面向电能质量数据采集的蚁群优化算法∗
2019-03-26王嘉怡
王嘉怡 房 俊 高 鹏
(1.北方工业大学大规模流数据集成与分析技术北京市重点实验室 北京 100144)(2.北方工业大学数据工程研究院 北京 100144)
1 引言
电网电能质量的优劣是电网正常运行的重要标志。电能质量数据涉及的指标数据种类多,且采集这些指标数据频率不一[1];现有电能质量数据采集系统以省作为单位进行数据收集,但各省数据互相隔绝,造成“信息孤岛”,使得数据不能得到很好的利用。为了能更好地评估电能质量问题,增强用电效率,改善电能质量,进一步汇集各省电能质量数据很有必要。
在电网环境里,采集的各种历史电能质量指标数据以数据包的形式存储、发送,然而由于各指标数据采集频率的差异,所以在一段时间内,省网成批采集到数据量不等的数据包。在面临多批次任务时,大量数据发送到服务器时,可能会造成处理延迟,单点故障等等。如果对其进行合理的调度,既可以缩短任务整体处理的时间,也能减轻服务器处理负担。
电能数据的调度问题与TSP问题类似,批量任务在服务器集群中的调度可以理解为在集群中找到适合各任务的最好服务节点,达到处理时间最优的效果。该问题属于NP问题,作为一种启发式算法,贪心算法容易陷入局部最优解,整体性能无法保障;而蚁群算法在解决该类组合优化问题中取得较好的效果。蚁群算法是根据蚂蚁觅食路径的行为,总结归纳的一种最优路径搜索算法,在解决任务调度的问题中取得了较好的结果。本文对电网数据的任务调度问题进行建模,在蚁群算法的基础上进行改进,得到最优的任务-服务器的映射关系,以求改善任务时间,并将服务器负载情况记录在信息素中进行反馈,可以在降低任务时间的同时,达到负载均衡的效果。
2 相关工作
2.1 相关调度算法
2.1.1 轮询调度算法
假设所有服务器的处理性能都相同,不关心每台服务器的当前连接数和响应速度。其优点是:简洁,无需记录当前所有连接的状态,属于无状态调度。但当请求服务间隔时间变化较大时,该调度容易导致服务器间的负载不平衡。
2.1.2 蚁群算法
