采用语义分析的标签体系构建方法
2019-02-14李娜范正洁郝传洲王平辉陶敬林杰
李娜,范正洁,郝传洲,王平辉,陶敬,林杰
(1.西安交通大学智能网络与网络安全教育部重点实验室,710049,西安;2.中国移动通信有限公司研究院大数据与IT技术研究所,100053,北京)
随着大数据技术的深入研究与应用,企业的专注点日益聚焦于怎样利用大数据来为精准营销服务,进而深入挖掘潜在的商业价值[1-4],于是用户画像的概念也就应运而生。所谓用户画像,即用户信息的标签化,利用标签体系勾画用户的属性特征[5]。精准、细粒度且结构化的标签体系是用户画像的基础,其广度和粒度对用户画像的精确性有较大影响,因此标签体系的构建具有一定的研究意义和应用价值。
早期比较流行的标签体系构建方法均基于Golder所提出的协同标签体系[6];Yeung和Tahar等利用分众分类法构建标签体系[7-8];Cai等先后提出利用协同标签系统不同标签权重的结构化和非结构化标签来构建标签体系[9-10]。协同标签体系描述众多用户以标签形式向共享内容添加元数据的过程,大多知名网站允许用户公开标签和共享内容,用户不仅可以为自己的信息分类,也可以浏览他人的分类信息,故协同标签体系的构建受到个人和公共两方面因素的影响。由于个人背景知识以及描述文字的习惯不同,不同用户对同一网页可能添加不同的标签,致使最终的标签体系存在重复和结构层次不明显的问题。随着本体的发展,利用本体构建标签体系的研究也逐渐增多,Skillen、Maleszka和Ferreira等利用现有本体框架人工或自动化地构建本体以生成标签体系[11-13],但目前基于本体所得到的标签体系准确度低,存在冗余或者缺失以及结构问题。此外,本体的构建需要大量人工参与,成本较高。Farseev等基于主题模型[14-15]构建标签体系,但这种标签体系粒度较粗,不利于精准画像。
针对上述问题,本文基于主流网站的导航标签,提出一种标签体系融合方法以构建细粒度结构化的标签体系。主流网站的导航标签是经过专家仔细分析,并结合广大网民的用户体验进行优化而得,故网站导航标签能够精准勾画用户的行为属性,进而为用户画像打下基础。
本文根据标签文本特征、结构特征以及标签对应的网页文本特征,提出一种基于语义特征分析的标签融合方法(TMSFA)。该方法通过识别标签间的等同和上下位这两种映射关系,对主流网站的导航标签进行融合,进而构建出精准、细粒度且结构化的标签体系。
1 标签体系构建方法
第一层级标签称作根标签,每个根标签及其所有子孙标签称作一个标签树。本文方法三阶段流程如图1所示,其基本思想是将标签树两两融合,将待融合标签树插入到基准标签树中,通过找到待融合标签与基准标签的等同映射关系和上下位映射关系,从而构建出融合后的标签体系。本文方法分为数据处理、标签映射以及标签融合3个阶段。
在数据处理阶段,首先从网站中获取原始标签体系,并基于爬虫获取标签对应的网页文本,以丰富标签语义;其次根据标签体系内容并结合分组条件对标签树进行聚类分组,分组条件一是当两个标签树的根标签相同分为一组,分组条件二是当标签树的根标签不同但子标签内容相似则分为一组;最后根据标签树的层数、叶子标签及非叶子标签的数量判断融合顺序,标签树层数越多则标签的划分结构粒度越细,叶子标签的数量越多则标签树描述的子领域越广,非叶子标签的数量越多则标签的划分粒度越细。
在标签映射和标签融合阶段,基于标签间的等同映射关系和上下位映射关系去除标签体系中重复以及结构相同的标签,然后将待融合标签树插入到基准标签树中,进而构建出融合后的标签体系。
2 等同关系标签映射
标签间的等同关系是指两个标签语义相同,对应的网页内容相似。在识别标签的等同关系时,主要存在以下两个难点:一是不同原始标签体系的标签词义表达方式不同,例如“钓鱼用品”“垂钓用品”和“彩宝”“彩色宝石”等;二是上级标签对下级标签的语义具有约束力,例如标签“洗发水”的上级标签有“洗发护发”“男士洗护”两种,此时标签的语义截然不同。
