基于分块处理的2D图像并行绘制技术
2019-04-26吴振华
文/吴振华
1 引言
在近年来,随着计算机技术的快速发展,带动了各种各样不用功能的应用软件面世,随着软件越来越绚丽漂亮,对计算机性能的要求也越来越高,而计算机性能很大一部分的性能开销是在图像处理方面,在通常情况下,为了获得更高的图像处理性能,往往是依赖更快速的GPU处理(GPU英文全称Graphic Processing Unit,中文翻译为“图形处理器”)。而高性能GPU往往都是功耗最高的部件之一,平均功率甚至超过CPU功耗,而与此同时,CPU的性能在大多数情况下却出现“性能过剩”的情况,尤其是多核CPU,如今大多程序都只利用到单核,而Intel公司创始人之一戈登·摩尔曾经提出著名的摩尔定律在多核CPU时代已经几乎走到尽头,也就是说,基于单线程的应用效率的提升已经不能再依赖于CPU单核性能的提升,必须使用合适的并行技术和算法,最大限度的发挥多核CPU的优势,才能使得应用程序的效率成倍提升。
从日常的应用软件不难看出,90%以上都是基于2D形式的表现和设计的,剩下很少的部分以3D的形式表现的。如果在这90%以上的应用中,我们能在不增加或者几乎不增加CPU负担的情况下利用CPU完成这些绘图的处理,就可以不必给GPU增加计算量产生功耗上的浪费。而这些软件的功能不管多么复杂,最终与人交互的时候都会通过GUI(Graphical User Interface,图形用户界面)来表现,而这些内容从画面的直观来看,无非就是一堆点,线,图片和文字之类通过各种方式组合在一起形成特定的表现形式。其中最具有丰富表现的就是图片了,无论我们看到多么绚丽的效果,无非就是图片的各种混合,缩放,旋转等等方式组合而成。在传统的方式下,比如Windows平台,大量应用程序都采用微软 的MFC(Microsoft Foundation Classes)来实现绘图,而这些都是采用GDI(Graphics Device Interface,图形设备接口)实现,这些方式虽然非常简单,灵活,但是比较遗憾的是在上层的应用开发中,没有办法修改底层实现,在绘图的时候也都只能不可避免回到单线程进行处理,从而不能使效率最大化。而多核并行计算技术是当前计算机领域的研究热点。多核中的并行分为指令级并行 (instruction-level parallelism,ILP) 和线程级并行 (thread-level parallelism,TLP),而线程级并行被普遍认为将是下一代高性能处理器的主流体系结构技术。随着多核计算机的普及,线程级并行计算已经广泛用于计算机科学的多个领域,也正引领着程序设计由串行到并行的基础性变化。所以文章从线程级并行的角度出发,在软件层面上论述并实现了并行的绘图方式。
2 方法
2.1 计算机图像处理的原理
计算机图像处理的原理如图1所示。

