二元选择分位数回归模型的贝叶斯估计方法及模拟研究
2019-03-28邸俊鹏张晓峒
邸俊鹏,张晓峒
(1.上海社会科学院 数量经济研究中心,上海 200020;2.南开大学 数量经济研究所,天津 300071)
0 引言
分位数回归和贝叶斯估计属于当前计量经济学理论的前沿领域。分位数回归作为一种不同于均值回归、应用更广泛、提供信息更丰富的计量方法,虽然早在1978年就被Koenker等[1]提出,但关于它的理论研究和应用研究方兴未艾。贝叶斯估计尤其是采用马尔科夫链蒙特卡罗(MCMC)方法,在小样本性质、假设检验以及预测方面具有比传统估计方法无可比拟的优势,因而受到越来越多的关注。Yu和Moyeed[2]在2001年首次将贝叶斯分析方法应用于分位数回归模型,提出贝叶斯分位数估计方法,并证实了该估计方法的有效性。
然而在贝叶斯分位数估计中大多数研究都是针对连续型因变量的,对离散型因变量,如二元变量的分位数回归模型研究较少。目前离散型因变量模型代表性的文献主要有:Manski(1975,1985)[3,4]定义了半参数的二元选择分位数回归估计量;Koenker和Hallock(2001)[5]主要致力于中位数上的二元选择分位数回归(Binary Quantile Regression)的相关研究;进而,Kordas(2006)[6]将该研究扩展到了各个分位数上,并阐明了二元数据的各分位数回归可以提供解释变量对因变量更丰富的影响。上述研究都是基于传统的频率学派方法的。Skouras(2003)[7]、Florios和Skouras(2008)[8]指出这些方法并不能保证得到目标函数的全局最优解。因此,采用频率学派的方法求解二元选择分位数回归模型,无论在统计量的一致性方面还是在统计推断方面都受到质疑。
本文将针对二元选择分位数回归模型的贝叶斯估计方法进行探索性研究。首先介绍基于ALD的贝叶斯二元选择分位数回归估计方法;进而通过模拟实验,对不同先验设定和不同抽样算法下二元选择分位数回归估计量性质进行比较研究;最后,比较频率学派方法和贝叶斯估计方法对二元选择分位数模型进行估计时的不同表现。
1 二元选择分位数回归的贝叶斯估计方法
1.1 二元选择分位数回归
标准的二元选择模型表达式为:


F(⋅)为累积分布函数。F(⋅)所采用的形式不同,二元选择模型也相应不同,常用的二元选择模型如表1所示:

表1 常用的二元选择模型
因为线性概率模型不能保证条件概率的预测值在0和1之间,即使加以约束,其预测结果也往往与现实不符,故应用较少。Logit模型假设条件概率分布的累积分布函数;Probit模型假设条件概率为标准正态分布的累积分布函数;而对于互补对数模型,假设条件概率为极值分布的累积分布函数。Probit曲线和logit曲线都是在概率为0.5处存在拐点,但logit曲线在两个分布的尾部要比Probit曲线厚。

其中,Q(⋅)和F(⋅)分别表示潜变量的条件分位数函数和条件分布函数,βτ为在τ分位数下的参数向量。因为潜变量是观测不到的,所以不能直接用模型(2)进行估计。
为了估计离散选择的分位数回归模型,Powell(1986)[9]指出可以借助分位数回归的同变性(Equivariance),这是分位数回归的一大优势。假设h(⋅)是因变量yi的变换(transition)函数,是定义在实数空间上的非递减函数,那么对于任意的随机变量y,则有:,即随机变量先变换再进行分位数估计与先进行分位数估计再变换是等价的。因此随机变量y的单调变换不影响分位数估计结果。在离散选择模型中,潜变量与因变量yi之间满足这种单调变换关系,因此潜变量与解释变量的分位数估计结果可以通过可观测的因变量与解释变量的分位数估计得到。
1.2 频率学派二元选择分位数回归方法存在的问题
频率学派在估计二元选择分位数模型时,首先要对其进行极大得分估计(maximum score estimate)。这个方法几乎对误差分布不作过多假设,只要求误差以自变量为条件的中位数为0。因此,极大得分估计不知道解释变量和误差项的函数形式,因而它也适应存在异方差的情形。Manski(1975)[3]最早只是关注中位数上的估计,后来Manski(1985)[4]将其扩展到更一般的分位数情形。极大得分估计如下:

其中sgn()为符号函数,ρτ(⋅)为损失函数。
Kim和Pollard(1990)[10]指出极大得分估计量收敛速度低而且渐近分布复杂,而极限分布的复杂性限制了它在统计推断方面的应用,同时也使得目标函数不存在渐近的一阶条件。Delgado等(2001)[11]采用子采样(subsampling)的方法克服上述问题。他们从理论上证明了子采样对于极大得分估计是有效的,并给出了模拟证据。但该方法的一个主要缺点是计算量大,因而它只适用于解决小样本和维度低的情形。该方法起初用于中位数估计,Kordas(2006)[6]将其扩展到一般的分位数情形,但是这个平滑的估计量对误差分布假设过于严格。模拟实验表明,即使样本容量很大时,用正态分布近似也是不准确的;即使采用自举也很难得到估计量的标准误差[12]。Skouras(2003)[7]、Florios和Skouras(2008)[8]则侧重于就对目标函数(3)的优化,但他们指出没有哪个算法可以保证能得到全局最优解,即使是采用改进的算法,如混合整数规划(mixed integer programs)。总之,采用频率学派的方法求解二元选择分位数回归,无论在统计量的一致性方面还是在统计推断方面都受到质疑,即使提出了改进的方法,仍存在某些缺陷。
1.3 基于ALD的贝叶斯二元选择分位数回归估计方法

τ为关注的分位数,如τ=0.5,则是二元选择中位数回归。同样地:

这里,Fy*(⋅)设定为非对称拉普拉斯变量y*的累积分布函数。

π(β)为回归系数的先验分布,I(⋅)为指示函数。这个后验分布不是我们所熟悉的分布,不可能对其进行直接抽样,而MCMC方法可以解决这个问题。以β为条件的y*的全条件后验分布是可知的:
当yi=1时,

当yi=0 时,
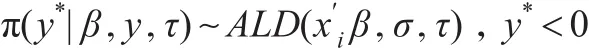
由(5)可知,以y*、τ和观测值为条件的β的后验分布是:

这个全条件后验分布不同于潜变量y*的全条件后验分布,不存在解析形式,因此采用MCMC方法,如Gibbs抽样、M-H抽样来获取后验分布。具体而言,给定观测值、参数的先验分布和感兴趣的分位点,借助式(4)和(5)给出的条件分布,采用Gibbs或者M-H抽样,可以得到联合后验分布(6)。以极大似然估计值为初值,并删除开始的部分估计值,最后得到一个抽样值序列,从而可以方便地得到参数的点估计和置信区间。这也是贝叶斯方法相对于频率方法的一大优势。
关于先验分布,Yu和Moyeed(2001)[2]指出,回归参数的先验分布π(β)可以是任意的,即使是一个不合适的均匀分布,得到的后验分布也是合适的。此外,由式(6)可知,后验分布是由误差服从非对称拉普拉斯分布的假设所决定的,这也表明模型参数的估计量和统计推断是受这个假设影响的。然而,在下文的模拟中可以看出,即使误差不服从这个假设分布,相关结论也是相当稳定的。
1.4 模拟实验
下面通过一个模式实验展示采用贝叶斯方法分析二元选择分位数回归的过程。在二元离散选择模型中,如果存在异方差,贝叶斯分位数回归方法可以有效地捕捉和反应这种异方差。参数先验采用模糊的标准正态分布,β~N(0,10),以此来减弱对后验分布的影响。MCMC抽样值的收敛性由从边际分布中得到的抽样值的时间序列是否平稳来判定。
首先通过下面的异方差模型,生成n=200数据:

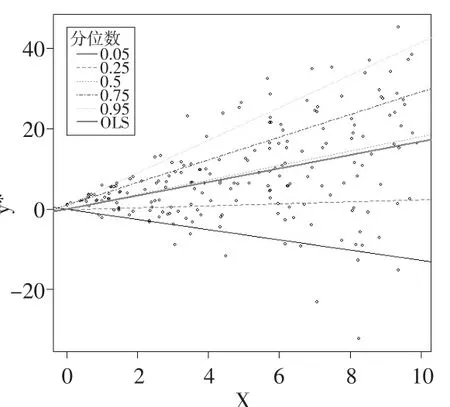
在上述数据生成过程(7)的基础上,定义离散二元变量yi:当时yi=0,当时yi=1。采用贝叶斯二元选择分位数回归方法对其进行估计。由于为潜变量,是不可观测的,所以本文使用的数据是二元离散变量yi和解释变量x,来估计潜变量中隐含的异方差。在0.05、0.25、0.5、0.75、0.95分位数上的抽样值轨迹图和核密度图如图2所示。
比较使用二元选择贝叶斯分位数回归(图2)和采用潜变量的贝叶斯分位数回归得到的各分位数下估计值(图1),见表2。

