紧凑型深度卷积神经网络在图像识别中的应用*
2019-02-13钱雪忠
吴 进,钱雪忠
江南大学 物联网工程学院,江苏 无锡 214122
1 引言
深度卷积神经网络在图像识别领域取得了突破性的进展,但是网络的参数规模越来越大,参数量达到百万级,甚至千万级,不利于应用。为了更好地解决这个问题,一种方式是压缩现有的网络模型,Howard等人[1]提出的基于深度可分离的卷积结构MoblieNet,引入了传统网络中原先采用的group思想,即限制滤波器的卷积计算只针对特定的group中的输入,将标准卷积分离成一个深度卷积和一个点卷积,极大程度地降低了卷积计算,同时提升了计算速度。基于MobileNet的group思想,ShuffleNet[2]将输入的group打散,结合深度可分离卷积代替类似于ResNet block单元构成了ShuffleNet单元,解决了多个group叠加出现的边界效应,减少了计算量,增强了网络的表现力。Theis等人[3]通过使用对角Fisher信息值在尽量避免训练损失的前提下一次去掉一个卷积的特征图的方法来剪枝。
另一种方式是权值压缩,Han等人[4]基于权值聚类的方法将连续分散的权值离散化,从而减少需要存储的权值数量,并采用Huffman encoding将平均编码长度减少实现减小模型尺寸的目的,最后采用CSR(compressed sparse row)来存储。Rastegari等人提出的XNOR-Net[5]输入和输出都量化成二值,将输入数据先进行BN归一化处理,接着进行二值化的卷积操作,实现32倍的存储压缩,同时训练速度得到58倍的提升。
本文鉴于卷积神经网络(convolutional neural network,CNN)结构的压缩理论,分析了现有的不同的CNN结构模型,设计了多分支的Conv-mixed结构,并设计了新的紧凑型深度卷积神经网络架构Width-MixedNet,分别在 CIFAR-10、CIFAR-100 和 MNIST数据集上进行实验,结果表明,Width-MixedNet在参数规模远低于其他深度神经网络结构的情况下,取得了更好的效果。
2 相关工作
2.1 Conv-mixed结构
传统的深度卷积神经网络都是以convolutionspooling堆叠起来的直线型结构,比如2012年Krizhevsky等人[6]提出的由5个convolution层和3个fullconnection层堆叠成的AlexNet,2014年Visual Geometry Group和Google DeepMind研发的由3×3的小型卷积核反复堆叠的19层VGGNet[7],之后由微软训练的多达152层的ResNet[8]。上述深度卷积神经网络的深度逐渐加深,虽然达到的精度越来越高,伴随而来的是网络的参数越来越庞大,容易导致过拟合,计算量也变得相当大,难以应用,并且网络越深,容易导致梯度消失,模型难以优化。为了深度神经网络能在有硬件条件限制的平台上广泛应用(比如自动驾驶汽车、无人机、VR设备等),紧凑型的网络模型设计引起了很多关注。
