基于QU-NNs的阅读理解描述类问题的解答
2019-04-17谭红叶王元龙
谭红叶,刘 蓓,王元龙
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引言
机器阅读理解旨在使机器像人类一样能够通过对文本的深入理解来回答一系列相关问题。近几年机器阅读理解受到了学术界和企业界的广泛关注,已成为人工智能及NLP领域的一个研究热点。如微软、Facebook、Google DeepMind、百度、哈工大讯飞联合实验室、Stanford University等顶级IT公司与大学分别展开相关研究,并创建公布了各自的阅读理解数据集,提升了机器阅读理解的研究水平,促进了语言理解和人工智能的发展。
根据已有的阅读理解数据集,从形式上看,阅读理解问题可分为cloze问题、选择题和问答题。针对cloze问题有CNN/Daily Mail[1]、汉语PeopleDaily/CFT[2]等数据集;选择题有MCTest[3]、CLEF高考评测[4-5]等数据集;而问答题有SQuAD[6]、MS MARCO[7]、汉语DuReader[8]和CMRC2018评测任务5[注]http: //www.hfl-tek.com/cmrc2018/等数据集,根据这些数据集中答案的长短,又可将问答题分为YesNo问题、简单事实类(实体类、短语类)问题和描述类问题。针对cloze问题和简单事实类问题已提出了众多的神经网络模型,而对问答题中的描述类问题(其问题语义概括程度高,答案(斜体字)也一般由多个句子组成,如表1所示)研究较少,但该类问题在现实生活中广泛存在,百度对其搜索引擎上的日志进行统计后,发现52.4%的问题都属于描述类问题[8]。文献[9]针对北京语文高考题中的概括题采用分步解答策略,先基于关键词词向量的句子相似度定位问句出处,然后利用CFN(Chinese FrameNet)进行篇章框架标注,并基于框架语义匹配及框架语义关系进行答案候选句抽取,最后采用流行排序算法进行排序得到最终的答案,由于高考题数据量的缺乏,无法训练端对端的神经网络模型,且传统方法容易带来级联错误,所以本文采用端对端的神经网络模型对描述类问题的解答进行研究。
本文的贡献主要有: 基于端对端的神经网络模型对阅读理解中描述类问题的解答进行了探索;在神经网络模型中融入了对问题的理解,即在模型的解题过程中考虑了问题类型、问题主题和问题焦点这三种信息;在模型的最后一层对答案进行了后处理,即对答案进行了噪音和冗余信息的识别与去除。

