基于半参数统计模型的弗明翰心脏病数据研究*
2019-04-17李静
李 静
(南京理工大学 理学院,南京 210094)
0 引 言
现今社会,越来越多的人患有冠心病或心脑血管疾病,此类疾病对人类健康存在极大威胁,所以心脑血管疾病的研究越来越受到重视。很多学者对弗明翰心脏病数据进行过建模分析,Carroll等[1](1997)指出线性logistic模型不能准确地捕捉到一些信息,所以他们将利用部分线性logistic模型对弗明翰心脏病数据进行拟合,得到较合理的结果:心血管疾病事件(CHD)与年龄(AGE)存在非线性关系,与血压(SBP)和胆固醇(SCL)存在线性关系。Yang等在对含有测量误差的单指标模型的研究中,将血压(SBP)作为响应变量,年龄(AGE)和胆固醇(SCL)作为指标变量研究三者之间的关系。本文也将对相应变量进行建模分析。

1 数据介绍
弗明翰心脏病数据一共1 615个样本,包含5个变量,变量意义见表1,相关数据可见Kannel[8]。首先通过散点图分析年龄(X1)和胆固醇(X2)与血压(Y)的关系。从图1,图2中可以看出,血压(Y)与年龄(X1)和胆固醇(X2)存在非线性关系,其相关系数矩阵如表2。从散点图中只能粗略地判断出血压(Y)与年龄(X1)和胆固醇(X2)的关系,血压(Y)与年龄(X1)和胆固醇(X2)均存在非线性关系。为了更准确地挖掘出隐藏在相关数据中的信息,进一步针对具体的模型:单指标和单指标变系数模型来对数据进行拟合。

表1 弗明翰心脏病数据变量

图1 Y与X1的散点图
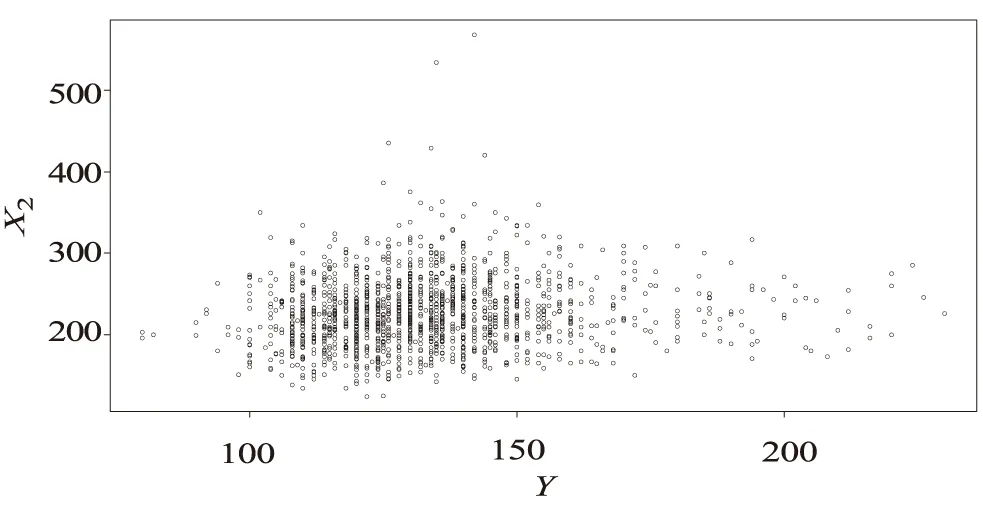
图2 Y与X2的散点图

表2 相关系数矩阵
2 模型分析
单指标模型具有形式:
Yi=g(βTXi)+εi,i=1,2,…,n(1)


当g(·)已知时,β的最小二乘估计是极小化目标函数式(2)。
(2)
这里首先将β再参数化,使用通常的关于β的“去一分量”方法,此时式(2)等价于方程组
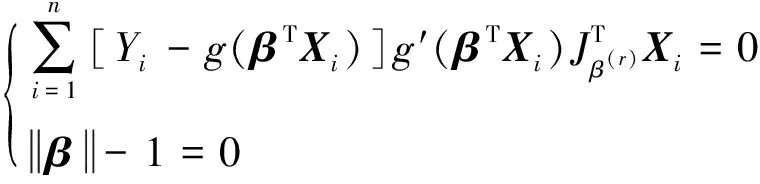
的解。这里由于g(·)及导数g′(·)是未知的,所以需要寻找估计量代替它们,使用局部线性回归来拟合g(·)和g′(·)。对v的某一邻域内的点V,使用一个线性函数局部地逼近g(V),即
g(V)≈g(v)+g′(v)(V-v)≡a0+a1(V-v)

的解。
单指标变系数模型考虑:
Y=gT(βTX)Z+ε
3 模型拟合
采用Carroll在1997年研究的弗明翰心脏病数据,共有1 615个样本量,5个变量,本文选取其中4个变量进行研究。其中Y代表血压(SBP),X1代表年龄(AGE),X2代表胆固醇(SCL)Z代表,抽烟事件(Smoke Status)。将数据应用于单指标模型Y=g1(β1X1+β2X2)+ε和单指标变系数模型Y=g2(β1X1+β2X2)Z+ε。首先为了计算的准确和方便,对指标变量进行处理,将其转化到[-1,1]的区间上。非参数局部回归的估计涉及带宽的选择。这里利用Epanechnikov核函数,通过交叉核实(CV)验证方法选取的带宽h进行估计。选取的h=0.058 9,h1=0.230 9,单指标模型指标参数的估计值为
拟合结果如图3所示。
单指标变系数模型指标参数的估计值为
拟合结果如图4所示。

图3 g1(·)的估计
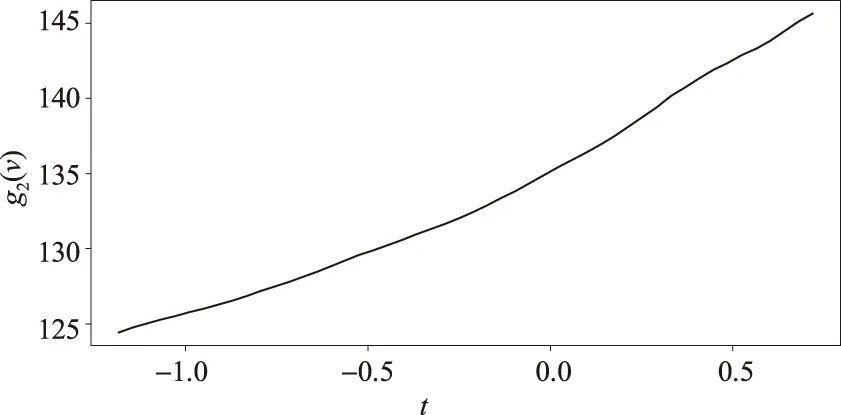
图4 g2(·)的估计
从图3和图4可以看出,单指标模型和单指标变系数模型都能较好地拟合弗明翰心脏病数据。
4 结 论
本文中的两个模型都能较好地拟合弗明翰心脏病数据,但单指标变系数模型比单指标模型多考虑了一个因素,所以相对来说,单指标变系数模型比单指标模型更能准确地反映出数据内部隐藏的相关信息。当然,还有很多的其他模型可以拟合此数据。另外,本文处理的是数据测量准确的情形,还有很多时候数据的测量并不精准,即所谓的测量误差数据,测量误差数据也是统计学方向经常研究的一类数据,这时也可以用本文的模型进行研究。