为了让深度卷积神经网络有更好的提取特征和学习能力,最直接有效的方法是增加卷积层的通道,但这会增加整个网络的计算量,容易导致过拟合。因为卷积神经网络中每一个输出通道只对应一个卷积核,同一个层参数共享,因此一个输出通道只能提取一种特征。在文献[9]中提出的MLPConv代替传统的卷积层,将输出通道之间信息进行组合,相当于普通卷积层之后再连接1×1的卷积核ReLU激活函数,因为内核为1×1的卷积层只有一个参数,只需要很小的计算量就可以提取一层特征,增加一层网络的非线性化。
在2014年ILSVRC(large scale visual recognition challenge)的比赛中,Google Inception Net[10]以较大的优势夺冠。值得注意的是,InceptionNet精心设计的Inception Module(如图1所示),先将前一层输出的特征图(previous layers)分别作为1×1、3×3和5×5的卷积层和一个maxpooling层的输入,然后各个分支在输出通道上合并(concatenation),作为下一个Inception Module的输入。这种由Inception Module堆叠成的深层网络结构,对宽度进行了高效的扩充和利用,提高了准确率并且不至于过拟合。
最近的研究开始直接设计紧凑型的网络架构:SqueezeNet[11],论文提到的Fire Module如图2所示,先将前一层的输出特征图(previous layers)作为由3个1×1卷积组成的squeeze层的输入,在输出通道上合并之后,再作为由4个1×1和4个3×3的卷积组成的expand层的输入,接着在输出通道上合并作为下一个Fire Module的输入。SqueezeNet达到了AlexNet相同的精度水平,同时SqueezeNet的模型大小只有AlexNet的1/50。

Fig.2 Fire module图2 Fire模块
受到所述观察的启发,提出了一种紧凑的深度卷积神经网络结构,其中包含一种新的基本模块Conv-mixed。图3是整个网络模型中的一个Convmixed结构,前一层的输出(previous layer)作为Convmixed的输入,输入共有5个分支,分别为P-C0-C1-C2、P-C3-C4-C5、P-C6、P-A-C7、P-C8。C8之后又是两个分支C8-C9和C8-C9,最后各个分支在输出通道上合并。参数k和s表示内核大小和步长,参数r表示空洞卷积的扩张率,在每一次的卷积操作之前,都对其输入进行Batch Normalization正则化,所有的卷积都采用ReLU激活函数进行非线性化。
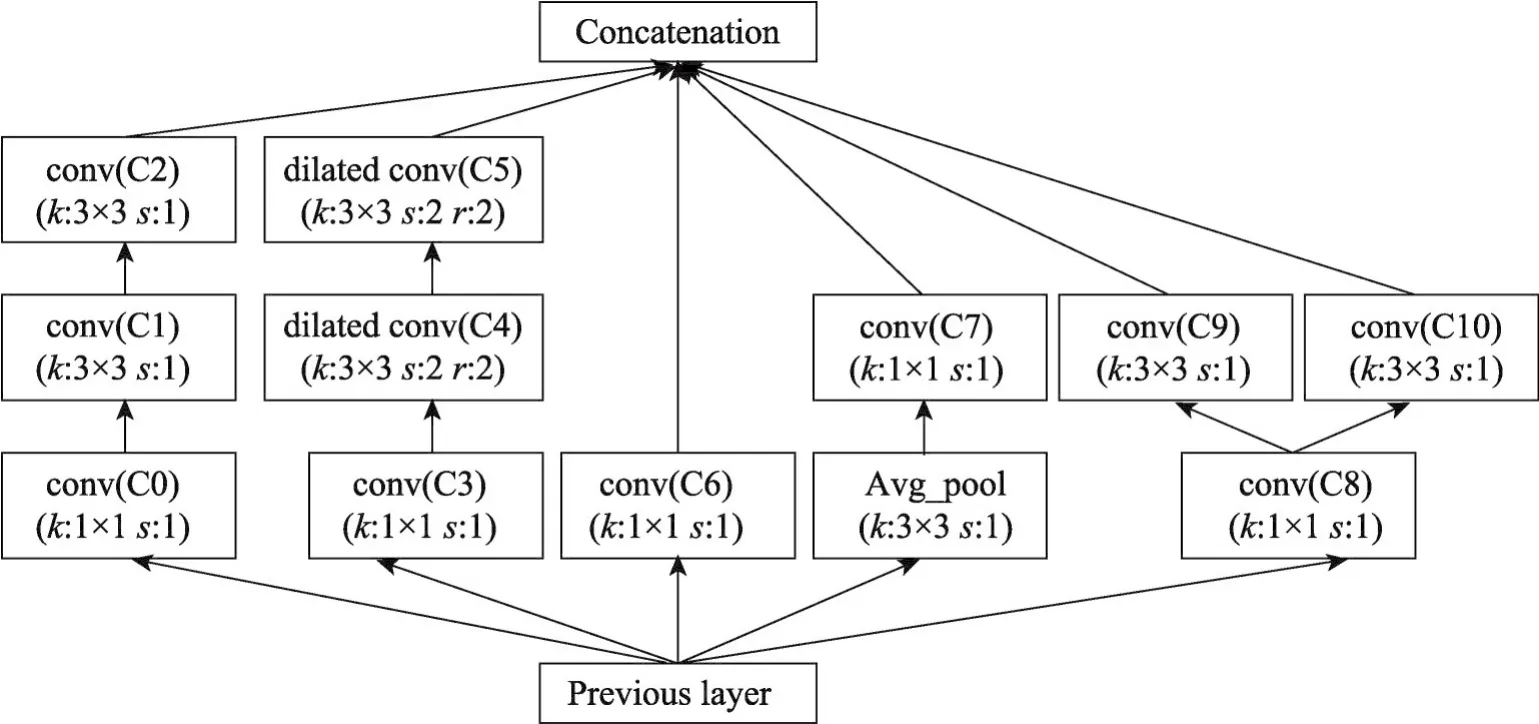