图1

图2

图3
通常来说,计算机中CPU、GPU、显示屏幕是以上面这种方式协同工作的。CPU计算好显示内容提交到 GPU,GPU渲染完成后将渲染结果放入帧缓冲区,随后视频控制器会按照帧缓冲区的数据,经过可能的数模转换传递给屏幕显示。而对于程序来说,绘图循环如图2所示。
如何在这个绘图循环中,优化绘图机制,减少执行开销,提高运行效率,是文中主要讨论的问题。
2.2 绘图处理流程
从日常应用的软件我们知道,在很多情况下,每一帧的画面变化的时候,或许并不是屏幕内所有区域的画面都变化了,比如点击一个按钮,就只是这个按钮做了一个变化表示这个按钮的状态变成“被按下了”,而与此同时,屏幕的其他部分是不需要做改变的,如果能把这些不需要改变的部分做标记,在每一帧刷新时候跳过这些计算,那么性能将会得到很大提高。
如图3,以绘制图片为例:有A,B两个图片,绘图顺序为A-B,在传统的方式下,每一帧画面需要刷新的时候,都要重新绘制AB的全部部分,哪怕AB的绘图属性都不发生变化,或者只是A或者B发生了变化都需要这么做。而明显地看出,在AB都没变化的时候,AB是不需要重新绘制的,如果A发生变化,也只需要重新绘制A和B∩A的部分。所以我们要把需要绘制的部分描绘为“需要更新”,不需要重绘制的描绘为“保持不变”,保留上一次绘图的内容即可,只需要处理“需要更新”的部分即可。
为此,我们把整个屏幕区域划分为M个固定的子区域,只要这个与这些子区域相交的绘制属性发生变化,就重新绘制与这个子区域相交的图片的交集部分。如图4。
绘图顺序是A-B,如果A的绘图属性发生发生变化,与A相交的子区域会被重新绘制,对于上图来说,需要绘制的部分有:A ∩ A11,A ∩ A21, A ∩ A12, A ∩ A22,B ∩ A22。不需要重绘制的有:B ∩ A32,B ∩ A23,B ∩ A33。
这样划分子区域的好处,在于对于子区域变化后计算。设有n个需要绘制的图片,最坏情况下,每个图片与M个固定子区域相交的部分,计算也只是M*n,由于M是一个固定常数,它相对于n而言都很小,所以可以认为这个计算的时间复杂度为O(n)。而且每个子区域是固定的范围,所以每个子区域的计算都可以作为一个独立模块,也就很自然和直观的看出这个方式非常适合多线程的并行处理,发挥多核处理器的最大性能。

图4

图5
3 实现与结果讨论
3.1 从上层绘图过程到底层绘图命令
对于上层的软件开发来说,如果要显示一个图片,或者一个文字,或者绘制一些点,线之类,是不去关心底层是如何处理的,也没有必要关心。所以,底层做的一切,都是为了上层在不需要了解细节的情况下,就能实现高效率的绘图方案。为此,需要构建一个从上层到下层的桥梁,也就是在上层调用绘图处理的时候,需要转换为底层命令,要实现这一目的,需要定义一系列的绘图命令,每一个命令对应的数据结构,以及一个管理命令的命令池结构,最终目标是把各种绘图命令做一个队列化的操作,以便在绘图的时候能顺序进行处理。流程如图5。

图6
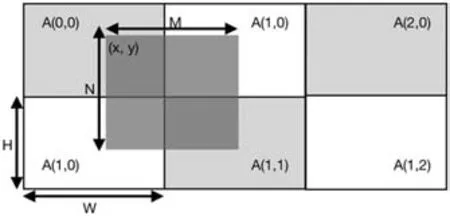
图7
3.2 分块子区域的逻辑
在3.1的基础上,把整个绘图区域划分为若干个子区域,由于每个子区域的数据是不重叠的,所以能非常方便的用于并行处理。对于每个子区域,使用两个命令队列,一个是“当前帧的绘图命令队列”,一个是“上一帧的绘图命令队列”,每一帧开始的时候,清空当前帧绘图命令队列,再逐渐添加当前帧的各种绘图命令,这样设计的目的,是用于判断当前帧的绘图命令队列和上一帧的绘图命令队列是否完全一样,如果完全一样,就说明这个区域没有改动,是不需要重新绘制的。如果不一致,则需要做绘图处理。如此完成操作之后,交换当前帧和上一帧的绘图命令队列指针,继续往返循环。对于每个子区域的工作机制如图6。
3.3 绘图指令分配到子区域
要把上层绘图的指令分配到每个相关的子区域,先看最简单的方式:
如图7,假定每个子区域大小为W x H, 有一个 M x N 大小的图片贴在了x, y的位置,那么该图片与图中的4个子区域都有交集,所以A(0,0), A(1,0), A(1,0), A(1,1)这几个子区域都需要把这个图片的绘图命令添加到自身的绘图队列。绘图的时候,只需要处理这个图片与每个子区域范围交集的部分就行,相当于把绘图的范围精确的分配到每一个子区域,对于其他的情况,比如绘制一段线段,一批点集之类的图片数据,均可用类似的方式,把对应的数据按照不同的方式进行切割,分配到对应的子区域内,再做不同的数据处理,得到的每个子区域需要绘制的内容就是一个互不相交的结果,组合起来就得到了整个完整的绘图区域。

