基于异构特征信息匹配的车辆自主定位方法研究
2019-05-16魏东岩王向东
李 雯,魏东岩,陆 一,王向东,袁 洪
(1.中国科学院光电研究院,北京 100094;2.中国科学院大学,北京 100049;3.北京航天发射技术研究所,北京 100076)
0 引言
车辆导航已成为现今生活中必不可少的一项应用,极大地提升了人们的出行效率。目前,车载导航定位主要依赖于全球导航卫星系统(Global Navigation Satellite System,GNSS)技术,但卫星导航信号无法覆盖隧道、地下车库等典型场景。因此,目前的车载导航定位服务还存在诸多服务盲区。随着城市化建设的不断推进,人们对于复杂道路、建筑空间内的导航定位需求日益迫切,如何解决GNSS拒止条件下的车辆导航定位问题,受到越来越多的关注。
INS、DR、Lidar等技术与GNSS的组合在一定程度上缓解了GNSS短时失效情况下的车辆定位问题[1]。但车载定位传感器的性能受成本、尺寸等多方面约束,这些基于递推原理的定位手段其定位性能通常随行驶距离或时间会快速发散,并不适合隧道、地下车库等GNSS长时间无服务的场景。
相比而言,基于指纹特征的匹配方法具有可以利用已布设的硬件设施和传感器成本低、易实现的优势,且其定位精度不随时间或距离而发散,更加适合GNSS长时拒止的应用场景[2-4]。目前,基于WLAN/蓝牙无线电强度指纹、地磁强度指纹的匹配定位在行人导航定位中研究较多[5-6],且已有不少商用化的尝试。但在车辆应用中,由于车辆的应用环境比行人导航应用更为复杂,包括隧道、车库、复杂建筑群等多种情形,单一的某种匹配手段难以满足要求。例如隧道内WLAN/蓝牙覆盖相对稀疏,但地磁特征更为稳定;地下车库等环境中WLAN/蓝牙信号覆盖通常较为良好,但磁场信息受周围车辆影响明显。
综上,本文面向车辆在GNSS拒止环境下的导航定位需求,综合考虑无线电指纹、地磁指纹、地理信息指纹的优势,针对多源特征信息的指纹库建立方法和联合匹配方法分别进行研究,以解决车辆在GNSS拒止条件下的连续定位问题。
1 问题描述
匹配定位中的指纹通常上是指和位置相关联的某种特征信息,例如WLAN/蓝牙/蜂窝无线电网络的无线信号强度、磁场强度、图像信息、地理特征等,这些信息的分布和位置密切相关,不同位置具有不同的特征。指纹定位通常分为建立指纹数据库和在线匹配2个过程。建立指纹数据库是指事先建立特征信息与位置的关联关系,一般是事先离线完成的;在线匹配过程是在定位时将实时采集的指纹数据和事先建立好的指纹数据库进行比对匹配,从而实现位置估计。
传统的指纹数据库建立过程一般需要测量人员进行专门的实地测量,工作量巨大,成本较高,而且指纹数据库会因为环境变化、电子元器件老化等问题而变化,导致指纹数据库的生命周期较短,需要频繁维护。由于车辆导航应用环境通常区域面积大、环境复杂,传统的人工方式建库并不适合。面向上述场景,众包数据为指纹库的构建提供了一种有效的手段[7-9],但由于指纹定位所适合的场景一般是GNSS无法服务的区域,所以在这些区域采集的众包数据中通常不含有定位结果信息,如果事先没有地图信息,很难直接利用[10-11]。因此,如何利用众包数据获得地理结构关系、标注数据采集点的位置成为关键,一旦知道了众包数据的采集位置,便可以基于众包数据进行建库。针对此,本文提出了通过地理信息、地磁分布以及蜂窝网络、WLAN、蓝牙基站信号等特征综合进行路段的空间聚类,进而实现众包数据空间构图的方法。
