基于双向LSTM的动态情感词典构建方法研究
2019-03-13李永帅王黎明柴玉梅
李永帅,王黎明,柴玉梅,刘 箴
1(郑州大学 信息工程学院,郑州 450001) 2(宁波大学 信息科学与工程学院,浙江 宁波 315211)
1 引 言
随着社会媒体的快速发展,互联网正改变着人们的生活方式,据官方统计,大约新浪微博每日增加的数量是一亿条,这些微博更多的是表现出某个事件或者人或者产品的情感及情感倾向性.因此利用情感分析技术帮助去分析文本的情感,这将是很重要且很实用的一个环节,可以更好的快速的整理并分析这些信息,从而获取舆论倾向性.为了能够更好地研究情感分析[1],构建一个高质量的情感词典往往是占据着很重要的地位,关系着情感分类的质量好坏,一个好的全的情感词典能够更好的提供比较全面的情感信息,可以有效的帮助提高情感分析的质量.
在国外代表性的英文词典有GI(General Inquirer),该词典收录1914个褒义词和2293个贬义词,并为每个词语按照极性、强度、词性等打上不同的标签;还有主观词词典.该词典主观词语来自OpinionFinder系统,该词典含有8211个主观词,并为每个词语标注了词性、词性还原以及情感极性;在国内比较知名的中文情感词典有HowNet情感词典,包含9193个褒义词和贬义词;还有NTU评价词词典(繁体中文),该词典由台湾大学收录,含有2812褒义词与8276个贬义词.本文把预先被标记好了其词情感极性信息的情感词典称作静态词典.但目前的静态情感词典在情感分析中存在以下几点不足:
1)一些中性词也能表达出情感色彩.比如现实,噪音,浮云等也能表达出情感词的效果.
2)对于本身没有情感意义的词汇,当加入一些肯定词或否定词时,会表现为具有情感意义的效果.比如:意义->有意义,问题->有问题.
3)对于动态极性词,不同的词组其极性是不一样的.动态极性词和不同的词组搭配会出现不同的情感极性,比如,油耗高和效率高有着相反的极性.
4)没有涵盖流行词汇.比如,你脑子“瓦特”了,“凉凉”等词汇.
5)对于本来有情感意义的词汇,有时未必表现出情感色彩.比如:好难受,其中“好”并未表现出褒义的色彩.

图1 情感词典构建基本思路框架图Fig.1 Basic frame diagram of the emotion dictionary construction
以上不足都是传统的静态词典无法体现的,为了解决上述问题,本文提出了动态情感词典构建的方法,如图1所示,主要包括三层神经网络:1)第一层利用ECBOW模型对情感特征进行提取,该模型是基于CBOW模型基础之上的;2)第二层在本文构建的二叉语义依存树基础上,利用语义依存分析模型通过双向LSTM神经网络[10-12]对二叉语义依存路径特征提取;3)在第三层,利用获取到的情感特征和二叉语义依存路径特征加上中心词信息和相对位置特征一起组成当前词的特征作为另一个双向LSTM神经网络的输入,并通过标签框架标注输出情感词信息,最终训练出情感词分类器即动态情感词典.
2 相关工作
情感词典的构建在情感分析的过程中占据着重要的地位,目前情感词典构建的研究主要包括基于语料库、基于图模型以及基于词对齐模型的方法.宋佳颖等人[2]以PolarityRank算法为基础,面向产品评价文本展开汉语领域动态极性词典扩展研究.杜伟夫等人[3]提出一个可扩展的词汇语义计算框架,把词语语义倾向计算问题看成对其优化的问题.Duyu Tang等人[8]利用改进的Skip-Gram模型获得情感词向量,并借助Urban Dictionary来构建情感词典.郗亚辉[5]基于约束的标签传播算法来计算情感词的情感倾向从而构建情感词典.赵妍妍等人[6]利用微博上的表情符获取情感词,然后利用点互信息计算公式计算相应情感值.Mohammad等人[7]利用每个词和种子情感词的点互信息来构建情感词典.尹文科等人[9]利用Wiki百科中的链接结构通过有权无向图的团渗透方法CPMw进行词汇聚类构建出领域词典.
