交通事故的自动判案研究
2019-04-17尹何举昝红英陈俊怡翟新丽
尹何举,昝红英,陈俊怡,翟新丽
(1. 郑州大学 信息工程学院,河南 郑州 450000; 2. 郑州大学 法学院,河南 郑州 450000)
0 引言
自动判案是针对一个案件的事实描述给出一个判案结果,例如杀人、盗窃和交通肇事等。对每一个案件判案而言需要分析案件的事实描述文本,找出事实描述文本中相同的特征。主流的处理过程为查找相似案件或者律师根据自己的专业知识对文本中的关键词等特征进行分析,因此可以将让机器对案件进行自动判案看作是对法律文本的研究。现阶段关于自动判案的研究也主要被当作自然语言处理中的文本分类任务,对事实文本进行分析找到文本的特征,根据提取到的特征找寻特征和判案结果之间的映射关系。
文本分类是自然语言处理中的一项基础研究。近年来,深度学习技术逐渐取代基于传统机器学习的方法,成为文本分类领域的主流。深度学习在自然语言处理领域的突破以Mikolov、Bengio等人[1-2]为代表提出的神经语言模型,如CBOW和Skip-gram等。通过神经语言模型如Word2Vec提供词向量让神经网络在文本分类中有了更好的表现。
传统机器学习主要使用支持向量机(Support Vector Machine,SVM)、k近邻算法(k-NearestNeighbor,kNN)、朴素贝叶斯方法,其中SVM算法由于核函数的使用在文本分类上取得较好的应用。
深度学习中循环神经网络的出现对文本分类问题有较好的帮助,通过循环神经网络去学习词和词之间的上下文关系,词和词之间不再独立。同时近些年来借鉴人类视觉注意力机制(Attention Mechanism)将注意力机制引入神经网络中,在文本分类时,可以通过学习上下文信息的权重来生成文本表示。这样可以进一步提取特征,提升神经网络学习中的效果。
本文通过使用传统机器学习SVM算法、循环神经网络和基于注意力机制的循环神经网络的模型来进行自动判案的研究,并比较分析三种模型的实验结果。
1 相关工作
近几年来,随着词向量的引用,文本可以很好地表示成词向量序列,这就为各种神经网络架构提供了良好的基础,例如卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)等。词向量训练工具多种多样,例如Word2Vec等。通过这些工具可以在数据量较小时实现较好的结果。
Kim[3]等提出了多尺度并行的单层卷积神经网络结合预训练的词向量的方法,在多个句子分类任务上的表现优于传统的机器学习算法,以及早期的神经网络方法。得益于RNN的出现,文本分类又有了进一步的提升,RNN更适合学习长文本序列,但是RNN在训练时会出现长期依赖问题,例如预测“我住在中国,……我说汉语。”中的“汉语”,由于句子长度过长,无法学习到关键信息。其变体长短时记忆网络[4](Long Short-Term Memory Network,LSTM)引入门机制,通过使用输入门、遗忘门和输出门来控制记忆的长短。随后LSTM的变种门控循环单元[5](Gated Recurrent Unit,GRU)出现,GRU和LSTM相似,但GRU将遗忘门和输入门合成了一个单一的更新门,同时混合了细胞状态和隐藏状态。
近年来,注意力机制作为深度学习中的重要研究方向,首先在神经机器翻译领域取得了突破,随后拓展到其他领域,例如语音识别、文本分类等。Zhou等人[6]提出了基于注意力机制的双向长短时记忆网络(Bidirectional Long Short-Term Memory Network,BI-LSTM)并用于文本分类,Yang等人[7]又提出分层注意机制的神经网络模型(Hierarchical Attention Networks,HAN),并应用在文本分类。
法律判案研究在自然语言处理中常被当作一个对文本多分类的问题处理。其中Chao-Lin Liu等人[8]在2006年提出用kNN对12种和6种犯罪结果进行预测,在2015年Yi-Hung Liu等人[9]又提出使用SVM来进行犯罪结果的分类提高了判案的准确率。另外英国伦敦大学的Nikolaos Aletras等人[10]在2016年提出对欧洲人权法庭的预测,考虑人权等其他伦理性因素,使用SVM构建模型对判案结果进行预测,准确率达到79%。美国芝加哥肯特伊利诺伊理工学院法学院的Daniel Martin Katz等人[11]在2016年使用随机森林构建模型对美国最高法院行为的预测,准确率达到70%。同时还有日本的Mi-Young Kim等人[12]用SVM的方法来计算文本的相似度从而对判案结果进行胜负预测。2017年Bing-Feng Luo等人[13]使用基于神经网络的模型对刑事案件进行预测,准确率达到98%。
本文使用基于循环神经网络和机器学习的模型,并对其中一个循环神经网络使用注意力机制。模型需要较大数据量,本文对河南省2014~2018年部分“交通事故”数据集进行实验,对比基于SVM的模型、基于双向门控网络(Bidirectional Gated Recurrent Unit,BI-GRU)的模型和基于Attention+BI-GRU的模型结果。
2 交通事故自动判案模型
2.1 基于SVM的模型
基于SVM的“交通事故”自动判案模型如图1所示: 将文本分词,将文本通过词向量表映射成词向量组成的序列,将词向量组合成文本特征进入分类器进行训练。