本文基于标签体系的语义和结构提出两种方法以解决上述难点,一是通过判断标签对应网页内容是否相似;二是同时分析标签及其上级标签的语义信息,基于这两种方法可得到众多等同关系标签对,本文取这些等同关系标签对的并集作为最终识别的等同关系标签对。
四级标签体系树状图如图2所示,其中一级标签指所有标签树的第1级根标签,如标签a1~a2;二级标签指所有标签树的第2层级标签,如标签b1~b4;三级标签指所有标签树的第3层级标签,如标签c1~c8;四级标签指所有标签树的第4层级标签,如标签d1~d4。
2.1 基于标签语义的等同关系映射方法
基于标签语义比较待融合标签与基准标签是否“相同”,若“相同”则将待融合标签和基准标签的父标签及祖父标签进行两两比较,存在一对“相同”则说明待融合标签与基准标签具有等同关系。
待融合标签A和基准标签B分别由n和m个字组成,表示为A1,A2,…,An和B1,B2,…,Bm,其中Ai(i=1,2,…,n)、Bj(j=1,2,…,m)分别表示组成标签A和B的字。逐个比较标签A和B的字,假设标签A和B中重复的字的个数为h,则标签A和B的相似度为h/n,若相似度大于基于统计分析设定的阈值,则说明这两个标签是“相同”的。
2.2 基于附加语义的等同关系映射方法
基于标签对应的网页文本内容的相似性来判断标签的等同关系。基于网页文本语义获得标签的向量表示,输入为每个标签对应的k个网页标题,通过句子向量表示模型(Sentence2Vec)[16]。获得每个标题的句子向量表示为s1,s2,…,sn,则标签表示为
(1)
待融合标签A与基准标签B的向量表示分别为SA和SB,其余弦相似度为
(2)
当余弦相似度大于基于统计分析设定的阈值时,说明待融合标签A与基准标签B具有等同关系。
3 上下位关系标签映射
上下位关系是指两个标签的语义之间存在包含与被包含的关系,下位词是上位词的一个特殊实例或者一个子类。如图3所示,待融合标签“鲜花饼”的上级标签为“休闲食品”,标签“鲜花饼”会跟随其上级标签“休闲食品”融合到“鲜花饼1”的位置,但是“饼干糕点”是“鲜花饼”更为准确的上位词,故标签“鲜花饼”应融合到“鲜花饼2”的位置。
基于标签对应的网页文本内容提出两种上下位标签映射方法:一是通过判断待融合标签对应的网页标题中包含基准标签的比例来判断上下位关系;二是通过判断待融合标签与基准标签的子标签的相关性来判断上下位关系。
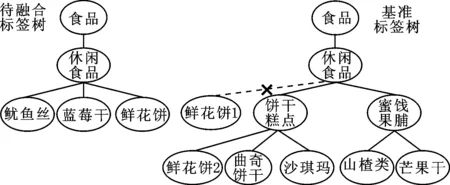
图3 基于上下位关系的标签融合示意图
3.1 基于网页标签包含关系的上下位标签映射方法
标签对应的网页标题通常会包含其上级标签,利用这个特点判断两个标签是否存在上下位关系。待融合标签A的对应的网页标题个数为p,若网页标题中有q个标题包含基准标签B,则包含比例为
(3)
当包含比例大于基于统计分析设定的阈值时,则说明待融合标签A与基准标签B具有上下位关系。
3.2 基于标签间相关性的上下位标签映射方法
如图2所示,“鲜花饼”与“饼干糕点”的子标签“曲奇饼干”和“沙琪玛”有一定的相关性,也就是子标签间存在着一定的相关性,据此判断两个标签是否存在上下位关系。计算待融合标签与所有包含子标签的基准标签的相关性,当最大相关性大于基于统计分析设定的阈值时,则说明待融合标签A与基准标签B具有上下位关系。基于子标签的向量表示分别计算标签A与标签B以及子标签的余弦相似度C(SA,SB),C(SA,SB1),…,C(SA,SBn),则标签A和B的相关性为
(4)
4 实验与分析
4.1 实验设置
目前用户访问的网站类型主要包括门户、金融、电商3类,故从这3类网站中分别选择两个主流网站导航作为原始标签体系进行融合,其中门户网站选择新浪网和搜狐网,金融网站选择中金在线和东方财富网,电商网站选择天猫和苏宁易购,详情见表1。

表1 三类网站标签体系中各级标签分布
为了测试融合方法得到的标签体系的准确性,本文提出标签重合度和上下位关系重合度两个指标来验证融合方法的效果。
所谓标签重合度指标,即通过计算融合后标签体系与测试标签体系的标签重合比例来说明两个标签体系的内容差异,它是一种标签内容相似的度量。融合标签体系和测试标签体系中标签的个数分别为NL、NT,相同的标签个数为Nsame,则标签重合度为
