基于最优定权组合法的大气污染物SO2预测①
2019-03-11铁治欣宋飞扬丁成富
谢 磊,铁治欣,宋飞扬,丁成富
1(浙江理工大学 信息学院,杭州 310018)
2(聚光科技 (杭州)股份有限公司,杭州 310052)
SO2作为大气中主要污染物之一,既能导致空气质量变差,又能在空气中迅速氧化生成SO3进而通过异质核化过程形成液态气溶胶[1],降低了大气的能见度.同时,高浓度的SO2也是形成酸雨的罪魁祸首[2],严重影响水环境以及农作物的产量,给人们的身心以及日常活动带来严重的影响.所以,实现对大气中SO2的精准预测,从而达到对空气质量的精准预警预报变得尤为重要.目前,在空气质量预报领域展现出良好应用前景的预报模式包括:CMAQ、CAMx、WRFCHEM、NAQPMS等[3].但是由于各模式本身的不确定因素较大,在一定程度上影响了空气质量的预报结果,导致对SO2的预测不精准,为了提高对大气中各污染物浓度的预测准确度,以集合的形式把多个空气质量预报模式的预报结果集合在一起的预报方法已经成为提高预测大气污染物浓度的有效决策和方法[4].
目前,运用在大气污染物集合预报中较为广泛的方法包括以下几种:a)算术平均法.它具有算法简单且能够很好地反映出预测结果的整体趋势等优点.如:王自发等[5]基于多个空气质量预测模式(CMAQ、CAMx、NAQPMS)构建出业务化的北京空气质量集合预报系统(EMS-Beijing),该系统预测结果主要依赖于各模式的算术平均值.但是仅仅利用算术平均法进行集合预报获得的结果值极易受到极个别异常值的影响.Mallet等[6]在不同的初始条件下,互相组合构建了几十种空气质量预报模式系统,发现只是简单的平均集合方法并不能显著地改进预报结果,并且平均集合方法的使用范围总存在着一定的局限性,需要引入一些其它的方法才能改进预报性能.b)多元线性回归法.该方法通过研究多个自变量和因变量的线性关系,计算出一个拟合度较高的回归预测模型,能够很好地度量各个因素之间的相关程度.如:黄思等[7]利用多模式集合和多元线性回归改进北京PM10预报,通过将历史观测信息纳入到北京空气质量集合预报系统(EMSBeijing)预报体系,并对EMS-Beijing三个集合成员的预报结果进行集成,能够很好的分析出影响集成预报的影响因子,提高了预测的准确率.c)动态权重分配法.这种方法通过分析在一段时间内各模式预测值的偏差率动态调整集合模式的权值,有效地提高了集合模式的预测准确率.如:姚文强等[8]针对杭州市的空气质量情况,提出了一种动态权重更新模型并与已有的平均预测模型进行比较,结果表明比简单平均集成效果更好.但是通过单个预测模型的集成方法的适用性存在一定的局限性,且预测准确率不稳定[9].张春萍等[10]在进行区域物流量的预测当中,基于多个单项预测模型的预测结果,采用最优定权组合模型以误差平方和最小为原则求得各单项预测模型的最优权值,有效地解决了单项预测模型准确率不稳定,适用性不高等问题,查阅相关资料得知有关最优定权组合预测模型在空气质量预测方面鲜有介绍.
因此,本文通过采用三种国内应用成熟、业务化程度高的空气质量预测模式(CMAQ、CAMx、WRFCHEM),结合云南省的地势、气候、污染源等特点,提出了一种基于最优定权组合预测模型的集合预测方法将上述三种预测模式的结果进行集成,并通过误差分析验证所提方法的有效性.
1 模式系统与数据介绍
1.1 系统的介绍
云南省省级空气质量预报预警平台所采用的多模式集合预报系统成员分别是由美国国家海洋和大气管理局(NOAA)预报系统实验室开发的WRF-CHEM[11],美国国家环境保护局研发的CMAQ[12]系统以及美国环境技术公司Environ维护并研发的CAMx[13]组合而成.上述三种模型被广泛的应用于国内外的空气质量模拟领域,但各个模式输出的格式各有特点,在定制化的过程中,因为变量名、变量组别的不同,为集合预报带来了极大的挑战.为了实现模式的统一化管理与展示,参考国家环保部发布的《环境空气质量指数(AQI)技术规定》,将三种不同的模式集成到同一个系统平台上,气象场采用中尺度WRF模式,初始场采用GFS数据集.云南省多模式集合预报系统框架如图1所示.
首先基于不同污染源的排放特征,通过SMOKE源排放模型对排放源清单进行处理,为各单项空气质量模式提供所需要的大气排放源清单的时空分布数据.然后利用气象模式WRF对GFS数据集进行分析计算,并按照各单项空气质量模式的运行需求将上述计算结果转换成其所需要的气象文件.最后将气象模式和源排放模型的计算结果作为各单项空气质量模式的输入计算出各模式对应的SO2预测值,并分别采用最优定权组合预测法、多元线性回归法和动态权重更新法对上述各单项空气质量模式的SO2预测值进行集成,从而实现多模式集合预报.这一系统已经应用于云南省环境检测中心,为云南省的空气质量预报提供更加准确的预报数据.

