LibSeeker:参数自整定的安卓应用第三方库检测方法
2019-02-15黄思荣陶非凡
黄思荣,陶非凡,张 源,杨 珉
1(复旦大学 软件学院,上海 201203) 2(上海通用识别技术研究所,上海 201100)
1 引 言
近年来,智能移动设备在人们日常生活中扮演了不可或缺的角色,其中,安卓是目前最受欢迎的手机操作系统,截止至2017年3月,国内安卓系统份额已暴涨至87.3%[注]https://www.kantarworldpanel.com/global/smartphone-os-market-share/,各类安卓应用市场为用户提供了大量功能丰富的应用软件.第三方库(Third-party libraries)在安卓应用程序中被广泛使用,开发人员使用它们来构建新功能、整合外部服务和减少发布应用程序的时间,常见的诸如在应用中加入广告进行盈利、将应用与在线社交媒体进行整合、引入单点登录服务等.安卓开发人员可以从流行开源项目服务(如GitHub,BitBucket)或在线软件包存储库(如Maven)上找到很多有用的第三方库.此外,安卓集成开发环境(Android Integrated Development Environments,简称Android IDE)中大多内嵌Maven/Gradle支持,极大方便了开发人员使用第三方库.有时开发人员需要进一步修改第三方库使其更适用于当前的安卓应用,例如,调整一些UI部件的外观等.这种情况下,开发者通常会从项目服务或在线软件包存储库上下载第三方库源码,并直接对源码进行修改.
第三方库的开发和使用为安卓应用程序的开发带来了很大的帮助,但是同样也给用户带来了安全隐患和隐私泄露的风险.2015年10月,淘米客SDK[注]http://thehackernews.com/2015/10/android-apps-steal-sms.html个被超过63,000个应用使用的广告库,被曝光窃取用户短信.此外,一些流行的第三方库如百度SDK[注]http://thehackernews.com/2015/11/android-malware-backdoor.html、Facebook SD[注]http://thehackernews.com/2014/07/facebook-sdk-vulnerability-puts.html、Dropbox SDK[注]http://www.infoworld.com/article/2895016/mobile-technology/ibm-discloses-droppedin-vulnerability-for-dropboxs-android-sdk.html都曾被发现有严重的漏洞,能被攻击者利用来控制受害者的设备、窃取敏感信息并注入恶意负载代码(malicious payload).然而,现有的应用程序安全分析工作(比如隐私泄露分析[10,11]、权限/风险分析[12,13]、敏感API分析[14,15]、漏洞分析[16,17]等)通常把整个应用作为单一主体,因此无法准确检测出恶意行为是来自于应用代码还是第三方库代码.此外,第三方库的广泛使用严重影响了应用分析工具的有效性.例如,目前的应用克隆检测工具大多数通过比较应用间的代码相似度实现,因此若两个不同的应用程序使用了大量相同的第三方库,这些工具就会产生误报.
应用程序构建的过程模糊了开发者编写的代码和第三方库之间的边界,同时开发者常使用混淆工具(如ProGuard)对字节码进行混淆,因此可靠有效的第三方库检测方法应该对常见的混淆技术具有适应性.现有的第三方库检测工作如依赖于流行第三方库名单的简单包名匹配、程序克隆检测等,这些方法可靠性不够,且无法应对代码混淆和包名冲突等情况.如何精确可靠地识别第三方库成为一个有待解决的技术挑战.LibScout[1]虽然能应对基本的混淆手段,但是它也存在一些问题:一是完全不考虑函数内部的实现,丢失大量代码信息,容易造成误匹配;二是LibScout中用到的参数阈值是根据人工经验确定,效果会受到较大的人为影响.这也是现有的第三方库检测方法常见的问题,即参数阈值往往通过有限的实验或人工指定.如果在检测工具中能实现对所有可能的参数阈值通过有限实验进行自整定,确定一组最佳的参数赋值用于最终的第三方库检测,阈值的设定将更加可靠有效.
针对上述问题,本文设计并实现了一个第三方库检测工具LibSeeker.它在LibScout函数签名哈希的基础上,加入函数特征向量对函数进行匹配,补充缺失的代码信息,降低函数误匹配的概率.不同于LibScout以类为比较的基本单位,LibSeeker的匹配细化到函数层面,并根据下一层的匹配情况逐层确定类、包以及整个第三方库是否匹配.同时,我们还实现了参数自整定功能,对LibSeeker中使用到的参数阈值进行自动调整测试,通过实验确定了最佳的参数组合.LibSeeker检测第三方库的准确率与召回率在整定后的参数设定下能达到99.82%和95.77%,相比LibScout有大幅度的提升.
2 背景及挑战
2.1 第三方库检测
本节主要介绍关于第三方库检测的现有研究工作,包括代码克隆检测、基于机器学习或代码聚类的检测、以及基于哈希特征文件的检测等.
2.1.1 现有的检测方法
针对第三方库检测的技术,最简单的就是通过第三方库的包名白名单在应用代码中检测第三方库.但是当应用进行一些简单混淆(如标识符重命名)后这个方法就会失效.
代码克隆检测(Clone Detection)技术,本质上就是检测两段代码之间的相似程度.通常会基于代码相似度进行计算[2],或是通过从程序依赖图(program dependency graphs)中提取语义特征[3]进行分析,从而检测出克隆应用.
AdDetect[4]和PEDAL[5]使用机器学习来检测第三方广告库.AdDetect使用分层包集群(hierarchical package clustering)来检测应用程序中的(非)主要模块;而PEDAL则从第三方库SDK中提取代码特征并使用包之间的关系信息来训练分类器,从而在标识符被混淆的情况下也能检测出第三方库.