蚁群算法来源于蚂蚁寻找食物过程中发现路径的行为。该方法经常被用于解决NP问题的优化求解,如旅行商问题,生产调度,路径规划等组合优化问题。在文献[2]中,考虑到虚拟机处理能力和其异构性,大量任务集中分配到性能较好的同一虚拟机上执行,有可能导致任务等待时间过长,同时出现其他虚拟机资源空闲的状态,针对该问题提出了信息素调整因子,将负载情况记录到信息素中,在迭代过程中,提高空闲资源的分配概率,在降低任务执行时间的同时,改善负载不均的情况,合理分配资源,提高资源利用率。该算法的主要参数,对蚁群寻找最优解的影响比较大,在文献[3]中,对蚁群算法的收敛性进行分析,可知重要参数影响收敛速度,合理设置参数取值可以有效地增强算法的全局搜索能力,提高算法收敛速度,减少算法计算时间,得到稳定全局最优解。
2.2 数据存储
数据包中的电能质量数据的任一实例可以表示为四元组,每分钟采集大约由2000个指标构成,单个量测大约80字节,每分钟采集数据包约160KB。如果有1000个监测点采集分钟数据,当天采集数量可达220GB。面对海量数据[4],用常规存储方式很难实现对其有效的管理。文献[8]中提出了电能质量大数据存储分析原型系统,是基于Hadoop和HBase的高效存储和分析数据的云平台。它结合监测数据特点,设计列存储模式,将有相关性的数据集中存储,以提高查询效率。但该系统虽然实现了数据存储,但易造成写入热点,且忽略了传输过程中数据的完整性和规范性,造成存储空间的浪费和数据冗余。文献[7]中的系统架构,在数据存储前,加入数据预处理层和数据写入层,结合数据多源、海量、高速的特点,对流数据进行数据预处理操作,并结合多线程技术,并行存储数据。同时对HBase行健进行优化设计,结合hash散列方法,将数据均衡存储到集群,既提高了存储效率,又提高了某种特定类型数据的查询效率。
在电能质量数据收集平台的数据存储系统结构的基础上,改进任务调度方法,采用多个数据接收服务器作为任务接收服务器,提出基于蚁群算法的电能质量数据多任务调度。
3 问题描述
现有的电能质量数据采集系统的调度结构如图1,采用多省轮询发送数据包。其采集特点是:调度器获取当前数据服务器上的数据包,将数据包按序依次发给指定数据接收节点。由于接收节点单一,导致入库效率较低。
在图1的基础上,以电能质量数据为研究对象,设计面向电能质量数据采集的蚁群优化算法。调整调度结构如图2,实现单省数据包动态分配到不同节点,结合多线程技术存储数据库。
蚁群算法的模型优化:改变信息素更新方式,添加信息素负载调整因子。为保证系统的运行效率和服务器的资源利用率最优,建立任务调度模型。
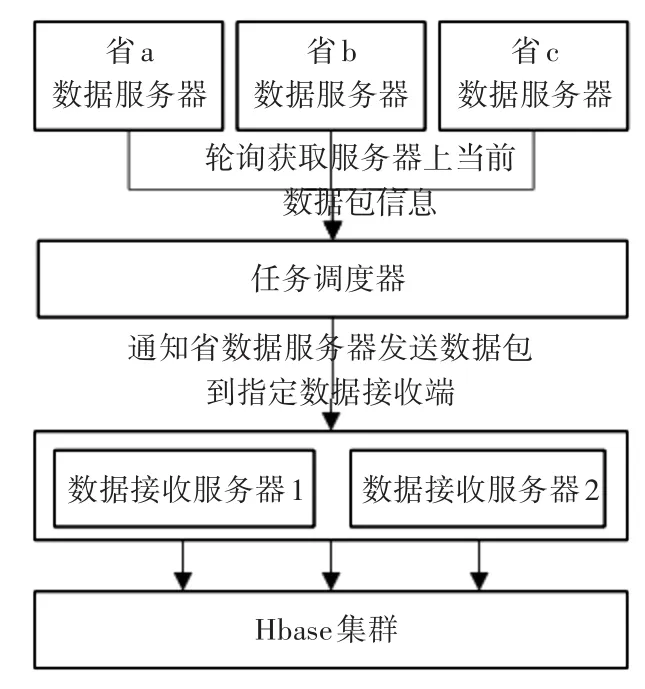
图1 现有数据采集调度结构

