基于文本挖掘的大学生网络舆情检测和预警模型*
2019-03-11金慧峰程振设
金慧峰,程振设
(浙江工贸职业技术学院,浙江温州 325003)
0 引言
互联网运营模式的不断创新、线上线下服务融合的加速、公共服务线上化步伐的加快,使得几乎所有大学生成为网民。微博、微信、论坛、贴吧等社交网络的繁荣发展,使得大学生在这些社交网络上发帖、转发、评论等行为已经成为常态。在传统数据时代,研究者主要通过抽样调查、内容分析等方法获取有限的、有代表性的舆情样本信息,并运用统计学方法进行分析。在大数据时代,随着海量舆情信息的涌现和数据采集技术的进步,样本分析被总体分析所取代,传统的抽样分析和检测预警手段已无法适应大数据时代的发展趋势,网络舆情大数据的分析、检测和预警成为社会管理的客观需求。
目前关于大数据时代高校学生网络舆情监测和预警机制的研究成果较少,主要分为两个层面。其一是理论层面,根据大学生网络舆情传播的特点和现状,提出了高校网络舆情管理的思路、策略和路径[1-4];其二是技术层面,主要集中于网络检测系统的设计[5-8]、网络舆情挖掘技术[9-10]等。不论理论层面还是技术层面,均没有针对大学生网络舆情的定量化监测的成果,主要原因可能在于海量文本信息不但对当前计算机性能提出了较大挑战,而且对文本挖掘技术也提出了较高的要求。
1 相关理论简介
1.1 文本表示方法
目前,基于统计的文本挖掘方法[11-12]中,文本是以向量形式表示的,向量的分量是特征词的频数,特征词是根据文本挖掘的任务或目标来确定的,可以是名词、动名词或形容词,等等。因此,要将文本表示为向量,首先就要将文本分词。
1.2 文本分词
目前国内常用的分词方法[11-12]有:机械分词法、词库匹配法、词频统计法、语义分析法、神经网络分词法、联想-回朔法、联想词群法、知识与规则法等。这些分词算法可以归为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。本文采用中科院计算所的汉语词法分析系统ICTCLAS进行分词,该系统的功能有中文分词、词性标注、未登录词识别,分词正确率高达97%以上,未登录词识别召回率均高于90%,其中中国人名的识别召回率接近98%,处理速度为31.5Kb/s。
1.3 特征词选择
所有文本分词之后,形成词语集,词的总数通常都很大,这会使得表示文本的向量空间的维数也相当大,因此需要降维。降维技术有两类:特征选择和特征重构。
特征选择是指去除冗余的和不能表达文本挖掘任务信息的词,或者选择那些能够表达文本挖掘任务信息的词(称之为特征词),从而减少词语总量,达到降维目的。特征选择的结果为原始词语集的子集。特征选择方法:根据词频来判断,当词频小于或大于给定的阈值时就去掉。
特征重构是指将原始词语集经过数学变换构造出新的词语集,以此达到降维的目的。新的词语集不是原始词语集的子集。比较常用的特征重构方法是潜在语义分析。
2 实证研究
2.1 研究设计
本文以百度贴吧里近几年浙江工贸职业技术学院(下称学院)大学生网络聊天的文本信息为研究对象,开展大学生网络舆情的监测和预警。相关工作主要有五步:第一,使用python爬虫软件从百度贴吧抓取近几年的聊天帖子,数量将超过万条。每个帖子的信息包括帖子ID、主题、作者、跟帖数量、跟帖内容、跟帖作者、跟帖日期和时间。第二,对抓取到的文本信息作总体特征分析、热门主题及其作者搜寻、热门主题的内容分析等。第三,建立舆情指数,度量网络舆情的大小,形成动态直观的网络舆情走势图。第四,设置“黄色、橙色和红色”三个预警级别,对网络舆情进行预警。第五,建立特征词指数,实现对热门主题的热点关键词的捕捉。
2.2 数据采集与初步分析
编写python 爬虫软件,从浙江工贸百度贴吧(http://tieba.baidu.com/f?kw=浙江工贸)抓取到2007年5 月4 日到2018 年2 月28 日大学生的“精品”帖子,一共6551条文本评论。每个帖子的信息包括帖子ID、主题、作者、跟帖数量、跟帖内容、跟帖作者、跟帖日期和时间。
2.3 大学生网络舆情检测模型
以天为计时单位。设ai表示第i天的衍生贴数量(个),表示第i天的历史平均衍生贴数量(个),则第i天的舆情指数为

