基于共享内存优化算法的用采终端实时库设计实现
2019-03-06曹子涛许金宇
曹子涛,许金宇,熊 剑
(国电南瑞科技股份有限公司,南京211106)
随着智能电网和智慧城市的快速发展, 以及“电,水,气,热四表合一”的试点应用,国家电网公司大力推进智能用电信息采集系统的建设。 面对日趋增加的各类应用,以及物联网、大数据、人工智能等技术的发展趋势,大量数据存储和计算能力成为越来越重要的问题[1-2],对用采终端的数据采集存储的实时性、高效性提出了更高的要求。 传统的关系型历史数据库需要对磁盘文件进行读写操作,运行效率低,无法满足要求,因此需要高效的实时数据库进行支撑[3]。
用电信息采集终端(简称用采终端)遵循DL/T 698.45《电能信息采集与管理系统 第4-5 部分:通信协议—面向对象的数据交换协议》电力行业标准,其中描述的实时数据可以分为结构化数据和非结构化数据2 类。 结构化数据主要指固定长度和类型的数据,有采集量、参数、控制命令等;非结构化数据主要指长度不定的数据如字节序列、文件等。
目前,针对用采终端设计的实时库较少,同时未考虑对于结构化数据和非结构化数据的区分,因而不能充分的满足性能最优和占用空间最小。 文献[4-5]未对用采终端实时库的实现做深入阐述,未对性能和空间利用率进行研究;文献[6]仅介绍了哈希Hash 索引技术, 未指出内存定位和管理等方法;文献[7]仅给出了粗略的方案设计。 在此所设计的实时库针对这2 类数据的不同特点采用不同的设计方法,以最大化提高运行效率和内存空间利用率。
1 用采终端实时库需求分析
用电信息采集终端是执行电能信息采集、转发控制命令、数据管理、数据双向传输的设备。 数据的采集和管理是用采终端的核心功能,其数据包括实时数据、参数数据、转发数据、控制命令、事件信息、历史数据等。 其中,参数数据、计算数据、采集数据等采集终端的核心任务数据,由于对实时性要求较高,需要存入实时库以便不同的进程进行高效的访问与更新。
用电信息采集终端往往需要连接大量的电能表和采集器, 其连接方式多种多样 (电力线载波、RS485、微功率无线),而且采集设备的地理位置分布广泛,同时要面对各种各样的用户类型,包括大型专变、小型专变、单三相一般用户等[4]。实时、高效地处理如此大量繁杂的数据是用采终端要解决的核心问题。
用采终端的内存容量较为有限,同时内存的使用率对于整个系统的运行情况有着非常重要的影响, 过高的内存使用率会大大降低系统运行速度,因此对于大量数据的处理,在不降低效率的同时尽可能的节省内存空间是非常必要的。
2 用采终端实时库关键技术分析与设计
2.1 用采终端实时库软件架构
实时库位于用采终端的软件架构中的位置如图1 所示。 图中,实时数据库位于平台业务层,管理数据采集、任务调度、通信管理等数据的交换。
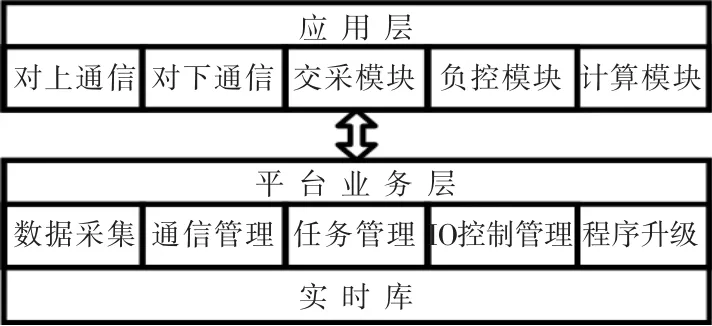
图1 实时库架构Fig.1 Real-time database framework
2.2 实时库索引技术分析与设计
提高实时库的访问速度的关键在于索引,建立合理的索引可以避免遍历查找,从而提高实时库的检索效率。 实时库常用的索引包括数组、自平衡二叉树(AVL)、B/B+树、T 树、Hash 索引等。 AVL,B/B+树、T 树等算法,在性能或者空间利用率上不太适合随机散列查找[6],而考虑到用采系统实时库自身数据类型不固定、随机查找为主的特点,采用Hash 索引作为用采系统实时库的索引机制具备最好的时间和空间的平衡性。 另外,在Hash 索引的基础上,使用Hash 桶来进一步提高查找效率, 同时实现Hash 值的防碰撞功能。
