基于差分隐私的匿名组LBS轨迹隐私保护模型
2019-02-15高喜龙王睿宁林思劼
袁 健,王 迪,高喜龙,王睿宁,林思劼
1(上海理工大学 光电信息与计算机工程学院,上海 200093) 2(复旦大学 信息科学与工程学院 ,上海 200093)
1 引 言
随着移动应用技术的发展,基于位置的服务(location based service ,LBS)给人们带来了诸多便利,日益受到人们的欢迎[1].用户在向服务商请求服务的过程中,包含了位置信息、身份信息、个人兴趣等敏感数据.其中,位置信息以及由位置信息推理出的信息属于位置隐私[2].与LBS请求内容相关的信息属于查询隐私[3],它们都属于位置服务隐私保护的范畴[4].研究表明,用户的连续查询会形成基于位置服务的轨迹信息,攻击者经过推理分析即可获取诸如用户住址、宗教信仰、是否患病等敏感信息[5],甚至预测用户的下一个位置[6],这将会给LBS用户造成不可估计的损失.因此,基于连续查询的轨迹隐私保护技术成为目前LBS领域的热点之一.
为了解决位置服务中的轨迹隐私保护问题,Gedik等人[7]提出了位置K-匿名模型.该模型利用K-匿名算法,保证当前用户与其他(k-1)个用户无法区分,实现基于位置服务的隐私保护.但由于K-匿名自身的劣势,其无法对攻击者的背景知识做出有效估计,很难设计出有效而全面的LBS轨迹隐私保护模型[8].差分隐私[9]具有背景无关性,能够弥补K-匿名在背景攻击方面的不足,逐渐被应用于LBS轨迹隐私保护领域.但由于差分隐私过度依赖隐私预算,隐私保护的有效时长无法得到保证[10].
针对现有算法存在的缺陷,本文提出了基于差分隐私的匿名组LBS轨迹隐私保护模型K-Differential-Privacy,该模型由两个子算法构成:与Chord相结合以快速定位的用户轨迹划分定位算法(User Trajectory Partioned Position Algorithm Based On Chord,简称UTPP算法)和基于差分隐私的噪声匿名组算法(Nosied Anonymous Group Algorithm Based On Differential Privacy ,简称NAGDP算法).经实验验证,噪声匿名组的设置提高了LBS轨迹隐私保护强度,同时,UTPP算法的采用保证了匿名组的生成速度,优化了查询请求的等待时间.
2 相关工作
根据查询请求在到达LBS服务器之前变换方式的差异,目前,轨迹隐私保护方法可分为以下3种:基于K匿名泛化的轨迹隐私保护方法、基于噪声数据的轨迹隐私保护方法、基于动态假名的轨迹隐私保护方法[11].
基于K匿名泛化的轨迹隐私保护方法的主要思想是:将连续的n次查询视为n个独立的 LBS 服务请求,即分别为这n次查询构建匿名空间.时空伪装[12]是实现该方法的主要技术,它指用一个空间区域CR(Clocking Region)来代替用户的真实位置;或通过延迟响应时间,使时空区域内的用户数量足够多,使得攻击者无法推断出真实用户.针对单独的查询请求,该方法能够有效地保护基于位置服务的用户隐私.而轨迹信息与连续查询相关,在进行连续查询请求时,时空伪装方法易受到最大速度攻击以及连续查询攻击.前者指利用移动用户的最大速度和多个连续时刻的伪装区域,推断出查询用户位置的攻击方式;后者指利用伪装区域匿名集的交集推断出查询用户位置的攻击方式.为了抵制最大速度攻击,Cheng等人[13]提出Delaying和Patching方案,其中,Delaying通过延迟请求来实现,Patching通过扩大伪装区域来实现.这两种方案均降低了LBS的服务质量.为了抵制连续查询攻击,Xu 等人[14]首先提出一个支持连续空间查询的K-匿名隐藏区生成算法KAA.Michaela等人[15]提出MaskIt方法,用隐式马尔科夫模型对攻击者获取的敏感信息进行建模.Agir 等人[16]利用有向图对用户在连续位置上变换的概率进行建模,以此来估计用户在下一个位置上的隐私级别.虽然以上改进方法均能够支持连续查询,但由于基于K匿名泛化的轨迹隐私保护方法以K-匿名为基础,其无法对攻击者的背景知识做出有效估计,难以设计出有效、全面的轨迹隐私保护模型[4,17].