AnDarwin[6]和WuKong[7]通过代码聚类技术检测第三方库代码.这种方法的前提假设是第三方库被许多应用普遍使用,且第三方库代码不会被修改.但因为在应用程序构建过程中常常自动或人工地消除死代码(dead-code elimination),并且开发者自定义调整第三方库的情况也很普遍,所以这个假设并不现实.LibRadar[8]扩展了WuKong的聚类方法,并根据在聚类中不同包内的API调用频率为每个检测到的聚类生成独特的特征文件,实现对第三方库的快速检测.由于代码聚类和特征提取都不是在原始第三方库上进行,对具有相同的根包(root package)的第三方库容易产生误报.
2.1.2 基于哈希特征文件的第三方库检测——LibScout
LibScout[1]为第三方库构建与代码无关的特征文件,利用高层级的类组织信息来进行特征文件匹配,检测应用是否包含给定的第三方库.LibScout能够应对一些常见的混淆技术,包括标识符重命名、API隐藏、控制流随机化以及字符串加密等.
LibScout的特征文件是基于层级结构提取的.对于每个第三方库,按函数、类、包、第三方库(或应用)这四个层级,由下自上生成哈希,形成一棵深度为3的默克尔树(Merkle Tree).最底部的函数哈希使用精简过的与代码无关的函数签名,往上每层的哈希值是对所有下一层子节点的哈希值进行排序、然后再取哈希.匹配特征文件则是从上而下进行的,先从包的哈希开始比较,当包的哈希值不匹配时,再比较包下每个类的哈希值,并计算包的相似度,同时根据包名的结构和根包对可能的匹配进行筛选,最后挑选符合条件并且相似度最大的匹配对.
LibScout基于函数签名哈希的匹配方法快速简单,但是由于只提取了函数外壳信息,内部的代码都被忽略,而不同函数签名冲突的概率较高,因此容易造成较大的误匹配率.如图1所示,第三方库中的包X与应用中的包Y都有两个类,它们的内部实现不同,但是由于忽略了函数内部实现和自定义类型,包内的两个类提取出的函数签名完全一样,LibScout会错误地将类A、B分别与类C、D匹配,从而得到包X与包Y误匹配的结果.同样地,不同版本的第三方库如果仅仅修改了函数内的代码,整体的层级结构没有变,那么最后得到的哈希特征文件也是一样的,很可能会匹配到错误的第三方库版本.因此,基于函数签名哈希的方式在应对混淆技术的同时,也给第三方库检测带来了不准确性.
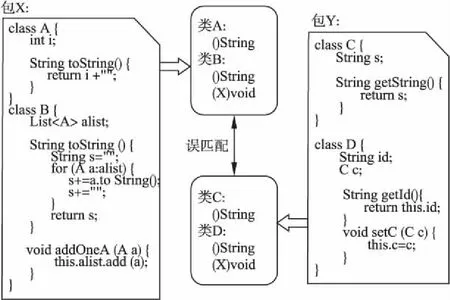
图1 LibScout误匹配示意图Fig.1 Mismatch of LibScout
2.2 参数自整定
参数自整定(parameter auto-tuning)本质上是对所有的参数向量(parameter vector)进行遍历,从中挑选出在预先设定的衡量标准下最优的参数向量.一个好的调优算法(tuning algorithms)会用尽可能小的代价来尝试找出一个足够好的参数向量.目前的调优算法主要从两方面来降低总搜索量,一是减少需要进行测试的参数向量数量,二是减少为每个参数向量创建的测试数量.本文中我们主要使用正交试验和UCB算法来降低搜索量,并使用ROC曲线的AUC值来衡量每个参数向量的效果.
2.2.1 正交试验
正交试验设计(Orthogonal experimental design)根据正交性从全面试验中挑选出部分有代表性的点进行试验,是研究多因素多水平试验的一种设计方法.表1是一个三因素二水平的正交表,括号内是某化工产品转化率试验的数据,三个因素分别为温度、时间和加碱量,每个因素都有两种水平取值.如果按照全面实验要求,需要23=8种参数组合的实验;而按照L4(23)正交表安排实验,则只需要进行4种参数组合的实验,大大减少了工作量.
表1 用于转化率试验的L4(23)正交表
Table 1 L4(23)used in conversion experiment

试验号1(温度)2(时间)3(加碱量)11(60°C)1(60min)1(5%)21(60°C)2(120min)2(7%)32(100°C)1(60min)2(7%)42(100°C)2(120min)1(5%)
正交表同样简化了试验数据的计算分析,根据试验结果可以挑选出这些试验中最好的参数组合,同时可以推断最优的参数组合.对于同一个因素的每一水平取值,其他因素的每个水平分布是均匀的,因此,我们可以统计每列因素上各水平实验效果的数据和,计算得到各水平数据的综合平均值和各因素的变动平方和,分析出每个因素上各水平取值对实验结果的影响趋势,从而挑选出每个因素的最优水平取值,进一步猜测出最佳的参数组合.当对参数粒度要求较高时,可以根据目前的结果进一步细化各因素的水平值,重复进行正交试验,直到找到满意的参数组合.
2.2.2 UCB算法
UCB(Upper Confidence Bound,置信区间上界)算法提供了一种多臂问题的选择方式,根据每个臂被选所获得的收益以及被试次数,计算出每个臂的收益均值与试验次数标准差之和,挑选值最大的作为下一个进行试验的臂,从而使获得的收益最大化.
其他针对多臂选择的算法如小量贪婪(epsilon-Greedy)算法和SOFTMAX算法等,容易受到臂回报随机性的影响,当初始遇上一次随机坏的结果,这个臂之后被选中的概率会非常小,而这个臂的整体效果有可能并不差.UCB算法克服了这些缺点.它完全不使用随机性,每一种情况下,UCB选择的臂都是可以通过数据计算出来的;它不仅仅关注于收益,同样会关注每个臂被试验的次数;且UCB算法没有任何需要配置的参数,不需要任何先验条件.OpenTuner[9]中作者就采用了类似算法来降低搜索代价.