统计出每天的舆情指数u1,u2,...,就形成了动态指数,如表1所示。
如果以时刻i为横轴,以舆情指数为纵轴,可以画出动态指数图。
从2007年5月4日至2018年3月17日的动态指数,如图1所示(剔除了指数为0)。
另外,从2007年5月4日至2018年3月17日的最大指数是53.9,具体日期是2013年8月19日,意味着这一天的帖子数量是历史平均值的53.9倍,其主题是“亲,你遇到了么?”,进一步查看帖子内容(略),大部分是关于寻找在温州的老乡的帖子。中国人普遍具有浓重的老乡情节,当大学生收到录取通知书之后,即将从全国各地来到陌生的温州,此时如果能够遇到老乡,那么就有了类似于亲人一样的、可以互相依赖和帮助的朋友,于是通过网络查找老乡就成为一条便捷的途径。
2.4 大学生网络舆情预警
为了预警,需要确定舆情指数的合理界限。如果舆情指数超过了这个界限,就发出预警信号。从表1和图1可知,一方面,舆情指数为0的指数占比很大,是32.8%;另一方面,舆情指数的极差也很大,是53.9。于是将原指数中的0 指数剔除,并针对非0 指数实施以7 天为窗口的移动平均,再画出舆情指数的直方图,如图2所示。

表1 部分舆情指数

图1 2007/5/4—2018/3/17的舆情指数
从图2 可知,非0 指数呈现负指数分布。给定显著性水平α=0.01,估计其均值得μ=3.0475,指数分布的参数λ=1/μ≈0.328,指数分布的概率密度函数为


图2 舆情指数直方图
2.4.1 大学生网络舆情预警级别的设置
本文将预警级别设定为“黄色、橙色和红色”三个级别。
给定显著性水平α,置信度1-α对应的分位数记作μα。如果舆情指数超过分位数μα,则发出预警信号。于是给定三个不同的显著性水平α=0.1、0.05、0.01,预警级别的临界值即可确定,如表2所示。

