基于模糊核聚类粒化的粒度支持向量机
2019-02-27黄华娟韦修喜周永权
黄华娟,韦修喜,周永权,2
(1.广西民族大学 信息科学与工程学院,广西 南宁 530006; 2.广西民族大学 广西高校复杂系统与智能计算重点实验室,广西 南宁 530006)
支 持 向量 机(support vector machine, SVM)自1995 年由Vapnik 提出以来就受到理论研究和工程应用2 方面的重视,是机器学习的一个研究方向和热点,已经成功应用到很多领域中[1-3]。SVM 的基本算法是一个含有不等式约束条件的二次规划(quadratic programming problem, QPP)问题,然而,如果直接求解QPP 问题,当数据集较大时,算法的效率将会下降,所需内存量也会增大[4-8]。因此,如何克服SVM 在处理大规模数据集时的效率低下问题,一直是学者们研究的热点。
为了更好地解决大规模样本的分类问题,基于粒度计算理论[9-10]和统计学习理论的思想,Tang 等于2004 年首次提出粒度支持向量机(granular support vector machine, GSVM)这个术语。GSVM 的总体思想是在原始空间将数据集进行划分,得到数据粒。然后提取出有用的数据粒,并对其进行SVM 训练[11-12]。与传统支持向量机相比,GSVM 学习机制具有以下优点:针对大样本数据,通过数据粒化和对有用粒子(支持向量粒)的提取,剔除了无用冗余的样本,减少了样本数量,提高了训练效率。然而,Tang 只是给出了GSVM 学习模型的一些设想,没有给出具体的学习算法。2009 年,张鑫[13]在 Tang 提出的GSVM 思想的基础上,构建了一个粒度支持向量机的模型,并对其学习机制进行了探讨。此后,许多学者对支持向量机和粒度计算相结合的具体模型进行了研究,比如模糊支持向量机[13]、粗糙集支持向量机[14]、决策树支持向量机[15]和商空间支持向量机[16]等。但这些模型的共同点都是在原始空间直接划分数据集,然后再映射到高维空间进行SVM 学习。然而,这种做法很有可能丢失了大量包含有用信息的数据粒,其学习算法的性能会受到影响。为此,本文采用模糊核聚类的方法将样本直接在核空间进行粒的划分和提取,然后在相同的核空间进行GSVM 训练,这样保证了数据分布的一致性,提高了算法的泛化能力。最后,在标准UCI 数据集和NDC大数据上的实验结果表明,本文算法是可行的且效果更好。
1 粒度支持向量机
张鑫[17]在Tang 提出的GSVM 思想的基础上,构建了一个粒度支持向量机的模型。
设给定数据集为X={(xi,yi),i=1,2,···,n} ,n为样本的个数;yi为xi所属类的标签。采用粒度划分的方法(聚类、粗糙集、关联规则等)划分X,若数据集有l个类,则将X分成l个粒,表示为:

若每 个粒包含li个点 ,Yi表示第i个粒的类别,则有:

其中:

则在GSVM 中,最优化问题变为:

将上述问题根据最优化理论转化为其对偶问题:


当数据集是线性不可分时,GSVM 不是在原始空间构造最优分类面,而是映射到高维特征空间,然后再进行构造,具体为:
将X从 Rn变换到 Φ:

以特征向量 Φ (X) 代替输入向量X,则可以得到最优分类函数为:

利用核函数来求解向量的内积,则最优分类函数变为:

其中,k(Xi,X) 为粒度核函数。当ai>0,根据以上分析,可知Xi是支持向量。显然地,式(5)的形式和SVM 的最优分类函数很一致,确保了最优解的唯一性。
2 基于模糊核聚类粒化的粒度支持向量机
2.1 问题的提出
在研究中发现,只有支持向量才对SVM 的训练起积极作用,它们是非常重要的,对于SVM 是不可或缺的,而其余的非支持向量对于分类超平面是不起作用的,甚至可能产生负面影响,比如增加了核矩阵的容量,降低了SVM 的效率。GSVM 也存在同样的问题,只有支持向量粒才对GSVM 的训练起决定性作用。可以通过理论证明来说明这个观点的正确性。
定理1粒度支持向量机的训练过程和训练结果与非支持向量粒无关。
证明定义Isv={i|al>0} 和Insv={i|al=0} 分别为支持向量粒和非支持向量粒对应样本序号的索引集,支持向量粒的个数记为l′。引入只优化支持向量粒对应样本的问题