UCB算法对于参数自整定的意义,在于平衡了我们对不同参数向量的实验次数.对于效果很差的参数向量,我们在少量的测试后就能放弃,减少无意义的测试;而对于效果很好的参数向量,我们则不断地对其进行测试以保证它的好效果并非偶然.
2.2.3 ROC曲线与AUC值
ROC(Receiver Operating Characteristic)曲线和AUC(Area Under Curve)常被用来评价一个分类器的优劣.ROC曲线是根据不同的分界值,以真阳性率(True Positive Rate,TPR)为纵坐标、假阳性率(False Positive Rate,FPR)为横坐标绘制的曲线.其中,真阳性率和假阳性率的计算公式分别为TPR=TP/(TP+FN),FPR=FP/(FP+TN).图2是一条ROC曲线,曲线上最靠近坐标图左上方的点D效果最好,敏感度和特异度均较高.实际实验中可通过计算约登指数(Youden′s J statistic)求得这个最优临界点,约登指数大小为TPR与FPR之差,刚好就是ROC曲线上的点到y=x在垂直方向上的长度J.

图2 ROC曲线和约登指数Fig.2 ROC and Youden′s J statistic
AUC被定义为ROC曲线下的面积.当随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的分值将这个正样本排在负样本前面的概率就是AUC值.AUC值越大,分类器效果更好.
比起其他的评价标准,ROC和AUC不容易被样本的不均衡性所影响.当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变.在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化,这种情况下使用ROC曲线衡量分类器比直接使用准确率和召回率效果要稳定得多.
2.3 存在的问题与挑战
简单的包名匹配当遇上标识符重命名等混淆机制就会失效,而应用中第三方库代码常被修改又容易影响到基于代码聚类的方式.LibScout虽然可以避免标识符重命名和API隐藏等混淆技术的影响,并根据哈希特征文件检测是否包含给定的第三方库,但由于只是对模糊函数签名取哈希,对函数内部的代码变动不敏感,在有助于应对混淆的同时,也造成了较大的误匹配率.
实现一个可靠高效的安卓应用第三方库检测工具面临以下几个挑战:
一是在提高检测准确率的同时要保证一定的混淆适应性.想要避免LibScout简单哈希特征文件带来的高误报率,需要加入更多的关于函数代码或结构等的信息.但是,常见的混淆工具如Android Studio中自带的ProGuard,有修改包名、类名和变量名,消除死代码等混淆功能,开发者同样可能对第三方库进行个性化定制,因此加入的信息需要在代码被修改或删除的情况下,对检测第三方库的结果有较小的影响.
二是在保证结果可靠性的同时确保增加的时间开销是合理的.工具应该要尽可能准确地检测应用中包含的第三方库,提高检测的准确率和召回率,但是这需要分析更多信息,消耗更多时间.然而,分析一个安卓应用应该在一定时间范围内,特别是在实际使用中,工具需要对应用商城中成千上万的安卓应用进行分析,因此希望每个应用需要的分析时间是在合理范围内的.所以第三方库检测工具在加入更多分析信息以提高准确率的同时,也要确保带来的额外时间开销是能被接受的.
三是实现参数的自动调整.以往的分析工具对于一些参数阈值的指定,绝大多数是根据人工经验指定,或者是人为指定一些可能的值、通过有限的实验确定里面效果最好的参数.但是这样的参数确定方式存在太大的人为因素,且不能在一定范围内遍历所有参数组合.而直接遍历所有可能的参数向量费时费力,尤其当参数较多时,遍历带来的代价太大.因此,我们需要找到一种方式,在尽可能少的测试次数中,挑选出指定范围内最好的参数组合.
3 LibSeeker基本架构
针对第三方库检测面临的问题和挑战,本文设计并实现了一个能自动调整参数的第三方库检测工具LibSeeker.如图3所示,LibSeeker主要由第三方库检测模块和参数自整定模块两部分组成.
第三方库检测模块.该模块主要实现了检测安卓应用是否包含给定第三方库的功能.首先为APK和第三方库中的函数提取函数签名哈希和特征向量centroid作为识别函数是否相似的特征,然后进行第三方库与APK之间的包匹配,通过类匹配程度和包之间的层级关系确定并筛选候选列表,列举所有情况并计算出全局最大相似度,从而得到最终匹配结果及第三方库相似度分值.
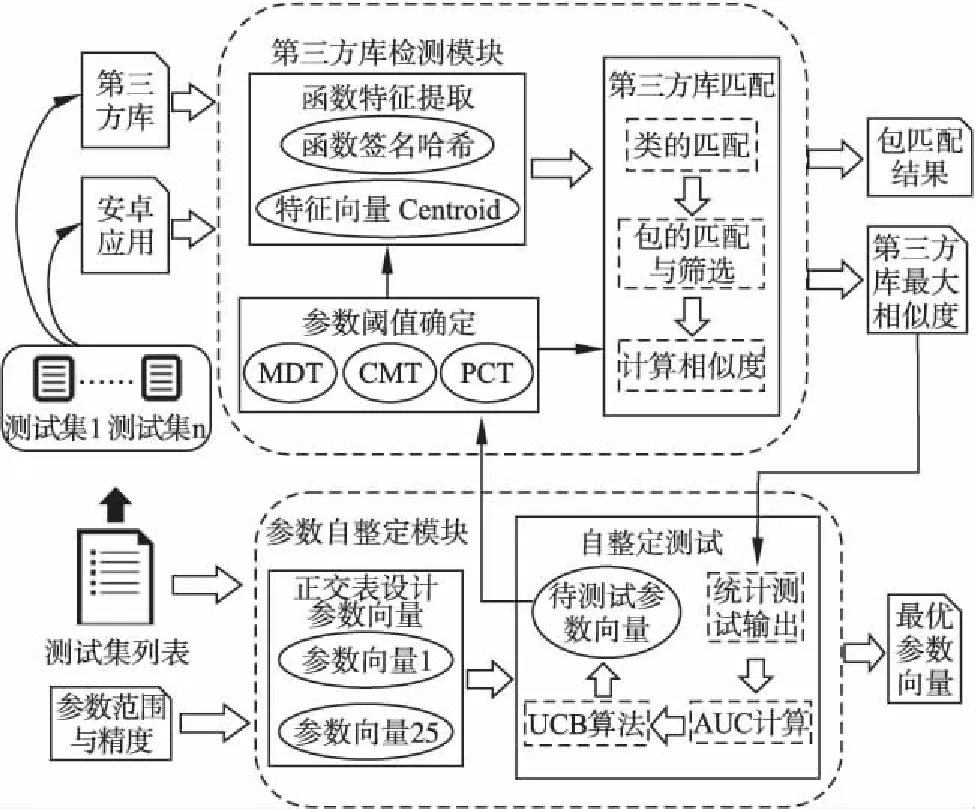
图3 LibSeeker系统架构图Fig.3 System architecture of LibSeeker
参数自整定模块.该模块主要实现对第三方库检测中使用到的参数阈值进行自整定的功能.根据预先设定的参数范围与精度,使用正交表设计参数向量,利用UCB算法挑选下一组测试的参数向量,传入第三方库检测模块设置参数阈值对测试集进行测试,统计结果并计算AUC值,回馈给UCB算法用以计算选出下一次进行测试的参数向量,直到所有测试集测试完毕.分析统计结果从而得到不同参数对测试结果的影响趋势并挑选或推断出最佳的参数组合.
