之间的关联关系,而三元组损失函数和分布对齐损失函数能够使模型在拥有语义辨识能力的同时,有效地将不同媒体类型数据的分布在统一空间内对齐,进一步提高了跨媒体检索的准确率.

Table 7 Baseline experiments on PKU XMedia dataset表7 PKU XMedia数据集上的基线实验结果

Table 8 Baseline experiments on PKU XMediaNet dataset表8 PKU XMediaNet数据集上的基线实验结果
4 结 论
本文提出了跨媒体深层细粒度关联学习方法,首先提出跨媒体循环神经网络以充分挖掘多达 5种媒体类型数据的细粒度上下文信息,然后设计了跨媒体联合关联损失函数,将分布对齐和语义对齐相结合,在准确挖掘媒体内和媒体间细粒度关联的同时,利用语义类别信息增强关联学习过程中的语义辨识能力,有效提升了跨媒体检索的准确率.通过在两个包含多达5种媒体类型(图像、视频、文本、音频和3D模型)的跨媒体数据集PKU XMedia和PKU XMediaNet上与现有方法进行实验对比,表明了本文方法在多种媒体交叉检索任务的有效性.
下一步工作将尝试扩展现有框架,在不同尺度上挖掘跨媒体数据之间的关联关系,同时充分利用无标注数据并结合外部知识库以进一步提升跨媒体检索的准确率.