表2 贝叶斯二元选择分位数估计量与真值的比较

图2贝叶斯二元选择分位数回归系数的抽样轨迹图和核密度图
表2中,β的真值与图1中拟合直线的斜率相对应。从表2可以看出,通过可观测的变量采用贝叶斯二元选择分位数回归方法得到的估计量虽然与真值在数值上有偏差,但是它仍可以反应各个分位数上潜变量与自变量的相关关系,比如在低分位数上负相关,且随着分位数的提高,相关系数逐渐增大。在下文中比较不同抽样方法对二元选择分位数回归估计结果时,采用某一分位数下的值占所有分位数下值之和的比例,来讨论哪种抽样方法更能反映各个分位数下变量之间的关系。
2 不同先验设定下二元选择分位数回归估计量性质的比较
针对一般化的形式:

误差项存在异方差。为比较不同先验分布条件下估计量的差异,本文设定回归系数的先验分布为正态分布,而且随着方差的减小,信息由弱到强。形式分别如下:
先验设定1:β~N(0,100)
先验设定2:β~N(0,10)
先验设定3:β~N(0,1)σ为参数化的尺度变量,设定其先验分布σ~χ2(3)。
根据上述数据生成过程,结合不同的先验信息,运用Gibbs抽样算法对模型参数进行估计,考察不同的先验分布对估计结果的影响。

表3 不同先验分布下二元选择分位数回归估计量分布的数字特征
由表3可知,与连续数据贝叶斯分位数回归不同,二元选择模型的贝叶斯分位数回归参数在各个分位点下的偏误和标准差均不受先验分布的影响。因此,在对二元选择模型进行贝叶斯分位数回归时,不必考虑先验分布的选取,即先验可以是无信息先验。
3 不同抽样方法对二元选择分位数回归估计量的影响
在贝叶斯分析中,Gibbs抽样和M-H抽样是目前较流行的抽样算法。而不同的抽样方法施行不同的算法和抽样规则,本文将比较采用Gibbs抽样和M-H抽样对二元选择分位数回归估计量的影响。
数据生成过程为:
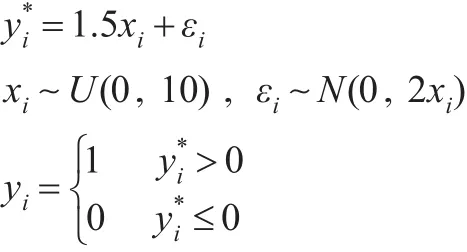
在Gibbs抽样过程中,参数β的先验分布为,将尺度变量σ参数化,并设定其先验分布为χ2(3)。在M-H抽样中,参数的先验分布与Gibbs设定相同,建议分布为高斯分布。每种抽样算法下共迭代6000次,为消除初值的影响,去掉前2000个抽样值。通过抽样值时序图和自相关图可以对两种抽样方法进行初步的比较。图3是为样本容量为200时,各分位数下Gibbs和M-H抽样值轨迹图和自相关图。左列为Gibbs抽样结果,右列为M-H抽样结果;在每个分位数下,第一行为4000个抽样值的时序轨迹图,第二行为自相关图。

图3各分位数下Gibbs和M-H抽样值轨迹图和自相关图
从0.05、0.25和0.5分位数的时序轨迹图可以看出,两种抽样方法得到的马尔科夫链都收敛,但Gibbs抽样值的分布呈左偏形态,比较而言M-H抽样值的分布较为对称。从自相关图角度看,Gibbs抽样值的自相关度下降快于M-H抽样值的自相关度。如在0.05分位数下,Gibbs抽样值的自相关度在滞后10期时基本趋于零,而M-H抽样值的自相关度在滞后35期才趋于零。在高分位数0.75和0.95下,抽样结果表明Gibbs抽样明显优于M-H抽样:Gibbs抽样值的时序图集中在某一个稳定值上下波动,且自相关图快速衰减,基本在5期滞后衰减为零;而M-H抽样值从时序图可以看出马尔科夫链收敛性差,存在自相关。此外不衰减的自相关图也说明了这一点。因此,从抽样的时序图和自相关图可以直观地初步判断,在高分位下Gibbs抽样明显优于M-H抽样,而在低分位数下需要进一步考察。下面对抽样得到的后验分布的统计特征进行进一步的分析。
依照上述数据生成过程分别生成25、75、100、200、500、800容量的样本,并在每个样本容量下分别进行Gibbs和M-H抽样,抽样结果见表4。