4 LibSeeker设计与实现
为了保证LibSeeker的快速有效,我们的实现基于LibScout使用的函数哈希,并结合函数特征向量centroid,匹配安卓应用程序与第三方库的类和包,计算应用与该第三方库的相似度分值,并输出匹配结果.同时,我们还利用正交表和UCB算法,实现对参数阈值的自动优化.
4.1 函数特征提取
本文中底层的函数匹配主要基于函数特征向量centroid以及函数签名哈希.LibScout中函数匹配主要基于与代码无关的函数签名哈希,这类特征的优点是快速简单、节省时间,但是忽略了代码信息会带来一定的误差.复杂函数若只使用仅保留签名外壳的哈希值匹配,丢失的信息太多,容易造成误匹配,因此需要使用特征向量辅助匹配.通过分析大量应用并提取它们的特征向量,我们发现很多简单函数如get或set函数,提取出的特征向量完全一样,且在应用程序中这类函数数量众多,特征函数的提取对于简单函数的匹配基本上没有太大帮助.因此,为了节省比较时间,在本文的实现中,简单函数直接使用签名哈希进行匹配,而复杂函数则在此基础上增加了函数特征向量的匹配.
4.1.1 函数签名哈希
本文采用与LibScout相同的函数哈希.我们要提取与代码无关的函数签名,首先为每个函数提取原始签名,原始签名由函数名,参数列表和返回值类型三部分组成,例如com.fudan.A.test(android.app.Activity,boolean,com.fudan.B)com.fudan.A,其中函数名com.fudan.A.test和参数与返回值中出现的自定义类型com.fudan.B、com.fudan.A都可能被混淆工具混淆,因此我们去掉了函数名,并用一个统一的标识符X取代出现的自定义类型,而基本类型如boolean以及安卓系统定义的类android.app.Activity则不会被混淆,所以保留下来,最后我们得到的与代码无关的函数签名为(android.app.Activity,boolean,X)X.我们用MD5算法对这些签名取哈希值并保存下来,以供后续第三方库匹配中使用.
不同于LibScout逐层向上取哈希并将类的哈希值作为比较的基本单位,我们在匹配函数时还需要加入复杂函数特征向量的比较,因此对于类和包我们不采用排序取哈希的方式,而是在之后匹配过程中通过计算匹配成功的函数比例来判断类与包是否匹配.
4.1.2 函数特征向量
我们需要为复杂函数提取函数特征向量centroid.首先根据函数中基本块(basic block)数量和指令(instruction)数量判断函数是否为需要提取centroid的复杂函数.因为基本块多代表函数内部实现出现的循环和判断语句较多,逻辑复杂,而指令数量则比较直观地反映了函数代码的长度.在本文的实现中,当基本块数量大于2或指令数量不少于10时,我们认为这个函数时一个复杂函数.
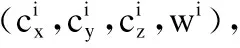
最后,我们通过计算两个函数centroid之间的差异度来判断这两个函数是否相似.对于centroid向量的8个坐标维度,分别计算每个维度上的差异度,例如cx上的差异度为
而两个特征向量centroid之间的差异度是取这8个维度上差异度的最大值.当这个最大值小于我们预先设定的函数差异阈值METHOD_DIFFERENCE_THRESHOLD时,我们认为这两个函数相似.
4.2 应用程序与第三方库的匹配
不同于LibScout自顶向下地通过比较包哈希与类哈希进行匹配,LibSeeker中安卓应用与第三方库的匹配过程是由底层逐层往上确定的,同时也结合包之间的层级关系进行分析.我们根据函数的匹配情况确定类是否可能匹配,同样也根据类的匹配情况确定第三方库包的候选APK包列表.在匹配的过程中我们还要求对应APK包和第三方库包的层级关系保持一致,以此对候选者进行筛选.最后从列举的所有情况中,找出相似度最大的包匹配.
4.2.1 类之间的匹配
为了判断一个给定的第三方库类和应用APK类是否匹配,我们循环遍历了第三方库类中每一个函数,尝试匹配APK类中还未匹配成功的函数.对于每对尝试进行匹配的函数对,我们首先判断该函数是否同为简单函数或同为复杂函数(基本块数量大于2或指令数量不少于10),当它们同为简单函数时,只要它们的哈希值相同,就认为这两个函数匹配成功;当它们同为复杂函数时,除了哈希值相同,还要求MDD值小于METHOD_DIFFERENCE_THRESHOLD,才算匹配成功;否则匹配失败.当匹配成功的函数对数除以该第三方库类中总函数个数所得的值不低于类匹配相似度阈值CLASS_MATCHED_THRESHOLD时,我们认为这两个类是匹配的.