图1 基于SVM的模型
如图1所示,文本可以视为是词的表示序列,可以将原始文本序列表示成式(1),通过词向量嵌入将序列文本S转换成如图1向量序列[x1,x2,……,xT],其中xt代表的是将单词wordt通过词汇表V查到对应词向量。
S=[word1,word2,…,wordT]
(1)
将词向量序列[x1,x2,……,xT]转换成图1所示的文本向量di,表示文本的特征。计算方法如式(2)所示。
(2)
其中T代表的序列中元素的个数,xt代表在t时刻的向量。将文本向量di和标注答案输入到SVM中进行有监督训练,SVM内核函数使用径向基函数。
2.2 基于BI-GRU的模型

图2 基于BI-GRU的模型
基于BI-GRU的模型结构如图2所示,模型主要包括以下几部分: ①首先将本文需要的事实文本通过词向量嵌入转换成词语向量集合[x1,x2,……,xT]。②将向量集合[x1,x2,……,xT]传入到事实文本编码器去编码生成文本特征向量df。③随后将文本向量df通过Sotfmax分类器计算每一个输入事实判案结果的概率。下面对具体结构进行介绍。
2.2.1 事实文本编码器
Yang等人[7]提出分层注意机制的神经网络模型,并应用在文本分类研究。直观上来看,一个句子由多个单词的序列组成,一篇文档由多个句子的序列组成。文档编码的问题可以转换成两个序列编码的问题,即序列Encoder的问题。如图3所示,首先在句子序列编码器中对单个句子编码,生成向量S,随后在文档序列编码器中,将句子向量S作为输入,生成文档向量的向量编码d。

图3 文档编码器
Sent代表句子序列,经过句子序列编码器后生成句子向量S,将所有句子向量S经过文档序列编码器生成文档向量d。其中文档序列编码器和句子序列编码器可以使用不同的序列编码器,本文在这里为了方便使用相同的序列编码器。2.2.2节对序列编码器进行介绍。
2.2.2BI-GRU序列编码器
本文使用双向的门控循环网络对序列文本进行编码。如图4所示,序列编码器中包括一个前置网络和后置网络,其中每个网络都使用GRU实现。对输入序列[x1,x2,……,xT]在每个时刻t产生前置网络中间状态hft和一个后置网络中间状态hbt。在每个时刻产生中间状态ht为式(3)所示,对中间状态hbt和hft可以使用拼接或者求平均,本文对hbt和hft进行拼接:
ht=[hft,hbt]
(3)
最后的状态向量g可以将中间状态ht进行连接或者求平均,本文将中间状态ht求平均,如式(4)所示。
(4)