基于噪声数据的轨迹隐私保护方法的主要思想是:将若干假位置(dummy)包含在发送的LBS请求中来保护真实位置,使攻击者无法分辨出用户位置的真假.其中,假位置是指用户的周边位置.该方法的隐私保护程度和服务质量与真假位置的距离有关.因此噪声数据的添加机制是该方法的核心.Kido等人[18]将真实位置随机移动后作为假位置,但该加噪机制产生的假位置与用户真实的移动特征不符,攻击者很容易区分出真假位置.针对这一问题,Suzuki等人[19]在生成虚假位置点时加入了移动速度、路网等约束条件.Kato等人[20]认为移动用户不会始终连续性移动,因此其在生成噪声数据点时会让移动对象根据周边的环境随机地产生一些停顿,以防止攻击者区分出真假位置.但是,真实场景中会遇到各种随机事件,影响用户的行为,因此,如何设计良好的加噪机制成为该方法的一个挑战.此外,上述方法对攻击者的背景知识的假设较为保守,当攻击者获得较多背景知识时,轨迹隐私保护无法得到保障.
基于动态假名的轨迹隐私保护方法的主要思想是:用户在发送LBS请求时使用假名(pseudonym)来代替真实身份.但移动用户在路网中是公开可见的,长时间使用同一假名无法有效保护用户的隐私.因此,Freudiger等人[21]提出了基于 mix-zone 的动态假名技术,该技术的实质是让第三方改变用户在指定区域内的假名.其中,如何构建mix-zone区域是该技术的关键.Palanisamy等人[22]基于用户在路网上的运动模式,提出MobiMix,针对现实中可能被攻击者利用的背景知识,利用不规则多边形及其组合建立单个mix-zone区域.但现实中需要部署多个mix-zone区域才能有效保护轨迹隐私.基于此,Xu等人[23]提出一种多个mix-zone区域的部署方案.但基于动态假名的方法需要第三方机构集中地对用户的假名进行修改,而第三方的可靠性则决定了该方法的有效性.
由上可知,基于K匿名泛化的轨迹隐私保护方法具有K-匿名本身带来的无法抵抗背景知识攻击的缺陷;基于噪声数据的轨迹隐私保护方法需要寻找一个有效的加噪机制,同时需要优化背景知识假设理论;基于动态假名的轨迹隐私保护方法过于依赖第三方机构,无法保障隐私安全.因此,基于噪声数据的位置扰乱技术在LBS领域日益受到重视[24].与基于噪声数据的轨迹隐私保护方法中以假位置代替真位置的思想不同,它主要是利用位置加噪算法对每个时刻的真实位置添加随机噪声,生成扰乱位置点,实现轨迹隐私保护[25].为了刻画位置扰乱方法中噪声与隐私间的关系,差分隐私的概念被引入.差分隐私的定义由Dwork在2006年提出[26].在该定义下,数据集的计算处理结果对于数据集中具体某个记录的变化是不敏感的,单条记录是否存在于数据集中,对计算结果的影响微乎其微.它主要解决传统隐私保护模型的两个缺点:其一,差分隐私假设攻击者可获得除目标记录之外的所有信息,即假设攻击者可获得所有背景知识,并以此为基础构建隐私保护模型,无需再针对不同背景知识信息,构建相应模型;其二,差分隐私建立在坚实的数学基础之上,对隐私保护进行了严格的定义并提供了量化评估方法,使得不同参数处理下的数据集所提供的隐私保护水平具有可比较性[27].传统差分隐私保护主要针对统计数据库的隐私泄露问题,而位置隐私保护则不同,其无法应用传统数据库隐私保护中的统计特性.基于此,Chatzikokolakis 等人[28]对差分隐私进行了扩展,使其能够适用于位置隐私保护,基于此,他们提出了基于Geo-Indistinguishability[10]的轨迹隐私保护算法.该算法使用差分隐私来刻画实体间的差异性,利用拉普拉斯机制进行加噪,通过提交噪声点来隐藏真实用户的信息.为了尽可能地利用隐私预算,保证轨迹隐私不被攻击者获取,Chatzikokolakis[29]又提出一种基于预测机制的轨迹隐私保护算法.但当差分隐私本身的隐私参数累积超过给定的隐私预算后,在一定程度上会造成隐私泄露问题.因而,当用户的查询量累积到一定程度后,差分隐私算法无法从根本上解决轨迹隐私泄漏问题[24],使得隐私保护的有效时长无法得到保障.