4.2.2 包之间的匹配与相似度计算
当检测一个安卓应用APK是否包含给定第三方库时,我们要先为每个第三方库包寻找所有可能的候选APK包.遍历所有APK包,计算与当前的第三方库包之间的匹配程度,对第三方库包中每个类,尝试匹配APK包中尚未匹配成功的类,计算类匹配成功数量除以该第三方库包中类的总数,若该值不小于候选匹配包相似度阈值PACKAGE_CANDIDATE_THRESHOLD,则将当前这个APK包加入该第三方库包的候选列表中.
接着,根据包的层级筛选候选匹配列表.在APK包候选者中寻找包名和第三方库包完全相同的候选包,将其放入成功匹配的第三方库包-APK包列表中.每次新加入包匹配对时检查与之前列表中已经存在的包匹配对是否存在相邻或父子关系,若存在这些关系,判断它们匹配的APK包名与新加入的APK包名是否存在同样的关系,如果关系不一致,就抛出匹配失败的异常.对当前已经成功匹配的包对,提取第三方库包的根包名(root package name),然后对还未匹配成功的第三方库包的候选列表进行过滤,若未匹配第三方库包与已匹配第三方库包拥有共同的根包,则它的候选APK包也一定是在对应的根包下,否则就将其从候选者中删除.
最后,根据已经匹配成功的第三方库包-APK包列表、待匹配第三方库包的候选列表以及这些包名之间的相邻或父子关系,枚举所有可能的匹配情况,计算每种情况下第三方库中匹配成功的类总数除以第三方库所有包下的类总数的值,作为与第三方库的相似值.取所有情况中全局相似度最大的值作为最终的第三方库相似度,并输出该情况下第三方库与应用中包的匹配情况.同时,我们通过设定第三方库相似度阈值LIBRARY_SIMILARITY_THRESHOLD来进行分类,输出该应用是否包含给定第三方库的判断结果.
4.3 阈值参数自整定
在上文特征提取和第三方库匹配的实现中,有以下4个阈值会影响我们的第三方库检测工具的准确性:
1)METHOD_DIFFERENCE_THRESHOLD(函数特征向量centroid差异度阈值,下文简称MDT);
2)CLASS_MATCHED_THRESHOLD(类匹配相似度阈值,下文简称CMT);
3)PACKAGE_CANDIDATE_THRESHOLD(候选匹配包相似度阈值,下文简称PCT);
4)LIBRARY_SIMILARITY_THRESHOLD(计算出的与第三方库相似度阈值,下文简称LST).
我们根据正交表L25(56)设计25种参数向量,利用UCB算法减少参数优化过程中的测试次数,通过ROC曲线的AUC值衡量每种参数组合的效果,从而挑选出在一定精度下最优的参数组合.由于采用AUC衡量实验结果,当把LibSeeker视为一个二元分类器时,LST就是分界值,所以可以在我们挑选出AUC最大的参数向量之后,再根据ROC曲线得到最优分界阈值作为LST.因此,我们只需要对MDT、CMT和PCT这三个参数进行参数自整定.
4.3.1 根据正交表设计参数向量
我们选择六元素五水平正交表L25(56)来设计参数的实验组合.取L25(56)前三列分别作为MDT、CMT和PCT对应的因素,根据预先设置的参数范围和精度,为每个参数分配5个实验值,然后按照L25(56)中的25种水平组合,设计25个参数向量进行实验.
由于正交试验设计的特性,对于每个参数,在每种水平取值下,其他参数的水平取值分布是均匀的.因此,我们可以根据这25组实验的结果,将各参数下每种取值的结果累加,获得水平数据和,并计算水平平均值和极差,从而分析出该参数的取值对实验结果的影响趋势,缩小最优取值的可能范围.然后在缩小后的范围内,重新为每个参数分配5个水平实验值,重复实验,直到最后各参数值之差符合要求的精度,即可分析挑选出最佳的参数向量.
4.3.2 计算AUC值
对于每个参数向量,我们将使用已知的安卓应用与第三方库测试集进行测试,测试集事先标注好该应用是否包含列出的第三方库.每次测试实验后能得到一组数据,即LibSeeker计算所得的第三方库相似度分值和正负样本的标签.
我们将获得的实验结果按照相似度分值从大到小排序,依次将每个数据点的相似度分值作为分界阈值,分值大于它的被判断为正样本,小于它的被判断为负样本,统计以该数据点为分界值情况下的true positive rate(TPR)和false positive rate(FPR),即可生成ROC曲线.
我们可以根据ROC曲线上的数据点来计算AUC值.具体地,每个数据点都记录了大于当前分界阈值的正样本个数(即TP)和大于当前分界阈值的负样本个数(即FN).已知测试集中的正样本总数和负样本总数,因此可以计算出每个数据点的TPR和FPR.因为AUC是ROC曲线下的面积,所以可以通过不断累加求面积的方式计算AUC.将数据点列表按照TP和FP从小到大排序,如图4所示,首先计算第一个数据点的TPR和FPR值,接着计算TPR与FPR乘积除以2的值,即为该点与原点连线上方的三角形区域(图4中area区域)的面积,加入累加面积S中.之后循环遍历每个数据点,计算上方增加的梯形面积x-y,并把它加入S中.其中,x等于当前节点与前一个点的TPR之差乘以当前FPR,y等于当前节点与前一个点的TPR之差与FPR之差的乘积除以2.当所有数据点遍历结束后,就能获得ROC曲线上方空间的总面积S,又因为整个空间面积为1.0,所以AUC可以由1.0减去S求得.