(5)
所谓上下位关系重合度指标,即通过计算融合后标签体系与测试标签体系的上下位关系相同比例来说明两个标签体系的结构差异,它是一种标签上下位关系的度量。融合标签体系和测试标签体系中树枝个数分别为ML、MT,测试标签体系中与融合标签体系中相同的树枝的个数为Msame,则上下位关系重合度为
(6)
测试标签体系是从上述原始标签体系中随机抽取若干个标签进行分组,在20多位老师和同学的帮助下人工融合标签并校正,得到最终的测试标签体系。
对于电商网站,本文将“家居家纺”“母婴玩具”和“个护化妆”3个分组的原始标签人工融合得到电商测试标签体系;对于金融网站,将“理财中心”和“股票中心”两个分组的原始标签人工融合得到金融测试标签体系;对于门户网站,将“频道”分组中的“新闻”“体育”“娱乐”“科技”“女人”“健康”“房产”“星座”和“旅游”这些小组的原始标签人工融合得到门户测试标签体系。三类网站标签体系中原始及测试标签数的统计情况见表2,以电商为例,电商网站原始标签体系共有6 039个标签,抽取其中1 265个标签进行融合,得到的测试标签体系共有934个标签。

表2 三类网站标签体系中原始及测试标签数
4.2 实验结果
为了进一步说明本文方法的优越性,采用基于同义词林的融合方法(TMC)与之进行对比。TMC方法基于同义词林和标签文本层面的相似性来判断标签映射关系,进而融合标签体系。
在同一台计算机上使用相同数据对本文方法和TMC方法进行对比,首先基于这两种方法分别将门户、金融、电商网站的原始标签体系进行融合,然后将融合后的标签体系分别与测试标签体系进行比对,最后计算出标签重合度和上下位关系重合度,对比结果及时间频度见表3、表4。

表3 本文和TMC方法在评价指标上的比较

表4 本文与TMC方法的时间频度对比
针对电商类网站,基于本文方法融合天猫和苏宁的标签体系得到1 041个标签,并与测试标签体系进行对比,标签重合度和上下位关系重合度分别为89.4%、88.4%,而TMC方法的结果是79.8%和80.9%。电商类网站的标签体系结构复杂,经常会出现待融合标签所在的结构粒度粗而相应所属基准标签粒度细的情况,这就需要拆分待融合标签子树并将其映射到基准标签体系中,但难点在于如何判断待融合标签与基准标签的映射关系,故造成上下位关系重合度相对标签重合度较低。针对金融类网站,基于本文方法将东方财富和中金在线的标签体系进行融合得到504个标签,并与测试标签树进行对比,标签重合度和上下位关系重合度分别为85.5%,90.2%,而TMC方法的结果是76.7%和88.4%。针对门户类网站,基于本文方法将新浪和搜狐的标签体系进行融合,得到232个标签,并与测试标签体系进行对比,标签重合度和上下位关系重合度分别为90.0%、95.3%,而TMC方法的结果是80.1%和90.3%。由于词语描述差异比较大,门户类网站和金融类网站难以精准判断标签之间是否存在等同关系,故上下位关系重合度相比于标签重合度较高。
在时间复杂度方面,本文方法和TMC方法的时间复杂度均为O(n2)。从表4可以看出,两种方法的时间频度相差无几,但从表3可以看出,与TMC方法相比,本文方法的效果有较大的提升,并且本文方法得到的融合后标签体系相对于TMC方法的标签体系的标签数量较少,说明识别的融合标签对数更多。无论从等同关系识别还是上下位关系识别,本文方法都有一定的提升且具备一定的准确性,而且相对已有构建标签体系方法得到的标签体系而言更为全面、结构化。
5 结 论
本文方法将不同网站的导航标签体系进行融合得到统一且结构化的标签体系,为精准用户画像打下基础。本文方法基于标签间的等同关系和上下位关系来判断标签的融合位置,由于标签本身词语短小且包含的语义信息较少,本文不仅分析标签本身的语义信息,还结合其对应网页文本的语义信息及标签上下级结构关系信息以丰富标签语义,进而判断标签间的映射关系。本文提出标签重合度和上下位关系重合度两个指标以评估本文方法的优越性,与现有方法相比,本文方法的这两个指标至少提升5%,证明了方法的有效性。采用本文方法可以构建出精准有效且适应不同领域的标签体系。