为了解决隐私预算过度依赖所导致的隐私保护时效有限的问题,本文提出NAGDP算法,将K-匿名算法中的匿名组思想融入到差分隐私的噪声生成算法中.该算法以不暴露真实查询用户的位置为目的,通过拉普拉斯机制在给定参数范围内生成多个噪声用户.利用噪声用户来请求服务,使攻击者无法识别出真实用户,以实现真实用户的轨迹隐私保护.由于在用户请求服务过程中多次涉及相关用户的定位过程,而现有的基于差分隐私的轨迹隐私保护算法并未涉及该领域的内容.因此,Ghinita等人[30]提出了基于Hibert-Curve[31]的空间定位算法,但该算法只能实现位置隐私保护.针对轨迹隐私保护中用户位置变化的不定时性以及连续性特点,本文提出UTPP算法,以降低更新空间的代价.通过相关实验证实,K-Differential-Privacy模型克服了现有基于差分隐私的轨迹隐私保护方法对隐私预算过度依赖的缺点,其中,UTPP定位算法的使用也使得用户的服务质量得到了明显的提升.
3 K-Differential-Privacy模型
K-Differential-Privacy模型的核心思想是:以拉普拉斯机制为基础生成噪声,在用户指定的隐私保护参数范围内确定若干个噪声用户,将其设定为匿名用户组,并以匿名组的身份去请求服务.与传统的K-匿名方法相比,K-Differential-Privacy模型最大的不同之处在于,实际提交的匿名组不包含真正的查询用户,同时,结合了差分隐私的思想,使攻击者在给定隐私参数范围内无法区分真实用户与噪声用户.
3.1 基于Chord算法的用户自组织网络
Ghinita 等人[32]实现了一种基于Chord算法的用户自组织网络系统,如图1所示.
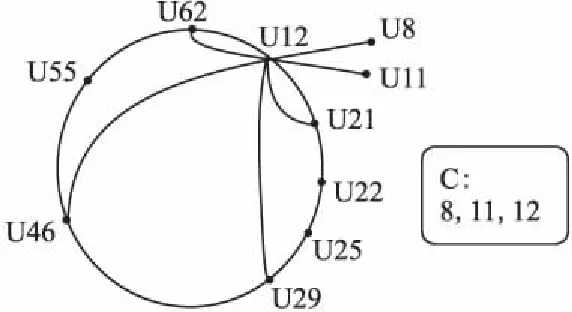
图1 基于Chord的用户自组织网络 Fig.1 User self-organization network base on Chord
系统内用户通过集群的方式自组织一个Chord网络系统,Chord上的每个用户节点是当前集群的头节点.该节点拥有一个包含m(用户的希尔伯特值)位的指向其他节点的指针路由表,路由表中包括:
·指向该节点的直接前驱和直接后继节点指针;
·一个用来提高容错率的后继链表,包含节点n的数个后继节点指针;
·一个存储有距离当前节点距离为2i(i=0,1,2,…,m-1)的节点所在集群头节点的指针链表(不包含已存储的节点).
在如图1所示的基于Chord的用户系统架构中,以用户U12为例进行分析,其存储路由表如表1所示:

表1 用 户U12路由表Table 1 Routing Table for user U12
每个集群的大小应根据当前希尔伯特空间内的用户数目决定,每个集群节点的数目应限制在α到3α-1之间,其中α为系统参数,当前集群内节点数目达到集群最大值时应考虑各个割分集群[32].文献[30]实现了一种基于Hibert-Curve的用户排序方法,在此基础上,用户可获取希尔伯特曲线空间内唯一希尔伯特值.
