基于MSER和SVM以及强种子区域生长的车牌定位
2019-05-07侯向宁刘华春
侯向宁,刘华春
(成都理工大学工程技术学院 电子信息与计算机工程系,四川 乐山 614007)
0 引 言
在车牌识别系统中, 车牌能否精确定位至关重要。 传统的车牌定位方式可以分为基于灰度图像和基于彩色图像的定位[1]。基于灰度图像的车牌定位, 其思路是首先把彩色图像转换为灰度图像, 然后通过对灰度图像进行相关处理以定位车牌。 该方法的优点于计算量小、速度快、实时性较好,缺点是复杂背景下定位的效果不理想。基于彩色图像的色彩分割利用车牌的颜色特征定位车牌,其优点是复杂背景下车牌定位的效果很好,缺点是色彩分割时的计算量比较大,因而实时性较差[2]。
文献[3]利用边缘检测算法进行车牌粗定位,然后提取颜色纹理特征并输入分类器,以实现精确定位;文献[4]利用边缘检测并结合形态学,从而得到连通的车牌区域;文献[5]先利用彩色图像的颜色特征对车牌图像进行粗定位,再利用边缘检测算法提取车牌区域;文献[6]利用最小生成树将图像转化为图论中的图,将获取到的车牌候选区域进行训练,从而识别出车牌区域。
以上车牌定位方式,在特定的场景下表现非常好,但对低光照、低对比度等自然场景下,很难同时保证车牌定位的准确性、实时性和鲁棒性。MSER被广泛用于自然场景图像本文的识别,然而很少有人将其与机器学习相结合用于车牌定位。本文在传统MSER算法的基础上做进一步的改进,并结合机器学习的SVM算法,使车牌定位在复杂自然场景中的准确性和鲁棒性得到进一步提高。
1 传统车牌定位方法
1.1基于彩色图像的定位
彩色图像因携带有丰富的颜色特征,常用于车牌定位。由于RGB颜色空间不能基于人眼感知特性[7-9],因此,通常先对颜色空间进行转换,比如转换为HSV颜色空间然后对彩色图像进行分割定位。实践中发现,采用颜色空间模型后,在光照适当、色彩充足的情况下,车牌定位的效果非常好。缺点是当光照不均,特别是在低光照、低对比度场景下,定位效果较差。此外,当车牌与车身颜色相近时,经过颜色空间转化为二值图像后,车牌与背景完全连在一起,定位效果差强人意。
1.2基于灰度图像的定位
1.2.1 基于边缘检测的车牌定位 原理是将彩色车牌图像灰度化后,突出字符边缘及背景灰度剧烈变化的区域以实现定位。该方法的优点在于计算量小,实时性较好,抗噪性也较好,并且一次识别可以进行定位多张车牌;缺点是在背景稍复杂,垂直边缘交错的场景下得到的区域比车牌要大的多,效果很不理想。
1.2.2 基于纹理特征的车牌定位 原理是将彩色车牌图像灰度化后,按照行、列进行扫描,统计车牌图像灰度的跃变次数,与预先设置的阈值进行比较,最终实现车牌的定位。该方法抗噪性较差,在背景稍复杂,车牌与车身的纹理特征相近时,效果很不理想。
1.2.3 基于形态学的车牌定位 原理是对图像进行灰度化及二值化后,根据车牌字符特征确定形态学结构元素的大小,利用数学形态学运算中开、闭操作得到车牌候选区域[10], 然后去除非车牌区域,最终得到车牌区域。 该方法的缺点是结构元素的大小不好选取,过大会引入噪声, 过小则无法确定连通区域。