与建库方法相比,指纹特征匹配算法研究相对更为成熟,例如WLAN/蓝牙匹配定位中的KNN、WKNN算法以及地磁匹配中的ICCP算法等,但这些算法通常只能针对某一种特定指纹信息进行匹配,在多种不同指纹特征间不具备通用性。使用单一特征指纹进行匹配的弊端在于,如果这种特征信息受到噪声影响,势必会造成定位精度的损失,甚至无法定位。相比而言,无线电、磁场[12]、地理信息等多种不同特性的指纹信息同时受到干扰的概率要远低于某一种单一特征受到干扰的概率。因此,如果能基于多种特征信息进行联合匹配,必然能够提高定位结果的鲁棒性以及精度。所以,本文基于隐马尔科夫模型(Hidden Markov Model, HMM),设计了一种面向多种异构特征信息的联合匹配方法,能够把无线电强度指纹、地磁场信息以及地图信息等多种信息联合匹配来进行位置求解。
2 基于众包数据的构图方法
考虑车辆的运动特征、工作环境,结合目前智能终端的发展水平,本文所考虑的众包数据包括用户终端在行驶过程中采集的磁场信息、蜂窝网/WLAN/蓝牙信息、加速度、角速度、磁航向及里程计信息等。为有效利用这些信息进行构图,本文设计的工作过程包括轨迹生成预处理、子轨迹段分割、聚类和空间重构、数据库建立4个过程,方法的实现过程示意图如图1所示。
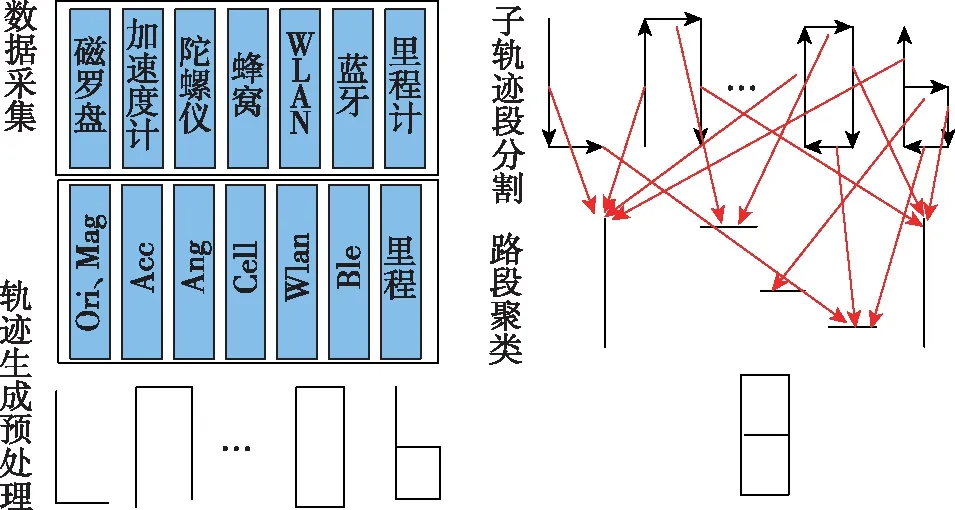
图1 众包数据处理过程Fig.1 Crowdsourcing data processing
2.1 轨迹生成预处理
原始的众包数据是由多个用户采集的原始观测数据组成的,对于任意一组观测数据,一般是时间上顺序排列的观测数据序列,把每个单独的观测序列称为一条轨迹。轨迹生成预处理是通过每条轨迹中的加速度、角速度、磁航向及里程计信息等数据,利用重采样方法对原始数据进行预处理,使得每个采样点之间的空间距离相同。对于预处理后的第i个轨迹Ti可描述为:
{Magi,Acci,Angi,Orii,CELLi,WLANi,BLEi}

2.2 子轨迹段分割
由于众包数据中包括大量用户的轨迹数据,为了便于寻找不同轨迹间的关系,把用户行驶的连续轨迹数据根据关键点划分为多个子轨迹段。
本文选用轨迹中的拐弯点作为关键点进行子轨迹段的分割。其中拐弯点的检测采用微机电系统(Micro-Electro-Mechanical Systems, MEMS)传感器中的角速度垂直分量的峰值和谷值检测方法,具体方法可参考文献[3,13]。如图 1所示,通过拐弯点检测可将一段轨迹数据切割为若干个不带拐弯点的子轨迹,子轨迹段Ri的描述方法与轨迹Ti定义相似,表示如下,将这些子轨迹集合记为R。
Ri={Magi,Acci,Angi,Orii,CELLi,WLANi,BLEi}
其中,Orii为该子轨迹的平均航向,其他定义与Ti相同。
2.3 路段聚类
路段聚类的目的是通过寻找R中各个子轨迹间的特征相似性来寻找子轨迹间的空间重叠与连接关系,从而重构出众包数据所覆盖的路径地图。本文采用DBSCAN算法对R中的各个子轨迹进行聚类,也就是将具有相似性的子轨迹段聚为一簇,每一个簇即代表一个路段,多个路段及相互之间的关联关系就代表路径地图。