图4 BI-GRU序列编码器
2.2.3 输出层
为了更好地得到输出,首先将事实文本向量d经过一个全连接层去产生一个新的向量d′,全连接层计算如式(5)所示。
d′=σ(Wf·[df]+bf)
(5)
其中d′∈Rk,答案类别数为k。随后将向量d′传入一个Sotfmax分类器中去产生可能预测的结果概率向量pf,pf∈Rk。其中pf中每个维度数值对应分类标准中每种类别的可能概率值,概率值最高的类别为预测结果。由于本文将自动判案视为单标签分类问题,即一个文本事实对应一个判案结果,因此不需要设置最后可能概率的阈值。
本文在使用BI-GRU模型进行训练时使用交叉熵损失函数,如式(6)所示。
(6)
其中T是判决的结果的分类数目,yt和pt分别是真实的判案结果和预测判案结果概率。其中真实判案结果中如果在T时刻为真的判案结果,则标签为1,否则标签为0。
2.3 基于Attention+BI-GRU的模型
基于Attention+BI-GRU的模型和基于BI-GRU的模型基本相同,最大的改进是在基于BI-GRU的模型中序列编码器直接使用了BI-GRU,如图5所示。其中最终输出g如式(7)所示,对中间状态取平均,即所有的信息都统一处理。但在这里使用Attention机制,对中间状态动态产生权重α,即可以动态的学习序列中重要的部分,如图5所示。

图5 Attention+BI-GRU序列编码器
图5中所用模型在传统的BI-GRU网络上增加了权重机制。对于给定的任意序列[h1,h2,……,hT],模型中的Attention机制计算出每个元素的权重[α1,α2,……,αT]。计算如式(7)所示。
(7)
其中W是一个权重矩阵,将输入的中间状态ht线性转换,u是一个内部的向量用来从没有信息的向量中找出有关键信息的部分。通过用这种方法,可以有效地区分出句子和文档中有效的信息。
3 实验设置
3.1 数据集
本文数据集来源为中国裁判文书网[注]http://wenshu.court.gov.cn/的公开数据,针对河南省2014~2018年的“交通事故”文书,最终获取法律文本数15 000条。对数据集使用正则表达式抽取事实,规则如“案件事实.(.*?)本院认为”,同时去除数据长度过短的文书,对人名进行匿名化减少噪音。最终获取有效数据集14 000条。