Fig.3 Conv-mixed module图3 Conv-mixed模块
在图像数据中,临近区域的数据相关性高,卷积神经网络中每一个输出通道对应一个滤波器,只能提取一类特征,因此使用分支结构使多个不同的卷积核连接同一位置,这样可以提取多个不同的特征。文献[12]中提出:如果数据集的概率分布可以被一个很大很稀疏的神经网络所表达,那么构筑这个网络的最佳方式就是逐层构筑,即将上一层高度相关(correlated)的节点聚类,并将聚类出来的每一个小簇(cluster)连接到一起。设计出的Conv-mixed这种多分支结构,将相关性高的节点连接在一起,构建了很高效的符合上述理论的稀疏结构。
为了增加提取特征的多样性,使用了1×3、3×1和3×3三种不同尺寸的卷积内核,相比于大型的卷积比如5×5和7×7,小型卷积的计算量虽然小,但是感受视野也小。为了弥补这个缺陷,在分支结构里加入了Dilated Convolutions[13]即空洞卷积。普通卷积和空洞卷积的对比如图4所示,左边是内核kernel=3的普通卷积,相当于kernel=3、膨胀系数r=1的空洞卷积;右边是kernel=3、r=2的空洞卷积,相当于kernel=7的普通卷积。膨胀系数r表示每个像素之间填充r-1个0。在通道数相同的情况下,图4左边的普通卷积和右边的空洞卷积参数量相同,但是在同一层的感受视野却不同,感受视野公式如下:
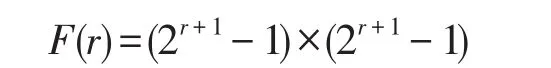
其中,r表示膨胀系数,F(r)表示最终的感受视野,例如图4中左边普通卷积在这层的感受视野为F(r=1)=3×3,右边r=2的空洞卷积感受视野为F(r=2)=7×7。可以推算:经过卷积层叠加之后,2层的3×3的普通卷积转换相当于1层5×5的卷积,2层3×3、r=2的空洞卷积,相当于1层13×13的普通卷积。
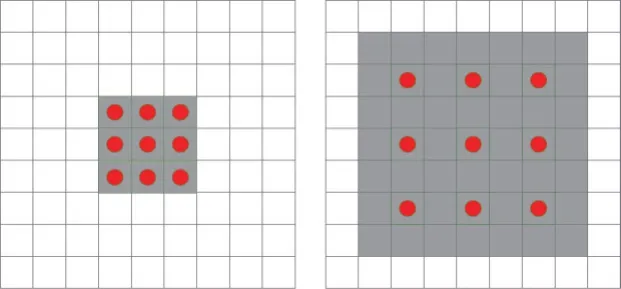
Fig.4 Comparison of ordinary convolution and dilated convolution图4 模块普通卷积和空洞卷积的对比
对于一个Conv-mixed结构的参数数量F(i,n)和运算量Flops(i,n)的计算方法为:

其中,kl和kd指的是当前卷积核的宽度和高度,Ni指的是上一层特征图的通道数也就是输入通道数,Ni+1指的是输出通道数,b指的是偏置,hl和hd指的是输出特征图的宽度和高度。
2.2 逐层卷积代替全连接层