图2 基于蚁群优化算法的数据采集调度结构
定义1待处理的任务集合Task。设Task={Taski|i∈N+}表示当前有n个相互独立的任务待接收,其中Taski表示第i个任务只在一个服务器上接收。
定义2可用的服务器集合M。设M=表示有m个可用接收服务器的集合,其中Mj表示第j个服务器。
定义3与TSP问题不同,电网调度由待处理任务和服务器两个因素决定,因此将Task与M做笛卡尔积运算,得到调度集合K,定义K={Kij|1≤i≤m,1≤j≤n},根据 K估算出任务的执行时间,用T表示,Tij表示Taski在Mj上的运行时间。为方便求解问题,将K任意两列构成连通图,如图3所示。

图3 连通图
定义4对蚁群算法中的启发函数和信息素函数进行初始化。其中εij(t)为启发函数,定义:

τij(t)为信息素函数,定义:

该函数表示Taski分配给Mj的信息素浓度,其中Δτij代表信息素增量,初始时为0,1-ρ表示信息素浓度残留程度。当蚂蚁k完成一次遍历后,对本次遍历选择节点进行局部信息素更新时的增量:

对全局信息素更新时选取最优路径解更新增量:

式中C,C'为常量。Tij表示Taski在Mj的完成时间;T'
ij表示本次最优分配中Taski在Mj的完成时间。
蚂蚁k从当前节点i访问下一相邻节点j的概率为
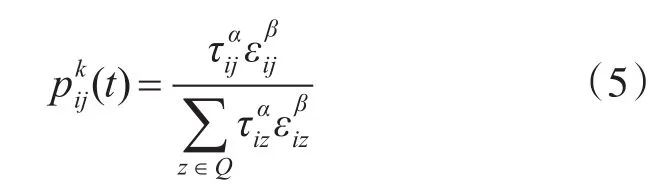
其中α,β反映蚂蚁在任务调度中路径上的残留信息素和启发式信息对任务调度的影响。
定义5添加信息素负载调整因子,记录每台服务器的当前接收任务的时间t,t=1-调整后式(2)中变为
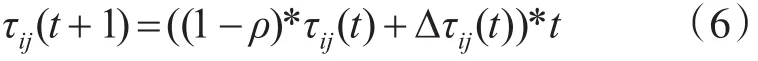
tj表示在Mj上的运行时间,tavg表示所有服务器的平均运行时间,tsum表示所有服务器运行的总时间;当分配给服务器的任务变多,tj变大,此时t变小;当下次任务分配时,该服务器的信息素降低,被分配任务的概率降低。
4 算法描述
算法的基本思想:将待处理任务与可用服务器进行组合形成任务调度集合作为任务搜索集合,随机设置蚂蚁的初始节点,将包含初始节点的任务-接收服务器的映射关系从任务搜索集中删除,然后计算下次允许访问的各个节点概率,依照概率随机访问下一节点,并从搜索集中删除包含下一节点的所有任务-接收服务器的映射关系,重复搜索过程。当蚂蚁没有任何节点可以访问时(即任务搜索集为空),结束这只蚂蚁本次搜索,得到一条搜索路径。比较所有蚂蚁本次迭代中的路径选择最优路径,调整信息素,记录该选择为当前最优解。根据调整后的信息素和启发式信息进行下一次搜索,直到迭代完成。从中选出全局最优解作为最优路径输出。算法实现步骤和实现流程如图4和表1所示。

图4 算法流程图

表1 算法的具体实现步骤
5 实验与分析
5.1 实验目的
为了验证面向电能质量数据采集的蚁群优化算法的可行性和有效性,设置3组实验。实验1为蚁群优化算法的参数对照实验,找到参数组合的最佳范围;实验2对不同负载的服务器,设置基于蚁群算法和蚁群优化算法的任务分配对照实验;实验3比较现有数据采集调度方法和面向电能质量数据采集的蚁群优化算法的数据存储写入性能。通过分析相关实验结果,期望验证面向电能质量数据采集的蚁群优化算法在存储性能和负载均衡方面更优。
5.2 实验环境与数据
搭建1台数据服务器用于采集数据包(任务),作为数据发送端;Hbase集群由3台装载CentOS7系统,Hbase1.2.1及Hadoop-2.6.0的接收服务器构成,将调度器部署在一台服务器上,用于周期性地访问数据服务器和检测接收服务器的负载情况,实现任务与接收服务器的关系映射;将数据采集系统部署到3台接收服务器中,用于接收任务并存储数据。实验中采用电网某省2016年12月9日下午4点到晚上12点的真实数据,真实数据采集时间1~3分钟不等。
实验1设置蚁群优化算法的参数对照试验,寻找参数的最佳组合数值范围,保证算法求得最优解的稳定性,即平均耗时。设置如下:实验单省数据包的任务分配,数据包大小约52000KB~55000KB;接收服务器的可用资源的差异比约为1:1.8:2.6。设置参数初始值为:α=2,β=3,ρ=0.7。①β,ρ不变,α从1开始以0.5的步长递增。②α,ρ不变,β从1开始以1.0的步长递增。③α,β不变,ρ从0.5开始以0.1的步长递增。①②③取值重复5次并记录最优解的平均耗时。④总结各参数的最佳取值范围及参数之间的组合优化设置。实验结果如表2所示。
实验结果分析:β,ρ不变,α∈[2,3]时,平均耗时较少,稳定性较高;α,ρ不变,随着β的递增,最优解的平均耗时呈递减趋势,在β∈[3,5]时,平均耗时较少,算法的稳定性较高;α,β不变时,随ρ的递增,平均耗时先降后升,在ρ∈[0.6,0.8]时,平均耗时较少,算法稳定性较好。由此得出参数的最佳取值范围:α∈[2,3],β∈[3,5],ρ∈[0.6,0.8]。并在实验2、3中设置α=2,β=3,ρ=0.7。

