基于混合采样的非平衡数据分类算法*
2019-02-13吴艺凡梁吉业王俊红
吴艺凡,梁吉业+,王俊红
1.山西大学 计算机与信息技术学院,太原 030006
2.山西大学 计算智能与中文信息处理教育部重点实验室,太原 030006
1 引言
大数据时代的到来使得基于数据的知识获取成为可能,促进了数据密集型科学的发展。分类是机器学习和数据挖掘中重要的信息获取手段之一,但传统的分类算法没有考虑数据的平衡性,在非平衡分类问题上仍面临着巨大挑战。例如在医疗诊断[1]、网络入侵检测[2]等问题中,关注的事件在所有数据记录中占比都极小,但是将其错误分类却会带来无法估量的代价。将数量占多数的类称为多数类,占少数的类称为少数类,在非平衡数据中对少数类的正确分类往往比多数类更有价值。例如在癌症检测领域中,健康人的数量远大于患病人的数量,但更注重对真正患病人的识别率。因此如何对非平衡数据集进行正确分类,提高少数类的分类精度成为分类问题中的一个难点[3]。并且多类问题通常可以简化为两类问题来解决,因此非平衡数据集分类问题的研究重点也就转化为提高两类问题中的少数类的分类性能[4]。
目前,国内外学者对非平衡数据分类问题的常用策略大致分为算法层面的方法和数据层面的方法。算法层面主要有代价敏感学习[5]、集成学习[6-7]、特征选择[8]、单类别学习[9]等方法。数据层面最常用的方法是数据采样技术,主要包括三种:过采样、欠采样和混合采样。本文重点关注数据层面的研究进展。
过采样中比较经典的算法是Chawla等人[10]提出的 SMOTE(synthetic minority over-sampling technique)算法,其基本思想是:距离较近的少数类之间的样本仍然是少数类,在距离较近的两个少数类样本之间通过线性插值的方式产生一个新的少数类样本,使得少数类样本增加,达到平衡数据集的目的。实验结果表明SMOTE算法显著提高了少数类的分类精度,但是SMOTE算法是对所有少数类样本盲目地进行过采样,容易生成很多不重要的少数类样本。Han等人提出的Borderline-SMOTE[11]算法,认为处在边界上的少数类更容易被错分,对分类器的性能起到更重要的作用,因此对样本周围多数类较多的少数类样本用SMOTE过采样。
欠采样中较为简单的方法是随机欠采样,指随机删掉一些多数类样本以平衡数据集,该方法操作简单,但容易删去一些有用的多数类样本造成信息丢失。Tomeklinks[12]方法认为能构成Tomeklinks对的样本中,某个样本可能为噪声样本或在两类样本的边界上,将其中的多数类样本删去,从而达到欠采样的目的。