2.3 实时库的共享内存管理技术分析与设计
使用共享内存是实时库的必然选择。 在UNIX中,主要包括进程间通信IPC(inter-process communication)和可移植操作系统接口POSIX(portable operating system interface of UNIX)2 种方法实现[7]。 由于IPC 方法允许使用的内存容量比较有限,考虑到对大量数据的存储要求,故在此采用POSIX 标准的基于文件映射的共享内存,在扩大一定容量的基础上而又不损失性能。
如果使用的共享内存超出系统内存容量,POSIX 标准的共享内存会使用磁盘文件进行缓存,一定程度上降低了效率,因此需要尽可能地在不损失效率的情况下节约内存空间。
另外, 由于非结构化数据的长度不统一性,插入记录时每次会计算分配的地址,从而会有一定的计算耗时, 而如果全部按照统一的长度进行存储,又会造成较多的内存空间浪费。 因此,针对长度固定和长度不固定的数据进行区分设计,可以较好地解决性能和空间的平衡问题。
3 内存数据库的实现
3.1 防碰撞的Hash 桶索引技术实现
每张实时库的表对应另外一个Hash 桶索引表。 选取一个或者多个域作为记录的关键字,内部有N 个桶来存放外部节点信息, 检索时Hash 函数计算该关键字对应的Hash 值, 并将该关键字节点根据特定的规则分别放入对应的Hash 桶中。 检索时,首先根据关键字计算获取该关键字位于哪个桶中,然后进行匹配计算比较Hash 值,同时为了防止碰撞的产生,在Hash 值匹配的情况下,会再次比较关键字本身的值,从而确保在Hash 值碰撞时, 仍然可以准确查找到关键字对应的值。Hash 索引表中存放地址偏移,在访问记录时,根据关键字查找到对应的内存地址偏移即可高效的访问数据。Hash桶处理过程如图2 所示。
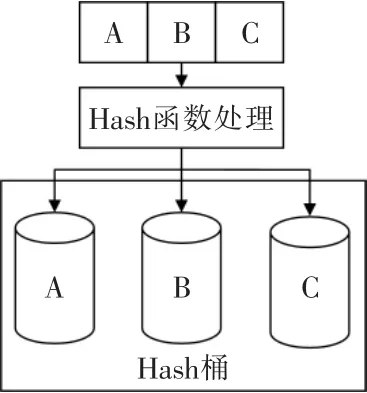
图2 Hash 桶Fig.2 Hash buckets
3.2 内存直接定位和管理技术实现
记录的内存地址访问速度是提高效率的关键。在DL/T 698.45 中, 记录键值是对象描述符OAD(object attribute descriptor),即数据的唯一标识。 而Hash 表中存储的记录的关键字就是OAD, 因此需要根据OAD 在Hash 表中查找到对应的内存地址偏移,以实现内存的直接定位,而对于结构化数据和非结构化数据分别使用不同的地址分配和和访问方法, 结构化数据使用静态链表索引的映射,非结构化数据采用增加记录信息头的方法。
3.2.1 结构化数据
对于结构化数据,由于每条记录的长度均都一致, 因此每条记录的起始地址的间隔都是固定的。静态链表的索引可以满足该特点,把对静态链表插入时分配的位置索引映射到实时库的表中,就可以满足内存地址的分配和访问功能。
在Hash 表中存放记录对应的静态链表的索引, 访问时从Hash 表中查找到该记录对应的索引值,从而直接根据索引乘以每条记录的长度计算出内存地址。 结构化数据内存结构如图3 所示。

图3 结构化数据内存结构Fig.3 Structured data memory structure
3.2.2 非结构化数据
(1)内存管理方法
对于非结构化数据,由于每条记录的长度不固定,如果采用静态链表映射的方法,每条记录都按照统一的长度,则在分配内存的时候会造成极大的空间浪费。 同时,对于插入、删除操作的内存分配可能导致记录覆盖等问题,要解决该问题会导致程序处理过于复杂,降低了程序的执行效率,因此设计了一种内存管理的方法。