3.2 K-Differential-Privacy模型概述
K-Differential-Privacy模型如图2所示,主要包括两个子算法:用户轨迹划分定位算法UTPP与基于差分隐私的噪声匿名组算法NAGDP:
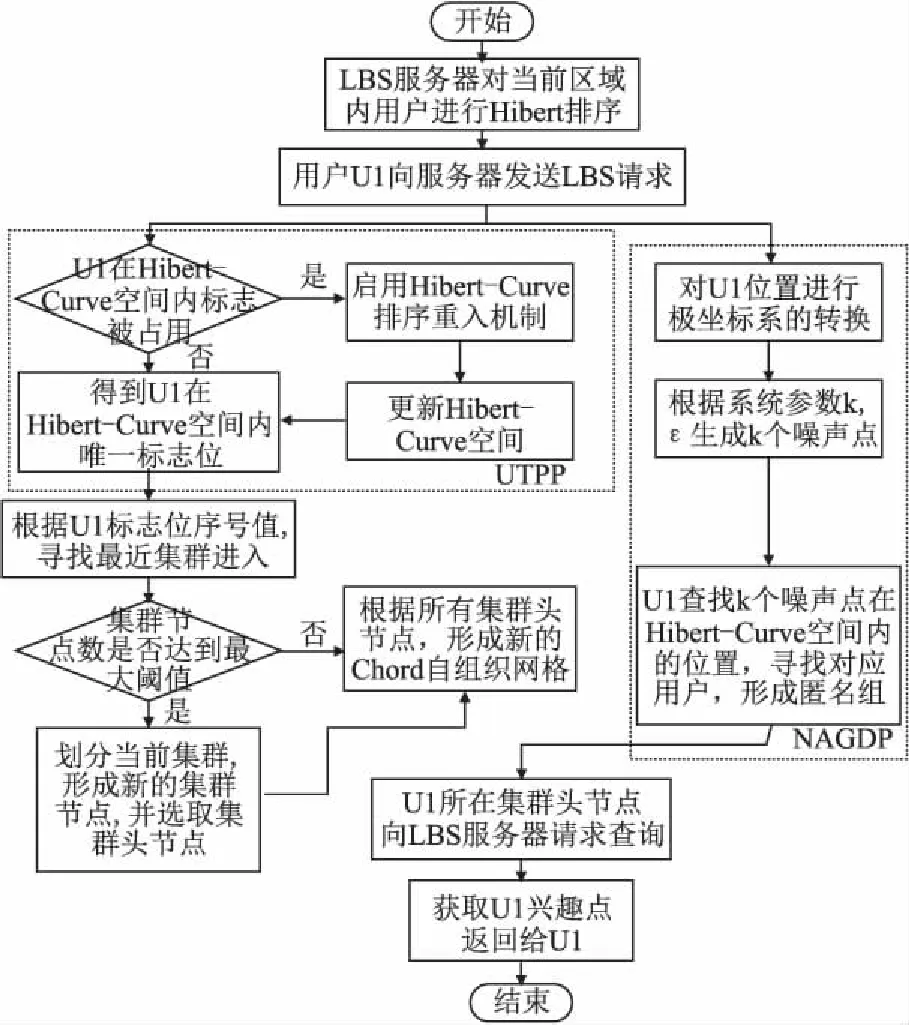
图2 K-Differential-Privacy流程图Fig.2 Flowchart for K-Differential-Privacy
K-Differential-Privacy模型的具体工作流程如下:
Step1.LBS服务器对服务区域内所有用户启用Hibert排序,并使用户维持一个基于Chord算法的自组织网络;
Step2.用户U1向服务器请求LBS;
Step3.系统根据U1所处位置,启用UTPP算法,得到用户U1在Hibert-Curve空间内唯一标志;
Step4.根据新入用户标志,更新集群,得到新的用户自组织网络;
Step5.启用NAGDP算法,对用户U1位置进行极坐标系的转换[33];
Step6.根据系统参数k,ε生成用户U1的k个噪声点;
Step7.以Step6的噪声点在自组织网络中逼近寻找k个用户,生成匿名组;
Step8.用户U1所在集群头节点向LBS服务器请求查询,获取服务.