使用单一的采样算法如只使用过采样容易造成分类器过拟合,只使用欠采样容易导致样本信息丢失。混合采样同时采用过采样和欠采样技术,在解决上述问题的同时提高了少数类的分类精度。传统的混合采样中表现较为出色的有SMOTE+Tomek links方法[13],在使用SMOTE对少数类样本上采样的同时,删除多数类样本中的Tomek links对,还有SMOTE+ENN(edit nearest neighbor)方法等。这些方法都是基于样本之间的距离的,Song等人[14]提出基于聚类的混合采样算法(bi-directional sampling based onK-means,BDSK),该算法将SMOTE过采样算法与基于K-means的欠采样算法相结合,在增加少数类样本的同时有效地删去噪声样本。上述混合采样的方法都是基于距离或者聚类的,没有考虑到决策边界对样本的影响。Veropoulos等人提出了代价敏感训练算法[15],通过赋予错分的正负类样本不同的惩罚系数来降低分类超平面的偏移度,此方法简单易行并且具有一定效果。然而,当少数类样本过分稀疏时,采用此方法会因分类超平面过分拟合少数类样本而影响分类效果。Jian等人[16]提出的基于不同贡献度的采样算法(different contribution sampling,DCS),认为支持向量是更靠近决策边界的样本,贡献度更高,因此针对支持向量和非支持向量采用混合采样方法,即使用SMOTE和随机欠采样技术来分别对少数类样本中的支持向量和多数类样本中的非支持向量进行重新采样。该方法虽然考虑到决策边界的影响,但没有考虑到被错分的少数类样本更靠近真实类边界,对分类器的性能起到重要作用,并且对多数类样本进行随机欠采样有可能会删去一些重要的样本。
为了克服采样算法的盲目性以及支持向量机算法(support vector machine,SVM)在处理非平衡数据时分类超平面容易偏向少数类样本的问题,本文提出了一种基于SVM分类超平面的混合采样算法(hybrid sampling algorithm based on SVM,SVM_HS),旨在利用SVM分类超平面找出较为重要的少数类样本和不重要的多数类样本,对这些样本进行过采样和欠采样,达到平衡数据集的目的。在UCI数据集上进行实验并与其他重采样算法进行比较,实验结果显示SVM_HS算法的F-value和G-mean值均有较大提高,在处理非平衡数据分类问题上具有一定优势。
2 相关工作
本文算法是基于SVM分类超平面的混合采样算法,因此首先将从SVM算法思想和超平面偏移问题以及混合采样中用到的采样算法两方面进行介绍。
2.1 SVM算法
20世纪90年代Vapnik提出了SVM支持向量机算法[17],以结构风险最小化为原则,同时考虑到置信范围和经验风险,克服了分类器过学习、高维数、非线性和局部极值点等一系列问题。目前在机器学习领域中成为一个新的研究热点。
SVM的基本原理是寻找一个最优分类超平面,使得该超平面在保证分类精度的同时能够使超平面两侧的空白区域最大化。设训练样本集为T={(xi,yi),i=1,2,…,l},xi∈Rm,yi∈{-1,1},超平面记作ωT∗φ(x)+b=0,求解最优分类超平面可转化为二次优化问题:

约束条件为:
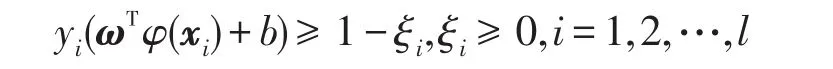
其中,ξi为松弛因子,C>0为误分样本的惩罚系数。用Lagrange乘子法可获得式(2)的对偶问题:
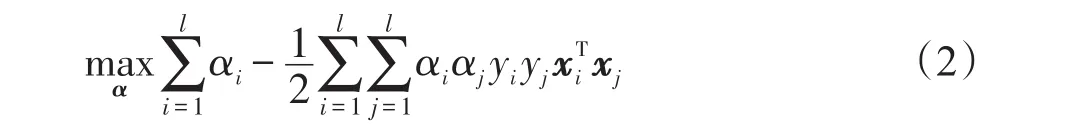
约束条件为:

其中,αi为Lagrange乘子。设k(xi,xj)为核函数,它对应非线性映射φ。那么SVM训练出来的分类判别式为:

但在利用SVM算法进行分类时,是建立在正负类数据样本数量大致持平的情况下,当样本数量不平衡时,分类超平面会偏向少数类。下面分别通过两组实验数据进行分析验证,两组数据样本正负比分别为1∶1和1∶10,其他参数包括高斯核宽度为10,惩罚系数C为100,实验结果分别如图1和图2所示。
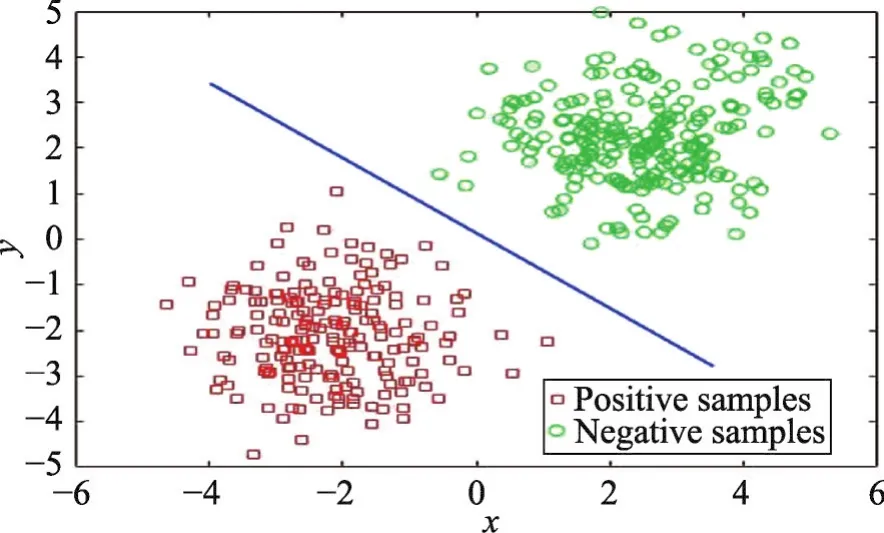
Fig.1 Hyperplane of balanced dataset图1 平衡数据集的分类超平面
可以发现,当数据平衡时,SVM分类超平面完美地位于正负样本中间,当正负样本出现严重失衡时,分类器的分类性能就会下降,为了使超平面两侧的空白区域最大化且获得较高的分类精度,分类超平面会偏向少数类。因此为了使超平面向真实类边界靠近,需要改变非平衡数据集的分布情况。

Fig.2 Hyperplane of unbalanced dataset图2 非平衡数据集的分类超平面
2.2 SMOTE算法
SMOTE算法基本思想是:在距离较近的两个少数类样本之间通过线性插值的方式产生一个新的少数类样本,使得少数类样本增加,达到平衡数据集的目的。整体算法如算法1所示。
算法1SMOTE算法

3 基于混合采样的非平衡数据分类算法
从相关研究中可以知道[15-17],传统的SVM算法对非平衡数据集进行分类时,训练所得的分类超平面会偏向少数类,被错分的少数类比分对的更靠近真实类边界,对分类器的性能起到更重要的作用,因此对这些样本进行过采样;而对于多数类来说,离分类超平面越远,则对分类性能的影响越小,因此对离超平面较远的多数类样本进行欠采样,进而使SVM分类超平面向着真实类边界方向偏移。
3.1 SVM_HS算法基本思想
给定一个样本集,使用该集合训练出一个SVM分类器,被错误分类的少数类样本更为重要,是要进行过采样的集合对象;离分类超平面较远的多数类样本相较于离超平面近的多数类样本更为不重要,是要进行欠采样的集合对象。
设初始训练样本集合为T,T=P⋃Q,其中P表示少数类样本集合,Q表示多数类样本集合。利用SVM对集合T进行训练得到分类器为:
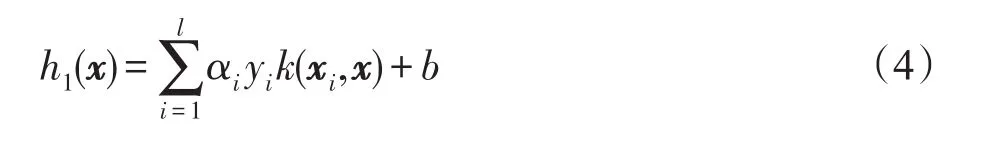
分类超平面为:

利用分类超平面可将少数类集合分为分对的集合P1和分错的集合P2。P2即为要进行过采样的对象,即:

对于集合Q,根据公式:

计算出所有多数类样本点到超平面的距离r,然后根据采样率得到较远的多数类样本即为集合Q′。
在算法中,找到集合P2和集合Q′后,直接删掉集合Q′,然后对集合P2使用SMOTE算法迭代进行合成,将每次合成的新样本加入到训练集中,在每次迭代后测试分类器的分类性能并使用G-mean值进行比较,当G-mean开始减小时,迭代结束,即得到优化后的分类器。根据算法思想可以看出,训练集将逐渐趋于平衡,使得SVM分类超平面慢慢向真实类边界方向偏移直至最靠近真实类边界。
3.2 迭代停止准则
将一个原始数据集分为训练集和测试集,测试集不进行任何操作,设训练集为T,集合T将训练SVM分类器并对T进行混合采样,重复此步骤。假设第t次迭代后得到的训练集合为X,使用集合X训练出新的分类器h(x)后,再使用集合X测试分类器h(x),并使用非平衡问题中常用的评价标准几何平均正确率G-mean值评价分类器的性能,若G-mean值逐渐增加,则说明所训练出的分类器性能变好,迭代继续;若G-mean值减小,则结束迭代,选择当前训练出的分类器作为最优分类器。
3.3 SVM_HS算法描述
SVM_HS的整体算法如算法2所示。
算法2SVM_HS算法

4 实验过程及结果分析
4.1 评价标准
对于分类问题,一般使用分类精度作为标准来评价一个分类器的性能。但对于非平衡数据来说,由于传统的分类算法更倾向于多数类样本,仅仅使用准确率评价非平衡数据分类算法是不合适的,反映不出对少数类样本的分类性能。因此,非平衡数据的评价标准也是数据挖掘领域中一项重要的研究内容。目前常用的评价标准主要有F-value、G-mean等。
在二分类问题中,常用的混淆矩阵[18-19]如表1所示。其中,TP表示少数类样本被正确分类的数量,FN表示少数类样本被错误分类的数量,TN表示多数类样本被正确分类的数量,FP表示多数类样本被错误分类的数量[20]。

Table 1 Confusion matrix of 2-class problem表1 二分类问题中的混淆矩阵
由此可以得到:
(1)分类准确率
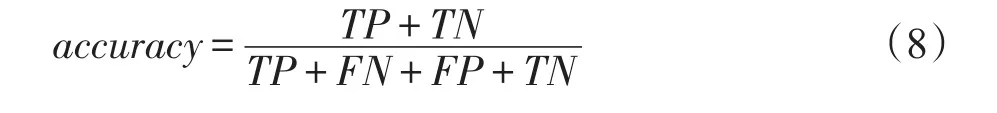
(2)查准率

(3)查全率

(4)少数类的F-value[21]
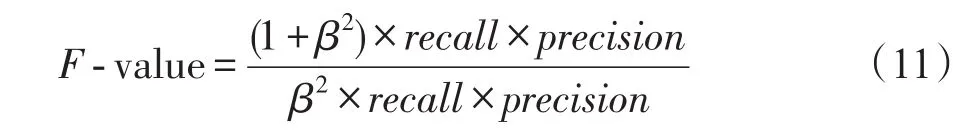
式中,β是调整查准率和查全率所占比重的参数,通常取β=1。
(5)几何平均正确率G-mean[22]