以上方法构建出来的情感词典都有引言中所述的缺点,在文本中不能很好的表现出词汇情感信息,为了解决这些问题,本文首先获取情感特征,Zhiyang等人[4]已经证明情感特征在双向LSTM中可以有效的提升情感分类准确率;由于钱忠等人[14]利用句法结构路径特征等多种信息对词汇序列化标注任务获得了很好的实验效果,本文提出了二叉语义依存分析模型来获取二叉语义依存路径特征;然后以情感特征、二叉语义依存路径特征、中心词信息和相对位置特征作为输入,以双向LSTM神经网络作为情感词分类器,训练得到动态情感词典.
3 基于双向LSTM的动态情感词典的构建
本节将详细介绍基于双向LSTM动态情感词典的构建方法,首先通过ECBOW神经网络对词向量的情感特征进行抽取,然后建立一个可以描述语义依存结构分析的二叉树,本文规定二叉树的根节点为整句的中心词,通过把双向LSTM神经网络应用到二叉语义依存分析模型去学习二叉语义依存路径特征;接下来依次获取中心词信息和相对位置特征;最后利用本文设计的标签框架作为双向LSTM的输出,把情感词特征、二叉语义依存路径特征、中心词信息和相对位置特征结合起来作为输入,最后将其训练成为一个情感词分类器,从而达到动态情感词典构建的目的.
3.1 词汇的情感特征提取
Google的开源工具word2vec[15-17]中用到两个神经网络模型,一个是Skip-Gram神经网络模型,另外一个是CBOW神经网络模型.本节选取CBOW神经网络模型作为改进目标对象并抽取词汇的情感特征.
3.1.1 利用CBOW神经网络模型进行词向量学习
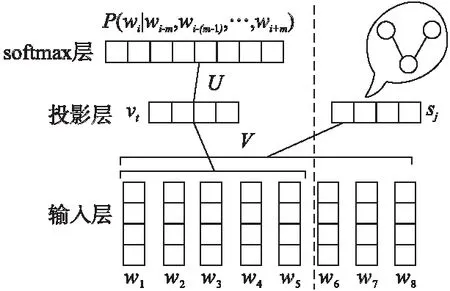
图2 ECBOW模型图Fig.2 ECBOW Model
CBOW神经网络模型的工作原理是根据上下文的词语预测当前词语的出现概率的模型.如图2左半部分所示,该模型分为输入层、投影层和softmax层,语料C中每个词汇w代表文本中的one-hot向量并作为输入层,V代表是一个n×|V|词向量表;在投影层经过矩阵转换为相同的n维向量的叠加,即:
(1)
在这里设置m=2.在输出层输出最可能的w,也就是最大似然化函数:
(2)
3.1.2 通过ECBOW模型提取情感特征
ECBOW模型是对CBOW模型进行的改进模型,主要改进如图2右半部分所示,在原来的CBOW模型下增添了一部分网络结构,其目的是提取有效的情感特征.其原理为:在原来的CBOW模型做一个基本的句法结构约束,然后通过具有褒贬意义的文本,对其情感进行约束.具体过程如下描述:
在新增的网络结构中,输入层为褒贬意义的文本中所有词w,投影层sj表示具有褒贬意义的文本中所有词的one-hot向量经过词向量表V转化为词向量并求和而得到的,即:
(3)
对于输出层来说,因为只有褒贬二元分类,因此通过一个逻辑神经元来计算输出为褒义和贬义的概率,如公式(4)所示:
(4)
其中H为向量参数,记p(sj)为文本褒贬性,如果投影层sj是由褒义文本所投影,那么p(sj)=[1,0];如果投影层sj是由褒义文本所投影,那么p(sj)=[0,1].从而最大化目标函数为:
(5)
具体的ADDEMOTION算法如算法1所示.
