单帧图像下的环境光遮蔽估计
2019-02-20郭雨潇陈雷霆
郭雨潇 陈雷霆, 董 悦
1(电子科技大学计算机科学与工程学院 成都 611731)2(电子科技大学广东电子工程信息研究院 广东东莞 523808)3 (微软亚洲研究院 北京 100080)
在真实三维场景中,每个点的颜色不仅取决于光源的直接照射,也包括周围环境全局光照的贡献.快速评估周围环境全局光照产生的亮度,对实时绘制、求解直射分量都有很重要的作用.环境光遮蔽在计算机图形学和视觉中用于近似场景中每个点对环境的总体可见性.常常用于快速计算在低频环境光照下的全局光照.
在图形学中,一系列算法从已知的3维场景几何形状中直接计算环境光遮蔽.这些算法虽然可以做到实时,但是都需要知道场景几何信息,因而无法直接用于计算几何未知的真实场景中环境光遮蔽.针对真实场景,计算机视觉的算法主要通过观察和统计不同方向光源照射下,物体上同一点的光照强度变化从而对场景中每个点的环境光遮蔽属性进行估计.这类方法具有以下2点主要缺陷:1)输入图像数量过多.为了有效地统计物体随光照变换的趋势,已有方法往往需要对单个视点在不同光照下采集多达数十帧的图像.2)场景光照限制.该类方法往往要求场景中存在一个或者数个已知位置和满足特定分布的方向光源.同时,对场景的环境光强度亦做出了限制.显然,以上2点要求在难以在大部分的应用场景中得到满足,限制了该类方法的应用场景以及辅助其他计算机视觉问题求解的可行性.
针对以上不足,本文提出了一种基于单幅输入图像的环境光遮蔽估计算法.给定在自然光照下的单幅输入图像,我们设计了一个多层的卷积神经网络,直接估计图像中每个像素对应点的环境光遮蔽值.为了有效地训练这一卷积神经网络,我们算法利用大量的3维物体模型,通过真实感渲染生成大量的仿真图像和对应的环境光遮蔽贴图作为训练数据.我们提出了3种不同的网络结构和相应的训练方法.通过分析和比较,得到了针对这一问题非常有效的一种卷积神经网络结构.仿真和对比实验证明了本文提出的方法在任意光照单张图像的输入条件下,能够取得比现有多帧估计算法在更多输入条件下更好的结果.同时,在真实图像中的测试表明该方法能够对真实世界的物体进行较为准确环境光遮蔽的估计.和已有的算法相比,我们的算法极大地减少了输入图像的数目并放宽了图像的光照条件,加快了求解速度,扩展了算法的普适性.
1 相关工作
在图形学绘制中,给定场景几何信息,一些算法在场景在当前视点下的深度图像上直接快速计算环境光遮蔽[1-4].这些方法通过对相邻像素间进行采样,通过像素间的深度变化对沿各个方向的可视角进行估计,进而计算环境光遮蔽.
针对几何未知的真实场景,一些视觉算法利用场景在不同光照下的图像计算环境光遮蔽[5-6].文献[7]通过假设物体由单一材质构成,利用同一方向光源在不同视点下的多帧图像中求解其环境光遮蔽.文献[8-9]假设环境光照均匀且光照强度固定,通过单张图像针对人脸的环境光遮蔽进行计算.文献[10]借助多帧图像重建的点云信息对环境光遮蔽进行估计,并且将其带入到了光照与物体表面反射率的估计中.在该类方法中,环境光遮蔽常作为其算法流程的中间步骤.通过在特定的输入条件下对环境光遮蔽求解,从而进一步优化光照或者几何结构估计精度.
另外,一些工作旨在对光照做有限假设和未知物体几何结构、表面材质的条件下,通过引入额外先验求解环境光遮蔽.文献[11]提出了一种多帧图像的估计方法.通过假设物体的局部可见面呈圆锥形和独立统计各像素光照强度的变化,建立了物体反射率与环境光遮蔽关系的数学模型,进而使用优化方法求解问题.该方法最大的问题在于对要求输入大量不同光照方向下相同视角的图像,在实际的应用中难以满足.同时,该方法还存在全局模糊等问题.文献[12]允许在单张图像中存在多个光源,结合压缩感知技术同时求解满足该图像成立最稀疏的光源分布和局部可见性关系,有效地减少了对输入图像数量的依赖.然而,其需要预先知道所有光源在3维空间中的位置,使其难以推广和扩展.文献[13]在文献[11]的基础上,通过约束各像素在多帧图像中对应的光照入射角也应该满足均匀分布,使其在10帧左右图像的输入条件下亦能取得较为合理的效果.基于图像估计的方法往往需要从多张图像中推测物体的光照和阴影关系,同时还需要对光照进行特殊布置或满足一些基本条件(例如无环境光以及光源分布均匀等).与该类方法相同,本文通过图像对物体的环境光遮蔽进行估计.但是,本文使用单张图像作为输入,对物体的环境光遮蔽属性进行估计.同时,本文算法能够在自然光照的条件下适用.
环境光遮蔽计算可以被看作本征图像分解的扩展和延伸.本征图像假设场景材质为漫反射,从而将输入图像分解为场景的反射率图和光照图.环境光遮蔽计算是对本征图像恢复的光照图像的进一步分解和求解.本征图像最早由文献[14]提出,并衍生了一些具有代表性的工作[14-18].对于该类问题,由于未知量多于已知等式,重点在引入合理的假设和先验使得问题可解.近年来,由深度学习在相关视觉任务中的进展启发[19-22],文献[23-24]将卷积神经网络作为特征提取器,引入到了本征图像分解中.随后,文献[25]提出了以光照贴图和反射率贴图为卷积神经网络输出的端到端网络结构.在此基础上,文献[26]通过在大量仿真数据中训练网络,实现了非漫反射场景下本征图像的分解.目前,尚未见算法将深度学习引入环境光遮蔽的计算中.
2 基于单帧图像的环境光遮蔽算法
2.1 问题定义
对于环境光遮蔽,通常定义如下:

其中,x为物体表面上的点;AO为该点对应的环境光遮蔽值,其取值范围AO∈[0,1];S+是以该点法向量n为中心的上半球面积分区域;V(·)为一个布尔函数,表示该点与当前环境光源方向w间是否被其他几何结构遮挡;·为点乘操作.由定义可知,环境光遮蔽的值仅由物体的几何形状决定,与光照强度和物体表面反射率无关.
给定输入的图像I,假设对应场景的表面为漫反射表面,其像素值I(x)为
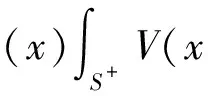


本文并不假设环境光位于无穷远,所以对于每一像素,其环境光强度可能不同.
我们的目标是从输入图像I(x)中恢复每个像素的环境遮蔽值AO(x).与本征图像的其他问题相似,对于单个等式存在多个未知量,是一个典型的病态问题.我们将问题形式化为一个输入图像I到环境遮蔽图AO的映射.采用卷积神经网络对这一映射进行建模,并通过基于大量数据的训练对模型进行回归.
2.2 编码器-解码器设计
本文采用了多层编码器-解码器卷积神经网络结构,如图1所示:
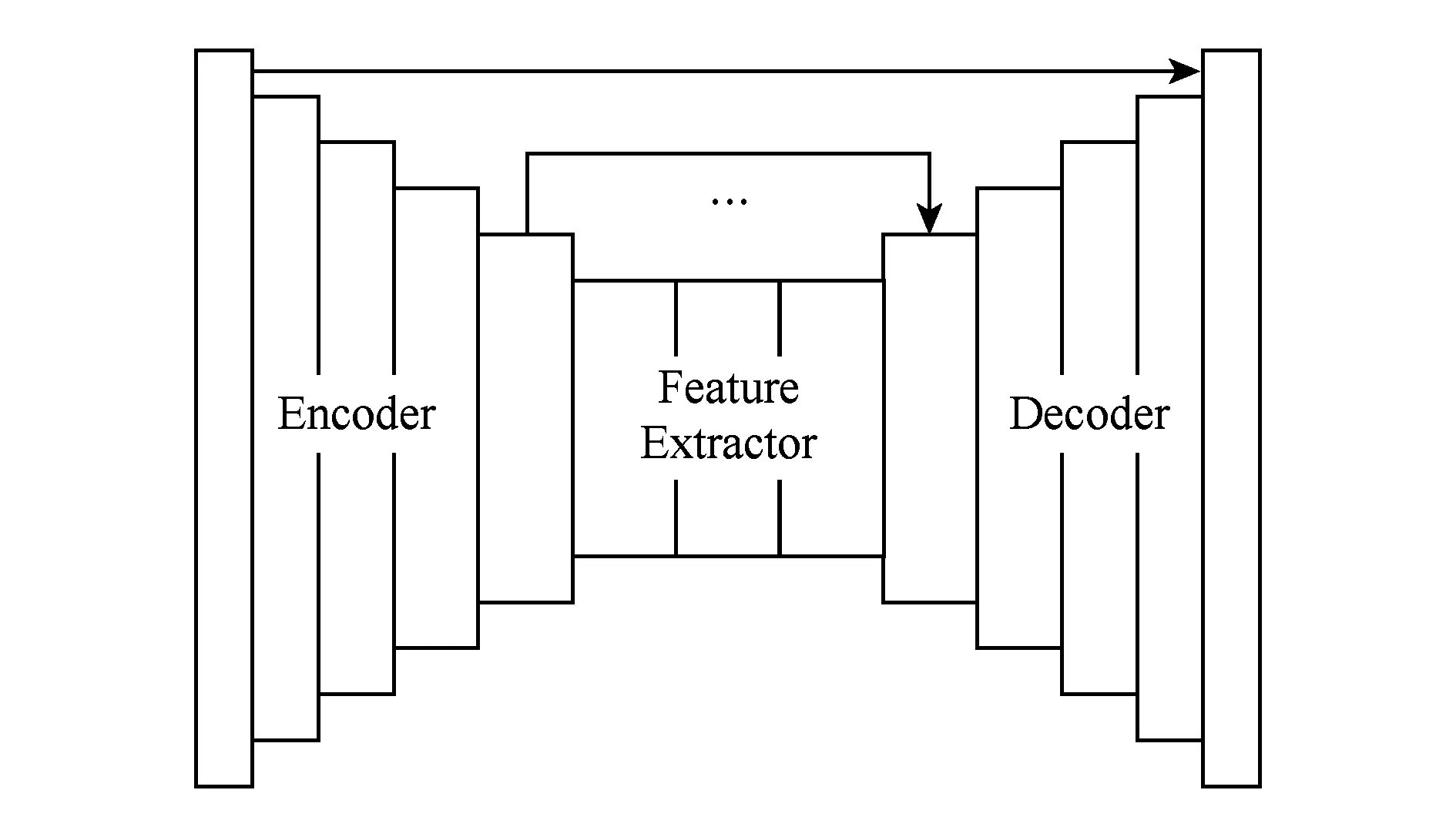
Fig. 1 Encoder-decoder network structure图1 编码器-解码器结构示意图