3.3 UTPP算法
为了减少用户请求LBS时的等待时间,K-Differential-Privacy模型基于分布式架构构建用户自组织网络.在网络中,每个用户都拥有唯一标识,用于查找和定位相关用户.为此,考虑采用Ghinita等人提出的基于Hilbert-Curve[31]的希尔伯特曲线空间,对用户位置进行排序[30].文献[31]提出的Hibert-Curve经过有限次迭代,总能将区域内元素划分至相互隔离的四边形区域,并且由一条曲线贯穿区域内所有分隔空间.基于以上特点,为了保证用户标识的唯一性,本文以用户在曲线上出现的先后顺序作为用户标识,同时采用基于Chord的用户自组织网络对拥有标识符的用户进行维护.
任一区域内的日常通勤LBS用户轨迹较为固定,在该背景下,用户的移动区域维持在固定范围内,该部分用户的希尔伯特空间排序较为稳定.因此,如何对用户新轨迹进行分割定位成为本算法的核心.当用户外出旅游到达一个陌生地时,该地的划分位置所用的服务器上未存储该用户的信息,本文采用H-Space(S)表示当前用户自组织网络中所存储的相关用户在希尔伯特曲线空间内的信息,其中,ULoc表示当前新用户的位置信息,且ULoc∉H-Space(S).此时,排序算法需考虑如何获取新用户的标识符.综上,本文提出适应于轨迹隐私保护的基于Chord的定位算法UTPP,其算法流程如图3所示.
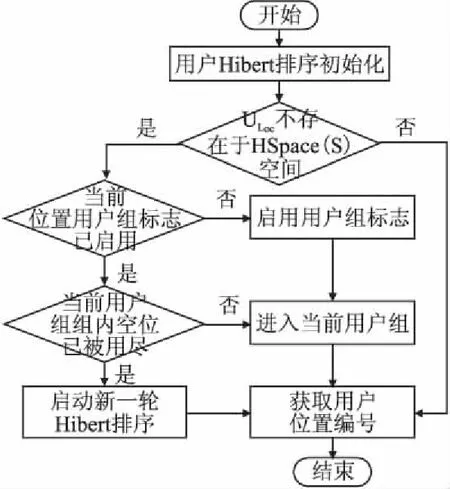
图3 UTPP流程图Fig.3 Flowchart for UTPP
UTPP算法的工作流程如下:
Step1.启动用户的希尔伯特排序过程,对当前区域内所有用户进行排序,形成Hibert-Curve空间,并以用户自组织网络维持;
Step2.在已有排序号的情况下,当有用户发起LBS请求时,查询当前用户在Hibert-Curve曲线空间内的位置序列号(Serial Number in H-Space(S),简称SNIHS).若用户在Hibert-Curve曲线空间内的SNIHS未被占用,直接返回SNIHS作为用户标识符(ID of User,简称IDOU);否则执行Step3;
Step3.当前用户标志位所对应的用户组所包含的用户未达到队内上限,执行用户入组策略,得到用户组内标号(ID in Group,IDIG),进而得到IDOU;否则执行Step4.若使用用户组标志(Flag of Group,FOG)表示SNIHS是否被占用,则Step2与Step3可用如式(1)表示:
(1)
Step4.对于新入组用户U1执行新一轮的Hibert排序过程,获取IDOU.
针对Step 3中的队内上限问题,由于构造每个划分区域的迭代曲线时,曲线的迭代不超过4次,因此,与执行入队策略后直接查找用户的代价相比,在n个已完成希尔伯特排序的用户空间内添加新用户,所耗费的资源应满足公式(2),具体如(2)所示:
kn≤4n
(2)
当组内排序值超过4时,查找新用户的代价实际超过新的希尔伯特排序过程所产生的代价.为此,限定每个组队列上限为4.当组内用户达到上限,启用新一轮的希尔伯特排序.
3.4 NAGDP算法
3.4.1 噪声获取
NAGDP算法以差分隐私噪声生成算法为核心,在一定程度上摆脱了传统差分隐私对隐私预算的过度依赖问题.Chatzikokolakis等人在Geo-Indistinguishability[10]算法中针对位置差分隐私保护提出了一种改进的拉普拉斯加噪方法.该方法以x0代表用户真实位置,使隐私保护参数ε>0,对任意噪声点x,噪声函数的概率密度函数的两种表示方式如公式(3)和公式(4)所示.
