梯度约束SLIC的快速视频目标提取方法*
2019-02-13桂彦,汤问,曾光
桂 彦,汤 问,曾 光
1.长沙理工大学 计算机与通信工程学院,长沙 410114
2.长沙理工大学 综合交通运输大数据智能处理湖南省重点实验室,长沙 410114
1 引言
视频目标提取是将视频中用户感兴趣的物体(即视频目标)从视频的其他部分(即背景)中分离开,已提取的视频目标可应用于影视后期制作、运动识别、三维建模、虚拟现实和语义分割等领域。交互式的有监督视频目标提取是目前用于解决该类问题的主要方法,可分为基于传播框架的视频目标提取[1-4]和基于图切割的视频目标提取[5-10]两大类。现有基于图切割的视频目标提取方法允许用户交互修正提取结果,可操作性强,且在时间效率和提取精度上是令人满意的。因此,本文侧重于研究基于图切割的视频目标提取方法。
由于视频具有数据量大的特点,直接基于像素级构建的三维无向图的结点和边的数量都异常巨大,这将导致视频目标提取的效率大大降低。为提高效率,现有方法通常采用分水岭算法[11]、均值位移算法[12]、超像素分割方法[13]等对视频帧进行预处理,并将视频目标提取建立在视频帧的过分割(oversegmentation)结果基础上,这有效地减少了计算代价。然而,在处理复杂自然视频时,如视频中包含颜色相近似的视频目标和背景区域、视频目标边界模糊、光照变化和阴影等。上述预处理方法的效果并不理想,这容易产生错误的视频目标提取结果。另一方面,基于图切割的视频目标提取方法通常采用光流法[14]估计视频目标的运动。然而,若视频片段中存在多光源、噪声干扰、视频目标剧烈运动等情况,现有光流算法[14]难以准确地跟踪视频目标,这会破坏视频目标在视频帧间的时空一致性,从而导致视频目标提取结果中出现部分残缺等瑕疵。因此,如何确保视频目标提取结果的时空一致性是亟待解决的关键问题。
本文提出了一种基于梯度约束SLIC的快速视频目标提取方法。首先,通过利用梯度约束SLIC算法对所有视频帧进行预处理;然后,在视频预处理结果上构建三维无向图,并进一步优化图割模型,以最终实现快速且高质量的视频目标提取。本文方法在segtrack数据集、youtube-objects数据集上进行了相关实验,并对比了经典的视频目标提取方法。实验结果表明,本文方法通过利用改进的超像素分割方法,改善了视频预处理效果的同时有助于进一步加快视频目标提取方法的运算效率。本文方法通过引入保持视频目标时空一致性的高阶项,从而极大地改善了视频目标提取的质量。
2 相关工作
视频目标提取一直是计算机视觉领域的一个研究热点及难点问题。Bai等人[1]提出了一种基于测地线框架的视频目标提取方法,用以有效避免运动背景的干扰。为改善提取质量,Bai等人[2]提出了一种基于局部分类器的视频目标提取方法,该方法通过在第一视频帧的视频目标边界上设置一系列重叠的局部分类器,用以向后续视频帧传递视频目标的边界信息。Zhong等人[3]对定向局部分类器进行改进,解决了视频目标因运动剧烈造成的时空不连续性问题。考虑到视频目标和背景通常具有不同的运动特征,Fan等人[4]提出了一种基于掩膜图传播以及双向运动插值的视频目标提取方法。该方法通过分别对齐视频目标和背景,并使用两个分离的最近邻域(split nearest-neighbor fields)分别跟踪视频目标和背景区域。上述这些基于传播框架的视频目标提取方法在提取视频目标时,通常需要借助局部分类器跟踪局部视频目标区域,因而,用户需要消耗大量时间进行局部分类器的部署以及各分类器的训练。为获得理想的视频目标提取结果,用户需要对第一视频帧的前景目标进行精确提取,以及用户需要对错误的视频目标提取结果不断进行交互修正。因此,相对于基于框架传播的视频目标提取方法,快速提取高质量的视频目标更适合采用基于图切割的视频目标提取方法进行解决。