这一结构被广泛应用于计算机视觉中的不同图像解构问题.具体地,我们使用的编码器由5层独立编码单元构成,各编码单元包含卷积层、向下采样层(down sampling)、批单位化层(batch normalization)以及线性激活单元(ReLU)等操作.经过编码单元后,特征图的大小变为输入的一半,但是特征图数量变为2倍.即对于通过5层编码器的输入特征图边长依次变为256,128,64,32,16,其对应的输入输出特征图数目为38,816,1632,3264,64128.随后,将经过编码器的特征图进行特征提取,特征提取阶段包含3个连续的卷积层、批单位化层以及线性激活单元操作.在此阶段,保持特征图的数量以及大小不变.解码器阶段亦包含5层结构,其解码单元包含卷积层、批单位化层、线性激活单元以及向上采样层等操作.根据文献[24],采用近道连接(shortcut connection)能够很好地处理利用卷积神经网络求解图像回归问题中的输出图像模糊问题.在本文中,
亦使用了近道连接对网络进行改进,将编码器的特征图直接并联到同尺度的解码单元中.故对于各解码器,其输入特征图边长依次为16,32,64,128,256,对应的输入输出特征图数目为128128,25664,12832,6416,328.随后,将根据不同的网络结构设计方案对编码器-解码器进行组合和扩展.
2.3 损失函数
由于图像分解中各分量仅保持了相对关系,故估计值和真实值间往往具有一个全局放缩量,该任意性的存在使得均方估计损失函数(MSE)并不适用于本征图像相关的工作中.为了同时确保训练精确性和收敛性,本文采用了放缩不变性L2损失函数[25]作为损失函数:

其中,Y*为预测值;Y为真实值;y=Y*-Y为两者间的估计误差;i,j分别对应图像长宽坐标;n为参与误差估计的总像素个数(仅包含图像中属于目标物体的部分);λ是调节系数.当λ=0时,该联合损失函数变为均方损失函数;当λ=1时,该函数为一个纯粹的放缩不变损失函数.考虑到训练数据集中包含各种光照条件下的样本,较大的λ能够取得更好的效果.在本文中,所有的损失函数均采用了λ=0.95的联合损失函数.
2.4 卷积网络结构设计
基于编码器-解码器结构,本文设计了3种不同的网络结构来尝试求解这一问题.
一个直接的解决方案是将该问题建模为本征图像分解的扩展问题,这样将映射分解为2步:1)由单张图像估计物体的光照贴图;2)由光照贴图估计物体的环境光遮蔽结果.基于这一分解,设计一种2级的编码-解码器结构,结构如图2所示:

Fig. 2 Cascade training network structure图2 多级训练网络结构示意图
每一级网络针对单一问题进行求解,并且输出结果作为下一级网络的输入.具体地,第1级网络以图像为输入,以光照贴图为预测目标进行训练;第2级以第1级预测的光照贴图为输入,以环境光遮蔽结果为预测目标进行训练.在优化时,采用了交替优化的策略.即首先以光照贴图为标签,训练第1级网络.随后,以环境光遮蔽为标签,在固定第1级网络参数的条件下,对第2级网络进行训练.最后,以环境光遮蔽为标签,同时优化第1第2级网络.本文亦尝试了同时优化的策略,发现训练过程无法收敛.
在本征图像中,文献[26]通过共享参数,对反射率、高光以及光照3种不同属性使用联合优化的方法进行求解.在第2个设计中,我们尝试了使用类似方法对网络进行改进,如图3所示:
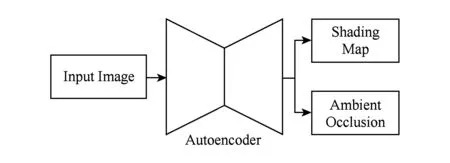
Fig. 3 Union training network structure图3 联合训练网络结构示意图
在解码器后,额外接入了2个独立输出通道分别为3和1的卷积操作,预测光照贴图和环境光遮蔽.在训练时,采用同时优化的方式进行训练.2优化目标均采用了2.3节中提到了混合损失函数,整体优化目标Ltotal:
Ltotal=αLshading+(1-α)LAO,
(5)
其中,Lshading为光照贴图部分的损失函数;LAO为环境光遮蔽部分的损失函数;α负责调节因光照和环境光遮蔽输出通道不同带来的数值不平衡问题.针对该问题,取α=0.25.
2.4.3 环境光遮蔽端到端训练结构
2.4.1节和2.4.2节的2种设计分别代表了串行和并行的方法,对将该问题视作一个本征图像的扩展问题进行求解.在第3种设计中,本文直接将该问题作为一个独立问题进行端到端的求解.为此,我们将编码器-解码器的输出结果直接与一个输出通道为1的卷积层相连,输出预测的环境光遮蔽估计值.结构如图4所示:

Fig. 4 End-to-end training network structure图4 端到端训练网络结构示意图
2.5 仿真数据生成
卷积神经网络需要大量的标注数据作为训练样本,从训练数据中抽取相关任务所需的特征.文献[27]中所提出数据集包含了大约50 000个物体的3维模型,近年来被计算机图形学用于训练数据的生成.考虑到环境光遮蔽与物体的几何特点相关,而ShapeNet中的大部分物体的几何构成简单,难以作为训练样本.本文从中选取了6类物体共计2 500余模型作为训练目标,包含飞机、摩托车、洗手台、耳机、照相机以及吉他.其中,飞机和吉他的几何构成与环境光遮蔽分布的相似性较高.其余4类具有更加复杂的几何结构和环境光遮蔽强弱分布.对于环境光照,为了保证光照的随机性和复杂性,本文选取了计算机图形学研究中一些常见的环境光贴图.其包含了室内室外以及晴天、阴天等各种条件下的环境光照情况,共计92张.
本文使用MITSUBA作为物理渲染引擎,使用路径追踪作为光线追踪渲染算法,单像素采样次数为512次.渲染时,对于每个模型,将其置于世界坐标中心.对于每一张环境光贴图,随机挑选位于上半球面中半径为2(所有模型已经归一化)的一点作为摄像机位置.同时,使用采样次数512次的环境光遮蔽采样结果作为真实值进行训练和评估.仿真数据共计生成约270 000左右的数据,对于每个模型,我们按8020的比例划分训练测试数据集.
3 实验结果与讨论
本文在1台PC上用Torch实现了上述的算法.训练使用AdaDelta算法作为梯度更新方法,对3个模型,设置初始学习率为0.01,初始L2正则惩罚项为0.000 1.同时,设定单次迭代的批样本数量为32,总迭代为40次全数据周期(epoch).对于输入图像,将其放缩到256×256.训练网络消耗的内存大约为4 GB,训练使用的显卡为Nvidia TITAN X.
3.1 模型评估
首先对提出的3个模型进行了评估,从数据集中选择摩托车作为训练数据集,因为其具有更复杂的几何结构以及精细的局部特征,能够较好地反映估计结果.
3种网络的数值对比结果如表1所示,发现端到端的模型在给定的数据集上得到了最好的训练和测试结果.而另外2个基于本征图像分解扩展的模型对环境光遮蔽回归结果与端到端直接训练相比并无提高,甚至还略微有下降.一个可能的原因来自于本征分解和环境遮蔽估计的问题属性决定的.本征图像分解具有较高的难度,因为在反射属性和光照中都同时包含高频和低频属性,例如深色贴图和阴影的区分.而在环境遮蔽中只包含低频量.所以,与端到端的训练相比,以上2种网络结构如果在本征分解精度不高的时候,很难再从光照图中得到准确的环境遮蔽结果.同时网络层数的增多导致参数增多,导致网络的训练变得更加困难和不稳定.使得在同样的训练数据集后,其结果不如端到端的直接训练准确有效.一些具有代表性的视觉对比结果如表2所示.

Table 1 Numerical Comparison Among Three Networks表1 3种网络结构数值精度比较

Table 2 Visual Comparison Among Three Networks表2 3种网络结构视觉效果比较
3.2 仿真数据评估结果
随后,评估算法在仿真数据上的性能.由于之前没有其他基于单张图像的环境光遮蔽算法,我们选择了文献[11]的方法进行对比.为了满足文献[11]的输入要求,对于每个测试项,本文在固定方向光源光照强度的情况下,在物体中心向着摄像机为中心的半径为2半球面上,以Halton序列随机生成约60组光源位置,并采集其在该光照下的渲染结果.由于场景中不存在环境光源,本文选择其非迭代结果作为比较项(根据其报告,无环境光时估计结果更加准确).
由于文献[11]对于每个测试样本需要生成大量数据,受到计算资源限制,本文在训练数据集中具有代表性的水龙头、摩托车和飞机3个类别中随机选取了约2 000个样本进行了对比实验.
在数值误差评估时,选择了RMSE (root mean square error),LMSE (local mean square error),DSSIM (district structural similarity)3种指标对结果的数值精度进行评估.其中,RMSE是均方误差开根结果,其衡量了估计值与真实值间的像素误差.LMSE由文献[28]提出,其通过衡量局部均方误差,能够更好的表达视觉准确度与数值误差的相关性.DSSIM是常见的衡量图像间相似程度的指标.其对比结果如表3所示.显然地,本文算法在仿真数据上的数值误差远好于测试基准线和文献[11]的方法.值得注意的是,在本文所用的数据集中,文献[11]的结果在数值精度上与基准值相比仍有差距,显示出了该类方法对复杂物体的局限性.

