基于分布式集群的网络浏览行为大数据分析平台构建
2019-03-06蔡艳婧
蔡艳婧,王 强,程 实
(1.南通大学,江苏 南通 226019;2.江苏商贸职业学院,江苏 南通 226011)
0 引 言
随着互联网快速发展,用户利用网络技术可体验到多样化、高速率的网络服务[1]。互联网中的用户呈现爆炸式增长,用户在网络上产生海量的数据,构建大数据分析平台能够从大量数据中分析出用户上网的共性与个性特征,挖掘用户上网内容偏好等行为习惯规律[2],提升网络资源配置。完整、高效的大数据分析平台为大数据运用提供一站式基本服务[3],对实现网络浏览行为大数据的准确分析具有重要意义。
文献[4]基于大数据处理技术的AIS应用研究,只利用弹性数据集构建分布式数据库实现AIS数据分析,无法实时满足大数据分析需求,不能挖掘出网络浏览行为。文献[5]基于大数据的网络舆情分析系统模型,只针对大数据技术处理网络舆情数据进行初步探索,缺乏大数据挖掘过程,分析网络浏览行为存在一定的局限性。文献[6]提出大数据环境下的分布式数据流处理关键技术,只分析分布式数据流处理技术,同样缺乏数据的挖掘和管理过程,分析网络浏览行为大数据效果差。
为解决上述问题,本文构建基于分布式集群的网络浏览行为大数据分析平台,提高网络浏览行为大数据分析的效率。
1 基于分布式集群的网络浏览行为大数据分析平台
1.1 平台总体结构设计
构建的基于分布式集群的网络浏览行为大数据分析平台的结构用图1描述。
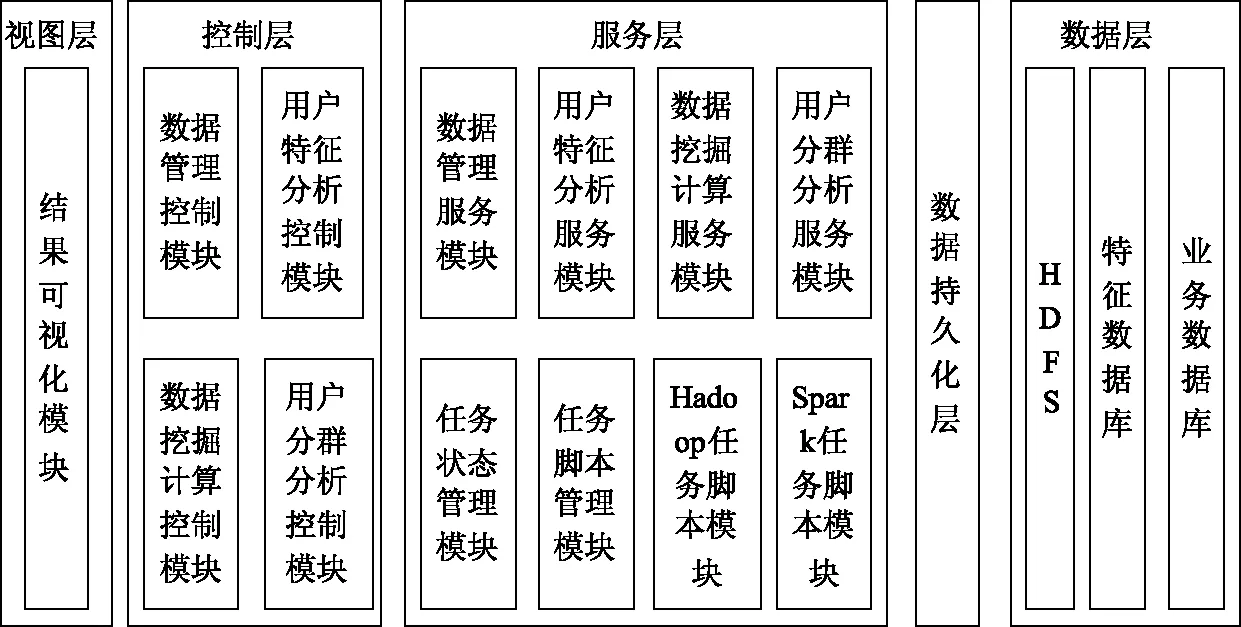
图1 平台架构图
本文平台层次结构分明,针对大量用户网络浏览行为产生数据实施存储与管理问题,平台使用分布式存储系统HDFS与分布式计算系统Spark组成的分布式集群[7]。图1描述平台架构图分为五层,分别为:
(1)视图层:将用户请求操作发送至前端Web界面再发送至控制层,由前端Web界面呈现用户请求操作结果。视图层调用Echarts插件对数据概况和挖掘结果分别使用折线图和柱状图等方式呈现给用户[8],能够直接了解用户网络浏览行为分析的数据结果。
(2)控制层:视图层将数据上传、清洗等请求发送到控制层。控制层收集视图层用户操作信息与数据,再发送到服务层处理,同时接收服务层处理后的结果,将结果反馈到视图层呈现在前端[9]。