基于ANFIS的水环境质量参数COD预测模型研究
2019-03-26潘淼
潘 淼
(辽宁润中供水有限责任公司,辽宁 沈阳 110000)
经济社会的快速发展在大幅提升人们的生活水平的同时,也不可避免地造成了日趋严重的环境污染。为有效利用水资源,减少水质污染造成的负面影响,对水质进行科学、准确、可靠的评价以及对其变化趋势进行有效预测极为重要[1]。网络自适应模糊推理系统(ANFIS)实现了人工神经网络技术和模糊控制技术的完美融合,可以在水质评价和预测领域发挥更要重要的作用[2]。
1 指标选取和数据预处理
1.1 水质指标选取
水环境质量通常是由多个水质指标数据体现出来的,而水环境质量预测也需要依据权威的水质监测数据创建预测模型。2003年,国家环保部出台的HJ-T100- 2003《水质指标的自动分析仪技术》中提出了9项环境保护行业标准,不仅包含了总氮、总磷、氨氮、pH等传统惯例监测项目,同时也包含了化学需氧量(COD)、生化需氧量(BOD)以及部分重金属离子等水质监测参数。结合上述标准以及水质监测的实际需求,本次研究选取了水质监测站的COD、pH、溶解氧、氨氮和总磷等5个水质质量监测指标。其中,化学需氧量(COD)作为研究水域中还原性物质污染程度的主要指标,是进行水质预测的重要参数,因此将COD作为预测模型输出计算的基本参数。
1.2 数据预处理
不同的水质参数拥有不同的量纲和单位,会对模型的数据分析造成影响,因此必须要对数据进行归一化处理[3]。本次研究中拟采用如下的线性函数进行归一化处理。
(1)
式中,xmin—某组数据的最小值;xmax—某组数据中的最大值。
在数据进行归一化处理之后,试验数据将映射在区间[0,1]之间。
在模型试验过程中,对整体数据进行聚类分析,将其中的离群数据删除,可以有效提升模型本身的预测精度。因此,结合数据的实际特征,采取欧式距离法对水质数据进行聚类分析[4]。
2 ANFIS预测模型的构建
2.1 模型预测方法
基于ANFIS水质预测模型的预测基本流程如图1所示。
第一步,首先确定预测水域的主要参数,本次研究选取了水质监测站的COD、pH、溶解氧、氨氮和总磷等5个参数。第二步,对原始数据进行预处理:在剔除部分无效和离群数据后,将余下的数据进行归一化处理,在归一化处理之后进行测试和训练样本分组。第三步,利用训练样本对模型进行训练,寻求并确定最合适的参数以及隶属度函数。第四步,将测试数据输入模型完成对COD水质参数的预测。