表4 不同抽样算法下二元选择分位数回归结果比较
通过以上分析,得出相关结论:①关于标准差:在给定样本容量下,各个分位数上,Gibbs抽样得到的后验分布的标准差均小于M-H的标准差。这表明在贝叶斯二元选择分位数回归中,采用Gibbs抽样得到的估计量精度更高,统计推断更准确。②关于偏误:在两种抽样算法下,抽样后验分布的均值对真值的偏误都比较大,其结果与表3类似(表中未列出),而且Gibbs的偏误比M-H的偏误更大。但需要强调的是,在二元离散选择模型中,每个分位数上估计量偏误的绝对值并不重要,重要的是各个分位数上估计量的相对值,因此在表4中本文给出了各个分位数下估计量的偏误占所有分位数上估计量偏误之和的比重(特定样本容量下,第一行数值),同时计算真值在各个分位数下占所有分位数上真值之和的比重(特定样本容量下,第二行数值)。如果采用某抽样方法时各个分位数上参数估计量的偏误占总偏误的比重更接近于对真值所对应的比重,则该抽样方法更优。如样本容量为100下,Gibbs抽样得到的β在0.05、0.25、0.5、0.75、0.95分位数上的偏误占总偏误的比重分别为-0.270、0.012、0.151、0.232、0.542;而M-H 抽样得到的β在上述分位数上的偏误占总偏误的比重分别为-0.074、0.010、0.046、0.144、0.874;真值在各分位数上的偏误占总偏误的比重分别为-0.187、0.025、0.202、0.397、0.563,显然Gibbs抽样下偏误的相对值与真值偏误的相对值更接近。由此可知,贝叶斯二元选择分位数回归采用Gibbs抽样方法得到的估计量更能描述潜变量与自变量关系的全貌。
4 不同估计方法对二元选择分位数回归估计量的影响
针对二元选择分位数回归频率学派的主要方法是基于二次抽样标准差的二元选择分位数回归方法[4]和基于渐近标准差的二元选择分位数回归方法[6]。下面比较了不同样本容量下贝叶斯二元选择分位数回归方法Bayes(LAD)与频率学派这两种方法的参数统计性质。
数据生成过程为:

差)

在不同样本容量下,比较两种传统二元分位数回归于贝叶斯二元分位数回归得到的估计结果,实验结果见表5。

表5 不同估计方法下二元选择分位数回归估计量比较
主要结论为:①随着样本容量的增加,三种估计方法下估计量的偏误、均方误以及置信区间都减小。这表明可采用的数据越多,参数的估计量越趋向于真值,而且估计的不确定性越小。②贝叶斯二元选择分位数回归(Bayes(LAD)估计量比频率学派得到的估计量拥有更小的偏误、更小的均方误和更精准的置信区间。③随着样本容量的增加,频率方法和贝叶斯方法得到的二元选择分位数回归估计量的差异会减小;BRQ和sBRQ在大样本下才能进行可靠的统计推断;同时这也说明,在小样本情形下,贝叶斯方法用于二元选择分位数回归估计效果更好。上述结果也验证了Benoit等(2012)[13]、Abrevaya和 Huang(2005)[12]、Kottas和Krnjajic(2009)[14]得出的结论。
5 总结
本文对二元选择贝叶斯分位数回归方法进行了研究,模拟结果表明:二元选择模型的贝叶斯分位数回归参数在各个分位点下的偏误和标准差均不受先验分布的影响,因此在对二元选择模型进行贝叶斯分位数回归时,不必考虑先验分布的选取。在进行二元选择分位数模型的贝叶斯估计时,与M-H抽样相比,采用Gibbs抽样得到的估计量精度更高,统计推断更准确,更能描述潜变量与自变量关系的全貌,而且在高分位下Gibbs抽样的优势更明显。贝叶斯二元选择分位数回归估计量比频率学派得到的估计量拥有更小的偏误、更小的均方误和更精准的置信区间,尤其是在小样本情形下,采用贝叶斯方法对二元选择分位数回归模型进行估计效果更好。