控制层由四个模块组成:采用数据管理控制模块解决前端数据管理场景中数据上传和数据清洗等相关请求,分析前端的文件名与文件流,调用数据管理服务模块将数据上传到HDFS中,这一过程为数据上传请求;通过用户特征分析控制模块管理前端用户网络浏览行为特征,分析场景中数据多维与相关性等请求;采用数据挖掘计算控制模块控制数据挖掘任务中分类分析的创建任务,以及实施任务的生命周期,管理前端挖掘计算场景相关请求[10]并调用数据挖掘计算服务模块实现具体操作;利用用户分群分析控制模块管理前端用户分群分析操作请求,并调用用户分群分析服务模块实现具体操作。
(3)服务层:管理控制层请求,依据控制层请求对应的数据模型完成相关操作。数据模型的增减查改操作由服务层中对应的四个服务模块控制;Hadoop与Spark分布式集群的计算能力由服务层中两个管理模块与两个脚本模块调配使用,处理异步化的具体情况为:采用任务状态管理模块管理Hadoop与Spark任务创建与结果查询等的生命周期;通过任务脚本管理模块处理任务脚本信息与类型等对应的不同分布式服务[11],出现新的分布式服务时只需在任务脚本管理模块直接注册即可;为能够让用户实时了解服务模块的管理步骤,得到异步操作的目标,采用多线程把脚本发送至集群Spakk分布式集群中分析。
(4)数据持久化层:增减改查数据方式和封装数据持久化方式通过Hibernate完成,确保数据模型映射到数据库内。
(5)数据层:在HDFS内存储用户的网络浏览数据源,在MySQL数据库内存储特征数据与业务数据,数据层管理HDFS和MySQL数据的存储过程[12]。使用HDFS分布式文件系统存储海量网络用户浏览数据的数据源。特征数据库利用MySQL缓存数据的统计分析挖掘运算结果,将用户网络浏览数据状况等相关内容直接呈现在前端。
1.2 平台动态流程设计
以数据源上传与数据挖掘计算为例,详细介绍平台的动态流程。
(1)数据上传流程设计
平台把数据源上传至HDFS内的过程则是数据源上传,该过程实现了海量网络浏览数据源的存储。平台利用多线程方法和任务状态管理模块控制文件上传任务的生命周期,减少文件上传时I/O堵塞情况。图2描述了数据源上传流程图。
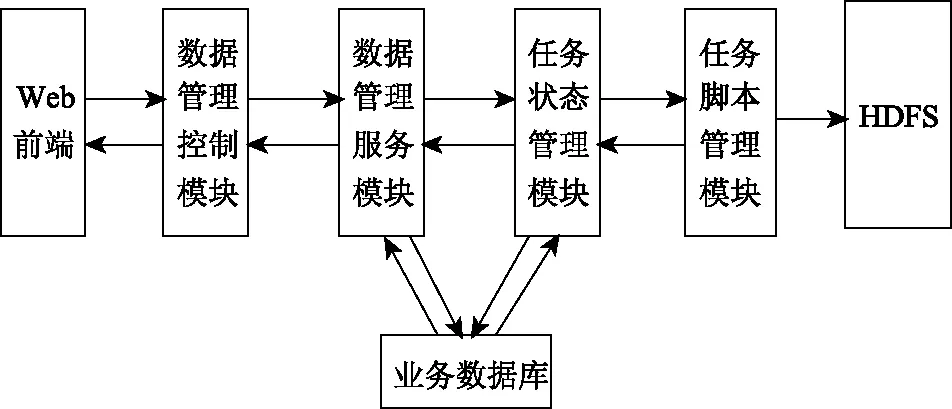
图2 数据源上传流程图
图2描述的数据源上传流程为:通过Web前端获取用户发出数据上传请求的数据源文件;为得到数据上传请求内的文件名等参数,管理控制层的数据管理控制模块上传数据请求,并调用服务层的数据管理服务模块实施上传;任务状态管理模块同数据管理服务模块间的数据传递完成数据上传任务,并将上传请求成功的结果返回控制层;文件状态为上传中时,视图层呈现出反馈成功的结果,由数据管理控制模块转换为json格式,用户通过Web前端了解到该数据源的文件名、状态等信息。