算法1.基于ECBOW模型情感表示(ADDEMOTION算法)
1) 语料预处理
2) 收集词语,创建词典
3) 初始化参数:θ:(U,V,α,η)、e、H、w、xs
4)while不收敛do
5)forsjinSdo
6)forallwt-2,wt-1,wt,wt+1,wt+2do
8)end
9)p=σ(xs·H)
10)e=e+η(hj-p)·H
11)H=H+η(hj-p)·xs
12)forw∈sjdo
13)V(w)=V(w)+(1-α)e
14)end
15)end
16)end
其中S表示训练集的所有句子集合,θ参数包括U、V、α、η,U为图2的左半部分投影层到softmax层向量参数;α为权重参数;η为学习速率;e为向量变化的大小;其中:
(6)
V(w)表示词汇w的向量;
(7)
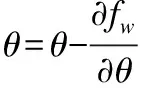
3.2 利用双向LSTM提取二叉语义依存路径特征
本节首先根据一个二叉树来描述语义依存关系,并通过哈夫曼编码记住二叉树结构,然后通过二叉语义依存路径信息,利用双向LSTM神经网络模型对每个词的二叉语义依存路径信息特征学习,为后面对情感词标签识别提供有效的特征.本文记哈夫曼语义依存结构二叉树路径为二叉语义依存路径.
3.2.1 哈夫曼语义依存二叉树
哈夫曼语义依存结构二叉树是由词汇节点和词汇依存关系以及哈夫曼编码所描述的,在讲哈夫曼语义依存结构二叉树分析之前首先解释下该二叉树构建方法,如图3所示,首先按照文本序列把相邻具有依存关系的词节点进行合并,合并后生成的父节点为被依存的词节点,依次类推直到把所有节点合并为一颗二叉树.其中词汇之间的语义依存关系以及二叉树部分结构描述由二元组T=<“依存关系”,“哈夫曼编码”>所描述,NULL表示依存关系为自己,哈夫曼编码为0表示从该节点往左生成子节点,哈夫曼编码为1表示从该节点往右生成子节点.被依存的词汇作为生成的父节点,其左子节点到父节点如果依存关系存在,那么两节点之间路径被描述为<“依存关系”,0>,如果不存在,那么两节点之间路径被描述为
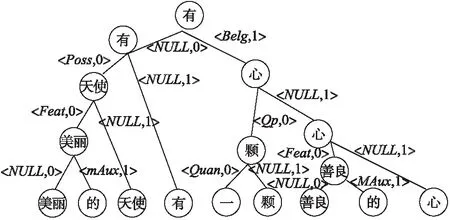
图3 语义依存结构二叉树图Fig.3 Semantic dependent two forked tree structure
3.2.2 二叉语义依存路径表示
由于中心词通常可以代表短语主要语法、语义特征,它被认为具有较强的预测能力[18].因此选取整句话的中心词为路径终点即二叉树根节点,从每句话的词叶子节点到中心词的路径被称作每个词的二叉语义依存路径,如“美丽”对应的路径信息为“美丽
3.2.3 提取二叉语义依存路径特征
LSTM是循环神经网络[10]中的一个特殊网络,它能够很好的处理序列信息并从中学习有效特征[13],它把以往的神经单元用一个记忆单元(memory cell)来代替,解决了以往循环神经网络在梯度反向传播中遇到的爆炸和衰减问题.一个记忆单元利用了输入门it、一个记忆细胞ct、一个忘记门ft、一个输出门ot来控制历史信息的储存记忆,在每次输入后会有一个当前状态ht,ht计算如下:
it=σ(Wixt+Uiht-1+Vict-1+bi)
(8)
ft=1.0-it
(9)
gt=tanh(Wgxt+Ught-1+bg)
(10)
ct=ft⊗ct-1+it⊗gt
(11)
ot=σ(Woxt+Uoht-1+Voct+bo)
(12)
ht=ot⊗tanh(ct)
(13)
其中,xt为t时刻输入的情感词向量,σ为sigmoid函数,⊗代表向量对应元素依次相乘,其中水电费Wi,Ui,Vi,bi,Wg,Ug,bg,Wo,Uo,Vo,bo为LSTM参数.