表2 蚁群优化算法参数对照实验
实验2设置蚁群算法和蚁群优化算法的任务分配实验:单省数据包的分配,数据包大小约52000KB~55000KB,接收服务器A,B,C负载存在差异,其可用资源比约为:①1∶1.2∶1.4②1∶1.5∶2③1∶1.8∶2.6④1∶1∶1。实验结果如表3所示。
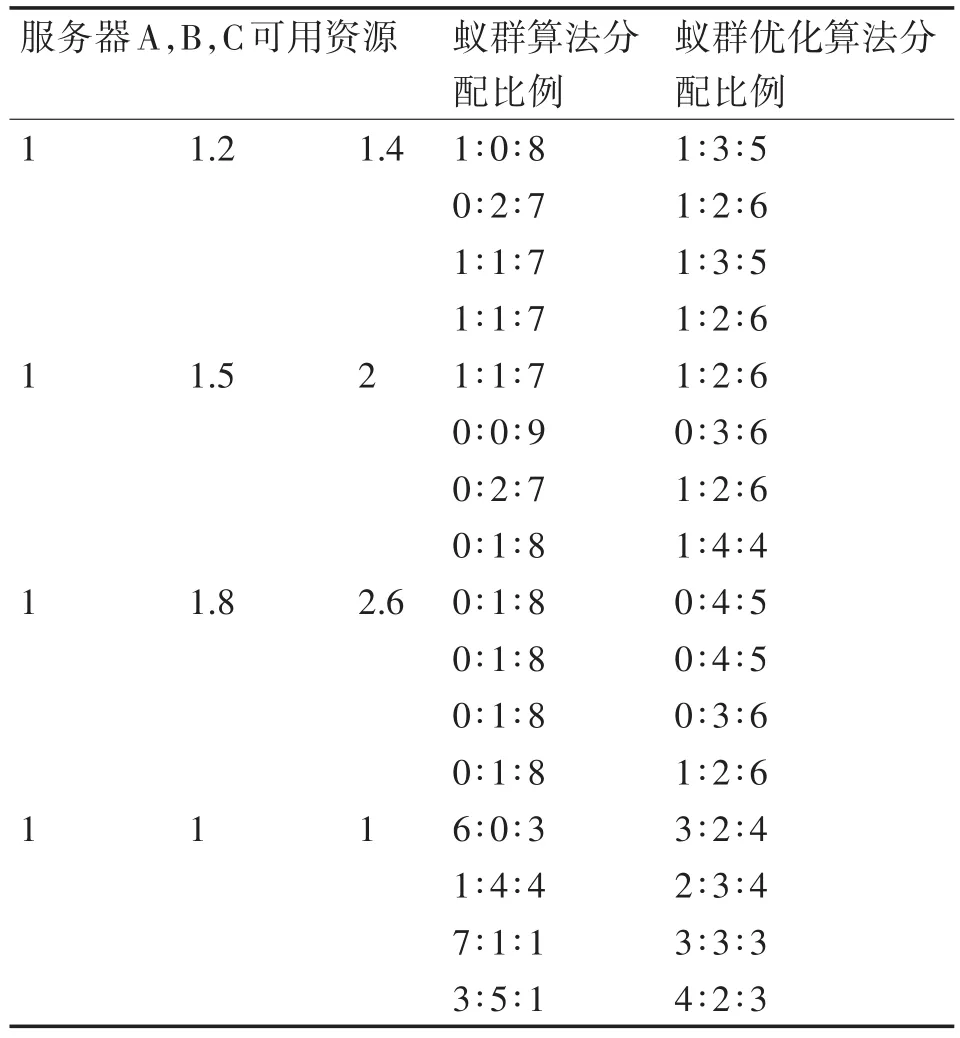
表3 负载均衡实验
实验结果表明:当服务器的负载相近(④)时,蚁群算法分配任务的随机性较高,而蚁群优化算法的任务分配比例接近1∶1∶1,负载较均衡;当服务器的负载差异较小(①)时,蚁群算法与蚁群优化算法的分配比例差异较小;当服务器负载差异较大造成处理性能差异较大(②,③)时,蚁群优化算法对均衡负载有一定改善。由此得出:服务器负载较均衡时,蚁群优化算法的任务分配比较平均;随着负载差异变大,负载较重的服务器接收任务较少或不接收任务,负载轻的接收较多任务,从而在下次的任务调度时,达到服务器负载均衡的效果。
实验3蚁群优化算法与现有数据采集调度方法的对照实验。设置如下:现有数据采集调度方法的数据处理节点为1个。蚁群优化算法中扩展节点到3个,接收并存储大小约9200KB的n个压缩包;分别记录服务器数据写入总量,写入时间和各服务器的数据分配比例。实验结果如图5、6所示。
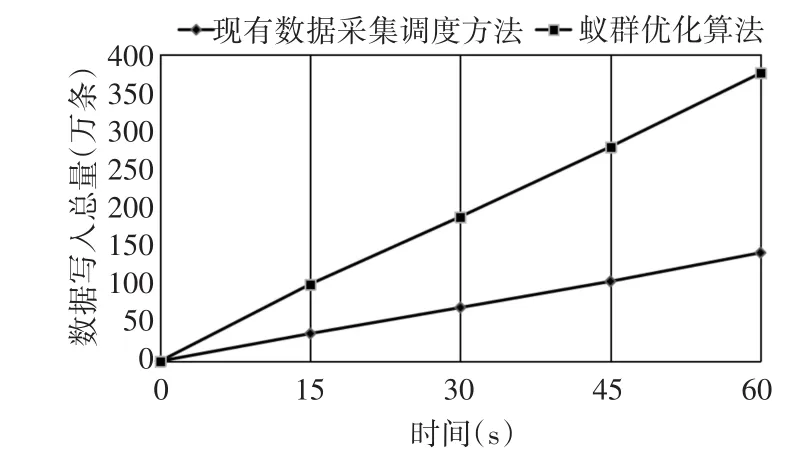
图5 两种调度算法的写入性能比较