4.3.3 利用UCB算法进行自整定测试
首先我们将所有已知正负的数据集均匀随机地划分为n个测试集合(n值远大于25),每个测试集中有一定数量的正样本和负样本,当挑选一组参数向量对测试集进行试验后,我们能获得该参数向量在这次实验中计算得到的AUC值.
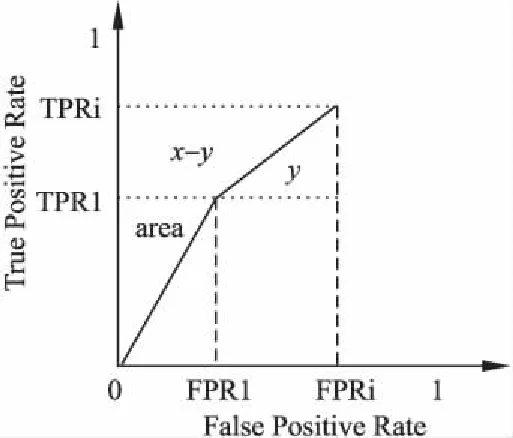
图4 ROC曲线面积计算示意图Fig.4 Area calculation of ROC
接着,我们利用UCB算法来为每个参数向量分配测试机会,对效果不好的参数向量尽早过滤,对效果很好的参数向量反复实验从而获得一个稳定的结果.
我们把25个参数向量当作多臂老虎机的臂,把AUC值作为拉动一个臂获得的收益.对于第1个测试集,我们将所有参数向量都试验了一次,获得每个参数向量的初始AUC值.对于之后的第2至n个测试集,每次都要计算选择权值C-score,挑选权值最大的参数向量进行实验.选择权值的计算公式如下:
其中,t是目前测试的总次数,Tj,t是该参数向量目前跑过的测试集数量,α是用以平衡AUC均值和次数附加值的一个常数因子.因为AUC值在0.5到1.0之间,而后面的试验次数附加值大于1,因此需要通过乘以α来使得公式前后两部分处于同一数量级下.在这种情况下UCB算法才能发挥较好的效果,既能给效果好的参数向量更多的测试机会,以期获得相对稳定的结果,避免因为偶然的高值导致的误差,同时也能给予试验次数少的参数向量被选中的机会,避免因为初始的低值就被排除在试验之外.
当所有测试集测试结束后,统计每个参数向量的测试次数和平均AUC值,分析向量的三个因素对结果的影响,根据实验结果和实际的精度需要,继续设计参数向量进行实验或结束测试返回最佳参数组合.具体实验情况可见5.2节.
4.3.4 最优分界值LST的确定
当MDT、CMT和PCT这三个参数通过参数自整定过程确定最优组合后,我们得到最终LibSeeker检测的ROC曲线.接着我们就可以通过计算约登指数来确定ROC曲线的最佳临界点.约登指数计算公式如下:
约登指数=敏感度+特异度-1=TPR-FPR.
ROC曲线的纵坐标TPR即为敏感度(sensitivity),而横坐标FPR等于1-特异度(1-specificity),所以约登指数最大的点就是TPR与FPR差值最大的点,也就是图中最靠左上角的点,该点所取的临界值即为最佳LST.具体实现只需要通过遍历ROC曲线上所有数据点,计算它们的约登指数即可找出最佳分界点,从而得到该点所取的分界值LST,统计出准确率和召回率.
5 实验与分析
本部分中,我们将对LibSeeker工具的参数自整定模块和第三方库检测模块进行实验并评估效果.实验环境为:具有40核心(Intel Xeon E7-4830,2.13Ghz),内核版本3.16.0,物理内存大小为128G的Linux服务器.服务器的操作系统为64位的CentOS 7,运行Java版本为1.8的64位HotSpot虚拟机(build 25.111-b14,mixed mode).
5.1 数据的收集
测试样本中的安卓应用主要来源于表2中四个应用市场上收集的APK.

表2 四个安卓应用市场收集的APKTable 2 APK collected from four markets
第三方库则是通过解析F-Droid上的开源应用配置文件中的GAV(groupName,artifactId和版本号),从Maven Central Repository上把对应groupName和artifactId下的所有第三方库版本用爬虫爬下来、保存在数据库中的.同样地,我们也从两个网站(Top 100 Android Libraries[注]https://github.com/Freelander/Android_Data/blob/master/Android-Librarys-Top-100.md和Awesome Android[注]https://snowdream.github.io/awesome-android/)上收集热门的第三方库.最终我们成功收集到了758种第三方库,共计11620个版本.
通过分析APK中的配置文件和第三方库使用时的配置设置,我们从样本中获取了23297个APK-第三方库匹配对作为正样本、23271个APK-第三方库匹配对作为负样本,组成了我们的测试集ground truth.将这四万多测试集均匀随机地划分为100个小测试集,作为之后进行参数自整定实验使用.随后,我们又根据安卓支持包与其他第三方库之间的依赖关系,扩展了7829个APK-第三方库匹配对作为正样本,再加上7446个新的负样本,组成新的样本集以供第三方库检测中的对比实验使用.
5.2 参数自整定模块的实验
本小节主要描述参数自整定实验的具体情况,主要有参数向量的设置、α值的确定以及实验结果的分析.我们将通过实验结果确定最优参数组合,同时计算出分界阈值LST.实验使用的样本集为5.1节中随机划分的100个测试集,共计46568个样本.
5.2.1 参数向量及α值的确定
我们分别以0.05、0.1和0.01的精度为PCT、CMT和MDT三个参数在0.4-0.6、0.5-0.9以及0.01-0.05之间设计参数组合.各参数在五水平上分配对应的值如表3所示.
根据正交表L25(56)设计参数向量,将正交表的前三列分别作为PCT、CMT和MDT对应的因素,生成(0.4,0.5,0.01)、(0.4,0.6,0.02)、……以及(0.6,0.9,0.04)共25个参数向量.