DBSCAN聚类算法的核心是评估各个样本之间的距离,并将高密度的样本进行聚类[14]。本文利用特征的相似性进行子轨迹段之间的距离评价,实现高空间相似度的轨迹聚类。通过综合比较可以看出,蜂窝网络/WLAN/蓝牙的信号稳定性较差,在几十米到几百米的范围内区分度不是很明显,但其基站数量众多、覆盖广泛,更适合从大尺度确定不同路段间的重合关系,例如在多个车库、街区、隧道之间可迅速通过上述特征进行区分;相比而言,地磁特征更为稳定,适合更精细的相关性判断,例如同一车库内不同道路的区分。综上,本文分别基于蜂窝网络/WLAN/蓝牙和地磁特征,给出了任意2个轨迹Ri、Rj间的磁相关性系数Mag_cci,j和可视基站相关性系数Bs_cci,j,其中Mag_cci,j定义为2个子轨迹上磁场序列的相关系数,Bs_cci,j为2个子轨迹上公共可视的蜂窝网络/WLAN/蓝牙基站数量比例,定义如下
(1)
其中,{IDRi}表示子轨迹Ri中所有可视的蜂窝网络/WLAN/蓝牙基站ID构成的集合,| |是集合的势。
在聚类过程中,首先通过2个子轨迹段的可视基站的交集进行邻域判断,定义子轨迹Ri的基站-邻域NBs(Ri)为
NBs(Ri)={Rj∈R|Bs_cci,j≥BsTh}
(2)
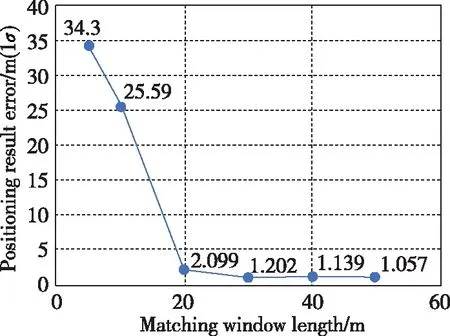
其中,0 在此基础上,在基站-邻域NBs(Ri)中更进一步地根据磁场分布的相似性进行比较和筛选,给出磁场-邻域Nmag(Ri)的定义如下 Nmag(Ri)={Rj∈NBs(Ri)|Mag_cci,j≥ MagTh} (3) 其中,0 通过上述可视基站与磁场分布的比较能够把相似性较大的子轨迹以更大概率、更小的计算复杂度聚集在通一条路段上;但同时存在另一种风险,如果在不同路段上采集的2个子轨迹由于受干扰等因素导致其可视基站及磁场强度的特征相近,则会将他们误判为同一个轨迹。针对上述风险,通过2个子轨迹邻域的重合度进行进一步的限定,最终得到e-邻域定义如下 N(Ri)={Rj∈Nmag(Ri)||Nmag(Ri)∩ Nmag(Rj)|>Cth} (4) 其中,Cth是重叠的门限值。 可以看出,对于Ri而言,若其邻域N(Ri)内的元素数量较少,说明该样本与其他样本的距离较大,应予以剔除,因此这里定义核心对象的概念:即满足|N(Ri)|≥MinPts的轨迹被称为核心对象,其中MinPts是一个门限值,主要取决于总样本数量。 基于上述e-邻域N(Ri)的定义,便可用DBSCAN算法对R中所有的核心对象进行聚类,输出簇划分结果C={C1,…,Ci,…,Ck},其中Ci表示路段,k为聚类后路段的总数量。 通过众包数据得到路段及相互的地理位置关系后,便可通过传统方式进行特征指纹库的建立。本文考虑的可匹配的特征信息包括WLAN、蓝牙、蜂窝网络的基站标识与接收的信号强度指示(Received Signal Strength Indication,RSSI),地磁场强度,以及场景信息等。其中场景信息是指和位置相关的地理特征,例如拐弯点、减速带等(文献[15]、文献[16]和文献[17]给出了这些信息的检测方法),每类特征信息的详细内容见表1。 特征指纹库建立的过程实际上是将上述特征信息与路段关联的过程,将每个路段进行网格划分,每个网格点称为一个参考点,其中相邻参考点之间的距离相同。通过重采样方式便可得到众包数据中每组数据在各参考点的采样值。由于众包数据一般是非合作用户采集得到的,虽然采集密度大,但数据质量参差不齐。因此在本文中,通过大量的样本统计,将每一类特征信息在该点的所有样本值及其分布情况存储在特征指纹库中。例如对于某一个参考点si,特征指纹库中存储的是WLAN、蓝牙、蜂窝网络、地磁场、场景在该点的众包数据值及其分布,参考点s组成参考点集合S={s1,s2,…,si,…}。 表1 特征信息分类及特征信息内容 如图2所示,多维特征联合匹配定位过程包括2个环节,分别是特征信息提取感知和匹配定位。 