在对基于图切割的视频目标提取方法的研究中,Li等人[5]提出了一种基于三维图切割(3D graph cut)的视频目标提取方法。该方法采用分水岭方法[11]对视频进行预分割;通过增加跨时空域的基于颜色特征度量的能量项,可在连续的关键帧对中运用三维图切割方法进行视频目标提取。Wang等人[6]提出了一套交互式视频目标提取系统。首先,该方法通过采用均值位移(mean-shift)算法[12]对视频进行层次化分解;然后,在现有的图割模型中引入了新的局部能量项,这有助于从背景中分离视频目标。然而,该方法不能很好地处理视频目标遮挡的情况。Huang等人[7]提出了一种新的基于超图(hypergraph)的视频目标提取方法。该方法将视频目标提取问题转化为关于超图内所有超边的标签分配问题。此外,该方法需要采用基于光谱的多尺度图像分割方法[15]对所有视频帧进行预处理。Tong等人[8]提出了一种渐进式视频目标提取方法,该方法根据用户的交互不断将交互结果传递至后续视频帧,以及该方法通过采用三维多层窄带图割策略加快了视频目标提取的效率。Zhang等人[9]提出了一种基于跨时空域的视频目标提取方法,这使得该方法在少量用户交互输入下适用于同时提取视频中多个重复场景目标。为提高运算效率,上述这些方法分别采用分水岭算法、均值位移算法等预处理视频数据。然而,由分水岭算法得到的结果存在严重的过分割现象,且运算效率较低;而使用均值位移算法生成的子块区域非常不规则,这些都会影响后续视频目标提取方法的质量和效率。
Ren等人[13]首次提出了超像素分割方法。使用超像素分割方法生成的超像素在良好保持图像局部特征的同时,还能够有效地表达目标区域的边界信息。因此,相较于分水岭、均值位移等图像过分割算法,超像素分割方法更适用于视频数据的预处理。而在视频目标提取方法中,如果使用超像素替代像素点构建三维无向图,则图中的结点和边的数量都会明显减少,这有助于提高后续视频目标提取的效率。其中,为增强不同视频帧间视频目标区域的连通关系,Grundmann等人[16]提出了一种层次化的视频目标提取方法,该方法根据视频预处理结果生产的子块区域构建不同阶层的区域图,从而可采用基于最小生成树的方法进行视频目标提取。此外,该方法利用光流法估计视频目标在下一视频帧的大致位置,以此作为视频目标的位置先验信息,并用于后续的视频目标提取。Papazoglou等人[17]提出了一种快速且全自动的视频目标提取方法。该方法利用Turbopixel算法[18]对视频片段进行预处理,且利用光流算法对视频目标在视频中的位置进行粗略估计,由此,该方法可借助动态更新的外观模型与位置先验修正粗略的视频提取结果。Jain等人[19]提出了一种基于超体素的半监督视频目标提取方法。该方法首先将连续视频帧内的超像素聚合成三维超体素,然后通过同时度量超体素内超像素之间的外观相似性和运动相似性以建立连通关系,这能够准确地将视频目标的边界信息传递给后续视频帧。Giordano等人[20]提出的视频目标提取方法适用于提取具有复杂场景的视频片段中的一个或多个视频目标。该方法采用SLIC算法[21]对视频片段进行预处理,且利用基于外观和视觉组织的先验信息优化能量函数,从而通过最小化能量函数实现视频目标提取。Tsai等人[22]提出了一种同时估计光流和分割视频目标的方法,在预处理视频帧基础上,该方法迭代地优化估计的光流并以此更新视频目标分割结果。
虽然上述基于超像素级的视频目标提取方法均借助了超像素分割方法提高运算效率,但超像素分割方法的分割质量与运算效率相互制约,而这会直接影响视频目标提取方法的提取质量与运算效率。现有光流算法不能鲁棒地估计复杂自然视频中目标的运动信息,而错误的视频目标运动信息会导致视频目标提取结果的时空不一致性。针对以上问题,本文采用改进后的SLIC超像素分割方法对所有视频帧进行预处理,且通过结合外观特征与运动特征构建鲁棒的相似外观度量机制,同时引入基于超像素的高阶项,以获得理想的视频目标提取结果。
3 基于梯度约束SLIC快速视频目标提取
3.1 算法概述