传统的深度卷积神经网络在最后一个卷积之后使用全连接层(full connection,FC)将特征向量化进行图像分类,但是全连接层的参数量太大,在整个深度卷积神经网络中占的比重过多,一方面增加了计算量,另一方面容易导致过拟合。以用作“ImageNet”[14]分类任务的AlexNet为例,经计算,整个网络的参数数量有6.1×106,后面的3个全连接层参数量有5.86×106,可以说全连接层的计算量几乎占据了整个网络。虽然AlexNet之后的深度卷积神经网络(比如VGGNet、GoogleNet等)中全连接层的参数量占整个网络的比重没有这么多,是因为都加深了网络的深度,只增加了卷积层的数量,后面的全连接层并没有增加,但是全连接层的参数量依然可观。
为了解决这个问题,一种方法是在文献《Network in Network》中提出的“GAP,Global Average Pooling”方法,在最后一个卷积层之后使用1×1的卷积缩小通道数,然后对每个feature map求平均,再进行softmax,以极小的计算量达到全连接层的准确率。虽然使用了GAP的深度卷积神经网络计算量减少了,也减轻了过拟合,但是整个网络的收敛速度减慢了。
另一种方法是Long等人[15]在语义分割的任务中提出的“全卷积网络(fully convolutional networks,FCN)”中将全连接层转换为卷积层,例如图5所示的全连接层,假设深度卷积神经网络的最后一个卷积层的输出特征图的尺寸大小为12×12×96,全连接层的第一个隐藏层和第二个隐藏层的节点数都为1 000,一共需要分为100个类。在连接第一个隐藏层时,需要将特征图拉伸成一个长度为13 824的一维向量,再和隐藏层进行全连接,再进行最后的分类。但是FCN中将全连接转换为卷积层时,如图6所示,直接用内核为12×12的大型卷积核、通道数为1 000的卷积层,将输出的特征图变为1×1×1 000,同样的,在连接第二个隐藏层时,直接用上一层的输出特征的宽度×高度的内核、通道数为1 000的卷积层代替,这样就可以达到全连接层直接转换为卷积层的效果。

Fig.5 Full connection layers(The number of parameters is 1.5×106)图5 全连接层(参数数量为1.5×106)

Fig.6 Full connection layers is converted to convolutional layer in FCN图6 FCN中将全连接层转换为卷积层
因为卷积层共享了大量的计算,权值和偏置有自己的范围,所以转换为卷积层后加快了整个网络的运算速度。参数数量仍为1.5×106。一个全连接层转换为卷积层的参数计算方法如下:

式中,kl和kd指的是卷积核的长度和宽度,Ni指的是通道数,b指的是偏置。因为转换为卷积层的参数数量和全连接层的参数数量是相等的,虽然整个网络的学习能力变强了,但是参数数量并没有减少,因此提出了“多个小型卷积逐层缩小特征图代替全连接层”的方法,如图7所示。