表1 描述类问题示例
数据来源: DuReader[注]http: //ai.baidu.com/broad/subordinate?dataset=dureader
1 相关工作
目前阅读理解的研究主要在CNN/Daily Mail[1]和SQuAD[6]数据集上进行,基于这些数据集众多神经网络模型被提出,模型的架构一般包含: 嵌入层、编码层、交互层和预测层。嵌入层对词进行分布式表示,编码层使得每个词具有上下文信息,交互层负责原文与问题比较,并更新二者表示,预测层根据交互层的输出预测答案,但各个模型在每层的实现上又有所不同。
在嵌入层,FastQA[10]加入了原文词是否出现在问题中的二值特征和原文词与问题词相似度的权值特征,加强了问题与文章的交互;jNet[11]使用TreeLSTM对问题进行编码,考虑了问题的句法信息,同时在模型中引入了问题类型(when、where等)标签,增强了模型对问题的理解。
在编码层,大多数模型使用双向的LSTM或GRU对原文和问题中的每个词进行编码,使得每个词都具有上下文信息,而QANET[12]使用卷积神经网络(CNN)和自注意力机制对问题和原文进行编码,去除了LSTM和GRU的循环特性,提升了模型训练速度。
在交互层,模型大都引入注意力机制,即通过某种匹配函数计算文本中每个单词与问题中每个词(或问题整体语义)的匹配程度,Hermann等[1]提出的Attentive Reader模型采用tanh函数计算注意力值;Chen等[13]在该模型基础上提出了Stanford Attentive Reader模型,采用bilinear函数计算注意力值;而Attention sum Reader[14]模型较简洁,直接将问题和文档的上下文表示进行点积,并进行softmax归一化得到注意力值;Dhingra等[15]提出的Gated Attention Reader模型采用哈达马积(hadamard product)计算注意力值,动态更新注意力值,对文档进行多次表达,对最后一层注意力值进行归一化,实验结果显示该模型有更好的推理能力;相比以上模型,Cui等[16]提出了一种多重注意力机制(Attention over Attention),不仅考虑问题对文档的注意力,也考虑文档对问题的注意力,即实现问题和文档的相互关注,实验结果相比以往有所提升;Seo等[17]提出的BIDAF模型也引入了双向注意力机制,并基于该注意力得到query-aware的原文表示,再将其输入建模层进行语义信息的聚合,最终得到融合问题和上下文信息的一个表示;R-NET模型[18]引入了一种self-matching注意力机制,其可高效捕获长距离依赖关系。
在预测层,对于cloze问题,模型利用交互层计算的注意力值进行答案预测,有的模型将具有最大权重的词作为答案输出[1,13],有的模型结合词在原文中的出现频次累加相应权重,选择累加权重最大的词作为答案输出[14-16];对于答案为一个片段的问答题,Match-LSTM模型[19]提出了两种答案预测模式: Sequence Model和Boundary Model。前者输出具有最大概率的位置序列,得到的答案可能是不连贯的,后者只输出答案在原文中的开始和结束位置,实验显示简化的Boundary Model效果更好,而DCN模型[20]使用了一种多轮迭代预测机制。
以上神经网络模型在这两个数据集上取得了不错的效果,但这些模型仍存在以下不足:
1) 仅能解决答案存在于原文中的问题,对需要生成答案的问题无能为力。
2) 模型中加入的问题特征过于表面,没有将问题的理解融入到模型中。
3) 没有达到对语言的真正理解,如Percy Liang等人[21]在SQuAD数据中加入了对抗语句,并对发布的16个模型进行了测试,结果F1值普遍降低了40%左右。
针对第二点,我们在模型中不仅融入问题类型(Question Type),还融入问题主题(Question Topic)和问题焦点(Question Focus)信息,其中问题类型可以增强期望的答案类别标识[22],问题主题表明问题的主要背景或约束条件,问题焦点表明问题主题的某个方面[23],识别这些信息,可以增强系统对问题的理解(Question Understanding),从而更准确的找到答案。
2 描述类问题的解答
我们将描述类问题的解答形式化定义为: 给定一个问题Q和一个候选文档D,目标是系统从文档D中选择一个与问题最相关的答案A={a1,a2,…,aj},其中aj为D中的一句话,在D中aj之间连续或不连续。本文假定aj之间在D中是连续的。
2.1 基于QU-NNs的描述类问题解答框架
如图1所示,我们使用框架为嵌入层、编码层、交互层、预测层和答案后处理层的QU-NNs(Question Understanding-Neural Networks,即融入问题理解的神经网络模型)模型解答描述类问题。为了增强模型对问题的理解(QU),我们将问题类型、问题主题和问题焦点这三种特征融入模型中,正确的识别这三种特征能对问题进行语义层面的理解,并对模型输出的结果进行噪音和冗余信息的识别,即答案后处理过程。基于BIDAF模型,我们对嵌入层和交互层进行改进,并加入答案后处理层,所以着重对这三部分进行说明。

图1 基于QU-NNs的描述类问题解答框架
融入问题类型的词嵌入层: 为了增强问题类型信息,将问题类型同问题一起作为输入,即:Q={qt,q1,q2…qm},其中qt为问题类型,m为问题的词数,Q∈Rd×(m+1)。文档D={p1,p2…pn},其中n为文档的词数,D∈Rd×n(d为向量的维度)。
编码层: 使用双向LSTM(Bi-directional Long Short-Term Memory Network)分别对问题和文档进行编码,将两个方向上LSTM的输出进行拼接作为每个词的表示,分别得到问题和文档的表示:Qh∈R2d×(m+1),Dh∈R2d×n,其中每个词都具有上下文信息。
融入问题主题和焦点的交互层: 即文档与问题的信息交互层。与BIDAF不同的是,在计算文档中第i个词与问题中第j个词之间的相似度Sij时,我们考虑到每个问题词的重要程度qimportance(相对于问题本身)对相似度的影响,该重要度由tf-idf值和问题主题与焦点信息共同决定。tf-idf是基于统计的方法评估一个词的重要度,具有很好的泛化能力,但不适用于个别反常数据。问题主题和问题焦点是针对问题本身用规则的方法评估一个词的重要度,这两种信息共同作用可以更好地表示问题词的重要度。
(1)
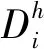
(2)