(3)
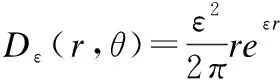
(4)
其中,ε2/2π是一个标准化因子,d(x,x)表达二维空间中两个位置点的欧氏距离.公式(3)与公式(4)分别为噪声函数在正常二维坐标系与极坐标系下的表示.
基于r、θ的独立性[10],通过Dε(γ,θ)对r、θ积分,来表示Dε(γ,θ)关于r、θ的边缘分布函数,具体如公式(5)和公式(6)所示:
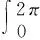
(5)
(6)
由于Dε,θ(θ)的连续性,θ的取值范围为[0,2π).对于r的计算如公式(7)所示:
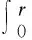
(7)
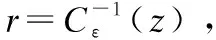
θ=random[0,2π)
(8)
z=random[0,1)
(9)
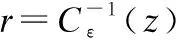
(10)
通过公式(8)、公式(9)和公式(10),可以得到对应具体查询用户位置的噪声点.
3.4.2 NAGDP算法描述
NAGDP算法具体流程如图4所示.
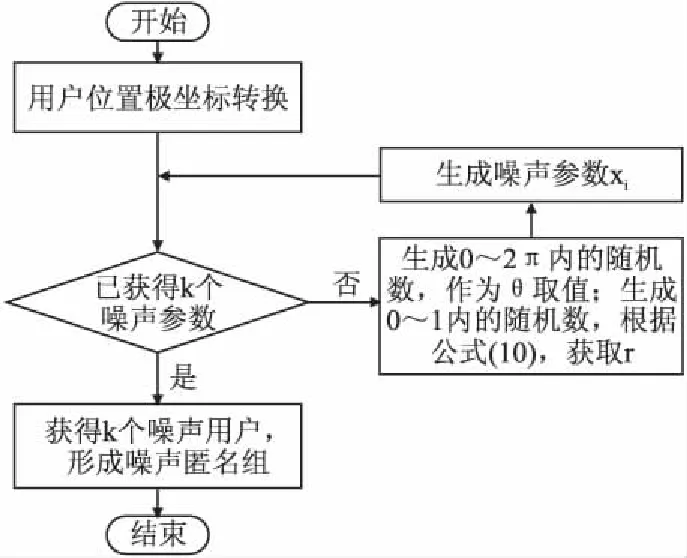
图4 NAGDP流程图Fig.4 Flowchart for NAGDP
算法执行步骤如下:
Step1.用极坐标(rU,θU)表示查询用户的位置参数;
Step2.查询当前用户的噪声参数是否达到系统要求的k值,若是,执行Step 5,否则执行Step 3;
Step3.根据公式(8)和公式(10),得到生成噪声点的两个参数:rN,θN;
Step4.根据rN,θN, 得到实际噪声坐标点xi,执行Step 2;
Step5.根据k个噪声点,获取匿名组用户,形成匿名组.
NAGDP算法将每一次的用户查询看作前后不相关的查询,因而需要指定隐私参数k以及ε,k为匿名组中包含的噪声用户的个数,ε为隐私保护参数[10],在算法实际执行中,该参数描述的是与真实用户的距离r.用户的每次查询请求首先经过自身的处理,生成k个满足隐私参数要求的噪声点.由于噪声点位置并不是提交请求的用户的位置,所以利用噪声点逼近的匿名组成员位置与噪声点之间存在距离差,因此NAGDP的隐私参数ε指定的距离信息r1应小于用户实际指定的距离信息r2.假设最终希尔伯特排序后的划分格边长为l,则r2与r1的关系式应如公式(11)所示:
(11)
由于地理位置因素等特点,生成的噪声点附近可能不存在相关用户(如噪声点在海中心).在这种情况下,可以预先排除不符合要求的噪声点,启动新一轮的噪声点生成算法,直至利用噪声点生成最终的实际查询匿名组,此时,查询用户的一次NAGDP算法完成.