要证明定理1,只需要证明式(2)和式(6)同解。用反正法,假设式(6)存在一个最优解a′使得g(a′)>g(a∗) 。由于a∗是式(2)的最优解,也即a∗是式(6)的可行解,同样,a′也是式(2)的可行解。由于a∗是式(2)的最优解,可得w(a∗)>w(a′)。又因为
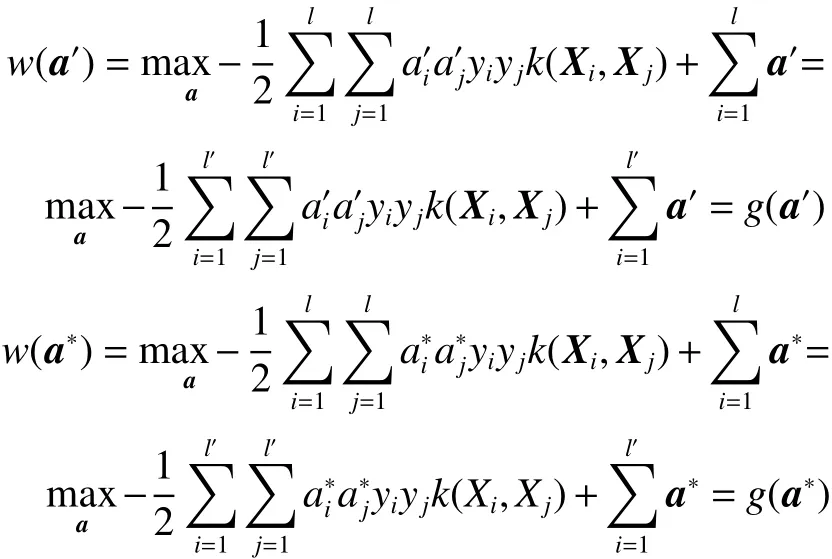
可 得w(a′)=g(a′)>g(a∗)=w(a∗) , 即w(a′)>w(a∗),这与a∗是式(2) 的最优解得出的w(a∗)>w(a′) 相矛盾。定理1 得证。注:a′是l′维向量,代入w的时候拓展为l维向量。
要想迅速地得到支持向量粒,节省粒化的时间,首先了解支持向量的特征,文献[13]对其特征做了归纳总结。
1)现实中,支持向量一般都是稀疏地聚集在训练数据集的边缘。
2)根据第一个特征,则每个类中心附近的数据不会是支持向量,即,离支持向量机超平面较近的数据比较可能是支持向量,这就为支持向量的选取提供了快速的获取方法。
2.2 问题分析
图1 中,红色部分的数据是GSVM 的支持向量粒,它们决定了分类超平面。并且从中可以看出,对于每一类,离类中心越远的点,就越有可能是支持向量粒。并且,从图1 中还可以看出,落在每一个环上的样本,它们离类中心的距离差不多相等。 离类中心越远的环就越有可能含有多的支持向量粒。基于这个思想,本文先把样本映射到核空间,按类标签的个数进行粗粒划分,确保相同标签的样本都在同一个粗粒中。 然后,对于每一个粗粒,采用模糊聚类的方法进行粒化,具有相同隶属度的样本归为一个粒,进行细粒划分。 每一个细粒就对应图1 中的一个环,从图中可以看出,离粗粒中心越远的环,越靠近分类超平面,其是支持向量粒的可能性越大。而离粗粒中心越远的环,其隶属度越小。因此,给定一个阈值,当细粒的隶属度小于给定的阈值,就说明其处于粗粒的边缘,是支持向量粒,进而提取出支持向量粒.

图1 支持向量分布图Fig.1 The distribution of support vectors
2.3 模糊核聚类
模糊核聚类(fuzzy kernel cluster, FKC)的主要思想是先将数据集映射到高维空间,然后直接在高维空间进行模糊聚类。而一般的聚类算法是直接在原始空间进行聚类划分。与其他的聚类算法相比,模糊核聚类引入了非线性映射,能够在更大程度上提取到有用的特征,聚类的效果会更好。
设原空间样本集为X=(x1,x2,···,xN),xj∈Rd,j=1,2,···,N。 核非线性映射为Ø:x→Ø(x),在本文中,采用Euclid 距离作为距离测量方法,由此得到模糊核C-均值聚类:

式中:C是事先确定的簇数;m∈(1,∞) 是模糊加权指数,对聚类的模糊程度有重要的调节作用;vi为第i类的类中心; ϕ(vi) 为该中心在相应核空间中的像。
按模糊C-均值优化方法,隶属度设计为

且有

为了最小化目标函数,需要计算k(xj,vi) 和k(vi,vi) ,由k(xi,xj)=< ϕ(xi),ϕ(xj)> 可得:

把式(9)~(11)代入式(7),可以求出模糊核C-均值聚类的目标函数值。
模糊核C-均值聚类的算法步骤如下:
1) 初始化参数: ε、m、T和C;
2) 对训练数据集进行预处理;
3) 设置vi(i=1,2,···,C) 的初始值;
4)计算隶属度uij(i=1,2,···,C;j=1,2,···,N);
5) 计算新的k(xj,vi) 和k(vi,vi), 更新隶属度uij为
2.4 FKC-GSVM 的算法步骤
目前,已有的粒度支持向量机算法模型大都是直接在原始空间对数据集进行粒化和提取,然后映射到核空间进行SVM 的训练。然而,不同空间的转换,很有可能丢失了数据集的有用信息,降低学习器的性能。为了避免因数据在不同空间分布不一致而导致泛化能力不高的问题,本文采用模糊核聚类的方法直接在核空间对数据集进行粒化、提取和SVM 的训练。基于以上思想,本文提出了基于模糊核聚类粒化的粒度支持向量机(fuzzy kernel cluster granular support vector machine, FKC-GSVM)。FKC-GSVM 算法包括3 部分:采用模糊核聚类进行粒度的划分;设定阈值,当每个粒子的隶属度大于规定的阈值时,认为这个粒子为非支持向量粒,丢弃,而剩余的粒子为支持向量粒;在核空间对支持向量粒进行SVM训练。具体的算法步骤如下:
1) 粗粒划分:以类标签个数l为粒子个数,对 训练样本进行粗粒的划分,得到l个粒子;
2) 细粒划分:采用模糊核聚类分别对l个粒子进行细粒划分,计算每个粒子的隶属度;
3) 支持向量粒的提取:给定一个阈值,当一个粒子的隶属度小于给定的阈值,提取这个粒子(支持向量粒),提取出来的支持向量粒组成了一个新的训练集;
4) 支持向量集的训练:在新的训练样本集上进行GSVM 训练;
5) 泛化能力的测试:利用测试集测试泛化能力。
2.5 FKC-GSVM 算法性能分析
下面,从2 个方面对FKC-GSVM 的算法性能进行分析:
1) FKC-GSVM 的收敛性分析
与SVM 相比,FKC-GSVM 采用核空间代替原始空间进行粒化,提取出支持向量粒后在相同的核空间进行GSVM 训练,其训练的核心思想依然是采用支持向量来构造分类超平面,这与标准支持向量机相同。既然标准支持向量机是收敛的,则FKC-GSVM 也是收敛的。但是由于FKCGSVM 剔除了大量对训练不起积极作用的非支持向量,直接采用支持向量来训练,所以它的收敛速度要快于标准支持向量机。
2) FKC-GSVM 的泛化能力分析
评价一个学习器性能好坏的重要指标是其是否具有较强的泛化能力。众所周知,由于SVM采用结构风险最小(SRM)归纳原则,因此,与其他学习机器相比,SVM 的泛化能力是很突出的。同样,FKC-GSVM 也执行了SRM 归纳原则,并且直接在核空间选取支持向量,确保了数据的一致性,具有更好的泛化性能。
3 实验结果及分析
3.1 UCI 数据集上的实验
为了验证FKC-GSVM 的学习性能,本文在Matlab7.11 的环境下对5 个常用的UCI 数据集进行实验,这5 个数据集的描述如表1 所示。在实验中,采用的核函数为高斯核函数,并且采用交叉验证方法选取惩罚参数C和核参数 σ , 聚类数c设为20。影响算法表现的主要因素是阈值k的设定,为此,对不同的阈值对算法的影响进行了分析。

数据集 Abalone Contraceptive Method Choice Pen-Based Recognition of Hand-written Digits NDC-10k NDC-1l#训练集 3 177 1 000 6 280 10 000 100 000#测试集 1 000 473 3 498 1 000 10 000维度 8 9 16 32 32
为了比较数据集在原空间粒化和在核空间粒化的不同效果,本文采用基于模糊聚类的粒度支持向量机(FCM-GSVM)、基于模糊核聚类的粒度支持向量机(FKC-GSVM)和粒度支持向量机(GSVM)等3 种算法对5 个典型的UCI 数据集进行了 测试,测试结果如表2 所示。为了更直观地看出FKC-GSVM 在不同阈值条件下的分类效果,给出了Contraceptive Method Choice 数据集在不同阈值条件下采用FKC-GSVM 分类的效果图,如图2~图5 所示。