图6 蚁群优化算法的任务分配比例
实验结果表明:蚁群优化算法的写入速率平均达到63692条/s,比现有数据采集调度方法的速率(23473.7条/s)快2.71倍;随着写入时间增加,蚁群优化算法和现有数据采集调度方法的写入速率的比例稳定在2.65倍。同时,每台服务器都能被分配任务,各服务器的数据接收分配比例基本维持在0.3~0.4之间。由此可见,蚁群优化算法在一定程度上提高了数据写入速度,降低任务执行时间,执行时间越长,其优势越明显,且对资源的分配较为平均。因此,蚁群优化算法的任务调度既可以提高写入效率,同时可以达到负载均衡的效果。
6 结语
本文针对电能质量数据的采集调度问题,提出蚁群优化算法的多任务调度方法,用于降低整体任务执行时间,实现任务并行处理,且实现接收服务器的负载均衡。作为一种启发式算法,蚁群算法对解决服务器集群的多任务调度较为有效。基于上述的实验结果及推理论证,表明合理的参数设置对算法有直接影响;同时,该算法不仅能降低任务执行的总时间,而且对数据接收层的负载起到一定的调节作用。
在下一步工作中,对服务器负载做进一步研究。本文对服务器负载考虑并不全面,后续应结合多个性能指标确定服务器负载状况。