(3)
其中,Qj=q,qtf-idf为词q对应的tf_idf值(公式4),V为词表,a,b,c为常数,若q不在词表中,且不存在于QTopic、QFocus和QType(QType∈{how,why,compare,explanation,evaluation,brief,other})中,则取0.001(该词的重要性一般很低,为了平滑,取0.001)
(4)
其中,tf(q)是词q在文档D中的词频,|D|为文档D的总词数,|AD|为所有的文档(All Document),|AD(q)|即为包含词q的文档数。
基于相似矩阵S,计算双向注意力(即文档对问题的注意力(Context2Query)和问题对文档的注意力(Query2Context)): 其中ai∈Rm+1(式(5),其中Si: 表示第i行)表示所有问题词对文档中第i个词的注意力权重,b∈Rn[式(6),其中maxcol(S)表示取S矩阵中每行的最大值]表示所有文档词对问题中第i个词的注意力权重,基于该注意力计算query-aware的原文表示,并使用双向LSTM进行语义信息的聚合,最终得到包含问题和文档信息的语义矩阵。
预测层: 基于Boundary Model思想预测答案,即只预测答案开始和结束位置。模型输出的是答案区间,其仅适应答案连续的问题。
答案后处理层: 本文采用一个启发式的方法检索噪音和冗余信息,通过对比人工生成的答案和对应的文本片段,构建噪音词表W,如标签词“百度经验”“经验列表”等就为文本中的噪音。同时,文本中存在重复片段(如网页中会存在恶意复制现象等),系统输出的答案中就可能包含重复信息。将噪音和重复信息删除,可提高结果的简洁性。
问题类型通过卷积神经网络进行识别,问题焦点和问题主题通过句法分析获取,具体细节见2.2节。
2.2 问题特征识别
2.2.1 问题类型识别
问题类型可以增强期望的答案类别标识,对答案具有一定指导作用。本文为了探索问题类型对回答描述类问题的引导作用和防止细粒度分类错误,我们将描述类问题分为以下四大类,如表2所示。

表2 问题分类及示例

续表
可见,汉语的提问方式复杂多变,经常出现: 同一问题,疑问词不同;不同问题,疑问词相同的现象,甚至有时问句不包含疑问词,因此识别问题类型仅凭疑问词是有一定难度的。本文采用目前在分类问题上应用较多的CNN(Couvolutional Neural Networks)模型,对词汇进行语义层面的表示,完成对问题的有效分类。
本文采用CNN进行问题类型的识别,即将问句以字的形式输入模型中,通过卷积层、池化层和全连接层,最后通过softmax函数确定每个类别的概率,最终输出问题类型。
由于“what”类问题较笼统,我们进一步根据关键字将该类问题分为“解释”、“评价”、“简述”和“其他”四种类型,如表3所示。至此,问题类型共有以下7类: 方式(how)、比较(compare)、原因(why)、解释(explanation)、评价(evaluation)、简述(brief)、其他(other)。
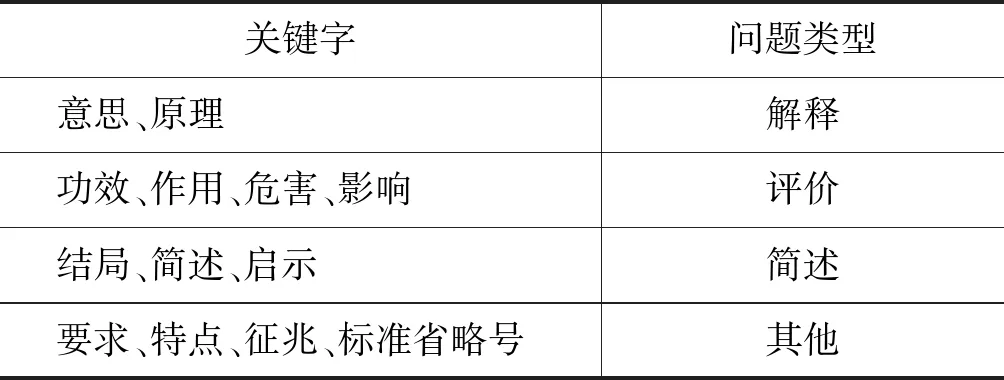
表3 “what”类问题分类
2.2.2 问题主题和问题焦点识别
问题主题和问题焦点是问题中的关键信息,问题主题表明问题的主要背景或约束条件,问题焦点表明问题主题的某个方面。如“西游记的结局是什么”中的“西游记”、“结局”分别为问题的主题和焦点,识别这两种信息,可加强系统对关键信息的关注,降低非重要词的干扰,使系统更易找到正确答案。
通过句法分析获取问题Q={w1,w2,…,wn}的主题和焦点,预先构建疑问词表QW和虚词、副词(的,和,是,很,非常省略号)等功能词表T。
如果wi∈QW,(wj,wi)存在依存关系,则wj为问题焦点,若wj∈T,则再找与wj存在依存关系的词作为问题焦点。如果wk修饰(ATT)wj,则wk为问题主题,如图2所示。(注: 若问句中不存在特殊疑问词,则将句子的最后一个词视为“疑问词”,如问句“成都二手房交易流程”,将“流程”视为疑问词)
如果Q为compare类问题,(wu,wv)存在并列(COO)关系,则wu和wv为问题主题,如图3所示。