图1 云南省多模式集合预报系统框架
1.2 网格嵌套设置
本文重点针对云南省环境监测中心业务化运行的云南省省级环境空气质量预报预警业务平台进行分析与集成研究.为了便于系统采用的三种不同模式的集成以及减小因为不同的区域设置而带来的误差,本系统采用统一的区域设置、统一的排放清单、统一的气象场驱动,以云南省为中心的三重网格设置.第一重网格包括中国中西部地区,范围如图2中的D1所示,网格精度为 27 km,网格数 (东西×南北)为 141×134,第二重网格包括中国西南地区,范围如图2中的D2所示,网格精度 9 km,网格数为 219×219,第三重网格包括云南全省,范围如图2中的D3所示,网格精度为3 km,网格数为327×327.
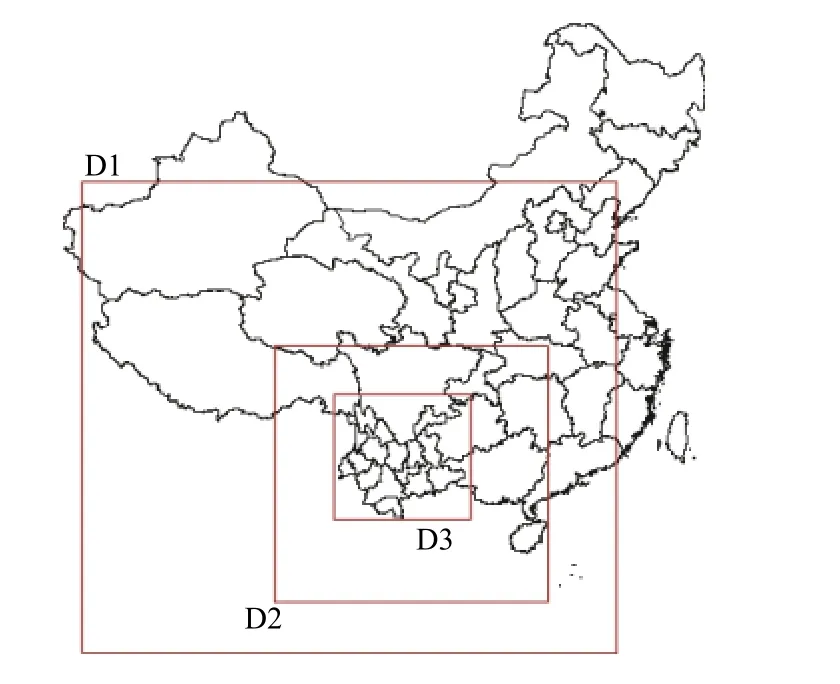
图2 云南省多模式集合预报系统网格设置简图
1.3 运行环境
云南省环境监测中心预报预警业务平台采用多模式集合预报系统的环境为 Red Hat Linux 7.3,编译环境为 Intel Fortran,并行环境为 MPI和 OpenMP 混合并行,运行所用核数为48核/96线程,同时安装了Intel C/C++编译器、GNU C/C++编译器.
1.4 实验数据
本文所采用的数据均来自于云南省省级环境空气质量预报预警业务平台数据库,为保证数据的有效性,该数据库数据均经过自动审核系统的过滤和筛选.其中观测数据分别来源于云南省蒙自、楚雄、昭通三个区域站点在2018年1月至6月期间的SO2日均实测值.模式输出数据来自模式第三重网格的预报结果,根据我国执行的空气污染指数标准,利用当天的12时至第二天的11时的SO2预报值计算日均值.
2 集成方法和评价指标
2.1 本文的最优定权组合预测模型
组合预测最早是由Bates和Granger提出来的[14],其基本思想是即使某一单项预测方法的预测精度很差,我们也不能随意丢弃任何一种预测结果,因为这种做法极有可能造成某些有用信息的丢失,把它和某一种或几种预测精度较高的方法进行组合,完全有可能提高系统的整体预测能力,比较科学的做法是通过某种方法将各单项预测方法进行组合集成,综合利用各单项预测方法的优势,从而获得优于各单项预测方法的预测能力.
组合预测的关键[15]是如何确定各组合成员的权重系数,对于多模式空气质量数值模式集合来说,传统的方法是主观赋权法,通过相关领域的专家根据经验进行主观判断得到相应的权重系数,这种方法的主观因素较多,随意性较大,不同的专家给出的结果不同.还有一种是普通的平均定权法,虽然方法简单,但是如果某一组合预测成员的误差极大,通过平均定权后很容易影响整个系统的预测精度.而最优定权组合法基于误差平方和最小原则求得最优加权系数,它综合了各种单项预测模型的优势,充分利用各种单项模型提供的有用信息达到提高预测准确度的效果,不仅能克服上述缺点,而且还能在一定程度上分散组合预测模型中选择不当的风险.
利用最优定权组合法集成的思路如下:通过应用多个单项空气质量数值模式(WRF-CHEM、CMAQ、CAMx)对SO2的浓度进行预测,并计算出相应的单项模式预测误差,然后将各单项预测误差以不同的权值建立出组合预测误差方程,并以误差平方和最小为原则建立目标函数对组合预测误差方程进行优化,最后在一定的约束条件下求出目标函数的最优解.
具体建模步骤如下:假设SO2的观测值序列为Y={yt,t= 1,2,… ,n} ,其中yt为第t时刻的实际观测数据.利用m种单项预测模型对SO2浓度进行预测,设第i(i=1,2,… ,m)个单项预测模型在第t时刻的预测值为,且第i个单项预测模型的权值为ki,并且满足,则第t时刻组合预测值可表示为:
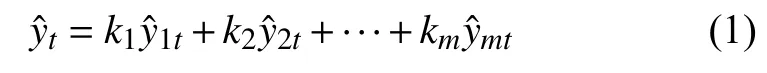
令第i个单项模型在t时刻的单项预测误差为eit,则eit可表示为:

令et为组合预测模型在第t时刻的组合预测误差,则et可表示为:

令J为组合预测模型的误差平方和,则有:


则式(4)的矩阵表达式如下所示:

令R=(1,1,···,1)T,则可以表示为:

由此可知我们要做的就是在式(6)的约束条件下,求出最优加权向量K,使得此时的误差平方和J最小,即:

利用拉格朗日乘子λ对式(7)进行求解,则J可以表示为[16]:

若想求得J的极值,则J对K的一阶偏导必为零[16],则:
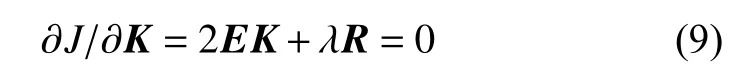
将式(9)两边左乘E-1可得:
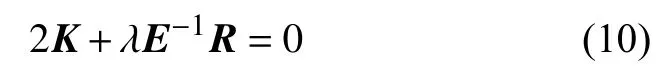
将式(10)两边左乘RT可得:

将式(6)带入式(11)即可得到 λ的值:
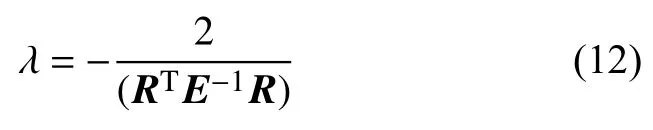
将式(12)带入式(10)即可得到K的值:

又由式(6)可得:
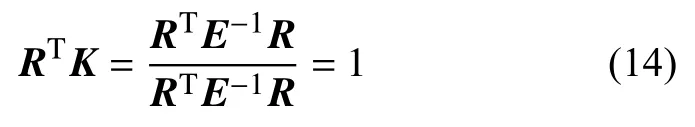
从而得出结论,由式(13)求得的最优权重满足式(6)的约束条件,即表明式(13)求得的K就是最优加权系数向量,且此时的J值就是极小值.
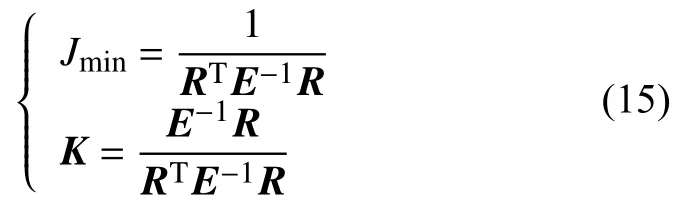
最后将求出的最优权重K代入式(1),即可求出t时刻的最优预测值.
2.2 多元线性回归法
多模式集合预报系统的预报结果往往受到多个单项预报成员的影响,由于各单项预报模式的预报性能不同,不同模式对SO2的预测准确程度不同,所以为了分析各单项预报模式之间的相关性,采用多元线性回归的方法[7]对各模式的预报结果进行集成预报,通过大量的样本值做回归分析,建立拟合度较高的回归方程.

2.3 动态权重更新法
动态权重更新[8]通过评估一段时间内单个预报模式的预测值和实际观测值的偏差情况,从而可以动态调整各单项预报模式在集成预报中的权重,其优点在于各单项预报模式的权重分配依赖于实际的监测数据,具体操作步骤如下:
设第i个数值预报模式第j天的SO2预测值为,第j天的实测日数据为Yj,则该模式的偏差率为:

然后根据第i个模式每天的偏差率计算出总共m天内的平均偏差率Rim.定义一个过渡因子Vi,且该过渡因子与权重系数呈线性关系,与预测偏差率呈反比,则Vi可表示为:

设单个模式的权重为wi(i= 1,2,…,n),且满足,则wi可表示为:

最后将求得的权重和相对应的模式预报结果进行加权计算即可得到多模式集成预报结果.
2.4 评估方法
根据统计学的相关性原理,本文通过使用误差平方和 (Sum of Squares for Error,SSE)以及均方百分比误差 (Mean Square Percentage Error,MSPE)两个评价指标对各预测模型的准确度进行评估分析.
(1)误差平方和:
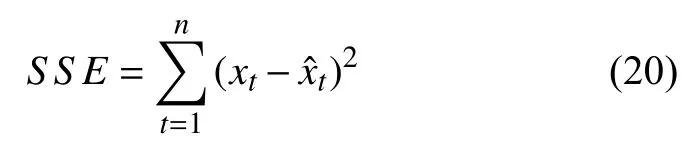
(2)均方百分比误差:

其中,n表示实验样本总个数,为第t时刻单项预测方法的预测值,xt为第t时刻的实测值.
SSE表征的是由于模式的输入、排放清单采集不合理以及模式自身的一些物理和化学参数导致预报结果与实际观测值的偏差.其值越大,表明与测定值之间的差异越大.MSPE则表征各模式的平均误差水平.其值越小,表明模式的预测值与实际观测值的误差值越小,即预测的偏差值更小.
3 实验结果
3.1 单项模式预测评估
为了了解单个空气质量模式的特点以及它在不同站点对SO2的预测能力,本文收集了2018年6月份云南省蒙自、楚雄、昭通三个站点各单项空气质量预报模式(CMAQ、CAMx、WRF-CHEM)的SO2预测值和日均实测值.通过对比不同区域的各单项预报模式预测结果,利用SSE与MSPE两项指标评估多模式集合系统中三个空气质量模式对不同站点SO2的预测能力,结果如表1所示.
观察表1中数据发现,在蒙自站点的误差分析中,CMAQ模式的SSE以及MSPE在三种模式误差对比中最小,说明该模式的预测能力最好,CAMx模式的预测能力次之,WRF-CHEM模式的预测能力最差.而在楚雄站点的误差分析中,对SO2预测较为精准的模式是WRF-CHEM和CAMx,CMAQ模式的预测能力最差.在昭通站点的误差分析中,WRF-CHEM和CMAQ模式的预测能力较为精准,CAMx的预测能力最差.
由此可知,对于不同的区域,不同的模式预测能力相差较大,每种模式在不同区域的优点各有不同.通过进一步对比不同区域的三种模式的预测结果可得,没有任何一种模式在不同区域的预测结果完全优于其它两个模式,从而在一定程度上证明了单项空气质量模式对大气污染物浓度的预测仍存在一定的局限性.
表1 各单项模式在不同区域的误差分析
3.2 最优定权组合法集成预测评估
为了充分利用各单项空气质量预测模式的优势,验证本文所提出的最优组合预测模型(OWCF)的有效性,选取多元线性回归法(MLR)和动态权重更新法(DWA)与本文提出的最优组合预测法分别对各单项空气质量预报模式(CMAQ、CAMx、WRF-CHEM)的预报结果进行集成对比实验.即在相同的实验条件下,分别利用蒙自、楚雄、昭通三个站点2018年1至5月份的SO2实测值和上述模式预报数据构建出预测模型,对各站点2018年6月份的SO2浓度值进行预测,并与各站点六月份的实测数据(REAL)进行对比验证,最后通过绘制对比图的方式将各方法的预测结果与实测结果进行对比分析,实验结果如图3-图11所示.