清洗过的数据集总数14 000条,选择其中12 000条作为训练集,2 000条作为测试集,各类别数目分布如表2所示。
通过法律判案事实总结规律,对判案结果进行人工标注,粗、细两种粒度下的分类结果如表1所示,粗分类分为4类,细分类分为8类。标准划分后对有效数据集进行人工标注判案结果,分布如表2所示。
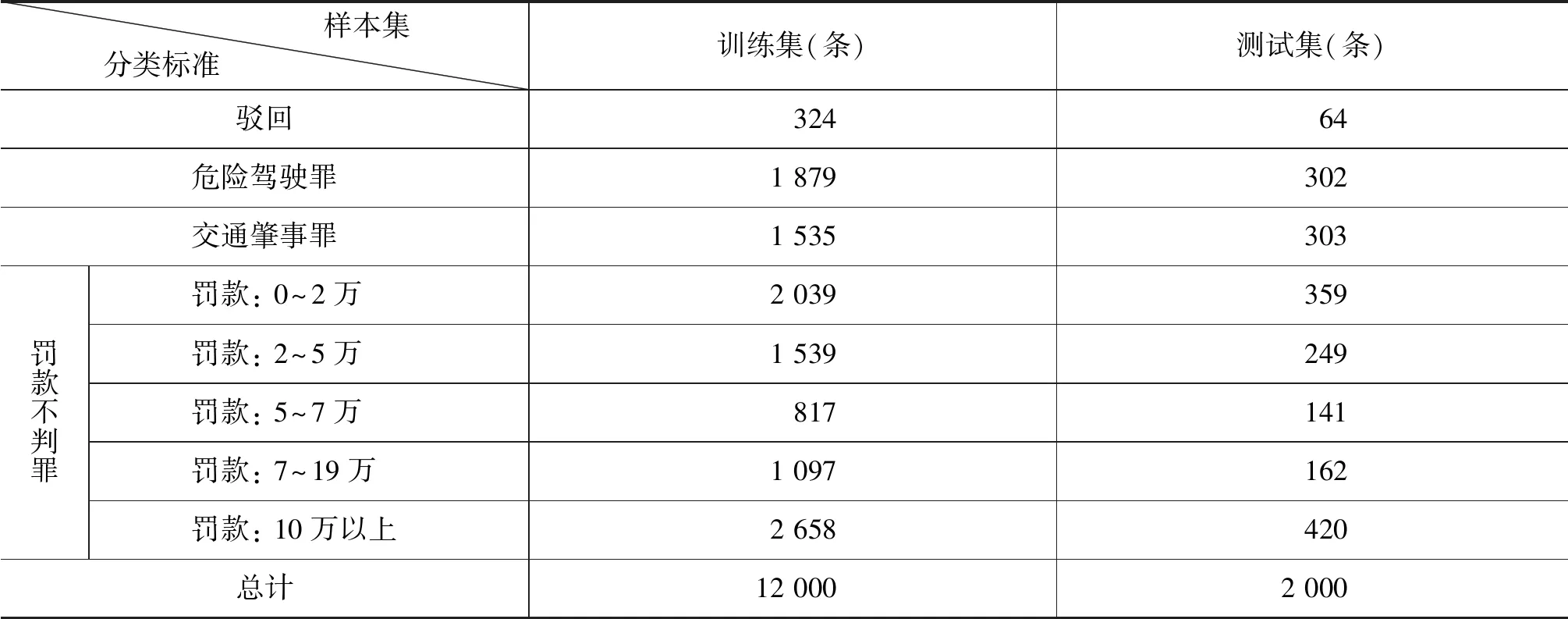
表2 数据集分布统计
3.2 词嵌入设置
本文对数据集的处理使用中科院的分词系统ICTCLAS[注]http://ictclas.nlpir.org/,(NLPIR)汉语分词系统,主要功能包括中文分词、词性标注、命名实体识别、用户词典功能。本文使用ICTCLAS进行无词性分词,对数据集进行预处理。
在数据集规模较少时使用词向量嵌入可以明显提高网络准确率。本文使用Word2Vec[注]https://code.google.com/p/word2vec/工具对实验语料进行训练。训练词向量维度为100维,生成有效词向量个数为63 812。对于训练后的词向量表中不存在的词,随机生成[-1,1]上的100维向量来初始化。
3.3 超参数设置及训练细节
本文模型中使用统一的数据输入格式,输入文本向量。经过对数据结果进行分析后设置一篇文档中的最大句子个数为15,单个句子的最大长度为40个单词,一个单词的维度为100,其中达不到句子最大长度时用100维的“0”填充。
本文基于SVM的模型使用Sklearn框架完成,设置迭代次数为150,内核使用径向基函数。
基于BI-GRU的模型和基于Attention+BI-GRU的模型使用TensorFlow框架完成。基于BI-GRU的模型批处理大小设置为100,基于Attention+BI-GRU的模型的批处理大小设置为7。每个GRU单元的隐藏层数目设置为75,基于BI-GRU的模型和基于Attention+BI-GRU的模型都使用随机梯度下降法作为优化器进行训练,其中学习速率设置为0.01。
3.4 评价指标
文本分类的评价标准类似于信息检索的评价标准,包括准确率、召回率和F1值。准确率是指分类正确的文本数和实际分类的文本数的比率,如式(8)所示。