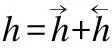
(14)
二叉语义结构模型可以定义为整句话词节点路径的概率的乘积:
(15)
其中,wi表示语义依存二叉树中的叶子节点.L表示wi的路径信息.PL(wi)表示该节点wi的路径发生概率.利用该模型借助双向LSTM对该二叉语义依存路径特征提取,如图4所示,输入层表示每个词的词向量,然后经过双向LSTM神经网路输出并进入特征层,其向量表示为fp,它的维度大小为np,最后进入softmax层表示该词节点二叉语义依存路径的概率,通过最大化目标函数使该神经网络收敛.最后得到每个词所对应的二叉语义依存路径特征.
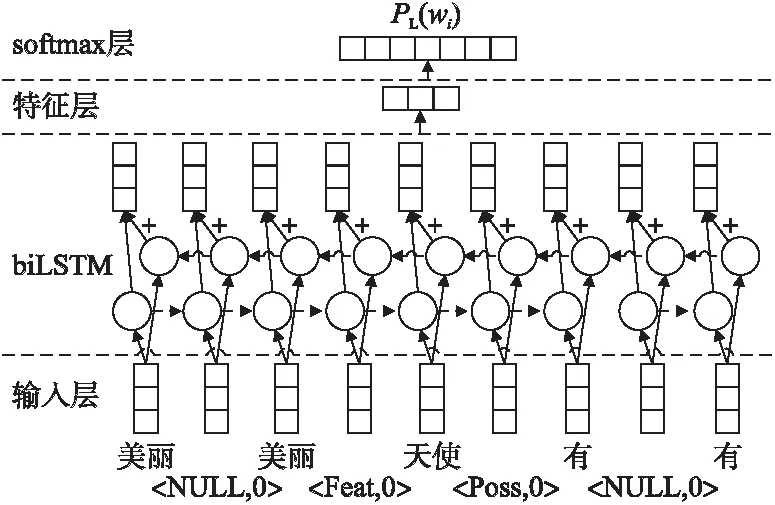
图4 利用双向LSTM神经网络抽取二叉语义依存路径特征图Fig.4 Using bidirectional LSTM neural network to extract path characteristics of two fork semantic dependency
(16)
3.3 相对位置和句子中心词信息
中心词通常可以代表短语的主要语法、语义特征,它被认为具有较强的预测能力.因此决定把文本中每个词汇到整个句子的中心词的距离计算出来,如“美丽”到中心词“有”的距离dm=-3.相对位置特征被映射为一个nrp维的向量frp.
中心词信息用以表示当前词是否为中心词,如果当前词为中心词,那么该特征的取值为一个特殊的词语“cue”;如果当前词不为中心词,那么该特征的取值为一另外一个特殊的词语“not_cue”,线索词信息被映射为一个nc维的向量fc.
3.4 情感词典分类器构建
本文将情感词典分类器(如图5所示)构建问题看成是序列标注问题,对于每一个词语,本文考虑其四个特征:情感词特征表示fe、二叉语义依存路径特征fp、中心词信息fc和相对位置特征frp.因此词语的特征f0表示为:
(17)
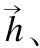
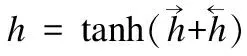
(18)
3.4.1 文本标签框架
本文的情感词性特征提取,采用文本标签框架来提取,本文采用的文本标签框架为本文定义的PNO框架,记框架标签Ti∈{P,N,O},其中标签集合解释:如果在文本中一个词表现出有褒义情感色彩的词汇,那么这个词被标记为P;如果在文本中一个词表现出贬义情感色彩的词汇,那么这个词标记为N;如果在文本中既不表现褒义情感色彩又不表现贬义情感色彩,那么这个词被标记为O;例句1 显示文本中每个词汇的标签:
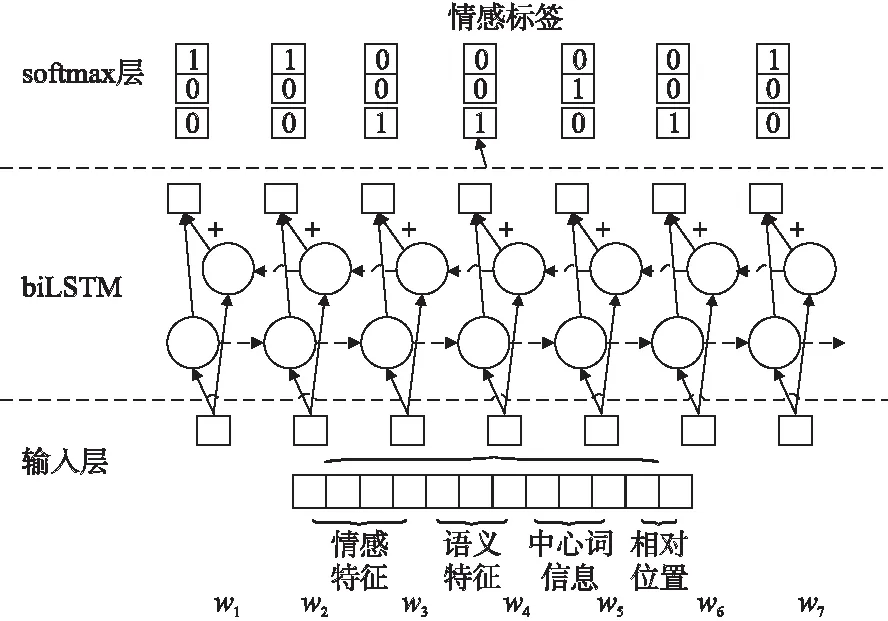
图5 利用双向LSTM神经网络构建情感词分类器图Fig.5 Using bidirectional LSTM neural network to construct emotional word classifier