4 实验结果与分析
实验分别从服务质量[34]与隐私保护度[34]两个方面对比了基于Geo-Indistinguishability的轨迹隐私保护算法[29]、MobiHide[32]和本文提出的K-Differential-Privacy模型.其中,基于Geo-Indistinguishability的轨迹隐私保护算法和K-Differential-Privacy模型都以MobiHide作为系统基础.实验采用Geo-life与T-Drive[29]数据集,这两个数据集均来自于微软亚洲研究所.其中Geo-life收集了183名参与者从2007年4月至2012年8月的数据;T-Drive收集了超过104条记录的北京市出租车司机数据.实验以周为单位,划分出不同的查询用户,从划分后的用户中随机抽取每组样本.本实验单机环境为Inter(R) Core(TM) i7 CPU 3.4GHz,8GB内存,window10操作系统.
4.1 实验评价指标
4.1.1 服务质量
隐私保护的服务质量由响应时间来衡量.在相同隐私保护度下,移动对象获得的服务质量越高则隐私保护技术越成熟[24].
响应时间指的是从用户发出LBS请求至用户获取服务的时间,任意选取n位用户,记用户Ui的响应时间为ti,对任意算法模型的平均响应时间MT(Mean Time,简称MT),可按公式(12)计算:
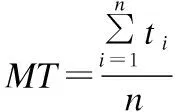
(12)
4.1.2 隐私保护度
隐私保护度一般通过轨迹隐私的披露风险来反映,披露风险越小,隐私保护度越高.披露风险与隐私保护算法和攻击者所掌握的背景知识相关.假设攻击者可以获得除实际查询用户之外的所有信息.用Ui表示查询结束后,攻击者是否推断出实际查询用户.若攻击者推断出用户真实身份,则Ui=true;否则Ui=false.以Ti作为查询结果的统计量,设每组样本实际查询用户数目为n,对于N组样本,披露风险DR(Disclosure Risk)计算公式如公式(13)所示:
(13)
4.2 实验结果分析
算法中的k为匿名组中所包含的用户数目;r为用户指定的隐私保护范围,即在r范围内,攻击者者无法区分真实用户与虚假用户.为了对比三种隐私保护模型的服务质量与隐私保护效果,实验所使用的系统参数如表2所示.其中,MobiHide[32]是一种基于K-匿名的位置隐私保护算法,相关实验采用1000组用户的连续查询数据作为样本,每组包含1000位用户,系统参数k取20.Geo-indistinguishability轨迹隐私保护模型[29]采用1000组用户的连续48小时内的LBS服务数据作为实验样本,系统保护参数r取100(m).针对所提出的K-Differential-Privacy模型,为了保证实验对比的有效性,同样系统参数k取20,r的取值应根据公式(11)以及每次划分的希尔伯特空间大小共同确定,采用1000组样本取均值.
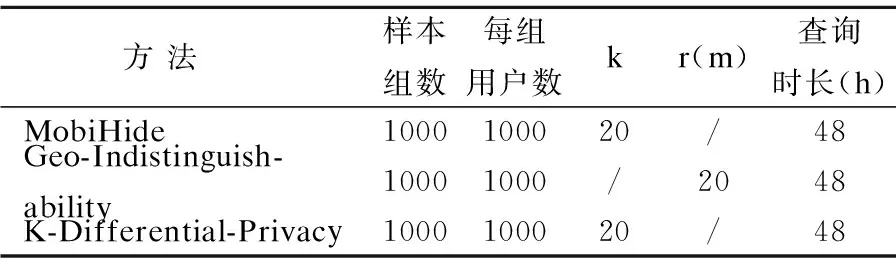
表2 对比实验使用参数Table 2 Used parameters in comparative experiment
4.2.1 服务质量
以响应时间作为3种隐私保护算法服务质量的衡量标准,实验采用的系统参数如表2所示.
从数据集Geo-life和T-Drive中挑选1000组样本,每组随机挑选1000位用户.其中,按照公式(12),取1000位用户LBS请求的响应时间进行统计.得到每组的平均响应时间.
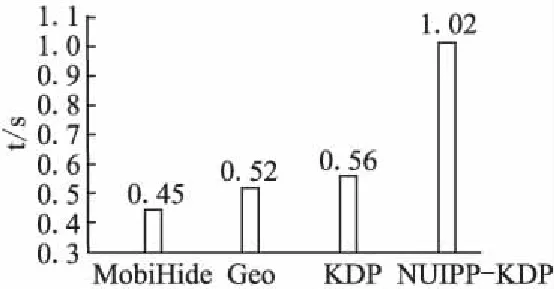
图5 平均响应时间对比Fig.5 Comparison for average response time
由于部分方法名过长,无法在图中完全显示, Geo-Indistinguishability算法在图中用Geo表示,K-Differential-Privacy用KDP表示,未使用UTPP算法的K-Differential-Privacy模型用NUTPP-KDP表示.4种方法的平均响应时间MT如图5所示.