(8)
召回率代表正确文本数和分类应有的文本的比率,如式(9)所示。

(9)
F1为了综合考虑准确率和召回率不同方面的影响,如式(10)所示。
(10)
本文对所有类别的F1值进行综合考虑,计算
F1macro值,如式(11)所示,其中N代表结果类别,f1i代表类别i多对应的F1值。
(11)
4 实验结果及分析
4.1 粗粒度分类结果
本文首先按照表1中粗粒度分类标准对三种模型进行实验,使用准确率(P)、召回率(R)、F1值作为评价指标,实验结果如表3所示:

表3 粗粒度分类结果
由表3得出,基于Attention+BI-GRU的模型的四个类别F1值均高于SVM、Bi-GRU两个模型。其他两个模型中基于SVM的模型的F1macro值高于基于BI-GRU的模型的F1macro,但是从分类的每类结果看基于SVM的模型只有“驳回”的F1值高于基于BI-GRU的模型。
进行纵向的比较发现三组实验中“驳回”的实验结果都相对其他类别较低,在驳回这一类中SVM的F1值是35.85%,BI-GRU的F1值是11.59%,基于Attention+BI-GRU的模型是39.02%。主要原因有如下几个方面: (1)通过观察表2所示,其中“驳回”类别在训练集上数目为324条,数目相对较少。(2)通过观察数据集发现是在训练和测试数据中“驳回”文书特征差距较大,即并不严格和“交通案件”相关,例如“交通案件二审”、“离婚案件”等。
4.2 细粒度分类结果
表4所示为细粒度分类实验结果,对比粗粒度分类实验结果表3,可以明显看出基于SVM的模型、基于BI-GRU的模型以及基于Attention+BI-GRU的模型的F1macro均有大幅度下降。其原因是在罚款的分类处理过程中文本的特征不明显。例如“……被告人A在原告骨折,住院治疗等花费6 000……”和“……被告人B造成原告脑震荡,且进行药物治疗等共计9 000……”文本内容相似,但是前例判案结果为2万以下,后例的判案结果为罚款2~5万。同时一篇文档中平均500词,关键信息在文本序列中不固定,造成循环神经网络即使通过上下文学习也不能准确找到,可能需要补充知识库,使得机器理解“脑震荡”比“骨折”对人体伤害程度更大。
在表4中,基于BI-GRU和基于Attention+BI-GRU的模型在罚款5~7万、7~10万两个类别的召回率和准确率都为0,基于SVM的模型召回率和准确率不为0,但是分类效果较差。原因主要有以下几个: ①观察表1数据后发现其罚款在5~7万、7~10万的文本数较少。②在罚款5~7万、7~10万之间的文本和其他罚款不判刑类别罚款文本之间特征区分小。③神经网络在学习过程中会遗忘信息,SVM则由于是将文本特征映射到高维空间丢失特征较少,因此SVM准确率和召回率不会为0。
从表4中可以看出,虽然其在罚款5~7万、7~10万之间两类的F1值为0,但是基于BI-GRU的模型和基于Attention+BI-GRU的模型的F1macro都相比传统SVM的F1macro高。其中基于Attention+BI-GRU的模型的F1macro低于基于BI-GRU的模型。分析原因如下: ①在细粒度划分时,部分类别文本之间相似,特征不明显。带Attention的BI-GRU模型会放大某些特征,去掉某些在注意力机制下不重要的特征。但是对于相似文本特征的细微之处就会影响结果,导致在对罚款这种相似文本的分类时反而结果不显著。②本文数据量不大,对于注意力机制来说可能没有更好的发挥作用。

表4 细粒度分类结果

表5 验证实验结果

4.3 相似文书对注意力机制的影响
为了验证在本数据集上带Attention的BI-GRU模型适合特征明显的文本,本文又做了补充实验以验证该结论,如表5所示。
从表5中可以看出基于BI-GRU的模型在对金额分成三类的分类实验中各项指标均处于领先地位。在对罚款这种相似案件分类时,从F1macro看基于SVM的模型的结果最差,基于Attention+BI-GRU的模型相对基于BI-GRU的模型F1macro相差23.51%,在4.1节的粗粒度实验中,文本特征明显,基于Attention+BI-GRU的模型实验结果最好。得出结论在本数据集上基于Attention+BI-GRU的模型对特征不明显的文本进行学习时,会抛弃掉某些特征,放大某些特征导致分类不明显,反而没有经过Attention的BI-GRU模型不会丢失掉相似文本中的细微特征,分类结果更好。
5 结论
本文主要实现从中国裁判文书网上获取公开文书数据,抽取关键信息,并对文书数据按照两种分类标准进行人工标注。通过三种模型: 基于SVM的模型、基于BI-GRU的模型和基于Attention+BI-GRU的模型在一定程度上实现“交通事故”自动判案。实验结果表明: 在粗粒度分类结果上基于Attention+BI-GRU的模型最好,细粒度分类上基于BI-GRU的模型实验结果最好。实验总体基于BI-GRU的模型和基于Attention+BI-GRU的模型优于基于SVM的模型,同时发现基于Attention+BI-GRU的模型相对基于BI-GRU更适合于数据集中且特征明显的文本。
本文的目的是实现“交通事故”的自动判案,未来工作中,将进一步研究注意力机制如何更有效地注意到关键信息,进而提高自动判案的准确率。数据集要进一步扩大,对更多的数据进行分析。将进一步研究法律事实描述文本中的特殊性,并尝试融合其他领域知识库将法律文本的规则特征添加到深度学习中。