例句1 这/O 场/O 比赛/O 打的/O 真/O 委屈/N,/O 队员/O 的/O 整个/O 状态/O 也/O 很/O 差/N !
本文把不同的标签映射为一个维度大小为3的词向量的长度.
3.4.2 输出层表示
进入输出层,其计算公式为:
O=softmax(Wsh+bs)
(19)
在输出层有每个输出节点的维度大小为3,因此分别用[1,0,0]、[0,1,0]、[0,0,1]分别代表该词汇的输出结果为褒义(P)、贬义(N)、中性(O);在这一层的输出做了一个softmax处理,通过这一步求取输出属于某一类的概率,如公式(20):
(20)
本文采用损失函数交叉熵作为目标函数,如公式(21)所示:
(21)
其中:yti指代在t时刻实际的标签中第i个值,preti指代在t时刻预测的标签中第i个值.
经过训练出来的双向LSTM神经网络情感词分类器即动态情感词典,然后利用测试数据进行初级扩展得到动态情感词典,如果该词汇所输出的标签为P,那么该词汇被判定为褒义情感词,如果该词汇所输出的标签为N,那么该词汇被判定为贬义情感词,如果该词汇所输出的标签为O,那么该词汇被判定为中性词.
算法2.情感词典初级扩展算法
输入:词语的特征f0、训练文本集Stest、测试文本集Strain
输出:输出褒义词典Dpos和贬义词典Dneg
1)while不收敛do
2)forwinsj∈Straindo
3)optimizebiLSTM(e(w),Tag(w))
4)end
5)end
6)forwinsi∈Stestdo
7)pTag=biLSTM(e(w))
8)ifpTag=[1,0,0]do
9)Dpos.append(w)
10)end
11)ifpTag=[0,1,0]do
12)Dneg.append(w)
13)end
14)end
其中:e(w)∈Dp,对于上述算法首先先用本文构造的双向LSTM模型对训练文本集进行训练,从而完成动态情感词典的构建,然后对测试文本集进行预测,预测为P标签将被判断其为褒义情感词,并把褒义情感词存入褒义词典Dpos;预测为N标签的将被判断其为贬义情感词,并把贬义情感词存入贬义词典Dneg;预测为O标签的将被判断其为中性词,最后得到初级扩展的静态情感词典.
4 实验与分析
在文本只有起到情感色彩的词汇叫做情感词,本文规定情感词由情感词主体和副体组成,其副体可为空.比如在“我们的做法是很有意义的.”一句话中“有意义”表现出褒义情感色彩,其中“有”为副体,“意义”为主体,然而有的中性词却能表达出情感色彩,比如:当在“问题”前加上“有”的时候,却能表现出贬义的情感色彩,因此对某些中性词在句子中却能表达出情感色彩时,本文规定这些词为中性情感词.因此规定情感词分为褒义情感词、贬义情感词、中性情感词.如图6所示.