本文提出的基于梯度约束SLIC的视频目标提取方法的总体框架如图1所示,主要包括视频预处理、三维无向图的构建和视频目标提取三个阶段。在视频预处理阶段中,在所选视频关键帧上分别标记视频目标和背景区域;同时,通过使用梯度约束SLIC算法对所有视频帧进行预处理,此时,每一视频帧的过分割结果中超像素数量是相同的。在三维无向图的构建阶段中,主要是以视频片段中的所有超像素作为三维无向图的结点,以及超像素之间的空间和时间邻接关系就是三维无向图中连接结点对之间的边。而在视频目标提取阶段中,本文根据构建的三维无向图进一步改进基于马尔科夫随机场的能量函数[23],其关键在于结合外观特征和运动特征重定义能量函数中的平滑项,以进行更准确的外观相似性度量;并在此基础上引入高阶项以保持视频目标提取结果的时空一致性。最后,本文方法采用最大流/最小割算法最小化能量函数,通过获得全局最优解以实现快速且高质量的视频目标提取。
3.2 基于梯度约束SLIC的视频预处理
由于采用原SLIC算法[21]预处理视频帧时较大程度上受紧密度值的影响,为获取理想的视频预处理结果,用户则需要逐视频帧设置合适的紧密度值,这增加了视频预处理的时间消耗。本文通过在原SLIC算法中引入梯度约束项以进一步优化像素聚类过程,即根据局部区域的颜色特征和梯度,对相应超像素的边缘进行修正,使其更贴近实际轮廓。采用本文改进的超像素分割方法对视频帧进行预处理的步骤如下:
步骤1初始化聚类中心。在每一视频帧上(图2(a)),以为步长栅格化视频帧且初始化K个聚类中心φj={φ1,φ2,…,φK}(图2(b)),每个聚类中心拥有唯一的标签。其中,N为视频帧的总像素数目;K为用户指定的超像素数目。
步骤2重置聚类中心。对于每一聚类中心φj,在其3×3的邻域内将其重置为φj′,该重置聚类中心为该邻域内具有最小梯度的像素点的坐标位置(图2(c))。

Fig.1 Algorithm flow chart for gradient-constrained SLIC based video object segmentation图1 基于梯度约束的SLIC视频目标提取算法流程图
步骤3像素聚类。对于视频帧上每一个像素点i,通过为像素点i赋予与其特征距离D(i,j)最近的重置聚类中心φj′的标签,从而实现像素聚类。为得到更加精确的像素聚类结果,本文在原特征距离的定义中引入了梯度约束项dt,这有助于根据梯度修正超像素的边缘和形状,从而提高超像素分割的精确度。基于梯度约束项的特征距离定义如下:


Fig.2 Video frame preprocessing图2 视频帧预处理

其中,dg(i,j)=∇i⋅cosθ为超像素边缘上的所有像素点的约束力,其中∇i为像素点i的梯度;θ为像素点i的梯度方向与其至重置聚类中心φj′方向的夹角;E(i)=dse-∇i/α用于调整像素点i到聚类中心φj′的特征距离,以控制生成的超像素的形状:若像素点i到聚类中心φj′的欧氏距离ds越小,则E(i)取值偏小,算法倾向于为像素点i分配重置聚类中心φj′的标签;反之,则倾向于分配匹配聚类中心的标签;α和λt为常数项,本文在所有实验中分别取α=15和λt=0.5。引入梯度约束项dt的主要作用是提高各超像素的边缘与实际轮廓的贴合度,且确保超像素的紧密度,以改善超像素分割方法的分割质量,这有助于提高后续视频目标提取的准确率。
步骤4迭代优化聚类结果。在上述像素聚类结果中,本文使用Sigma滤波[24]消除孤立的噪声点,这是为了避免超像素结果中出现颗粒状区域。在本文提供的所有视频预处理结果中,改进的视频预处理方法在迭代5次后即可取得理想的超像素分割结果,因此本文设置达到最大迭代次数(=5次)为像素聚类迭代过程的终止条件。
3.3 三维无向图的构建
在对所有视频帧进行预处理之后,本文将待分割的视频段构建为三维无向图G=(ν,ε),用于表达视频片段中超像素间的连通关系。其中,结点集ν包含预处理视频片段后生成的所有超像素;边集ε包含连接直接相邻结点对的边集εI,以及连接不直接相邻但具有相似外观特征的结点对的边集εT,且其中的每一条边都有对应的权值。另外,每个结点都与虚拟的两个终端结点S和T建立连接边。