(2)数据挖掘计算流程设计
平台使用数据挖掘计算功能,可以让用户直接在Web页面通过决策树方式挖掘数据。用户为获取可视化结果,选取已完成的数据源,利用数据挖掘与填入算法的参数,在Spark分布集群内运算数据挖掘任务。平台利用异步实施方式,提高用户体验与平台易用性。平台管理用户提交的数据挖掘任务信息,由前端页面呈现该任务的实时情况,分布式聚类运算由异步任务调用Spark,并在后台运算,任务完成后便可查看任务结果[13]。图3描述数据挖掘计算流程图。
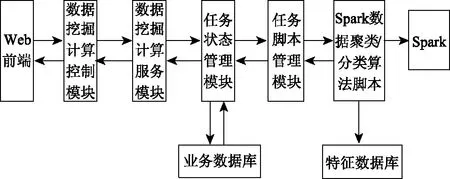
图3 数据挖掘计算流程图
分析图3可得,数据源列表在前端页面呈现的情况为:用户进入数据挖掘计算页面后,数据源列表是由数据挖掘计算控制模块对数据挖掘计算服务模块发起请求,通过任务状态管理模块从业务数据库中获取数据源信息,并将该信息逐层返回到前端;用户选取已存在数据源并点击下一步,平台支持的聚类算法信息列表由数据挖掘计算控制模块对数据挖掘计算服务模块发出请求,聚类算法的类型、参数列表等信息可从业务数据库内获取,并逐层返回到前端;用户选取与填写对应的算法与参数,将聚类计算任务提交到数据挖掘计算控制模块内,数据挖掘计算服务模块接收挖掘计算控制模块的任务请求,将任务信息通过挖掘计算服务模块加入业务数据库内;聚类计算任务由挖掘计算服务模块调用任务状态管理模块实施,聚类计算任务完成的结果发送至控制层;当前用户能够在页面了解到聚类任务名称、类型等信息。
1.3 平台实现
1.3.1 平台数据管理实现
平台具有数据管理功能,通过数据上传功能能确保用户上传数据集到分布式系统HDFS中,数据管理在Web页面内查询对应信息,数据文件上传、数据文件删除、数据预处理、数据分布特征统计组成数据管理[14],因篇幅有限,平台描述了服务层中每个模块中类的交互与调用关系,如图4描述,上传数据文件过程中,服务层数据源服务模块管理用户选取本地要上传的数据文件,数据文件在Web页面内,用户将上传数据任务请求发送到数据层,分析得到相关参数。
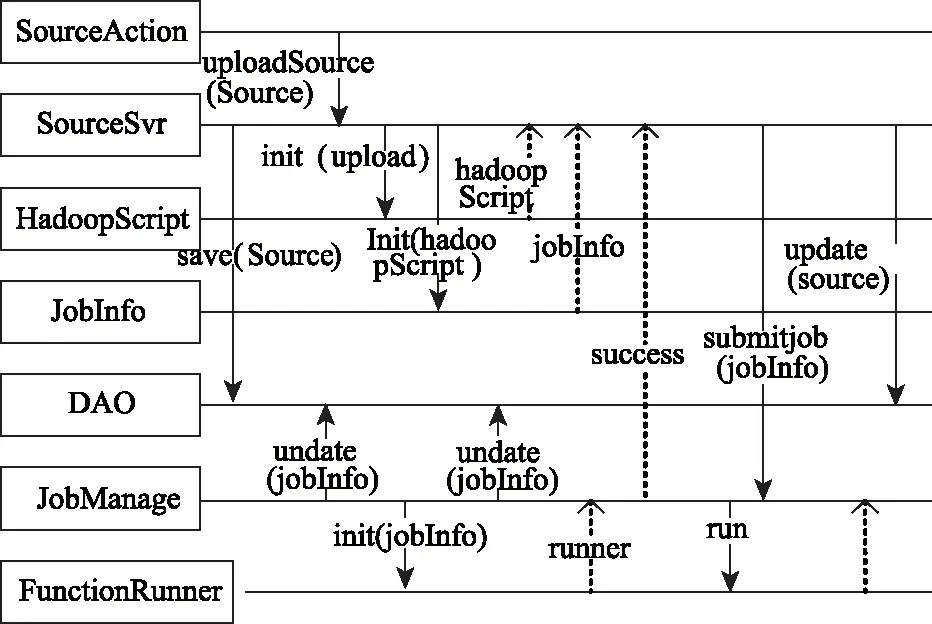
图4 数据上传