表2 预警级别临界值
2.4.2 大学生网络舆情预警级别的设置结果
不同显著性水平下的指数分布检验、分位数和均值估计结果如表3所示。

表3 指数分布检验、分位数和均值估计
从表3 可知,在0.01 的显著性水平下,非0 指数服从指数分布。于是,舆情指数预警的临界值如表4所示。

表4 预警临界值
从2017 年7 月1 日至2018 年3 月17 日的非0 舆情指数预警图,如图3所示。

图3 2017/7/1—2018/3/17的舆情指数及预警线
从图3和表1可知,在2017年8月15日和25日分别发出了橙色预警信号,需要引起关注。
查看2017年8月15日的发帖主题,分别是“毕业老学姐解答专升本疑惑”和“在浙工贸的70 件事”。查看2017 年8 月25 日的发帖主题,分别是“毕业老学姐解答专升本疑惑”、“开学骗术多——揭秘那些常见骗术”、“掉进染色桶里的工贸”和“在浙工贸的70件事”。
可见,跟帖增多的原因是学生对“专升本”话题很感兴趣,对“开学骗术”和工贸学院话题很关注。究其原因,首先,大二学生即将升入大三,一部分学生开始考虑专升本的诸多问题了;其次,新生即将报到,为了防止被骗对开学骗术自然就很关注;第三,毕业生可以回顾在大学的三年期间发生的历历往事,记录美好瞬间、回味幸福时刻、抒发离愁别绪,每一件事都成为工贸学院的特写,也成为即将来到工贸学院的准大学生们感兴趣的事件,引起他们的关注就不足为奇。
2.5 热门主题的关键词搜寻
将触发预警的主题称为热门主题。对于热门主题,我们需要进一步确定吧友们讨论的关键词是什么,例如对于专升本这个热门主题,关键词是“辅导、考试、报志愿、高等数学”里的哪一个?因此需要建立关键词搜寻模型。
2.5.1 文本预处理
采用中科院计算所的汉语词法分析系统ICT⁃CLAS 对文本进行分词,形成词语集,然后选择名词、动词和形容词作为特征词,一共340 6 个。以向量表示文本,设X表示一条文本,则

其中,wi表示第i个特征词的频数,m是特征词的个数。
2.5.2 特征词指数
由于舆情指数反映了衍生贴的相对数量,而每一个衍生贴是由特征词表示的,在热点帖子已经确定的情况下,如何测量特征词的热度呢?本文使用特征词指数来度量特征词的热度。
设有m个特征词,有n个文本,第i个特征词在 第j个文本中的频数记作aij,aij≥0,i=1,2,...,m,j=1,2,...,n。
对于第i个特征词,在第j个文本中出现的次数越多,说明其反映大学生的心理愿望越强烈,则热度越大,于是第i个特征词在第j个文本中的热度使用频率来度量,即