图2 基于HMM的多维特征联合匹配定位方法示意图Fig.2 Schematic diagram of multi-dimensional featurejoint matching method based on HMM 特征信息提取感知一方面是利用传感器直接对无线电信号、地磁等特征信息进行观测;另一方面,通过对原始观测值的提取和预处理,对场景等特征信息进行感知,并记录其对应的特征信息内容。这样,在每个采样时刻,都能提取和感知得到一个或多个上述特征信息,供在线匹配阶段使用。 将终端提取和感知到的观测信息按时间先后顺序进行排列得到观测序列O=(o1,o2,…,oi,…),其中相邻2个测量量之间的距离可通过里程计得到,匹配定位需要解决的问题是在指纹数据库的诸多参考点中寻找一个参考点序列S和序列O相匹配。显然,根据车辆运动的特点,序列S符合马尔科夫特性,因此这个过程可以用HMM来描述和求解。 HMM的参数包括可观测状态、隐含状态、初始状态矩阵、转移概率矩阵和输出概率矩阵[18]。如图3所示,本文将每个采样时刻的观测信息oi作为HMM中可观测状态,O为观测状态的集合;将离线数据库中的每个参考点si作为一个隐含状态,组成隐含状态集合S。初始状态矩阵在初始定位时刻可简单认为用户处于每个参考点的概率相同。各隐含状态之间的转移概率用转移概率矩阵A表示,其中aij表示从状态si转换到状态sj的概率,显然aij与si和sj这2个状态点之间的距离相关,设2个状态点间的真实距离为dij,实际量测得到的2个特征信息间的距离l与dij越接近,这2个参考点之间的转移概率越大,反之越小。因此,本文将转移概率简化成高斯模型,即aij=P(dij),其中dij服从N(l,σ)的高斯分布,σ为里程计的误差方差。输出概率矩阵B中的输出概率bjk=P(ok|sj)表示由隐含状态sj表现为可观测状态ok的概率。输出概率描述了数据库中的任意一个参考点表现为当前观测到的特征的概率,bjk可通过前述的数据库查表计算得到。 图3 HMM参数Fig.3 HMM parameters (5) 其中,λ为图3中涉及的模型参数,S=(s1,s2,…,si…,sL)为S中任意L个参考点的排列。 P(S,O|λ)=P(O|S,λ)×P(S|λ) (6) 对于式(6),通常采用维特比算法(Viterbi Algorithm)进行求解[19,20]:在少量数据情况下可采用穷举方法,但当数据库中存储的参考点较多或序列较长时,计算复杂度会很高[21];本文采用了递归算法寻找这一最可能的序列[22]。首次(即t=L),能够经概率计算,找到用户当前的位置。后面采用滑动窗口形式,采用同样的方法进行匹配,以不断得到用户的实时位置。 为了对本文所设计的基于众包数据的构图方法性能进行验证,论文通过实测和仿真结合的手段进行了分析。如图4所示,利用华为MATE10手机通过实际跑车在北京市海淀区航天城周边区域获得了图示轨迹上的2组数据。试验区域中共包含4个路段,采集数据包括WiFi、蓝牙、蜂窝、地磁以及行进过程中的MEMS数据,在此基础上通过计算机模拟仿真方式得到80组观测数据来模拟众包轨迹,进而进行聚类构图。 在仿真中设置MinPts为5,Mag_cc和Bs_cc这2个聚类参数在[0,1]不同取值组合时,对聚类算法的准确率进行评估,这里聚类准确的概念是:对于任意一个轨迹,如果该轨迹被划分到的簇中的其他轨迹均与该轨迹产生于同一路段,则被认为是准确,否则被定义为错误。通过对众包数据中所有轨迹样本进行统计,便可得到聚类的准确率。 