1.2.4 基于机器学习的车牌定位 首先,收集车牌样本集,然后用机器学习算法对车牌样本集进行训练直至算法收敛,最后用训练出来的算法模型对车牌进行定位。该类算法优点是具有自适应和自学习能力,在光照不均等复杂场景下也能精确定位车牌,具有较强抗噪性和鲁棒性。缺点是训练过程中容易陷入局部最优。
通过上述分析可知,传统的车牌定位算法在复杂的自然场景下差强人意,而机器学习算法具有自适应和自学习能力,可以通过参数调优以及调整算法结构来解决复杂问题。
2 基于MSER的车牌定位
MSER因其具有良好的仿射不变性、抗噪性、实时性、高回召率及稳定性而被广泛应用于自然场景下文本的定位[11-12]。首先将彩色图像转化为灰度图(灰度值为0~255),然后对灰度图像分别用[0,255]连续阈值进行二值化。在阈值由小至大的过程中,遍历图像中的每一个像素灰度值,将像素灰度值小于阈值的点置为黑色,像素灰度值大于阈值的点置为白色。在得到的所有二值图像中,图像中的某些连通区域变化很小,甚至没有变化,则该区域就被称为最大稳定极值区域[13-14]。
图1展示了阈值递增过程中,所生成的部分二值化图像,其中左上角是原始彩色图像,白色图像代表阈值为0时的二值化图像,右下角黑色图像是阈值为255时的二值化图像,观察其余几个图像在阈值逐渐递增的过程中,所生成的黑色连通区域就是最大稳定极值区域。

图 1不同阈值的二值化图像Fig.1 Image binarization of different thresholds
MSER虽然被业界广泛用于自然场景下文本的检测,然而MSER的高回召率也检测到了很多不是文本的区域,这是基于MSER 区域进行文本定位的最主要挑战之一。
2.1MSER文本检测流程
对传统MSER的算子做进一步改进,使其能在线性时间内完成对图像 MSER 的运算。并在此基础上,将MSER算子和SVM算法相结合,以提高其在复杂自然场景中定位的准确性、实时性以及鲁棒性。MSER文本检测的流程如图2所示。
在图像预处理阶段,首先对原始图像进行高斯去噪处理,然后将其灰度化,以便为MSER算子做准备。MSER阶段获取字符区域,由于其高回召率将一部分非字符区域也当成字符区域,因此,首先通过尺寸判断,将明显不是字符区域的稳定极值区剔除,剩余的候选字符区里仍然会有非字符区域,但已经不能通过尺寸来判断了。所以可将其输入SVM字符区域识别模型进行剔除,最后对得到的字符区域进行组合,最终得到精确的车牌区域。
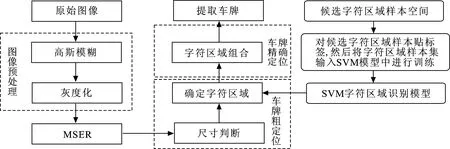
图 2MSER文本检测的流程Fig.2 The text detection process of MSER
2.2车牌粗定位
首先进行尺寸判断,获取多个候选车牌字符的MSER,这些MSER中既有车牌字符区域,也有非车牌字符区域。尺寸判断所要做的就是从中剔除明显不是车牌字符的区域。根据我国车牌的特点,利用字符区域的高宽比和占空比可以将明显不是字符的区域剔除,具体流程如下:
(1) 计算候选车牌字符区域的外接矩形。
(2) 计算候选车牌字符区域的面积Area,即矩形区域内灰度值为零的像素点的个数。
(3) 计算字符的高宽比f=h/w,其中,h表示字符区域的高,w表示字符区域的宽,如果f不在[1.5, 2.5]范围内,则可剔除该区域。
(4) 计算字符区域的占空比p=A/(hw)。如果p不在[0.2, 0.7] 范围内,则可剔除该区域。