与图6中的全连接层直接转换为卷积层相比,层数越深,输出的特征图的尺寸越小。在卷积层中,卷积核对特征图进行局部窗口滑动做滤波操作,因为上述FCN中提到的方法是直接使用和输出特征图“宽度×高度”一样尺寸的卷积核,那么就只有一个窗口作用于全部区域,但是参数和运算量都没有变,实际上效果等效于全连接层,而逐层使用小型卷积层,提取的都是特征图局部区域的特征,是所有的滤波器对局部区域分别进行卷积操作,是真正意义上的“卷积层代替全连接层”,并且计算量更小,收敛更快,参数量更少,仅有2.5×105,只有全连接层的1/6。

Fig.7 Multiple small convolution stacks instead of full connections(The number of parameters is 2.5×105)图7 多个小型卷积堆叠代替全连接(参数数量为2.5×105)
2.3 Width-MixedNet架构
经过初步实验,图8是本文设计的深度卷积神经网络架构Width-MixedNet。
在Conv-mixed结构之前,先使用了少量的普通卷积和最大池化,这样做可以用少量的计算将特征进行跨通道的组合,增加输出通道。为了能使整个网络的参数尽可能得少,优化Width-MixedNet架构时,在Conv-mixed合并多通道的特征图后面使用了多个1×1的卷积,这样可以把同一空间位置但是不同通道的特征组合在一起,同时可以用很小的计算量增加一层非线性化。在输出通道数相同的情况下,1×1卷积的参数量只有3×3卷积参数量的1/9、5×5的卷积参数量的1/25。
在最后的Conv-mixed结构之后是本文设计的多个小型卷积层堆叠代替全连接层,作为最后的特征提取。AlexNet、VGGNet、InceptionNet等大型卷积神经网络在卷积层的特征提取中,特征图的宽度和高度都在减小,通道数增加,设计的多个小型卷积层的目标是将特征图的宽度和高度缩小到1×1、通道数接近于甚至等于分类类别数。为了能使网络的参数数量和计算量少并且能够保证分类准确率的情况下,2×2、1×3和3×1等尺寸的卷积内核会使网络的层数变多,导致计算量过大,并且过拟合,5×5的卷积内核单个卷积层的参数数量大,导致损失函数收敛慢,需要更多的训练时间。初步实验证明,3×3和4×4的卷积最为合适。
3 实验与分析
为了验证本文提出的深度卷积神经网络架构的性能,分别在数据集MNIST、CIFAR-10和CIFAR-100进行测试,实验使用GTX1080Ti单个GPU,实验环境TensorFlow1.4.0。采用整个网络的参数数量和正确率对模型进行评价,并验证多个小型卷积逐层缩小特征图代替全连接层的性能。
3.1 CIFAR-10数据集
CIFAR-10数据集共有60 000张彩色图像,图像的尺寸为32×32,分为10类,每类由5 000张训练样本和1 000张测试样本组成。在样本训练时,先对图像进行预处理,对每张图片进行随机翻转,设置随机的亮度和对比度,对图像随机剪切成长度×宽度为28×28的大小,获得更多的带噪声的样本,扩充样本容量。