第i个特征词的平均热度为

对于第i个特征词,在各个文本中出现的次数越多,说明讨论它的大学生越多,则热度越大,于是第i个特征词的权系数为

其中,
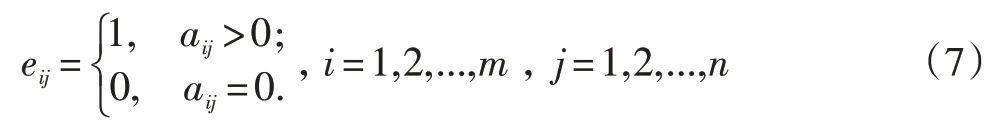
第i个特征词的加权热度为

第i个特征词的归一化加权热度为
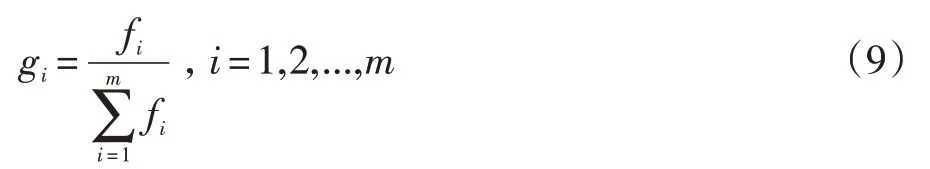
归一化加权热度gi∈[0,1]。
称归一化加权热度超过某阈值的特征词为关键词。于是,通过设置一个合适的阈值ε,可将关键词筛选出来。
2.5.3 关键词搜寻结果
以2017年8月15日引起橙色预警为例,针对主题“毕业老学姐解答专升本疑惑”,设置阈值ε=0,并删除无意义的词,关键词搜寻结果如表5所示。
将表5 中这些关键词联系起来分析,可以推测吧友们讨论的主要话题,比如:“专升本报考的学校和专业”“考试要求”“会计”“数学”“找到女朋友”“难易”,等等。作为即将专升本的学生,他们关心的话题自然是考试要求、考试内容、难易程度、报考学校以及专业;由于工贸学院的会计专业学生的入门录取分数高,学生基础扎实,所以专升本的学生自然就多;在专升本的考试科目中,数学是关键,既容易得分又容易失分,区分度大,数学自然成为学生讨论的话题;至于“找到女朋友”,可能是某些男生希望专升本之后快速的找到女朋友吧。
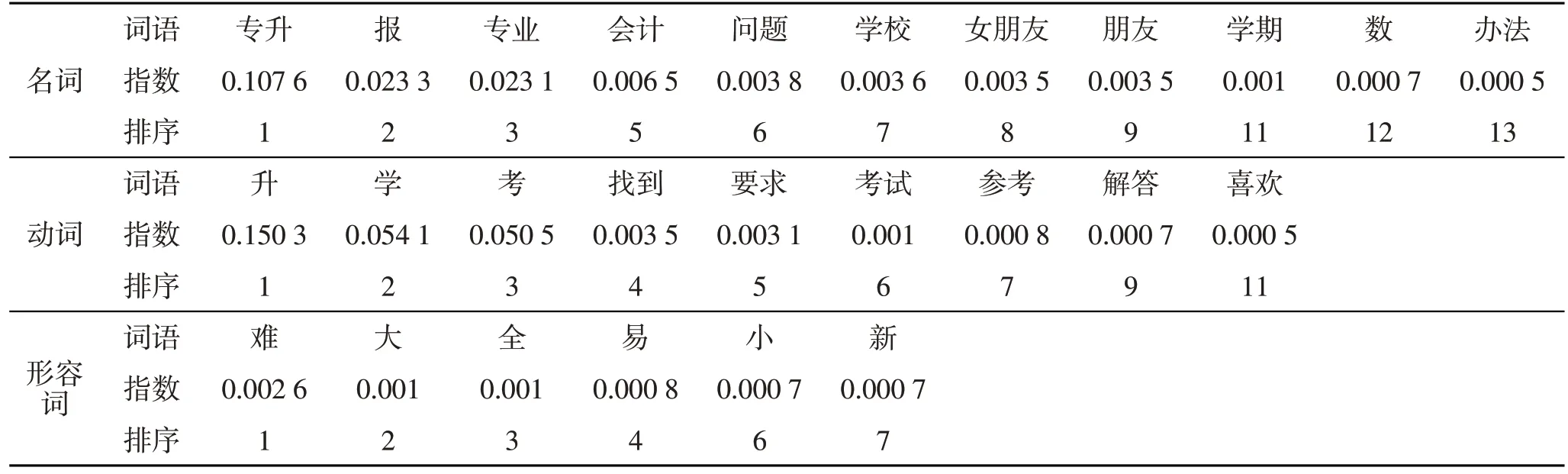
表5 关键词搜寻结果
3 研究结论
本文以百度贴吧里从2007年5月4日至2018年3月17日的学院大学生网络聊天文本信息为研究对象,建立了网络舆情检测模型,实现了大学生网络舆情的定量检测。然后设置了三级预警反应机制,实现了网络舆情异常状况的预警和热门主题的捕捉。最后,建立了特征词指数,实现了对热门主题里的关键词捕捉。获得的结论如下:
(1)最大指数发生的日期是2013 年8 月19 日,其主题是“亲,你遇到了么?”,帖子内容是寻找在温州的老乡。
(2)在2017 年8 月15 日和25 日分别发出了橙色预警信号,其中,2017年8月15日的发帖主题分别是“毕业老学姐解答专升本疑惑”和“在浙工贸的70 件事”;2017 年8 月25 日的发帖主题分别是“毕业老学姐解答专升本疑惑”、“开学骗术多——揭秘那些常见骗术”、“掉进染色桶里的工贸”和“在浙工贸的70件事”。
(3)搜寻热门主题“毕业老学姐解答专升本疑惑”的关键词,分别是“专升本报考的学校和专业”“考试要求”“会计”“数学”“找到女朋友”“难易”,等等。
综上所述,通过研究高校网络舆情,建立和健全舆情监测和预警机制,可以实时掌握大学生的思想动态,及早发现突发事件的苗头,主动解决学生的思想问题,优化高校思想政治教育方法,对于维护校园和谐发展,促进社会稳定具有重要意义。