分析图4数据上传图可得:HDFS接收用户通过Web前端请求的上传数据,请求上传数据源利用控制层数据源管理控制模块调用服务层中SourceSvr类的uploadSource方式,上传数据名称等参数;source实例是将要上传的数据源,其由SourceSvr类的uploadSource方式初步形成,且业务数据库内接收更新的source,数据源名称、上传用户等构成记录数据源的信息;平台使用HadoopScript类中增添upload方式调用HDFS内的API,将数据上传到HDFS中,通过HadoopScript实例完成数据上传;业务数据库内接收任务信息持久化、规划上传任务时间和状态等信息、上传数据任务由SourceSvr类调用JobManage类submitJob方式实现。
1.3.2 网络浏览行为数据挖掘实现
平台通过决策树算法准确挖掘网络浏览行为,决策树算法能够准确挖掘海量数据中的易解析形式。决策树能够作为数值型数据与非数值型数据存在。决策树ID3算法分析节点的检测属性由最大信息增益属性决定,通过各网络浏览行为检测属性已知值建立决策树的分支,根节点属性的各值都是一个子集,将该步骤规划递归地使用在各子树中,实现子集内元素为同类后停止规划,形成网络浏览行为决策树。
决策树ID3算法假设存在r个不同网络浏览数据{d1,d2,…,dr}在浏览行为检测属性D中,r个网络浏览行为{k1,k2,…kr,}通过利用属性D对总体浏览过程K规划,K内样本体现在Ky中,它们在D上具有值dy,假设检测属性为D,集合K节点的分枝与子集相对应。设定子集Ky中类Px的样本数为Kx,y。公式(1)反映D规划的网络浏览行为子集熵为:
(1)
公式(1)中,第y个子集权为(kx,y,…,kn,y)/k,等于子集内样本个数除以K内的样本总数,D值为d。F(D)与子集规划纯度呈负相关性。公式(2)描述规定的子集Ky为:
(2)
公式(2)内,Ky内样本属于类Px的机率为Qx,y=Kx,y/|Ky|。公式(3)反映D上分枝得到的信息增益为:
H(D)=X(k1,k2,…,kn)-F(D)
(3)
公式(3)内,信息增益通过网络浏览行为检测属性D值引起的期望压缩为H(D)。将运算得到的最大属性信息增益当成集合K的检测属性。决策树ID3算法利用相同的步骤,递归的构建网络浏览行为样本判定树,实现网络浏览行为的准确挖掘[15]。
2 实验分析
实验为了检测本文平台的有效性,对本文平台的功能与性能进行测试,详细过程为:
2.1 环境部署
构建硬件环境中,本文平台利用7台设备为E5-2620V3 CUP、128G内存和1TB硬盘的联想服务器构建底层分布式集群。HDFS分布式文件系统、Yarn分布式资源管理和Spark分布式集群部署在底层分布式集群内,在7台服务器内选取1台服务器为主节点,剩余6台服务器为从节点。在构建软件环境内选取适用性较高的软件。