直接相邻的边集εI(图3中红色的边)由连接同一视频帧中直接相邻两个结点之间的边和连接前后两视频帧中空间位置相邻的两个结点间的边组成。本文结合像素覆盖率和中心坐标间的空间距离度量前后视频帧中相邻结点对的邻接关系:给定两个结点p∈fi和q∈{fi-1,fi+1},若这两个结点对应超像素的中心坐标距离小于用户指定的阈值,则建立连接边<p,q>∈εI。其中,N为当前视频帧包含的超像素个数,K为当前视频帧的总像素数目。为构建具有相似运动特征的边集εT,本文需要确定同一视频帧或不同视频帧(图3中蓝色的边)中不直接相邻但具有一定相似特征的结点对的邻接关系:若两个结点p和q对应超像素的中心坐标距离大于阈值R且运动特征相近似,则建立连接边<p,q>∈εT,其中基于运动特征的相似性度量将在后续式(6)中进行详细说明。通过确定各结点对之间的连通关系后,本文在两关键视频帧之间构建三维无向图,如图3所示。
3.4 快速视频目标提取
在此基础上,本文将视频目标提取问题转换为三维无向图G的最优二值标签分配问题,即通过利用最大流/最小割算法最小化能量函数E(l),可为每一个结点分配唯一的标签l∈{0,1},从而确定每一结点是属于视频目标区域(l=0)或是属于背景区域(l=1)。需要指出的是,已被用户标记覆盖的结点具有绝对的标签值。根据构建的三维无向图G,基于马尔科夫随机场的能量函数E(l)定义如下:
其中,Dp(lp)为数据项,用于计算结点p分配标签lp∈{0,1}时的能量惩罚;Vp,q(lp,lq)为基于外观特征的平滑项,用于度量直接相邻的结点在分配不同标签时的能量惩罚;Up,q(lp,lq)为时空平滑项,用于度量不直接相邻但具有一定相似运动特征的结点在分配不同标签时的能量惩罚;Hυ(lυ)为高阶项,用于增强连续视频帧中超像素之间的连通关系,其中,υ是由视频片段中具有较强时空一致性的超像素组成的超像素集;X为整个视频片段中所有超像素集的集合。对于数据项Dp(lp)的计算,根据用户在关键帧上的交互输入,采用高斯混合模型(Gaussian mixture models,GMMs)[25]分别估计视频目标和背景的颜色模型,以计算任一结点属于视频目标或背景的可能性。其中,前景和背景高斯混合模型均由5个单高斯分布组成。如下,本文将详细阐述其他各能量项的定义。
平滑项Vp,q(lp,lq):当视频中的前景目标和背景的颜色相近似时,单一的颜色特征并不能准确度量前景目标与背景的差异。由此,本文通过结合颜色特征与纹理特征度量直接相邻两结点之间的外观相似程度,平滑项Vp,q(lp,lq)的具体定义如下:

其中,β为常数项,用于控制结点之间在分配不同标签时的外观差异容限;δ(p,q)用于度量直接相邻结点p和q之间的外观差异,其中,‖Zp-Zq‖和 ‖Tp-Tq‖分别用于度量相邻结点p和q在颜色特征和纹理特征上的差异。本文采用Gabor滤波[26]进行纹理特征提取,提取的纹理特征向量Tp是由m个尺度和n个方向(通常取m=4,n=6)上的均值μm,n和标准差σm,n组成的特征向量。值得注意的是,本文取每个超像素聚类中心的区域内的平均Gabor特征向量作为结点p的纹理特征,其中S为预处理方法中聚类中心φj之间的步长;λ为调节颜色特征与纹理特征比重的参数。另外,颜色特征与纹理特征都是归一化的。由平滑项Vp,q(lp,lq)计算得到的能量惩罚对应图3中标记了红色的边的权值。
时空平滑项Up,q(lp,lq):本文采用光流法跟踪前景目标在视频片段中的运动轨迹,然而,当视频中存在目标剧烈运动、非刚体运动以及光照变换等不利因素时,不稳定的光流估计会影响视频目标提取结果的质量。由此,本文结合颜色特征与运动特征定义时空平滑项:
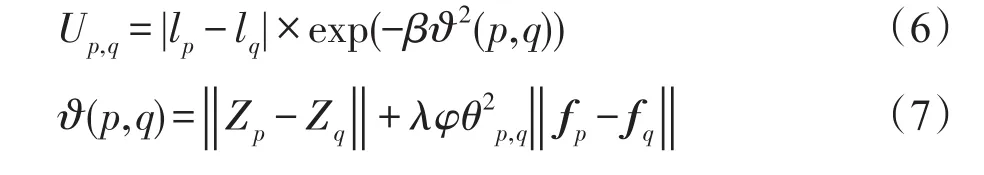
其中,ϑ(p,q)用于度量时空结点对的外观相似程度;fp和fq为结点p和q对应的光流向量。φθp,q为光流向量fp与fq之间夹角的余弦值;λ为常数项,用于平衡颜色特征和运动特征之间的重要程度。此外,为确保准确跟踪视频目标,本文计算光流向量fp与fq的置信度,并剔除阈值外的不可靠的光流。置信度定义如下:

高阶项Hυ(lυ):在能量函数E(l)中,两平滑项Vp,q(lp,lq)和Up,q(lp,lq)的主要作用是保持提取结果中视频目标的时空一致性。然而,时空平滑项Up,q(lp,lq)很大程度上依赖于准确的光流估计,因此上述两平滑项仅能保持提取结果中相邻视频帧中前景目标的时空一致性。由于视频目标内局部区域之间的运动特征往往存在较大差异,这将导致错误的标签分配,从而容易产生视频目标残缺等不理想的提取结果。为增强视频目标区域的连通关系,文献[19]在能量公式中引入高阶项以实现高质量的视频目标提取。该方法中定义的高阶项是建立在利用文献[15]生成的超体素的基础上的,且超体素内部的结点之间的连通关系是相对固定的。然而,在处理复杂场景的视频片段时,利用文献[15]生成的超体素中往往会出现视频目标区域和背景区域划分为同一个超体素的情况,此时,文献[19]中定义的高阶项将无法用于修正上述的错误结果。在本文中,通过度量用户标记的超像素与跨时空邻域的超像素在运动特征以及位置上的差异,在无向图中建立连接具有较强连通关系的超像素的边,以此形成跨时空的超像素集υ。具体地,对于关键帧fi上用户标记为视频目标/背景的超像素plp=0/1,若其他视频帧中存在超像素qlq=0/1,且与已标记超像素plp=0/1的中心坐标距离和对应光流向量的夹角均小于用户给定的阈值,则判定超像素plp=0/1与超像素qlq=0/1具有较强的连通关系,且认为其是属于视频目标/背景的超像素集υl=0/1的。高阶项Hυ(lυ)定义如下:
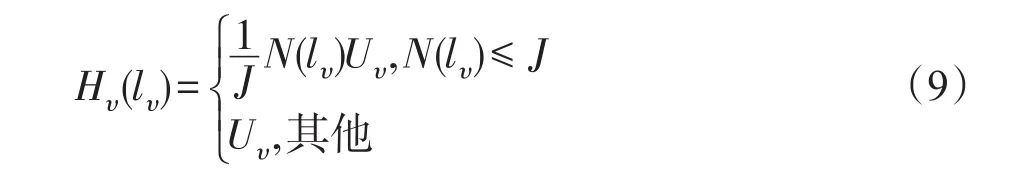
其中,N(lυ)表示超像素集υ内具有“弱势”标签的超像素的个数。若超像素集内100个超像素中有94个超像素的标签为“0”,6个超像素的标签为“1”,则标签为“1”的超像素处于“弱势”。此时,对应的N(lυ)取值为6。J为用户设置的截断参数,主要用于调整超像素集υ内超像素间的连通关系。Uυ为将超像素集υ中所有超像素划分为视频目标或背景的能量惩罚总和。相对于文献[17],本文通过为连续视频帧中具有较强连通关系的视频目标区域赋予高阶项Hυ(lυ),这能够减少这些区域在最小化能量函数时所需的能量惩罚,从而确保它们在视频目标提取结果中的时空一致性。因此,这一定程度上避免了视频目标提取结果中出现前景目标残缺等瑕疵。
4 实验结果分析与讨论
本文方法是在2.5 GHz处理器、8 GB内存的PC机上使用VS和OpenCV等开发工具实现的。为验证本文方法的实用性与高效性,本文在Segtrack数据集和Youtube-objects数据集上进行了大量相关实验验证,并从提取质量和时间效率两方面对比了现有经典的视频目标提取方法。另外,选取视频素材进行实验时充分考虑摄像机是否固定以及背景是否变化等情况,从而确保获得的实验结果能够在质量与效率上客观评价本文方法。
4.1 视频预处理
图4给出了本文改进的SLIC算法与原SLIC算法[21]在MSRA10K_Imgs_GT公共数据集(图4(a)和图4(b))和video Segmentation Data公共数据集(图4(c)和图4(d))上的实验对比。其中,第一行给出的待处理的视频帧具有光照变换明显、前景目标形态不规则且内部区域颜色分布复杂等特点。第二行是使用原SLIC算法得到的视频帧的超像素分割结果,这些超像素结果中出现了多种颜色信息(图4(a))、边缘过于锯齿化(图4(b))、超像素包含超像素(图4(c))和形状不规则(图4(d))等瑕疵。这是由于原SLIC算法直接在聚类中心的邻域内进行k-means聚类,没有对超像素的轮廓进行约束,这容易生成形状不规则的超像素;且k-means聚类算法对异常值较为敏感,这将使得聚类过程结束后产生孤立的噪声点。如图4第三行所示,本文改进后的SLIC算法能够获得较好的超像素分割结果,其关键是在像素聚类过程中引入了梯度约束项,这不仅能够使超像素的轮廓更贴近实际目标的边缘,还能够使得生成的超像素的形状更加均匀。同时,在每次像素聚类迭代后,本文使用Sigma滤波器去除噪声点以进一步改善超像素分割结果的质量。