在每条记录前存储本条记录的信息头,在预先分配的表空间范围内对数据进行管理。 其中,信息头包含了以下信息:当前数据块的长度、当前数据块是否空闲、前一个数据块的长度等。
在插入记录时,会遍历空闲的内存空间,直到找到满足记录长度的空闲内存空间段, 占用该空间,并返回该空间起始地址,同时分配剩余的空间为空闲的内存空间, 在信息头内记录数据长度,同时置为占用状态。
在删除记录时,首先检查相邻的内存空间是否也是空闲的,如果是则先合并空闲空间,再把对应信息头置为空闲状态。
在Hash 表中存放记录对应的内存偏移量,访问时从Hash 表中查找到该记录对应的地址偏移量, 直接用起始地址加上偏移量计算出内存地址。非结构化数据内存结构如图4 所示。

图4 非结构化数据内存结构Fig.4 Unstructured data memory structure
(2)内存碎片整理与备份
对于非结构化数据,由于长期频繁的插入删除操作可能会造成内存碎片的问题,降低了内存的使用率,因此需要内存碎片整理功能,释放与合并所有无法被利用的碎片空间,同时拷贝和移动相应的记录。
考虑到对内存数据的拷贝和移动有可能会出现错误或者异常,因此对移动数据在移动前备份在共享内存中,在发生异常时可以立即快速恢复。
另外,由于整理后的记录的内存地址偏移量可能会改变, 因此内存整理后的原有的Hash 表中的偏移量需要更新,而原实时库的访问在更新后不会受到任何影响。 偏移地址的更新过程如图5 所示。
4 试验测试
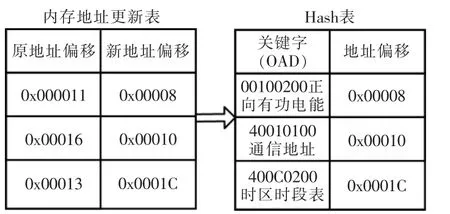
图5 偏移地址更新Fig.5 Offset address update
为了体现区分结构化数据和非结构化数据不同的设计在效率和占用空间方面各自的性能差异,选取电能量相关数据,对这2 种数据设计了7 种测试方法:总共10 张用采终端的实时库表,每次对每张表插入、读取、更新、删除记录5000 条,共执行100 次,记录平均耗时和使用的内存空间。 7 种方法具体如下:
测试1 结构化数据采用非结构化数据的使用方法;
测试2 结构化数据采用结构化数据的使用方法;
测试3 非结构化数据采用结构化数据的使用方法;
测试4 非结构化数据采用非结构化数据的使用方法;
测试5 混合数据全部采用结构化数据的使用方法;
测试6 混合数据全部采用非结构化数据的使用方法;
测试7 混合数据区分采用对应数据的使用方法。
这7 种方法的测试结果包括每张表的平均耗时、使用的总内存空间,具体数据见表1。
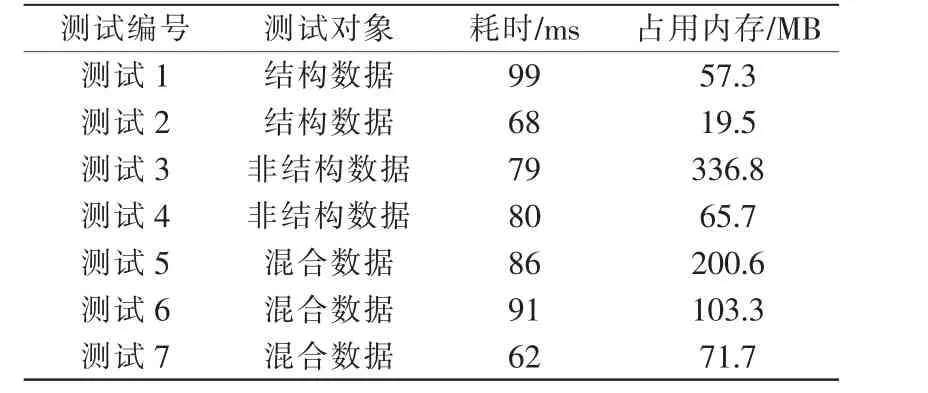
表1 实时库测试结果Tab.1 Test results of real-time database
实际测试结果表明,结构化数据采用结构化数据的存取方法在时间和空间上均表现更优,而非结构化数据采用非结构化数据的存取方法,在空间的利用率上提升非常明显,效率上和使用结构化的存取方法几乎相当,因此使用该方法更优。 而对于同时存在结构化数据和非结构化数据的混合数据,分别使用对应数据的存取方法无论在时间还是空间上都比不加区分的方法更优。
5 结语
详细阐述了用采终端非关系型实时库的实现方案, 关键在于使用防碰撞的Hash 桶索引表存放地址偏移的直接定位技术,和区分结构数据与非结构数据的内存管理技术, 满足了实时库的实时性、高效性,同时实现了对有限内存空间在大量数据处理中的最大化利用。 该实时数据库已在YDT100 系列用采终端实际应用。 对于未来的大数据分析、物联网等智能用电技术的发展趋势,用采终端的实时库后续需要考虑用电采集系统的分布式远程交互和大数据分析等功能升级[8-10]。