2.2 平台功能测试
平台功能测试由界面逻辑和整体结构两点出发,检测用例依据平台要求撰写,实验详细研究本文平台的功能,分析本文平台的数据源上传、数据预处理以及聚类分析功能的实际结果能否达到预期效果。
实验检验本文平台能否成功向HDFS反馈数据管理模块内数据集,数据源上传功能测试用例由表1所示。

表1 数据源上传功能测试用例
实验检验数据预处理功能经过本文平台的数据清洗能否达到规定条件,数据预处理功能测试用例由表2表示。

表2 数据预处理功能测试用例
检验本文平台能否成功实施数据挖掘计算内的聚类分析,并准确获取结果,聚类分析功能测试用例由表3表示。

表3 聚类分析功能测试用例由
由表1、表2、表3了解到本文平台进行数据源上传、数据预处理以及聚类分析的功能符合预期结果,说明本文平台是一种有效的网络浏览行为大数据分析平台。
2.3 平台性能测试
2.3.1 数据源管理的响应时间测试
listAllSources请求为数据源管理请求,数据源信息由listAllSources接口得到,在多用户并发状况下,利用工具Jmeter模拟检测本文平台和基于在线学习的网络浏览行为数据分析平台进行数据源管理的响应时间,用表4描述。

表4 数据源管理的响应时间/ms
由表4得知,在不同的并发数下,本文平台对listAllSources请求与整体响应时间的平均值分别为30.25 ms与843.75 ms;基于在线学习的网络浏览行为数据分析平台对listAllSources请求与整体响应时间的平均值分别为56.75 ms与1352 ms,对比分析可以得出,本文平台对于listAllSources数据源管理请求的响应时间以及整体响应时间比基于在线学习的网络浏览行为数据分析平台分别少26.5 ms和508.25 ms,说明本文平台具有较高的数据源管理响应效率。
2.3.2 用户行为特征分析的响应时间测试
getSummary、perHourUser、topApp、topWeb和serviceType这5个请求是较为关键的网络用户行为特征分析请求,每个维度的统计结果分别由这5个接口得到,各接口接收各维度返回结果,并由前端并行管理5个接口。在多用户并发状况下,利用工具Jmeter模拟检测本文平台和基于在线学习的网络浏览行为数据分析平台进行用户行为特征分析的响应时间,用表5描述。
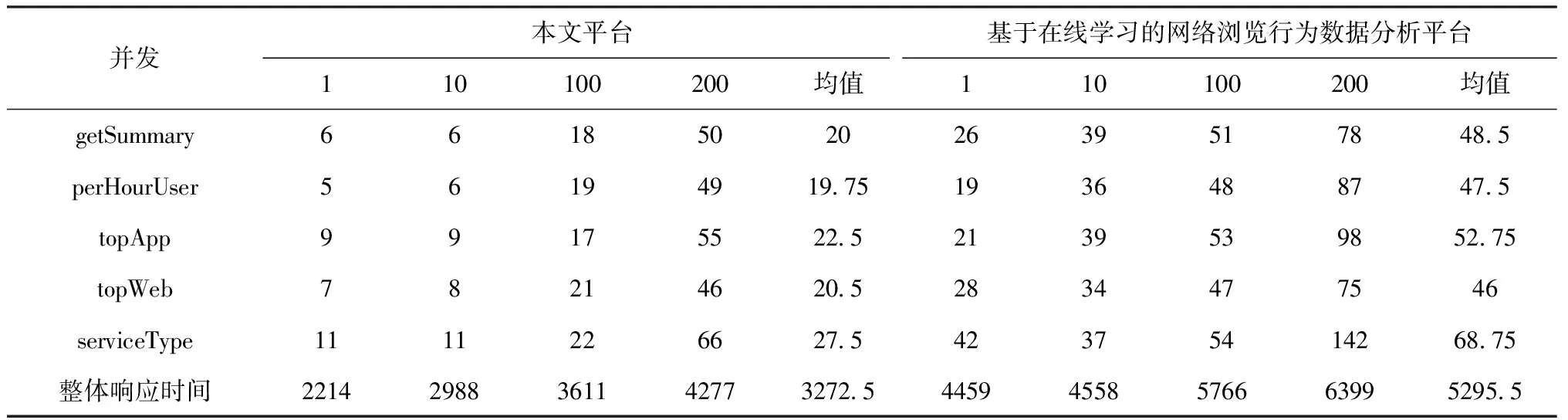
表5 用户行为特征分析的响应时间/ms