图5给出了与视频预处理方法的实验结果对比。对于处理具有复杂形状的前景目标(图5(a)第一行),使用分水岭算法获得的实验结果中存在严重的过分割现象(图5(b)第一行);而在采用均值位移算法获得的实验结果中,图像子块区域形状、面积差异过大(图5(c)第一行),这两种方法均无法获得理想的视频帧预处理结果。而超像素分割方法旨在于生成形状趋于均匀且能够保留一定图像局部特征的超像素,因此有效避免了上述两种方法的不足。实际上,不同超像素方法所产生的结果也会存在差异:ERS(entropy rate superpixel)算法[27]通过构造随机游走的熵率项,使得超像素具有良好的边缘贴合度,但该算法生成的不规则形状的超像素可能成为后续视频目标提取的一个隐患(图5(d)第一行);RSP(regular super-pixel)算法[28]过于强调保持超像素的拓扑结构,因而生成的超像素的边界不能贴合复杂形状目标的真实轮廓(图5(e)第一行);LSC(linear spectral clustering)算法[29]相对于上述两种超像素分割[27-28]算法较好地实现了超像素在拓扑结构与边缘贴合度的平衡,但该算法依然会生成形状不规则的超像素(图5(f)第二行)。对于包含具有前景目标是非刚体运动的视频(图5(a)第二行)和具有不同光照效果的视频(图5(a)第三行),本文的预处理方法能够生成较理想的超像素分割结果,如图5(g)第二行和第三行所示。

Fig.4 Comparisons on results of video frame preprocessing图4 视频帧预处理结果对比
4.2 视频目标提取
4.2.1 Segtrack数据集实验结果

Fig.5 Comparison of methods for video preprocessing图5 视频帧预处理方法对比

Fig.6 Comparison of experiment results on Segtrack(monkeydog)图6 Segtrack数据集实验结果对比(monkeydog)

Fig.7 Comparison of experiment results on Segtrack(girl)图7 Segtrack数据集实验结果对比(girl)
Segtrack数据集包含有猴子、狗、女孩、鸟、降落伞、猎豹和企鹅7个视频,并包含有准确分割这些视频的真值图像。虽然这些视频是普通分辨率的,但视频内容复杂,如具有视频目标与背景颜色接近、视频目标非刚体运动、摄像机快速运动等情况。这增加了视频目标提取的难度。图6和图7分别给出的是对猴子视频片段和女孩视频片段的前景目标提取结果,这两段视频片段均包含非刚体运动的视频目标以及复杂的背景,且分别与文献[5,17,19,22]进行了实验结果对比。从图6中可以看出,文献[5](图6(c))获得的提取结果中存在视频目标缺失(第三行)和严重欠分割(第五行)等瑕疵。这是由于单一利用颜色特征难以准确区分具有颜色相近似的视频目标与背景。文献[17](图6(d))通过结合颜色特征与运动特征用以提取视频目标,然而,由于该方法无法准确估计视频目标的非刚体运动,因此极大地降低了前景提取精度。文献[19](图6(e))提取的视频目标仍存在局部缺失的情况(第三行),主要原因在于视频目标提取的质量过分依赖超体素的边缘贴合度。此外,对于处理具有复杂场景视频时,文献[19]在预处理阶段生成的三维超体素并不能准确表达视频目标的边界信息。文献[22]通过迭代更新视频中猴子的运动信息,从而能够获得较理想的视频目标提取结果(如图6(f)所示)。本文使用基于梯度约束的超像素分割方法逐帧进行预处理,生成的超像素边缘贴合度较高。此外,本文基于多特征融合度量视频目标与背景的差异,在提取具有非刚体运动的视频目标时也能得到较好的结果(如图6(g)所示)。