表2 FCM-GSVM 与FKC-GSVM 测试结果比较Table 2 Comparison of test results between FCM-GSVM and FKC-GSVM%
FCM-GSVM 和GSVM 是在原空间进行粒度划分和支持向量粒的提取,然后把支持向量粒映射到高维空间进行分类,而FKC-GSVM 是直接在核空间进行粒度划分和支持向量粒的提取,然后在相同的核空间进行分类。从表2 的测试结果可以看出,由于FCM-GSVM 和GSVM 可能导致数据在原空间和核空间分布不一致,在相同的阈值条件下,其分类效果要比FKC-GSVM 的分类效果差,这说明FKC-GSVM 的泛化能力比FCM-GSVM 的泛化能力强。
为了分析在不同阈值条件下FKC-GSVM 的泛化性能,本文给出了0.9、0.85、0.8、0.75 四个不同阈值条件下的实验。从表2 可以看出,阈值越小,FKC-GSVM 的分类效果越差,这是因为阈值越小,选取的支持向量粒就越少,这一过程可能丢失了一些支持向量,影响了分类效果。但是阈值越小,大大压缩了训练样本集,算法训练的速度得到了很大的提高。因此,对于大规模样本来说,只要在能接受的分类效果的范围内,选取合适的阈值,采用FKC-GSVM 就能快速地得到需要的分类效果。图2~5 是Contraceptive Method Choice 数据集在不同阈值条件下采用FKC-GSVM 分类的效果图,从这几个图中可以很直观地看出,FKC-GSVM 的分类效果还是比较令人满意的。

图2 FKC-GSVM 在阈值为0.9 条件下的分类效果Fig.2 The classification results of FKC-GSVM under the threshold 0.9

图3 FKC-GSVM 在阈值为0.85 条件下的分类效果Fig.3 The classification results of FKC-GSVM under the threshold 0.85

图4 FKC-GSVM 在阈值为0.8 条件下的分类效果Fig.4 The classification results of FKC-GSVM under the threshold 0.8

图5 FKC-GSVM 在阈值为0.75 条件下的分类效果Fig.5 The classification results of FKC-GSVM under the threshold 0.75
3.2 NDC 大数据集上的实验
为了测试FKC-GSVM 处理大数据集的性能,在实验中,采用的数据集是NDC 大数据集[20],是由David Musicant’s NDC 数据产生器产生的,NDC 数据集的描述如表3 所示。在实验中,FKCGSVM 的测试结果将与现在比较流行的孪生支持向量机(twin support vector machines, TWSVM)的测试结果[20]从测试精度和运行时间2 方面进行对比。其中,FKC-GSVM 的运行环境、参数设置方法和实验3.1 一样,阈值k= 0.9;TWSVM 的惩罚参数和核参数的选取都是从 {2-8,2-7,···,27} 这个范围内采用网格搜索算法进行选择。表4 显示的是FKC-GSVM 和TWSVM 两种算法的运行结果。

表3 实验采用的NDC 数据集Table 3 NDC datasets used in experiments

表4 2 种算法对NDC 数据集的测试结果Table 4 Comparison of two algorithms on NDC datasets
从表3 中可以看出,本实验测试的对象为5 种数据集,NDC-3L 的训练样本数为300 000 个,而NDC-1m 的样本增加到了1 000 000 个,同样,测试样本也从30 000 增加到了100 000,特征数都是32 维。这3 个数据集主要是为了测试算法在处理维度一样而数据量不断增加时候的学习性能。为了进一步测试学习算法处理高维样本的性能,NDC1 和NDC2 这2 个数据集的维数分别是100 和1 000,设置他们的训练样本量和测试样本量都一样,都是5 000。
实验结果如表4 所示,从中可以看出,当数据集为NDC-1m 时,由于训练时间过高,采用TWSVM 算法无法将实验进行下去。然而,FKC-GSVM 在处理NDC-1m 数据集时能够在合理的运行时间内得到较满意的精度解,这表明了FKC-GSVM 在处理大数据时是具有优势的。同样,在处理NDC1 和NDC2 这2 个高维数据集时,从表4可以明显看出,FKC-GSVM 处理高维数据的效果也是不错的。实验结果充分说明了FKC-GSVM 的学习能力比TWSVM 的强,更适合于处理大数据集。
4 结束语
GSVM 是将训练样本在原空间粒化后再映射到核空间,这将导致数据与原空间的分布不一致,从而降低了GSVM 的泛化能力。为了解决这个问题,本文提出了一种基于模糊核聚类粒化的粒度支持向量机方法(FKC-GSVM)。FKC-GSVM 通过利用模糊核聚类直接在核空间对数据进行粒的划分和支持向量粒的选取,然后在相同的核空间中进行支持向量粒的GSVM 训练,在标准数据集的实验说明了FKC-GSVM 算法的有效性。但是阈值参数的选取仍具有一定的随意性,影响了FKC-GSVM 的性能。如何自适应地调整合适的阈值,将是下一步要研究的工作内容。