图6 情感词分类图Fig.6 Classification of emotional words
4.1 测试数据
为了反映微博数据的真实性,随机挑选微博语料9836条微博作为测试数据集,并将该数据集利用哈工大语言平台中的分词功能和语义依存分析功能将数据集进行分词和语义依存二叉树的构建.首先,对输出标签进行标注,在标注时请了五位标注者同时对这些微博数据进行人工标注.标注者根据微博文本中情感词汇的情感倾向性将文本中具有情感的词标注出来,若有标注不一致的情况,则使用投票的方法决定词汇的情感倾向性.利用哈工大语言云平台的语义依存树功能将该数据集进行二叉树构建,并人工核查,对语义依存关系不正确的地方进行修改,最终由五位标注者协商决定.
最后统计这9836条微博中所有标注的情感词,这些微博数据的人工标注结果统计如表1所示.
表1 人工标注统计结果表
Table 1 Artificial selection result statistics

微博情感词数据集标注褒义情感词贬义情感词中性情感词总和10395892139819714
4.2 不同特征组合对动态情感词典的影响
鉴于语料规模有限,本文使用十折交叉验证的方法来进行验证,对微博语料中情感词进行褒义情感词、贬义情感词、中性情感词和中性词的四元情感分类,其中,中性情感词的分类具体过程是,如果该词汇在本句话中被确认为具有情感倾向性,而单独拿出来的时候没有情感倾向性,那么该词被认为中性情感词.
1)EWR(情感词特征)+SR(二叉语义依存路径特征)+TR(相对位置和中心词信息)+TRAIN(训练集):表示在基于ECBOW模型情感特征的基础上,进行添加语义特征、相对位置特征和中心词信息一起组成为该词特征,并取出训练集1万句进行各种指标计算.
2)EWR+SR+TR+TEST(测试集):表示在基于情感特征的基础上,进行添加二叉语义依存路径特征、相对位置特征和中心词信息一起组成为该词特征,并用测试集进行各种指标计算.
3)WR+SR+TR+TEST:表示在基于CBOW模型下特征向量基础上,进行添加二叉语义依存路径特征、相对位置特征和中心词信息一起组成为该词特征,并用测试集进行各种指标计算.
4)EWR+SR+TEST:表示在基于情感特征的基础上,只添加二叉语义依存路径特征一起组成为该词特征,并用测试集进行各种指标计算.
5)EWR+TR+TEST:表示在基于情感特征的基础上,只添加相对位置特征和中心词信息一起组成为该词特征,并用测试集进行各种指标计算.
如表2所示,可知以上各种方法测试其精确率均达到97%以上,证明本文构建的动态情感词典总体上对情感词和中性词识别度比较高.然而更为关心的是其识别出情感词的精准率,从上表数据可知实验1是基于ECBOW模型构造的情感特征的基础,并同时添加二叉语义依存路径特征、相对位置特征和中心词信息,可以发现其训练数据集的精准率略高于实验2测试数据集的精准率,提高了1.68%,其召回率提高了2.7%;同时发现实验3在没有加入情感特征的组合所得的测试数据集的精准率明显低于其加入情感特征的组合,其精准率降低了10.76%,召回率降低了9.28%,这种现象说明情感特征对判别词汇是否存在情感倾向性所占权重比较大;实验4在基于ECBOW模型构造的情感特征基础上,只加入二叉语义依存路径特征,不加入中心词信息和相对位置特征,可以发现其精准率相对实验2其精准率下降了1.99%,召回率下降了1.56%,由此可以发现文本中心词可以提供具有很好的预测能力;实验5是基于ECBOW模型构造的情感特征的基础上,只加有相对位置和中心词信息而没有二叉语义依存路径特征,发现其精准率相对实验2其精准率下降了4.94%,召回率下降了5.18%,证明二叉语义依存路径特征有一大部分影响到情感词识别的能力,证明二叉语义依存路径特征是一个很有用的信息特征.