(5) 去除重叠矩形区域。通过第(3),(4)步可以剔除明显不是字符区域的的部分,因为MSER采用的是连续阈值的二值化,在这一过程中,会产生许多重叠的矩形区域,这些重叠的矩形区域会对之后的字符区域组合产生不利的影响,因此需要剔除。经过大量实践,发现如果2个矩形区域R1,R2,满足条件SR1∩R2/SR1∪R2≥0.5,则保留R1,除去R2,其中S代表的是并或交运算之后的面积。
(6) 最后将第(5)步得到的候选字符区域输入已经训练好的SVM分类器进行分类[15-16],最终剔除非车牌的字符区域。显然,SVM分类器的分类效果的优劣将直接影响本步以及下节将要进行的车牌精定位的效果。要利用SVM模型对候选字符区域进行分类。首先,收集第(5)步中得到的候选字符区域,并将其归一化为16×32像素。手工将其分为hasChar(字符区域)和noChar(非字符区域)。其次,要取得好的分类效果,还需要选取适合的核函数。本文采用直方统计来提取输入数据的特征,每个样本有16行,32列共48个维度,训练样本的数目是4 200张。由于输入数据特征的维度比较小,而训练样本的数量较大,因此选取径向基核函数做为SVM模型的核函数。这样就将每个数据的维度转化为4 200维,可以充分利用髙维的线型分类带来低维空间下的非线性分类效果的优势。最后,利用Opencv的svm.train-auto()函数设置相应的参数,然后一步一步自动调优,最终获取到分类效果最好的参数。
2.3车牌精确定位
精确定位就是将车牌字符区域组合成连通域的过程,为了达到良好的聚合效果,本文采用基于强种子的区域生长方法[17-20],具体算法如下:
(1) 将SVM分类结果概率大于0.9的设为强种子,在图3中用绿色框表示。
(2) 将相邻的强种子进行合并,并标出穿过这些强种子中心的直线,在图3中用白线表示。
(3) 在中心线的附近找SVM分类结果概率大于0.65且小于0.9的弱种子进行合并,在图3中用蓝色框表示。
(4) 通过每个方框中心点之间的距离来找出夹在中间的SVM分类结果概率小于0.65的字符区域进行合并,在图3中用橙色框表示。
(5) 统计绿色框、蓝色框和橙色框的个数n,如果n=7则生长结束;如果n<3可判定为不是车牌区域;如果3≤n<7则说明有缺失的字符,即通过MSER算子无法提取到,这时可以通过增加一个滑动窗口来寻找这些缺失的数字、字母或者汉字字符区域。第一步,统计绿色框、蓝色框、橙色框以及红色框(如果有的话)的总数n。如果n=7就结束;如果3≤n<7则进入第二步。第二步,对绿色框、蓝色框、橙色框以及红色框按位置进行排序。显然,缺失的字符只能在所有框所组成区域的两侧,即第一个框的左侧或最后一个框的右侧。在正常情况下,相邻两个字符区域间的距离是相等的,这里将其记为d。先将滑动窗口移到距离最后一个框的右侧为d的位置,并将滑动窗口所在的区域送入SVM分类器。如果分类结果大于0.6,就认为是缺失的字符,在图3中用红色框表示。否则,将滑动窗口移到距离第一个框的左侧为d的位置,并将移动窗口所在的区域送入SVM分类器。如果左右两侧均未找到缺失的字符,并且所有框的个数之和是5,则表明缺失的是车牌分隔符前的字符,即整个车牌中的第二个字符,这个时候将滑动窗口移到距离第一个框的左侧为1.22d的位置,并将移动窗口所在的区域送入SVM分类器。同样,若分类结果大于0.6,就用红色框表示。然后跳至第一步进行下一次的循环,直至n=7为止。