为了较好地平衡UCB算法中均值与测试次数标准差附加值对参数向量选择的影响力,我们分别以不同的α值进行了100次测试,统计参数向量的测试次数分布如表4所示.
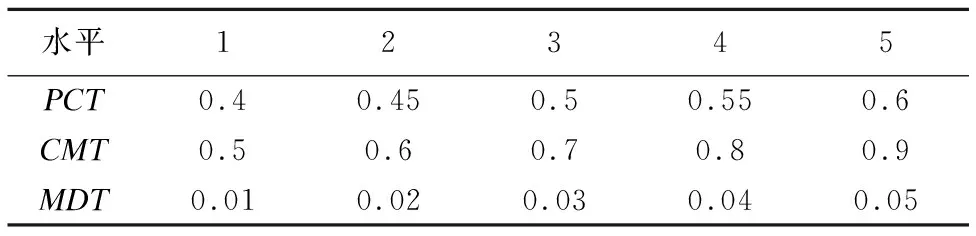
表3 各参数在五水平上的赋值Table 3 Values for each parameter on five levels
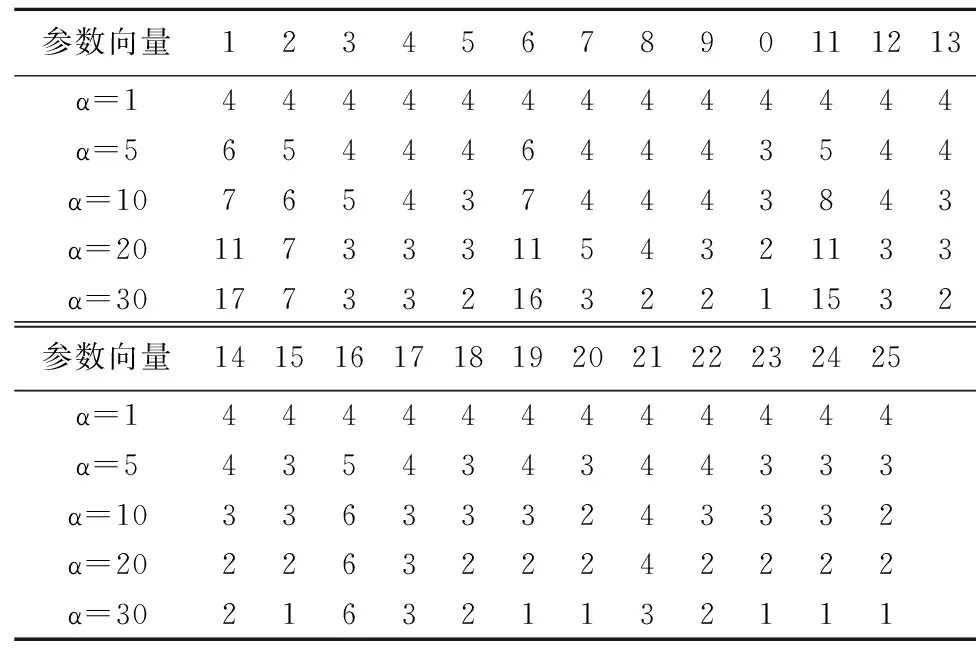
表4 参数向量测试次数分布表Table 4 Test number distribution of parameter vectors
α值为1时,AUC值对参数组合被测试次数的影响可以忽略,各参数组合都测试了4次;而当α值太大比如等于30时,AUC的影响太大以至于很多参数向量只得到1次被试机会,次数附加值起的作用很小,这种情况容易造成因为第一次测试偶然不好的结果导致之后再也没有测试机会,可能带来误差.因此,最终我们选定处于中间的α=10来进行之后的参数自整定测试.
5.2.2 参数自整定实验分析
我们以α=10对25个参数向量进行实验,以这25个参数向量经过UCB分配进行多次测试后得到的平均AUC值,作为每个参数向量的实验结果.我们对每个因素上各水平取值进行统计分析,结果如表5所示.
在这25个实际测试的参数组合中,有3个参数向量实验获得的平均AUC较高,分别是AUC为0.9962的(0.5,0.5,0.03)、AUC为0.9953的(0.4,0.5,0.01)和AUC为0.9952的(0.45,0.5,0.02).
统计分析这25个参数向量的水平数据,表5中I-V行是该参数在每个水平(即每种赋值)上的AUC数据和,K1-K5则是该参数各水平取值的AUC综合平均值,R为该参数下各水平AUC的极差.可以看出从水平1到5,PCT和CMT对AUC值的影响都是逐渐递减,而MDT则是有起伏波动,在水平4上达到最大值,因此我们推断最优的参数向量为水平(1,1,4)的组合,即在PCT=0.4、CMT=0.5和MDT=0.04时达到最好的识别第三方库效果.我们随机挑选3个测试集对该参数组合进行测试,得到平均AUC值为0.9967,确实优于测试的25个参数向量,因此我们最终选定该组合作为第三方库检测的阈值设置.