本文选用accuracy、F-value、G-mean作为评价算法性能的标准。
4.2 数据集描述
为了评价本文提出的SVM_HS算法的有效性并与同类方法进行对比,选用标准数据库UCI中的8组非平衡数据集进行实验和分析,选择了不同平衡程度、不同样本数量、不同领域的数据集进行实验,使得数据集更具代表性。由于UCI中二类不平衡数据集较少,这里可以将部分数据集中的某些类别合并,形成二类不平衡数据集,例如,Segment数据集包含2 310个样本,共有7个类别,可以将其中的第五类“window”作为少数类,而其余的所有类别进行合并形成多数类,这样就可以形成一个二类的不平衡数据集。通过此方式,对UCI中的部分其他数据集也进行类似的修改,从而形成了需要的数据集。修改后的数据集详细信息描述如表2所示。
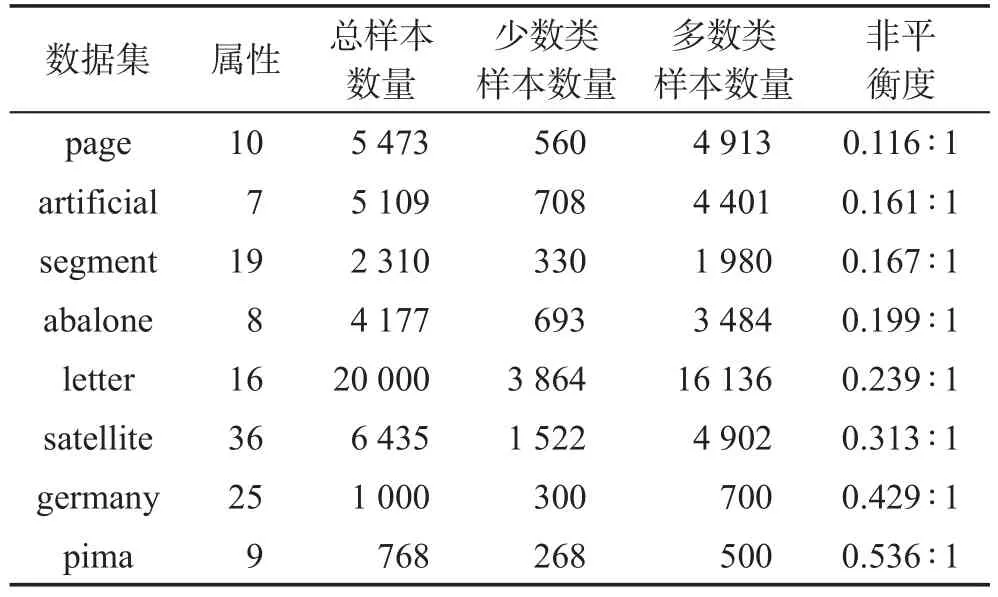
Table 2 Experimental datasets description表2 实验数据集描述
4.3 实验设计与结果分析
本实验采用十折交叉验证方法,使用Matlab作为仿真环境并将LIBSVM工具箱作为实现工具。
在SVM_HS算法中,需要输入训练样本集合T和每次迭代的采样率δ,即少数类增加的百分比和多数类减少的百分比。由于需要迭代使得分类超平面逐渐趋于真实类边界,因此每次采样的样本个数不宜太多,但为了排除人工的方法,为实验设置恰当的采样率,本文选取了几个采样率的值即10%、20%、30%、40%进行了实验,使用3个数据集进行测试,并利用非平衡分类问题中的一般性评价标准F-value、G-mean进行评估。如表3和表4所示,可以看出,当采样率为20%时F-value和G-mean的值普遍较高,因此本文将选取20%作为每次迭代实验中的采样率。
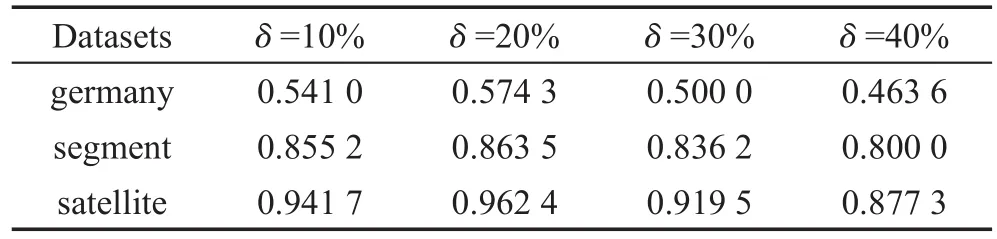
Table 3 F-value at different sampling rates表3 不同采样率下的F-value