图3 MLR 预测结果图(蒙自)

图4 DWA 预测结果图(蒙自)

图5 OWCF 预测结果图(蒙自)

图6 MLR 预测结果图(楚雄)
由图3-图11中不同站点的预测结果对比曲线可以看出,在大多数时间内,三种方法的预测结果均与实测结果(REAL)的拟合曲线趋势一致.但是相较于本文所提的OWCF,MLR和DWA所预测的结果准确率不高,偏差较大,而OWCF的结果值更加接近于实测值,预测准确率更高.

图7 DWA 预测结果图(楚雄)
图8 OWCF 预测结果图(楚雄)
图9 MLR 预测结果图(昭通)
为了定量地分析最优定权组合预测模型的特点,分别运用SSE与MSPE对三种预测方法的预测精度实行评估检验,其结果如表2所示.
表2表示通过采用式(20)和式(21)对三种预测方法在不同区域的预测结果进行评估分析,由表中数据可知,在蒙自站点中,MLR和DWA的SSE分别为179.82、218.05,本文所提的OWCF的SSE与以上两种方法的SSE相比分别降低了143.65、181.88.从MSPE的角度来看,MLR、DWA的均方百分比误差分别为 0.047、0.054,OWCF 的MSPE为 0.022,与以上两种方法相比分别降低了0.025、0.032个百分点.同样,在楚雄站点和昭通站点的数据中,本文所提的OWCF预测法的预测精度都存在不同程度的提升,SSE、MSPE均最小.

图10 DWA 预测结果图(昭通)

图11 OWCF 预测结果图(昭通)

表2 三种预测方法在不同区域的误差分析
且通过对比表1中单项模式的误差可知,在蒙自站点中,预测能力最好的单项模式是CMAQ,其中SSE为254,MSPE为0.056.而通过采用本文所提的OWCF法将各模式结果进行集成所获得的SSE为36.17,MSPE为0.022.说明本文所提方法的预测精度即使和单项预测模式中预测精度最优的模式相比任然存在一定的优势.同样,在楚雄和昭通站点中,OWCF和各站点单项最优的预测模式相比,OWCF的SSE和MSPE均最低.
由以上分析可知,通过与单项预测精度最优的模式以及采用不同方式的集成方法预测效果相比较,本文所提的OWCF有效的提升了SO2的预测准确度,从而证明了本文所提方法的可行性.
4 结语
本文基于多个空气质量预测模式(WRF-CHEM、CMAQ、CAMx),以误差平方和最小为原则,提出了最优定权组合预测模型.采用2018年1至5月份云南省三个监测站点(蒙自、楚雄、昭通)的SO2浓度实测值和多个单项空气质量模式的预测值作为实验数据,与现有的多元线性回归法、动态权重分配法等预测方法对前述三个站点2018年6月份的SO2浓度进行预测,并对各模型的预测误差进行评估分析.实验结果表明最优定权组合预测模型的预测准确率最高,效果最佳,为云南省空气质量预警预报平台提供一种高效的预测方法.