表2 不同特征组合对比表
Table 2 Different feature combination contrast table
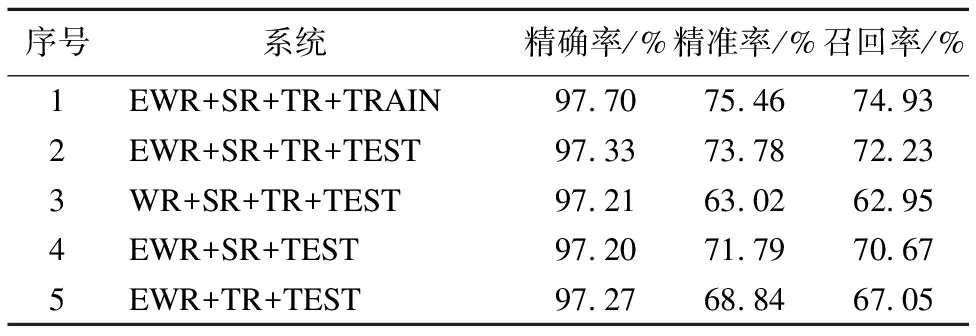
序号 系统精确率/%精准率/%召回率/%1EWR+SR+TR+TRAIN97.7075.4674.932EWR+SR+TR+TEST97.3373.7872.233WR+SR+TR+TEST97.2163.0262.954EWR+SR+TEST97.2071.7970.675EWR+TR+TEST97.2768.8467.05
4.3 验证动态情感词典可扩展性
本文用另外13821条测试微博数据作为测试集来进行验证动态情感词典扩展效果,其中EWR+SR+TR+NUM表示:在基于情感词特征并结合二叉语义路径特征、中心词信息和相对位置特征的双向LSTM模型下,对NUM条测试微博数据进行测试,从而来观察其情感词的扩展效果;比如,EWR+SR+TR+2000表示用了2000条微博测试数据,针对这2000条测试微博所产生出来的情感词判断其是否和原来标注的情感词一样,还是这些情感词并不在原来标注的情感词里面而是新增加扩展出来的情感词.通过表1人工标注去除重复的情感词后所得到的情感词统计结果如表3所示.
表3 标注统计情感词典
Table 3 Annotation of statistical affective dictionary

褒义情感词贬义情感词中性情感词总和379826352646697
在进行每次依次递增测试数据后都保留下分类出来的情感词,在情感词去重后进行人工挑选,不是情感词的词汇舍弃,然后统计出扩展出来的新的情感词汇,每次结果统计如图7所示,表示是通过依次增加取微博的数量的基础上统计出来新扩展出来的情感词的变化.
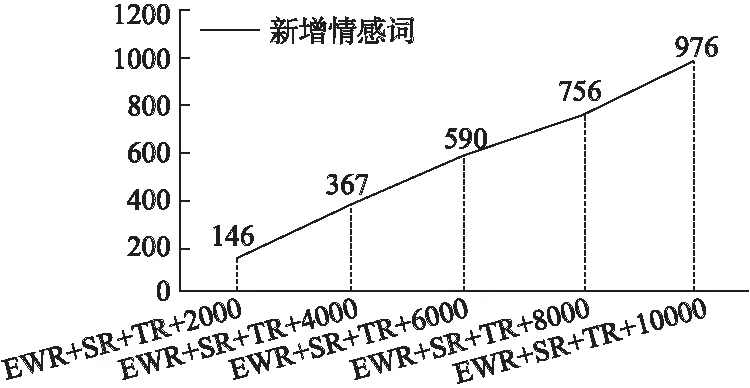
图7 新增情感词随测试数据集变化Fig.7 New emotion words change with the test data set
由上图可知,随着测试数据集的增加新增情感词在不断增加,当增加测试集到1万条微博数据时,最终统计得到的扩展出来的新词汇数量为976个,表明动态情感词典方法是有效的.最终得到如表4所示的较小规模情感词典WB-Lex.