Table 4 G-mean at different sampling rates表4 不同采样率下的G-mean
采样率确定后,将本文算法SVM_HS与SVM算法、SMOTE+SVM算法和Borderline_SMOTE+SVM算法进行比较,并对accuracy、F-value、G-mean等评价指标进行分析。算法参数设置如下:支持向量机分类器选择高斯核函数,核宽度为10,惩罚因子C为1 000,算法中SMOTE最近邻参数k选取为6,采样率为20%。实验结果如表5所示。
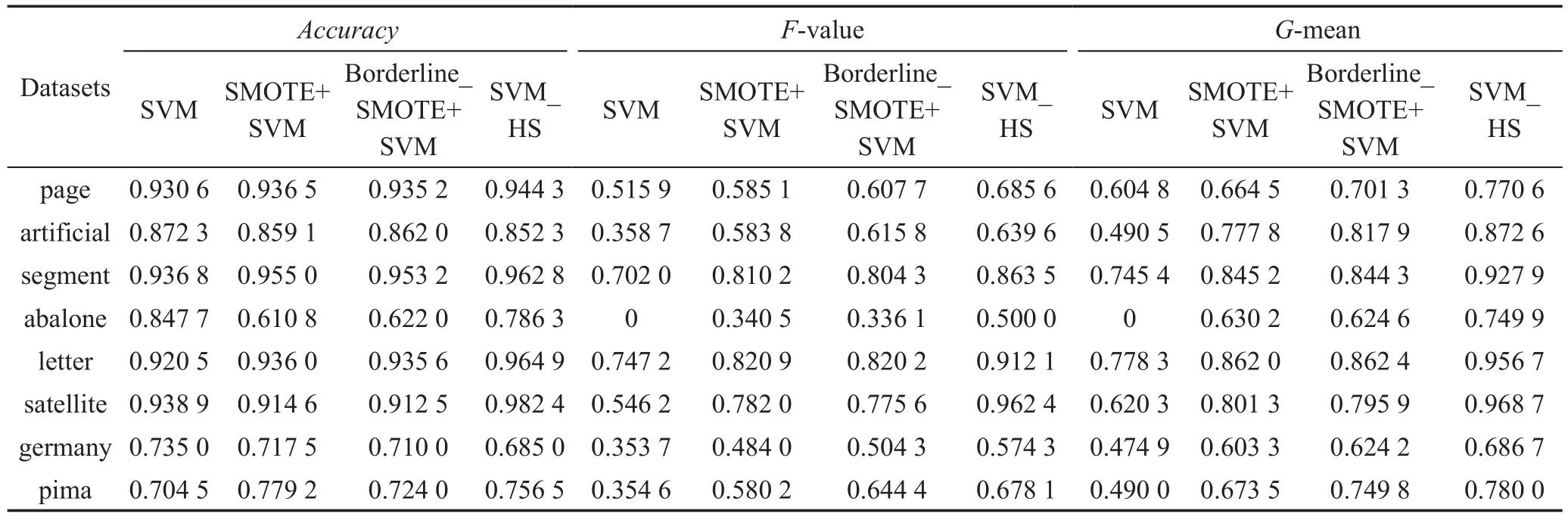
Table 5 Accuracy,F-value,G-mean表5 分类准确率、F-value、G-mean
在表5中,相比较传统的SVM算法,本文算法的准确率在多数数据集上只有小幅度的提高,且在个别数据集上有所降低。这说明在提高少数类的分类准确率的同时多数类的分类准确率可能会减小,但与两种改进的算法相比,本文的准确率都有明显提高。相比于准确率,F-value和G-mean更能作为非平衡数据整体分类性能的评价指标,往往能够指示一个方法在非平衡数据集的分类性能好坏。表5显示出,SVM_HS算法明显优于SMOTE+SVM算法和Borderline_SMOTE+SVM算法,在数据集上得到了较好的实验结果,有效提高了少数类和多数类的分类精度,说明本文算法有一定的优势和可行性。