由表5了解到,随着并发数的不断提升,两种平台对于5种不同用户行为特征分析请求的响应时间也逐渐提升,但是本文平台的响应时间始终低于基于在线学习的网络浏览行为数据分析平台,并且在相同的并发数下,本文平台的整体响应时间远远低于基于在线学习的网络浏览行为数据分析平台,本文平台的整体响应平均时间比基于在线学习的网络浏览行为数据分析平台少836.5 ms,说明本文平台分析用户行为特征时具有较高的响应效率。
2.3.3 数据挖掘及用户流量分群分析的响应时间测试
本文平台进行数据挖掘与用户流量分群分析的工作机制相同,需要向Spark分布式集群内反馈任务脚本,用户以任务方式请求提交形成的子线程向任务脚本反馈,主要包括同步的任务提交与异步的分布式计算任务,用户体验会受到同步任务提交的影响,其中submitDMJob请求和submitUserAnaJob请求分别是数据挖掘和用户流量分群分析请求。
在多用户并发状况下,利用工具Jmeter模拟检测本文平台和基于在线学习的网络浏览行为数据分析平台进行数据挖掘和用户流量分群的响应时间,用表6描述。

表6 数据挖掘及用户流量分群分析的响应时间/ms
通过表6了解到,本文平台对于数据挖掘submitDMJob请求和用户流量分群行为分析submitUserAnaJob请求的平均时间响应分别为62.25 ms和55.25 ms,而基于在线学习的网络浏览行为数据分析平台对于两种请求的平均响应时间分别为239.25 ms和232 ms,对比分析这些数据可以看出,本文平台具有较高的数据挖掘和用户流量分群响应分析效率。
3 结 语
本文构建了基于分布式集群的网络浏览行为大数据分析平台,通过分布式存储系统HDFS与分布式计算系统Spark组成的分布式集群存储与管理网络浏览行为产生的数据,为用户提供了一站式网络用户浏览行为分析服务,利用决策树ID3算法挖掘用户网络浏览行为。实验分别测试了本平台的功能与性能,得出本文平台的数据源上传、数据预处理以及聚类分析功能符合预期结果,本文平台对数据源管理listAllSources请求与整体响应时间的平均值比基于在线学习的网络浏览行为数据分析平台低26.5 ms和508.25 ms,具有较高的数据源管理效率;本文平台进行用户行为特征分析的整体响应时间比基于在线学习的网络浏览行为数据分析平台低836.5 ms,具有较高的用户行为特征分析效率;本文平台具有较高的数据挖掘与用户流量分群分析的响应效率,综合分析可得,本文平台可完成高效率的网络浏览行为分析,取得了令人满意的效果。