图2 问题主题与焦点识别

图3 Compare类问题主题识别
本文在具体实现时采用哈尔滨工业大学的LTP[注]https: //www.ltp-cloud.com/进行句法依存分析。
3 实验与分析
3.1 实验建立
3.1.1 问题类型识别
从Dureader数据集中抽取了2 150条描述类问题(训练集1 450条、验证集500条、测试集200条)对CNN进行训练,经过多次实验测试,模型参数设置为: 字向量维度为64,卷积核函数为ReLU,过滤器数量为256,优化算法为Adam,批大小为32,迭代次数为40,学习率为0.001。
3.2.2 问题主题和问题焦点识别
从Dureader数据集中随机抽取100个问题,对这些问题的主题和焦点进行人工标注。
3.2.3 QU-NNs模型
实验中采用的预训练词向量是通过Word2Vec对中文维基百科数据进行训练得到的。本文实验所用的数据集是Wei He[8]提出的Dureader数据集中的描述类数据,因其没有公开测试集的答案,为了方便评价实验结果,我们将验证集进行了划分,最终数据分布为: 训练集161 834篇、验证集4 378篇、测试集2 000篇;同时我们抽取了科大讯飞提出的CMRC2018阅读理解中符合描述类问题的数据作为实验数据(4 600条问答对,其中验证集和测试集分别为200条、200条)。实验评价方法采用Wei He[8]在其数据集上实验时使用的Blue-4[24]和Rouge-L[25]评价方法。问题词重要度中的参数在实验中经过多次测试后,最终设定为a=3,b=0.5,c=1。模型参数: 词向量维度为300,隐层节点数为150,优化算法为Adam,批大小为32,迭代次数为10,学习率为0.001。
3.2 实验结果与分析
3.2.1 问题类型识别
采用字符级CNN对问题进行分类,实验结果如表4所示:

表4 问题类型识别结果
从表4可看出,Compare类问题准确率达到了100%,而What类问题准确率较低,分析数据发现Compare类问题较有标志性,其一般都包含‘区别’、‘比’等词,问句比较规范,而What类问题询问方面很多且较多情况下不出现疑问词,如“甲骨文的字形特点?”,正确识别较难。
3.2.2 问题主题和问题焦点识别
将系统自动识别的问题主题和焦点与人工标注数据进行对比,实验结果如表5所示,分析数据发现由分词导致的识别错误较多,但整体识别效果已满足实验要求。

表5 问题主题和焦点识别结果
3.2.3 QU-NNs模型
为了验证本文所加特征的有效性,以不加任何特征的BIDAF模型作为实验的baseline。为了评价不同特征对实验结果的影响,我们设置了三组对比实验,实验结果如表6~7所示。
① 在baseline中融入问题类型特征(QType)
② 在baseline中融入问题主题和问题焦点(QTopic+QFocus)
③ 在baseline中融入问题类型、问题主题和问题焦点(QType+QTopic+QFocus)
由实验①②③可以看出,不同特征的融入对实验结果有一定影响,同时融入问题类型、问题主题、问题焦点这三种特征后实验结果最好。通过数据分析,发现加入问题类型后,答案区间定位更准确,可见问题类型对识别正确答案具有一定引导作用;加入问题主题和问题焦点后,答案中减少了与问题无关的信息,答案更精准。
④ 对加入三种特征后模型的输出结果进行后处理(Post-processing),即删除噪音和冗余信息。实验结果如表6所示,ROUGE-L值和BLEU-4值明显提高,因为实验数据均来自百度搜索和百度知道,网页上存在较多的噪音数据和重复信息,抽取的答案片段中自然也有较多的这些信息。CMRC2018是基于篇章片段抽取的阅读理解数据集,数据集较为规范,本文提出的答案后处理策略对该类数据不奏效。
表6 DuReader数据实验结果

表7 CMRC2018数据实验结果
从表6和表7的实验结果看: 本模型在CMRC数据集上效果更明显,分析数据发现CMRC数据集更加规范,问题表述较清晰,问题特征更易识别;融入所有问题特征的模型效果最好,可见加强问题的理解有助于系统找到正确答案。本文实验存在的不足有: (1)文本理解对回答问题很重要,实验中没有对文本理解进行建模。(2)由于语言表述复杂多变,简单的噪音和冗余信息识别对于答案生成过于粗糙,应该基于语义及篇章层面分析其中与问题无关的信息。
4 总结
本文针对阅读理解中的描述类问题,将对问题的理解融入了模型中,主要对问题类型、问题主题和问题焦点这三种问题特征进行了建模,同时对模型输出的答案进行了噪音和冗余信息的去除,对实验结果有一定的提升作用。但没有对文本的理解进行建模,以及获取答案的方式仍为抽取式的,直接从原文中抽取的答案含有与问题无关的信息,所以在今后的工作中,我们会从篇章层面对文本进行理解并将篇章信息建模到模型中,以及答案的获取考虑采用生成式方法,即对不同的句子进行删除、融合、改写等策略或基于大数据学习这种生成模式,获取最终的答案。