为了对比算法的优势,图3~图5分别绘制了4种算法在8个数据集上的测试结果趋势曲线。其中,横坐标为4种算法策略,纵坐标为实验取值范围。通过这3个图可以看出,使用SVM_HS方法进行混合采样,少数类的分类性能有所上升。
实验结果表明本文算法在少数类的数量有明显劣势的情况下,分类效果有较大的提高,能够显著提高少数类的分类精度,并具有良好的适应性。
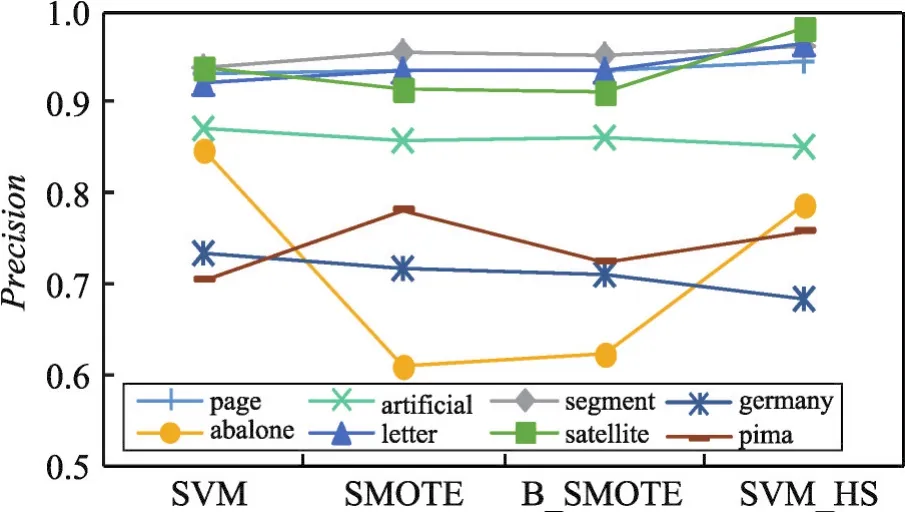
Fig.3 Variation curve of precision图3 准确率变化曲线图
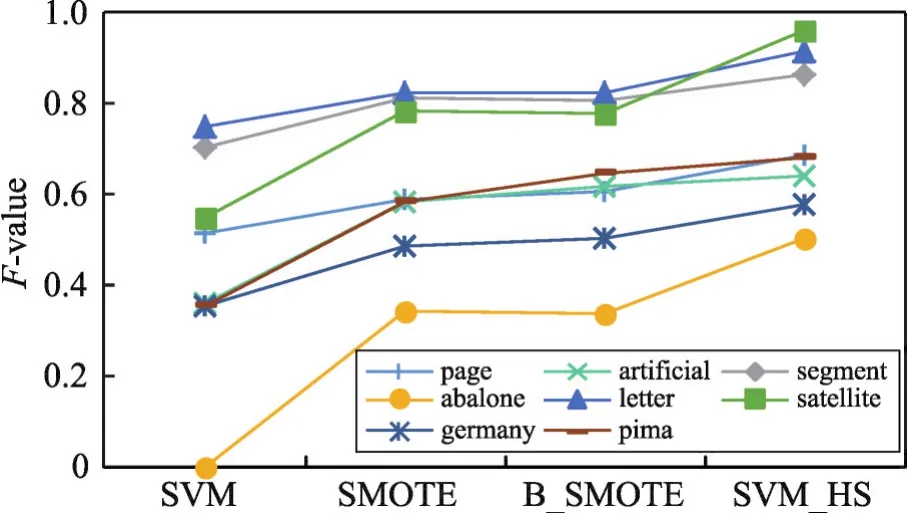
Fig.4 Variation curve of F-value图4 F-value变化曲线图
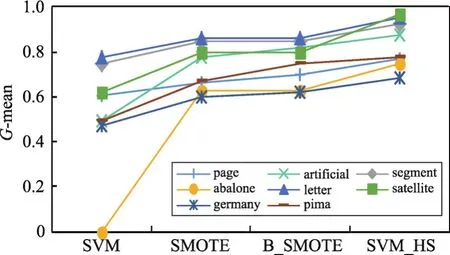
Fig.5 Variation curve of G-mean图5 G-mean变化曲线图
5 结束语
本文针对SVM算法在处理非平衡数据时分类超平面容易偏向少数类样本的问题进行研究。首先利用SVM算法得到分类超平面;然后迭代进行混合采样,主要包括删除离分类超平面较远的多数类样本和对靠近真实类边界的少数类样本用SMOTE算法过采样两部分;使分类超平面逐渐靠近真实类边界。本文算法通过在数据层面的改进,少数类的分类精度得到显著提高。然而,本文仅在数据层面进行了改进,如何在算法层面进行改进,将是未来重点研究方向。