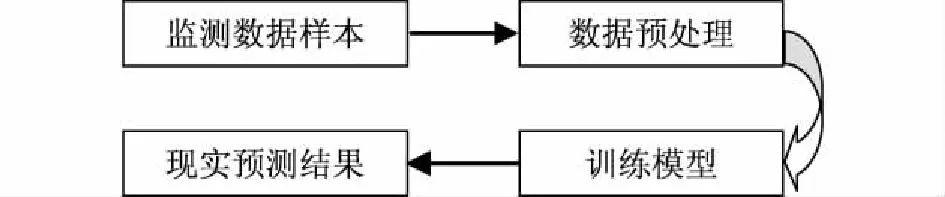
图1 ANFIS水质预测模型的预测基本流程
2.2 隶属度函数选取
在基于ANFIS的水质预测模型中,隶属度函数类型的选取以及数目的确定对模型预测精度具有较大影响[5]。常见的隶属度函数通常包括高速函数、钟型函数、梯形函数等几种常见的函数。对上述3种函数的比较显示,虽然都能拟合出原曲线,但是相对而言,高斯函数的拟合精度更高,因此在本次研究中拟采用高斯函数构建基于ANFIS的水质预测模型。
在隶属度函数确定之后,确定隶属度函数的数目。根据相关研究成果和实践经验[6],隶属度函数的数目通常选取在[1,30]之间,研究中将不同数目的隶属度函数依次带入模型,实践结果显示,隶属度函数的数目选定为5~20条之间时,ANFIS的水质预测模型均能对原曲线进行准确拟合,而隶属度函数的数目少于3条的情况下,模型就不能对原曲线进行准确拟合。另一方面,函数数目的增加,虽然能够提高拟合度的精准度,但是提高较为有限,模糊子集之间的相互影响会显著降低模型的灵敏度。本次研究最终确定隶属度函数的数目为5条。
2.3 模型训练次数选取
针对训练次数,根据相关研究成果,引入一个性能指标σ,设模拟精度为ε训练次数为n,trRMSE(n)为训练n次之后得到了RMSE值,根据公式(2),当σ≤ε时的n的值极为最优训练次数[7]。
σ=|trRMSE(n)-trRMSE(1)|
(2)
在本次研究中,初步设定模型的训练次数为500次,结合上述设定的高斯函数以及函数数目为5条等相关参数,对模型展开训练,获得的RMSE随训练次数变化的曲线如图2所示。由图2可知,当训练次数达到35次时,RMSE值的变化逐渐趋向平稳,根据公式(2)的要求,设定本次训练精度为0.02,最终得到最优训练次数为378次。

图2 RMSE值训练变化曲线
3 模型应用和检验
3.1 数据选择
为了检验基于ANFIS水质预测模型的泛化性和实用性,研究中以辽宁省大伙房水库出库口的监测数据为研究对象,由于该站每隔6小时采集记录一次水质监测数据,采集间隔时间合理,可以全面反映浑河该区段的水质情况。实验选取的是大伙房水库出库口2017年4—10月的数据,其中4—9月的数据进行模型训练,10月份的数据输入模型进行测试,并将期望值和实际值进行对比分析。其中,2017年4月1日6时至2017年4月5日0时的各项水质指标数值见表1。