(6) 最后,将所有7个框所在的区域进行合并,并求其外接矩形,在图3中用大的红色矩形表示,即为最终提取到的精确车牌区域。

图 3车牌精确定位Fig.3 The accurate location of license plate
3 结果与分析
为了测试本文方案对不同场景下车牌定位的准确性以及鲁棒性,随机选取不同场景下的彩色机动车图像3 000张。从这3 000张图像中随机抽出1 000张图像,对其依次进行字符区域的高宽比和占空比以及重叠区域判断,从而得到候选车牌字符区域,并将其归一化为16×32的图像样本集合。手工从这些16×32的样本集合中挑选出2 000张的字符区域和4 000张的非字符区域。并分别拿出其中70%做为训练用,剩余30%用来进行测试。然后手工将贴好标签的字符区域样本集输入SVM模型中进行训练,直至各参数调至最优。将剩余的2 000张彩色机动车图像分成白天(386张),晚上(403张),阴天(392张),雨天(411张),雾天(408张)5组场景来进行实验。
首先采用文献[4]中基于Sobel算子边缘检测和数学形态学的定位方法进行实验,实验结果如表1所示。
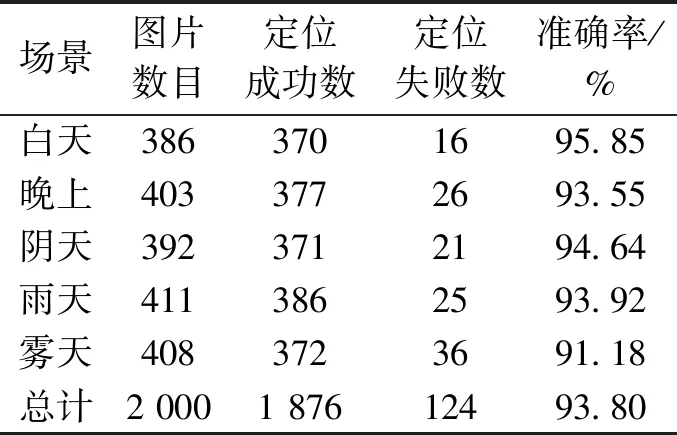
表 1各场景下的实验结果1Table 1 Result one in various scenarios
然后采用文献[5]中基于颜色特征和改进Canny算子的定位方法进行实验,实验结果如表2所示。
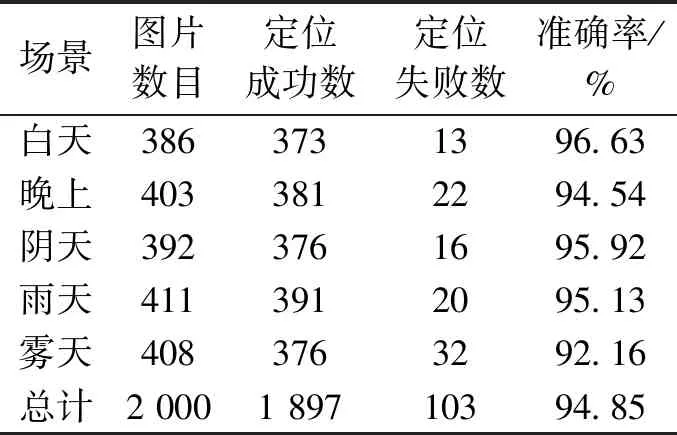
表 2各场景下的实验结果2Table 2 Result two in various scenarios
最后采用本文基于MSER和SVM以及强种子区域生长的车牌定位的方法, 进行实验, 相关实验参数的选取依据 2.1和2.2节。 实验的结果如表3所示。
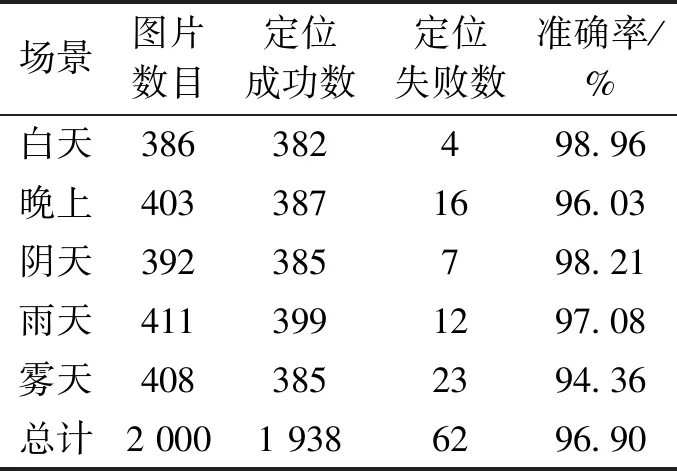
表 3各场景下的实验结果3Table 3 Result three in various scenarios
从实验结果可以看出,本方案不仅在正常光照条件下的定位成功率非常高,接近99%;而且在阴天、晚上光照不强及光照不均场景下的平均识别率也达到96%以上,比文献[4]高出3%以上,比文献[5]高出近2%。在雨天、雾天等复杂场景下的平均识别率95%以上,比文献[4] 高出近3.2%,比文献[5]高出近2.1%。综合各场景下的情况,本方案的平均识别率接近97%,比文献[4] 高出近3.1%,比文献[5]高出近2.05%。实验表明,本方案在各种场景下都具有很强的适应性和鲁棒性,定位成功率非常高。
4 结 语
本文将自然场景下的文本识别算法MSER和SVM算法相结合。首先利用MSER得到最大稳定极值区域即候选字符区域,然后对候选字符区域及位置关系进行进一步分析,剔除较明显的干扰区域,接着利用SVM算法筛选出最终的字符区域,最后通过聚合字符区域提取出精确的车牌位置。通过对比实验表明,该方法在不同场景下的定位准确率都有很好地表现,其自适应能力和鲁棒都较好,具有较好地适用性。