图7给出的是处理女孩(girl)视频片段获得的视频目标提取结果。在文献[5]给出的结果中,存在严重的视频目标内部区域缺失和目标边界锯齿化等现象(图7(c))。文献[17,19]使用超像素分割方法进行视频预处理,一定程度上避免了内部区域缺失的现象,但是不准确的光流估计导致视频目标提取结果中存在边缘区域缺失(图7(d)和图7(e))。虽然文献[19]引入高阶项以确保视频目标的时空一致性,提取结果相对于文献[17]有所改善,但依然无法满足高质量目标提取的要求(图7(e)第二行)。对于视频中快速跑动的女孩,文献[22]仍不能准确地对女孩的运动信息进行估计,因此,分割结果中存在视频目标局部缺失的瑕疵(图7(f)第二行和第五行)。从图7(g)可以看出,本文能够获得高质量的视频目标提取结果。
4.2.2 Youtube-objects数据集实验结果
Youtube-objects公开数据集是由Youtube上收集的超过10种分类(包括飞机、猫和狗等)的视频集组成的。其中每个类别包含9到24个视频片段,且不同的视频片段中视频的分辨率、视频目标的运动和摄像机的运动等各不相同。该数据集通常用于目标识别与跟踪,最近才被用于评价视频目标提取方法的性能。相应地,视频目标提取相对于Segtrack数据集难度更大。图8和图9分别给出了本文方法与上述四种视频目标提取方法[5,17,19,22]的实验结果对比。从图8中可以看出,文献[5]、文献[22]与本文方法的视频目标提取结果(图8(c)、图8(f)和图8(g))去除了马群腿部下方的阴影区域;而文献[17]与文献[19]对应的结果中由于保留了阴影区域从而导致不理想的提取结果(图8(d)和图8(e))。当视频中的阴影区域随着视频目标一起运动时,文献[17]难以准确区分视频目标区域与背景区域的运动。而文献[19]是一种半监督式的视频目标提取方法,其中视频目标提取的质量过于依赖视频首帧的准确分割程度。然而,尽管文献[5]的提取结果较为理想,但由于背景中部分区域的颜色与视频目标的过于接近,这容易将属于背景的部分区域误划分为视频目标区域的,从而产生了错误的视频目标提取结果。文献[22]能够获得较理想的视频目标分割结果(图8(f))。本文通过结合外观特征与运动特征进行相似性度量,并通过计算光流向量的置信度以剔除错误的光流估计结果,这同样能够改善最终视频目标提取的质量(如图8(g)所示)。
图9给出的是另一视频片段(猫)的实验结果。从图9(a)可以看出,该视频片段存在大量与视频目标相似的背景区域(如具有不同纹理的毯区域),这对视频目标提取造成了一定的影响。在文献[5]中,用户需要对视频目标区域与背景区域进行大量的交互标记,且提取结果显然很不理想(图9(c))。文献[17]通过估计光流信息准确捕捉了视频目标的运动轨迹,并结合颜色特征与运动特征实现了较为理想的视频目标提取。然而,由于摄像机是不断运动的,不准确的光流估计难以正确区分背景区域与视频目标区域的运动,从而该方法将视频中出现的水盆也划为背景(图9(d)第三行)。文献[19]中利用三维超体素增强了连续帧中特征相似区域的邻接关系,并且该算法也利用了颜色特征与运动特征进行外观相似性度量。然而,该方法也没有将视频片段中出现的水盆正确划分为背景,主要原因是该方法仍受到不准确光流估计的影响(图9(e)第四行)。文献[22]能够估计准确的光流信息,但由于缺乏有效的外观相似性度量机制,这使得该方法仍不能正确区分猫和地毯区域(图9(f)第二行)。本文方法提出了鲁棒的相似外观度量机制,即通过结合颜色特征与纹理特征区分视频目标区域和背景区域,从而改善了视频提取结果的质量(图9(g))。

Fig.8 Comparison of experiment results on Youtube-objects(horse)图8 Youtube-objects数据集实验结果对比(horse)
4.3 视频目标提取时间效率

Fig.9 Comparison of experiment results on Youtube-objects(cat)图9 Youtube-objects数据集实验结果对比(cat)