在图5中,当MagTh在[0.7,0.95]之间取值,BsTh在[0.6,0.9]之间取值时,可以得到较高的准确率,可以看出,当其中一个约束条件降低时,可以通过增强另一个约束条件来提高聚类的准确率。因此,在某一类特征干扰严重的情况下,能够通过另一种特征来提升聚类性能。 图5 聚类准确率和可视基站相关性系数门限MagTh与磁相关性系数门限BsTh之间的关系Fig.5 Relationship between clustering accuracy andthresholdsMagThandBsTh 测试中当BsTh=0.3、MagTh=0.8时,聚类准确率最高,为95%,具体情况如表2所示。通过80个子轨迹段得到4个聚类簇,分别对应于不同的路段,在聚类过程中共产生了4条噪声轨迹,聚类准确率能够达到95%,证明了该算法具有较好的分类性能。 表2 聚类结果 针对多维特征联合匹配定位性能分析,论文通过实际道路采集数据进行了试验分析。需要说明的是,由于试验过程中难以获得实际的众包数据建库,同时为了准确分析所提多维特征联合匹配方法的性能,试验分析中采用了高精度地图进行建库。试验路段全程约10km,包括普通道路、桥梁、高速路、小区道路等典型路段,用于比对分析的位置基准设备采用Novatel 100C设备。 基于HMM的特征匹配实际上是通过一个窗口内多个特征点的联合匹配来提高单特征点匹配的定位精度,因此定位性能与匹配窗口的长度密切相关。由于大多数传感器的观测量是按时间间隔均匀输出的,为便于描述和理解,第3节中观测序列O被定义为时间窗口长度为L的时间段内的观测序列。但考虑车辆在运动过程中包括低速、静止等状态,固定时间窗口L内的观测量实际上是冗余的(例如在静止状态下观测到的特征序列不变),因此在试验中,通过里程计信息将观测序列O定义为车辆行进某一个距离窗口L*内的的观测量序列。图6描述了在不同匹配窗口长度时统计的定位误差,可以看出,当匹配窗口长度从5m提高到20m时定位性能会快速收敛到2m左右,但再增加窗口长度时匹配精度的提高变得有限。实际上,随着窗口长度的增加,维特比算法译码的复杂度会显著增大,计算效率会大大降低,在实际应用中需要对定位精度和计算性能间折中考虑。 图6 匹配窗口长度对定位精度的影响Fig.6 Effect of matching window length onpositioning accuracy 本文针对车辆在GNSS拒止条件下的定位问题,提出一种通过多种异构特征信息源进行联合匹配定位方案,并给出了基于众包数据的特征建库方法和基于HMM的多源特征匹配方法。本文所提方法的特点在于:(1)设计了一种基于地磁和无线网络信号等多种位置关联特征的众包轨迹聚类方法,能够从无位置标定的众包数据中提取出复杂场景中的路径地图与位置信息;(2)设计了一种面向多种异构特征信息的联合匹配方法,该方法基于HMM模型,能够将无线电强度指纹、地磁场信息以及地图信息等多种信息进行联合匹配来进行位置估计。试验分析表明,该方法能够充分利用多种物理场特征,在GNSS不可用环境下提供定位服务。下一步工作主要包括针对隧道、室内等不同场景特点,进一步提升聚类算法的适应性和准确性,以及研究匹配算法对于横向不同车道的区分能力并做相应的算法优化。2.4 数据库建立

3 基于HMM的多维特征联合匹配定位方法


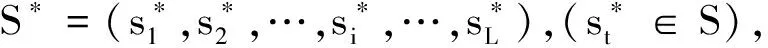
4 试验与仿真
4.1 众包数据构图方法性能仿真


4.2 多维特征联合匹配定位性能试验分析
5 结论