Table 3 Numerical Error among Different Methods表3 不同方法数值误差对比
另外,本文从视觉上将算法结果与真实值和文献[11]方法结果进行了对比,其结果如表4所示.表4中4列分别包含了本文算法所用的输入图像、真实值、本文所用算法结果和文献[11]所有算法结果(其输入图像为前文所述方法生成).另外,为了更好地对比局部结果,本文每个物体环境光遮蔽较为复杂和明显的区域进行了放大比较(表4中实虚方框),同时展示了误差热度图(图像下方区域).
总的来说,本文与文献[11]方法均能对物体大致的环境光遮蔽分布和趋势进行估计.在飞机的环境光遮蔽估计中,2种方法均能对引擎、机身和机翼接缝处的环境光遮蔽进行准确的估计.在水龙头的估计中,文献[11]如其论文以及文献[12]报告的一样,在整体的估计上存在模糊和估计值失真等问题.然而,本文的方法能够对其各处的环境光遮蔽进行较为准确的估计.值得注意的是,在该场景中,本文算法的输入图像具有明显明暗变化,在最终的估计结果中,算法能够准确地处理光照的变化.摩托车代表了较难的场景,其存在较多的几何细节和复杂的局部结构.在该类场景中,我们的方法和文献[11]方法类似,能够对大致的环境光遮蔽趋势进行估计,但在具体局部细节的估计上均存在着模糊的问题.但是和文献[10]相比,本文方法只需要单张图像作为输入.

Table 4 Visual Comparison Among Different Methods表4 不同方法视觉效果对比
3.3 真实图像
最后,为评估算法在真实场景的图像上的性能,我们从网上下载了一些常见的物体图像,通过本文算法对其环境光遮蔽值进行估计,结果如图5所示.其中,吉他、摩托车、飞机以及耳机等有类似物体的图像在训练数据集中.而玩偶和椅子2个类别均不包含在训练数据集里.
从图5中结果可以看出,即使作用于真实图像中,本文所训练的网络能够较为合理地估计物体的环境光遮蔽.

Fig. 5 Real cases results图5 真实场景结果图
在真实物体上的实验说明了我们的估计算法有以下2个优点:1)能够区分阴影和环境光遮蔽的关系.在飞机和玩偶的示例中,均存在一个较为明显的方向光源.处在阴影中的区域与非阴影区域相比,亮度较低,具有与环境光遮蔽较大区域相似的特征.在估计结果中,算法准确地估计了阴影处的环境光遮蔽结果;2)能够较为准确地区分暗色系材质与环境光遮蔽的关系.在吉他中心偏右处,玩偶眼部材质近乎黑色,与环境光较大时的表现相似.本文的算法能够较为准确地识别该区域正确的环境光遮蔽结果(玩偶的眼部和吉他下部仍然存在一个较浅的环境光遮蔽估计值).值得注意的是,由于漫反射场景在真实世界中几乎不存在,以上真实物体并不完全符合算法的输入假设.但是,本文算法在一定程度内仍然能够对环境光遮蔽结果进行合理估计.其中,耳机存在着一定的高光和反光部分,本文算法在对该物体进行预测时效果与其他物体较比相对较差.不过仍然能够反映该物体环境光遮蔽的总体趋势.
3.4 失败案例
本文方法仍存在一定的局限性,现就2个典型的失败案例进行讨论,如图6所示:

Fig. 6 Failure cases图6 失败案例
在飞机的例子中,网络将机翼和机头黑色贴图部分误估计为环境光遮蔽较大的区域.在本征图像中,对于阴影区域和贴图较暗区域的区分一直是一个较为困难的问题,在环境光遮蔽的估计中也存在相似的问题.在相机的例子中,镜头以及周边存在环境光遮蔽估计失真的情况.这是由于镜头周围的镜面反射明显,使得本文非漫反射的前提条件被破坏,使得估计出现较大误差.
4 结 语
本文提出了一种基于卷积神经网络的从原始图像到环境光遮蔽估计算法.算法仅要求单帧图像作为输入,同时对光照没有特别假设.本文提出并评估了3种不同的卷积神经网络设计,其中端对端的网络取得了最好的效果.本文对算法在仿真图像和真实图像上的性能进行了评估,实验结果表明,本文方法具有较好的鲁棒性.与已有方法相比,本文提出的算法结果精度更高,极大地减轻了传统基于图像的环境光遮蔽估计对输入图像数量和光照布置均有较高的限制,使得在单张图像估计环境光遮蔽成为可能.
本文的算法假设场景为漫反射,在未来的工作中,我们将对非漫反射场景的环境遮蔽问题进行研究.另外,下一步通过将本文的方法与其他以环境光遮蔽作为中间步骤的方法进行结合,使得该类其能够在更加通用的条件下进行求解并应用于不同的视觉应用.
致谢衷心地感谢微软亚洲研究院的童欣老师在论文完成过程中提供的指导和帮助.在研究过程中,与他的多次讨论使我受益匪浅!