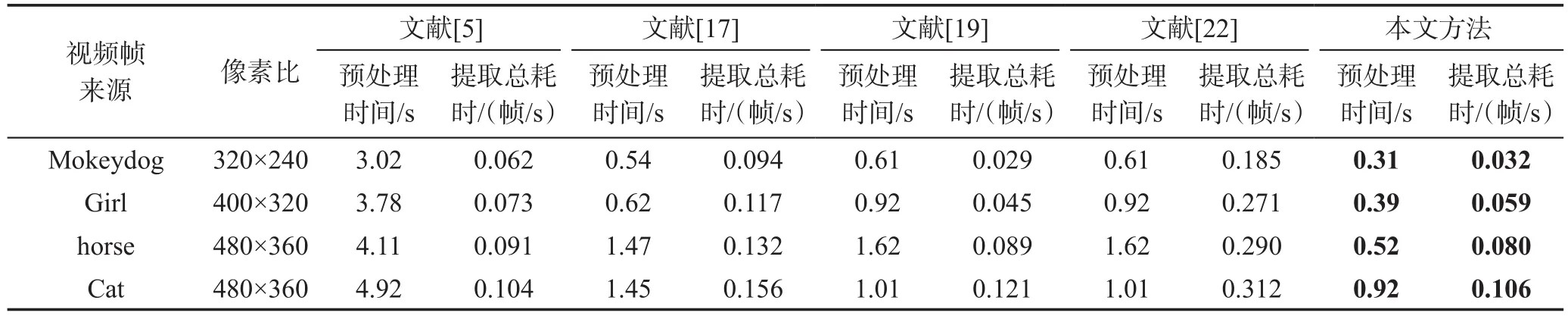
Table 1 Statistics about runtime of video object extraction表1 视频目标提取时间消耗统计
表1给出了上述视频目标提取方法在处理各视频片段并获得最理想前景提取结果所需的预处理时间消耗和总时间消耗。在表1中,文献[5]在预处理的过程中耗时最多,尽管前景提取阶段耗时较少,但该方法不能满足快速视频目标提取的要求。文献[17]采用的预处理方法在处理视频帧时虽然用时较少,但在后续视频目标提取阶段中需要耗费更多的计算时间,这是因为该方法为每一视频帧分配一个动态外观模型,而训练这些动态外观模型需要耗费大量的时间。文献[19]以预处理生成的超体素为结点构建三维无向图,这使得三维无向图中的结点数量远少于其他方法,因而该方法在前景提取过程中需要的时间消耗最少。然而,超体素的生成需要消耗较多的时间,这一定程度上也影响了最终视频目标提取的效率。文献[22]采用了与文献[19]相同的方法预处理视频数据,然而,该方法在提取视频目标时则消耗大量的时间。其主要原因在于该方法不仅建立了超像素与超像素之间的相邻关系,还建立了像素与像素、像素与超像素之间的空间域和时间域上的相邻关系,计算代价高。本文方法使用改进的超像素分割算法进行预处理,并在此基础上改进能量函数,这不仅能够实现在少量的用户交互下进行快速的视频目标提取,而且还能快速地处理具有高分辨率的视频片段。
4.4 高阶项结果对比
为验证本文引入的高阶项是优于文献[19]的,本文选取Youtube-obejcts数据集中的视频段进行实验结果对比。其中,从左至右分别为未引入高阶项、文献[19]和本文方法的视频目标提取结果,如图10所示。在图10给出的视频片段中,马的四肢运动幅度较大且背景是变化的。在未引入高阶项时,获得的视频目标提取结果中出现了目标区域缺失和错误前景提取等瑕疵(图10第二列)。文献[19]在引入以超体素为基础的高阶项后,视频目标提取结果的质量相对于图10第二列给出的结果有了一定的改善,这是因为跨时空域的超体素避免了来自背景区域不准确光流的干扰。然而,文献[19]中使用的是内部连通关系相对固定的全局超体素,高阶项并不能修正视频目标区域和背景区域被划分为同一个超体素的情况,因而产生了不理想的视频目标提取结果(图10第三列)。而本文方法使用各视频帧上的超像素构建局部高阶项,以确保超像素具有较好的边缘贴合度,这使得高阶项能够更准确地修正各超像素集在能量函数中的能量惩罚,从而改善了视频目标提取结果的精确度。如图10第四列所示,相对于文献[19](图10(c)第一行和第四行),本文去除了视频目标的前腿间夹杂的背景区域(图10(d)第一行和第四行)。
5 结束语

Fig.10 Comparisons on results of video object segmentation without/with high order potential图10 高阶项的视频目标提取结果对比
针对如何实现快速且高质量的视频目标提取问题,本文提出了一种基于梯度约束SLIC的快速视频目标提取方法。在使用原SLIC超像素分割方法进行视频预处理的基础上引入梯度约束项,这在提高后续视频目标提取效率的同时也改善了视频目标提取的质量。同时,本文通过结合外观特征与运动特征精确度量视频目标与背景的差异,因而本文能够处理具有目标剧烈、非刚体运动,视频目标与背景颜色相近似等内容复杂的视频片段。另外,本文通过引入高阶项保持前景提取结果中视频目标的时空一致性,从而有效地避免了提取结果中出现视频目标局部缺失等瑕疵。
本文方法的不足之处在于本文方法的视频目标提取结果的质量一定程度上依赖于视频帧预处理的质量,若视频目标具有细长且突出的结构(复杂且重叠的树枝、昆虫的触角和腿等),视频帧预处理方法生成的结果也很难表达这些结构的特征信息。因此,本文下一步将考虑优化特征度量机制,以进一步提高视频目标提取的精度与时间效率。