图8
3.4 线程工作池
到此为止,已经得到了所需绘制的一系列子区域中的各种绘图命令,为了实现并行的计算,文中设计了一个工作线程的集合,如图8。
工作原理如下:
把需要重新绘制的n个子区域做成一个队列,如图8 A1-An,假定有3个工作线程做处理,最开始的时候,选取A1,A2,A3分别进入每个工作线程,并把它们从队列中删除,然后工作线程开始进入工作状态,由于每一个子区域的计算量都不一样,所以每个工作线程的完成进度有快有慢,比如计算A1的工作线程完成了,便可以继续从队列里面寻找下一个子区域重复上述过程,如果队列为空,且所有工作线程都工作完成,就说明本次并行处理全部完成了,也就代表这一帧的画面整体处理完成。
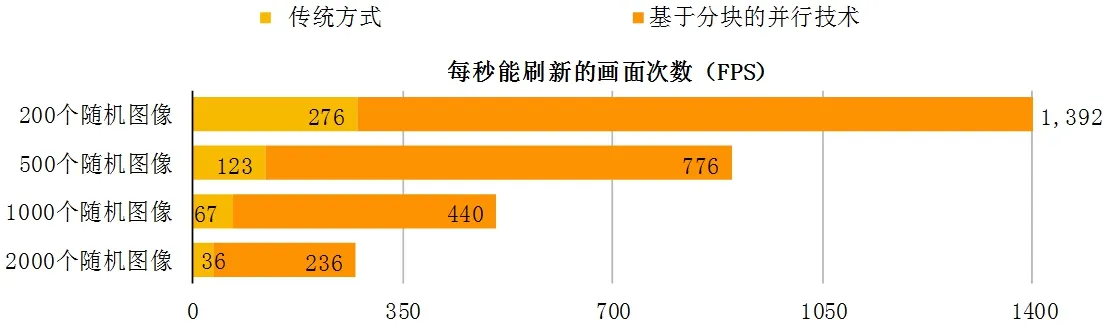
图9
3.5 运行测试
在并行计算领域,加速比用于表示当并行算法与对应的顺序执行算法相比较时,速度快了多少。加速比以如下公式定义:

其中p指CPU数量,T1指顺序执行算法的执行时间,Tp指当有P个处理器时,并行算法的执行时间。当Sp=p时,Sp便可称为理想加速比。意味着若将处理器加倍,执行速度也会加倍。由加速比派生出来的加速效率则是度量性能的指标,定义如下:

加速效率Ep的值一般介于0~1之间,表示在解决问题的时候,参与计算的处理器得到了什么程度的充分利用,如果加速效率Ep>1则称为超线性加速比。
测试平台:
CPU:Intel Corei7 6700K @4.00GHZ
主板:技嘉GA-Z170-HD3
内存:海盗船DDR4-2133 @16GB
硬盘:三星850EVO@250G 固态硬盘
显卡:七彩虹 GTX1070 8G显存
操作系统:Windows10 专业版
在1024x768 分辨率下,使用传统方式(单线程,无分块处理)与分块处理的并行绘制技术的方式快速刷新随机显示图片(注:图片规格为128x64和81x100的图片),如图9所示,得到如下结果:
不锁定刷新率,让程序每秒钟尽可能的刷新多次,记录如下:
可以计算出这个条件下的加速效率E8分别为:63%, 79%, 82%, 82%,平均加速效率=76.5%
4 总结
传统的绘图方式既不能利用并行处理让CPU利用最大化,也不能通过分块处理技术减少计算量,而基于分块处理的并行绘制技术,在CPU利用最大化的同时,也能优化的减少计算量,在单位时间内承载的计算量更多,同等计算量下耗费的时间最少,大大提高了多核CPU的加速效率,所以是一种很值得推广的技术,尤其在绘图密集型领域比如游戏领域能大大发挥加速作用。虽然该技术在纯CPU处理下和传统方式对比取得了很好的效果,但是遗憾的是,该技术还不能让GPU进行类似并行化处理并和传统的方式进行比较,如果今后能利用GPU进行分块并行处理的话,相信性能还会比传统方式提升一个很大的台阶。