从图5中可以看出,未使用UTPP算法的K-Differential-Privacy模型的平均响应时间远远高于其他三种模型;MobiHide模型的平均响应时间最少;完整的K-Differential-Privacy模型与Geo-Indistinguishability模型相比,时间消耗上略有增加,但总体仍在可接受范围内.实验结果反映了UTPP定位算法的必要性.
4.2.1 隐私保护度
针对连续查询,按照表2给定实验参数,根据公式13统计三种隐私保护模型的隐私披露情况.对比结果如图6所示.
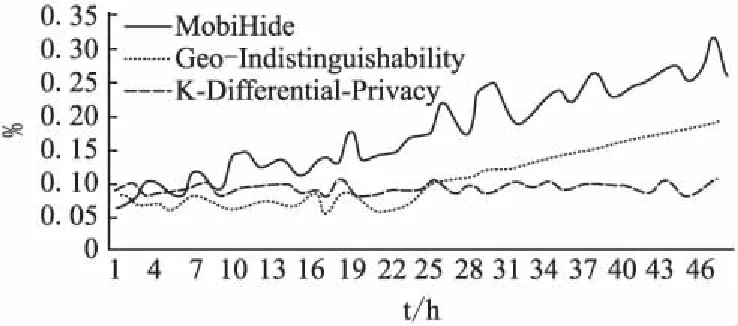
图6 三种隐私保护模型的保护效果Fig.6 Protection effect of the three kinds of privacy protection models
从图6可以看出,当多组用户的LBS服务时间在24小时以内时,Geo-Indistinguishability轨迹隐私保护模型与K-Differential-Privacy模型泄露隐私的概率相差不大,且两个轨迹隐私保护模型的隐私保护效果较好.然而当查询累积超过24小时之后,Geo-Indistinguishability轨迹隐私保护模型泄露隐私的概率随时间的增加而明显增加.而K-Differential-Privacy则没有明显变化.对于MobiHide模型,实验结果表明,当用户的查询次数累积到一定数量之后,隐私泄露概率随查询次数的增加而明显增加,可见,位置K-匿名算法无法有效保护轨迹隐私.
目前,统计推理攻击的时间跨度远远大于24小时[35],基于Geo-Indistinguishability的轨迹隐私保护算法仅能在24小时内有效保护用户隐私,当用户长时间查询数据时,攻击者很容易获得用户的轨迹隐私信息.本文的K-Differential-Privacy轨迹隐私保护模型能够在查询累积时长超过24小时的情况下保证轨迹隐私保护效果.因此,对于累积查询时长较长的用户群,K-Differential-Privacy轨迹隐私保护模型具有更好的轨迹隐私保护效果.
5 总结与展望
针对LBS的轨迹隐私保护问题,本文提出了一种基于拉普拉斯机制和匿名组的LBS轨迹隐私保护算法NAGDP.同时,为了加快LBS请求服务的响应速度,本文引入了基于差分隐私轨迹隐私保护的用户定位算法UTPP.二者共同构成轨迹隐私保护模型K-Differential-Privacy.该模型对LBS用户的真实位置进行多轮加噪,以获取匿名组,并以匿名组的名义请求LBS服务,克服了差分隐私在轨迹隐私保护中的隐私预算过度依赖问题,提升了轨迹隐私保护效果.
目前,基于差分隐私的LBS轨迹隐私保护的相关研究仍处于起步阶段.尽管差分隐私无视攻击者背景知识的特点弥补了K-匿名在该方面的缺陷,但现有模型仅是基于位置的拉普拉斯加噪机制的扩展.应用范围更广、隐私保护效果更好的轨迹隐私保护模型仍有待研究.其次,由于本文的定位算法引入了新的组策略,因此,组策略对划分集群阈值的影响仍有待进一步研究.