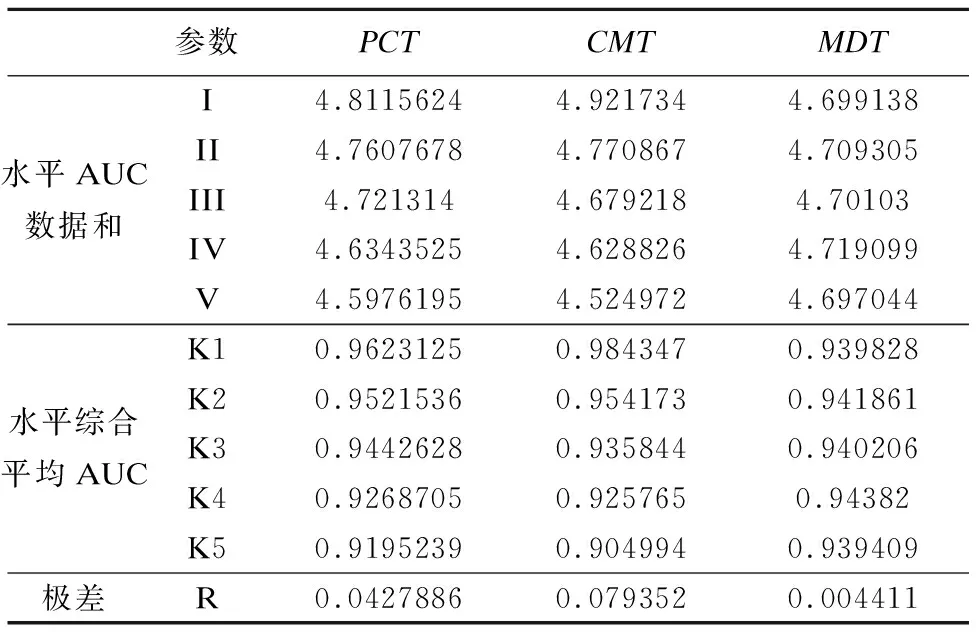
表5 参数自整定实验结果分析Table 5 Parameter auto-tuning results analysis
5.2.3 LST的确定
根据先前的实验,我们确定了PCT=0.4、CMT=0.5和MDT=0.04的阈值设定,在该参数组合下对所有46568个样本进行实验,最终得到第三方库检测的AUC值为0.9959,根据实验数据绘制出的ROC曲线是一条十分贴近x=0和y=1的曲线.遍历所有ROC绘制点,计算每个点TPR与FPR的差值,得到约登指数最大的点为坐标(0.01569,0.99632),此时约登指数等于0.98062,该点以LST= 0.4955作为临界值,统计可得在这部分样本集上的召回率(recall)为99.63%,准确率(precision)为98.46%.因此,将0.4955确定为之后第三方库检测实验中划分一个应用是否包含指定第三方库的临界值.
5.3 第三方库检测模块的实验
本小节主要描述关于LibSeeker检测第三方库效果的实验,同时我们也对LibSeeker与LibScout的效果进行比较.实验中使用与之前参数自整定实验不同的样本集,包括7829个支持包扩展的正样本和7446个负样本.
5.3.1 抗混淆性分析
我们对LibSeeker的抗混淆性进行分析,挑选正样本中LibSeeker检测结果是完全匹配的,即与第三方库相似度为1.0的APK-第三方库匹配对,共计12510对.对这些完全匹配对所包含的6148个APK进行类名分析,发现其中类名被混淆过的有3359个,约占59.64%.而LibSeeker成功检测出这些混淆过的APK中包含的第三方库,由此可见LibSeeker在一定程度上可以避免混淆的影响.
5.3.2 与LibScout之间的比较
LibSeeker基于LibScout中使用的代码无关函数哈希进行匹配,保留了应对混淆的能力,同时加入特征向量centroid降低误匹配的概率;LibScout中的参数阈值设定依赖于有限的实验和人工经验,而我们在LibSeeker中实现了对参数向量的自动整定功能,减少人为依赖因素.
我们分别对LibSeeker和LibScout检测第三方库的效果进行对比实验,其中针对LibSeeker还进行了使用参数自整定(PCT=0.4、CMT=0.5、MDT=0.04)和使用原始阈值(PCT=0.5、CMT=0.8、MDT=0.02)的对照实验.我们以LibScout中设定的第三方库相似度阈值0.6作为本实验中LibScout和使用原始阈值的LibSeeker这两组的LST临界值,而参数自整定的LibSeeker这组的LST值设置为5.2.3节中计算得到的0.4955.最终实验结果如表6所示.
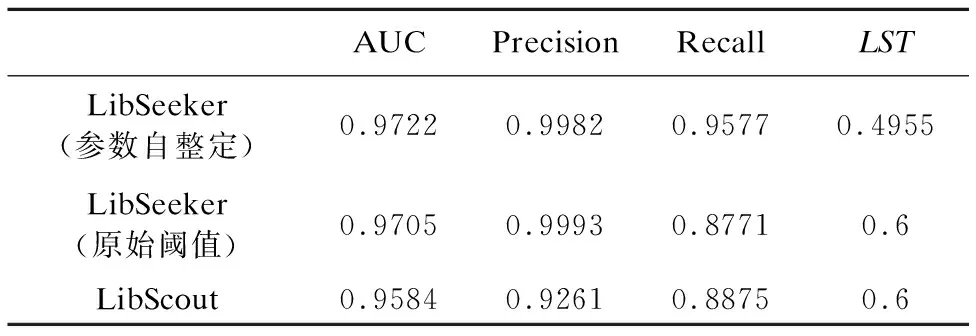
表6 LibSeeker与LibScout实验结果比较Table 6 Comparison of LibSeeker and LibScout
从实验结果可以看出,LibSeeker中加入的函数特征向量比较减少了函数签名冲突的影响,使得LibSeeker对第三方库检测的准确性优于LibScout.而参数自整定进一步优化了LibSeeker的效果,比起采用原始阈值的LibSeeker,在准确率变化不大的情况下,检测的召回率有了大幅度的提高.使用参数自整定的LibSeeker的准确率和召回率达到了99.82%和95.77%.
6 总 结
安卓应用广泛使用第三方库来构建功能,大部分现有的第三方库检测方法可靠性不够,对混淆技术抵抗程度较弱,实验中的阈值设定往往依赖于人工经验.本文设计并实现了能进行参数自整定的第三方库检测工具LibSeeker,通过采用LibScout中与代码无关的函数签名哈希,结合特征向量centroid,为第三方库和应用中的包进行匹配,并根据层级关系进行筛选,选取全局相似度最大的作为最终匹配结果,从而实现对第三方库精确可靠的识别.同时,LibSeeker还实现了对阈值的参数自整定功能,通过自整定实验挑选出最优的参数组合,进一步提高了第三方库检测的准确率与召回率.