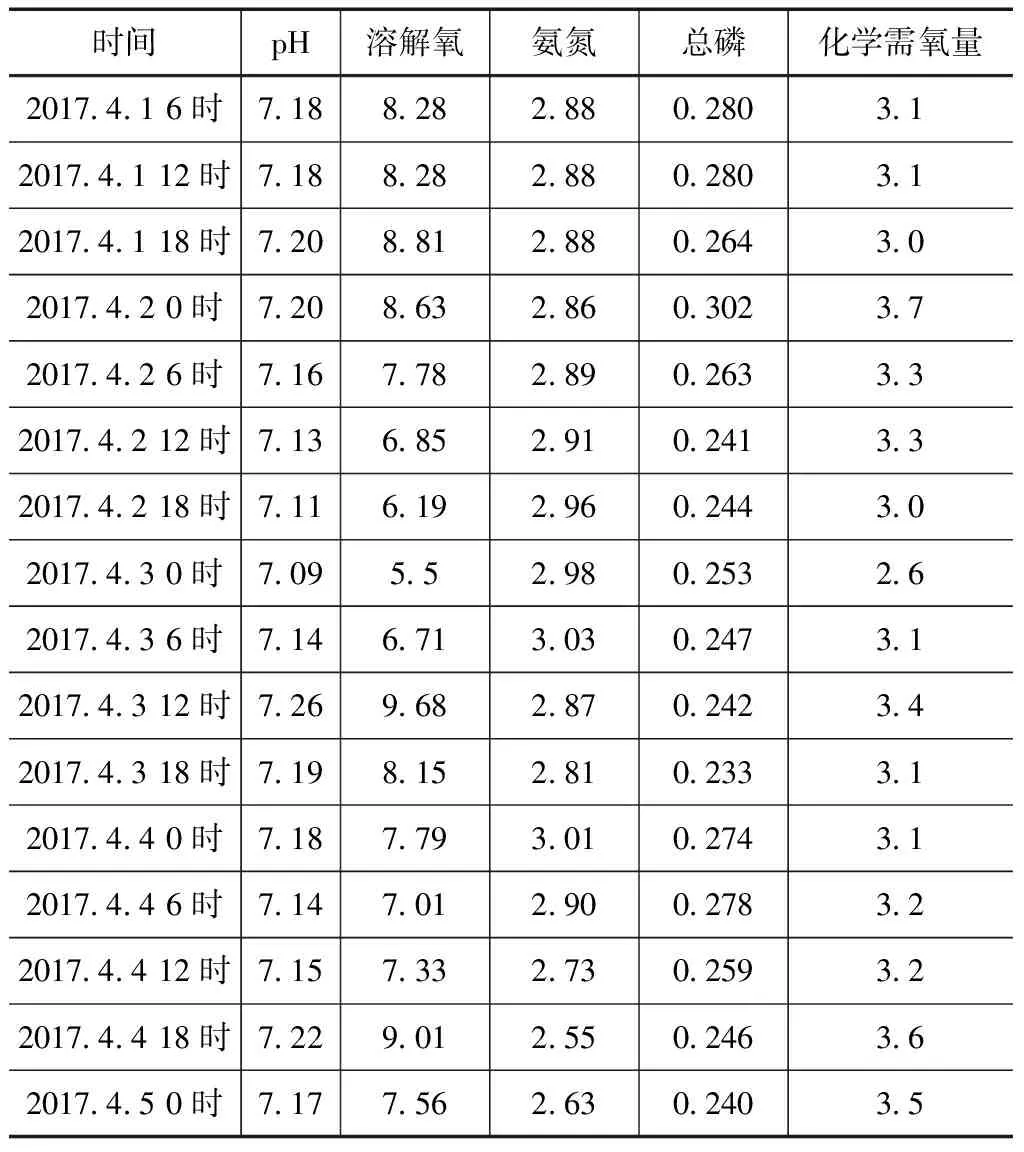
表1 大伙房水库库口水质监测部分原始数据单位:mg/L
3.2 预测结果分析
将原始数据进行预处理后,进行训练样本和测试样本划分,然后将训练样本输入ANFIS模型进行训练,在训练完毕后将测试样本输入模型,计算得出COD值的预测结果,然后与实际值进行比较,结果如图3所示。在软件窗口显示的模型预测值和实际值之间的相对误差为0.0966,均方根误差值为0.0610,均方根误差为0.2363。由此可见,ANFIS模型的预测值与真实值之间具有良好的拟合性,说明模型本身具有较好的预测能力和准确性。

图3 模型计算得出预测值与实际值
3.3 预测能力对比分析
为进一步验证ANFIS模型的实用性和泛化性,横向对比模型预测能力的优劣,研究中基于同组数据,分别利用BP神经网络模型和RBF神经网络模型进行预测计算[8],其预测性能参数的对比结果见表2。由表2中的数据可以看出,ANFIS模型能够对浑河大伙房水库段水体中的COD含量进行较好的预测,从相对误差来看,该模型的误差为0.0966,显著小于BP神经网络模型的0.1315和RBF神经网络模型的0.1485的相对误差值。因此,ANFIS模型相较于BP神经网络模型和RBF神经网络模型具有更好的泛化性和实用性。
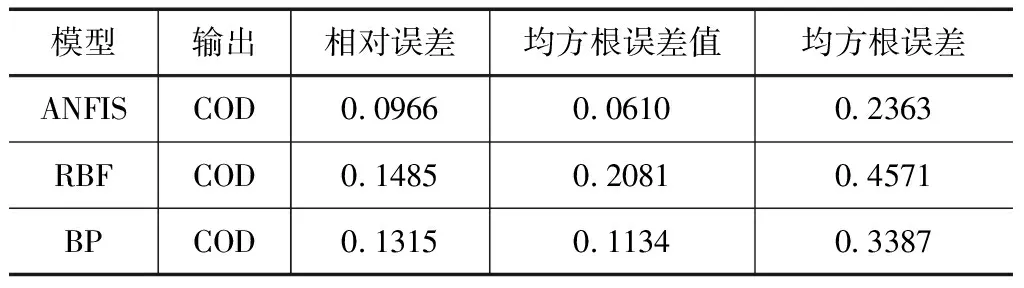
表2 不同预测模型的性能参数对比结果
4 结语
本文以浑河大伙房水库库口地表水为检测对象,建立ANFIS预测模型对该河段水体COD含量进行了预测研究,并获得如下结论。
(1)结合国家环保部的相关标准以及水质监测的实际需求,研究中选取COD、pH、溶解氧、氨氮和总磷等五个水质质量监测指标,并将COD作为预测模型输出计算的基本参数。
(2)利用ANFIS模型对COD值进行预测计算,并将结果与实际值进行比较,结果显示模型预测值和实际值之间具有良好的拟合性,说明模型本身具有较好的预测能力和准确性。
(3)将ANFIS模型与BP神经网络模型和RBF神经网络模型进行对比分析,结果显示ANFIS模型相较于BP神经网络模型和RBF神经网络模型具有更好的泛化性和实用性。