表4 较小规模静态情感词典WB-Lex
Table 4 Small scale static emotion dictionary WB-Lex

褒义情感词贬义情感词中性情感词总和429930113657673
4.4 验证得到的动态情感词典有效性
在得到动态情感词典后,为了验证词典质量,本文用情感分析的经典任务-情感分析,具体做法为判断一条微博的情感倾向为褒义、贬义还是中性.本文的做法是用所构建的动态情感词典与其他词典进行对比,除了本文构建的动态词典外还使用了其他四个开源的情感词典资源,他们分别来自清华、北大、大连理工及知网,详见表5.
表5 词典规模统计
Table 5 Dictionary scale statistic

词典褒义贬义总和清华(Tsinghua)5567446810035北大(Peking)95420515大连理工(DUT)110431064621689HowNet452843208848
为了对比本文构建的情感词典与其他的情感词典资源的性能,本文将其用于情感分类任务上,并选择了简单有效的基于特征分类的情感分类模型SVM.具体的,针对一条微博,提取的特征除了正规化后的情感词向量,还加入了两维特征分别是该微博中包含词典中的褒义词的个数与贬义词个数.
1)ECBOW(情感词特征)+ALL(all lexicon):表示在ECBOW模型下情感特征基础上使用全部的情感词典资源;
2)ECBOW+ALL-Our:表示在ECBOW模型下情感特征基础上除去情感资源(动态情感词典)的全部的情感词典资源;
3)ECBOW+ALL-HowNet:表示在ECBOW模型下情感特征基础上除去知网的情感资源的全部的情感词典资源;
4)ECBOW+ALL-DUT:表示在ECBOW模型下情感特征基础上除去大连理工的情感资源的全部的情感词典资源;
5)ECBOW+ALL-Peking:表示在ECBOW模型下情感特征基础上除去北京大学的情感资源的全部的情感词典资源;
6)ECBOW+ALL-Tsinghua:表示在ECBOW模型下情感特征基础上除去清华大学的情感资源的全部的情感词典资源.
各词典的性能对比详见表6.通过分析表6可知,本文的动态构建情感词典的性能要显著优于其他四类情感词典.主要原因是由于大多中性情感词的影响.比如对于一般情感微博语句“上场 对 澳大利亚 还 貌似 不错 来着,昨晚 看得 不是 一般 的 郁闷 啊!”各个情感词典能判断出“不错”为褒义情感词,“郁闷”为贬义情感词,但是当面对这些语句的时候“参加 体育 运动 是 一件 有 意义 的 事情 !”,更多的情感词典会把“意义”字识别为中性词,从而失去了对这句话的真正理解,然而对于本文所构建的动态情感词典来说可以把“意义”标记为褒义情感词,从而进一步理解语句想要表达的真正意思.但是从表6也可以发现,本文的情感词典并不能够完全替代其他四类情感词典.在使用了本文构建的情感词典的基础上再使用其他的情感词典资源,对情感分类的性能仍能有一定的提升.
表6 各情感词典性能对比
Table 6 Performance comparison of various affective dictionaries

系统Accuracy/% ECBOW+ALL68.71 ECBOW+ALL-Our65.73 ECBOW+ALL-HowNet67.96 ECBOW+ALL-DUT68.21 ECBOW+ALL-Peking67.99 ECBOW+ALL-Tsinghua67.86
5 结 论
为了解决现有的中文情感词典的一些存在的问题,比如:对于一些中性词虽然单独使用时没有什么情感色彩,但是放到整句话里却能表达出情感色彩,以及当有些词汇之前加入肯定或否定的词时却突显出情感色彩,还有平常的一些极性情感词和一些流行的网络词汇“给力”,本研究的情感词典扩展方法很好的解决了这些问题,该动态情感词典扩展方法基于双向LSTM神经非网络模型,不仅考虑到情感特征,还考虑了语义依存特征、中心词信息、和相对位置特征,从而使动态标注情感词及词典扩展时提供了很好的帮助.实验结果表明该方法对测试集情感词识别的精准率达到73.78%之高,然后对另外1万句测试微博,扩展出新情感词汇976个,最后在文本情感分类任务也表明本文所构建的动态情感词典可以在情感分类任务中起到重要的作用,能够显著的提高在情感分类任务的性能.