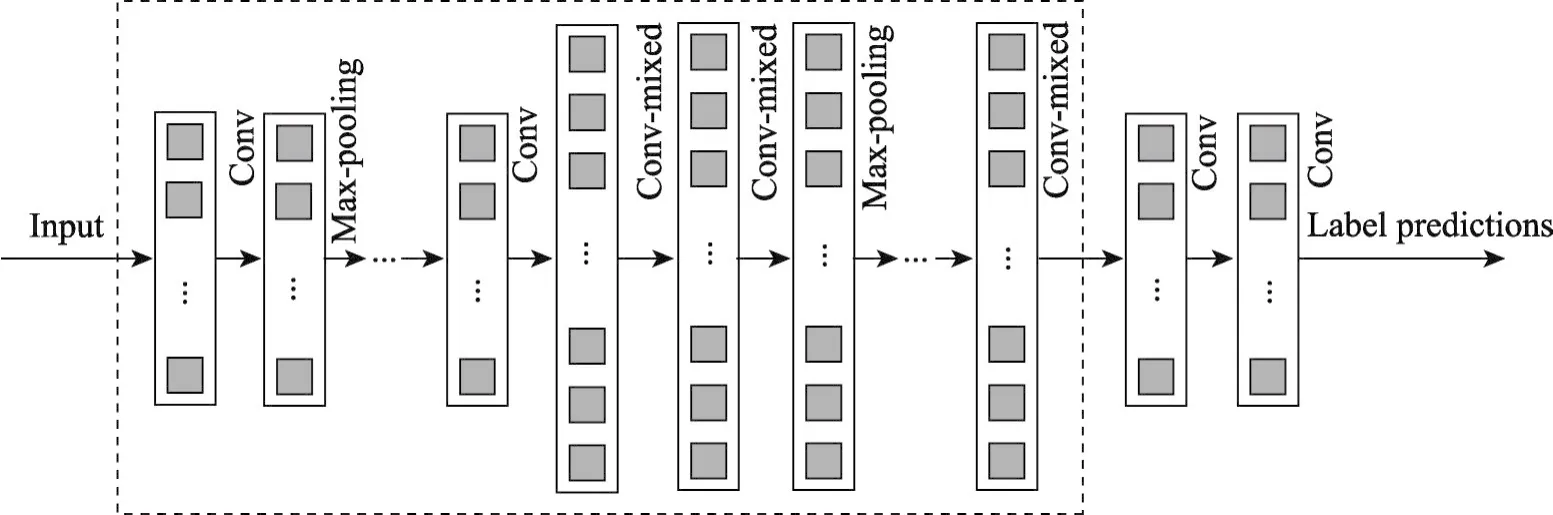
Fig.8 Deep convolutional neural network architecture Width-MixedNet图8 深度卷积神经网络架构Width-MixedNet

Table 1 Width-MixedNet parameters in CIFAR-10表1 在CIFAR-10中Width-MixedNet的参数
在CIFAR-10数据集中,使用的深度卷积神经网络框架如表1所示,表1介绍了Width-MixedNet的普通卷积(conv)、最大池化(maxpool)和Conv-mixed的详细参数,如第三列是每一层输出尺寸的宽度、高度和通道数的乘积;第四列Filter size/Stride表示普通卷积和最大池化的内核尺寸和步长;Conv-mixed的基本参数(参照图3)在第五列Feature maps(Convmixed)中;最后一列Parameters列出了每一层的参数数量。初步实验表明,对于输入图像数据,在前两层使用较大的内核如7×7和5×5的普通卷积对图像处理,会使分类精度提高0.5%~1%,另外在Conv-mixed中使用较大的内核,只能将精度提高0.3%~0.7%,但是会让整体参数量提高1倍。在表1的框架中,整体参数只有3.4×105,主要参数集中在最后两个Convmixed和代替全连接的第一个conv中,约占了整个网络参数数量的56%。
表2显示了使用的深度卷积神经网络Width-MixedNet和其他深度卷积神经网络在CIFAR-10数据集上参数数量和准确率的对比,实验表明Width-MixedNet在参数规模远低于其他深度卷积神经网络的情况下,准确率能达到较高水平。其中与SqueezeNet和FitNet相比,Width-MixedNet在准确率和参数规模上都有较大优势;与WideResNet(d=16,k=8)相比,虽然WideResNet的准确率高出2.17个百分点,但是本文的参数规模仅有WideResNet的1/30。

Table 2 Comparative evaluation results on CIFAR-10表2 CIFAR-10对比实验结果
3.2 CIFAR-100数据集
CIFAR-100数据集和CIFAR-10数据集的组成方式基本一致,图片的大小和格式相同,但是CIFAR-100有100类,每一类的训练样本和测试样本都只有CIFAR-10的1/10,识别难度更大。在实验中,使用的架构和参数与CIFAR-10实验一致,只是在每个卷积层之后增加了Batch Normalization[20]正则化处理,并调整了batch大小和迭代次数。实验结果如表3所示,实验表明,Width-MixedNet在参数规模远低于其他网络结构的情况下,可以达到更高的识别准确率。
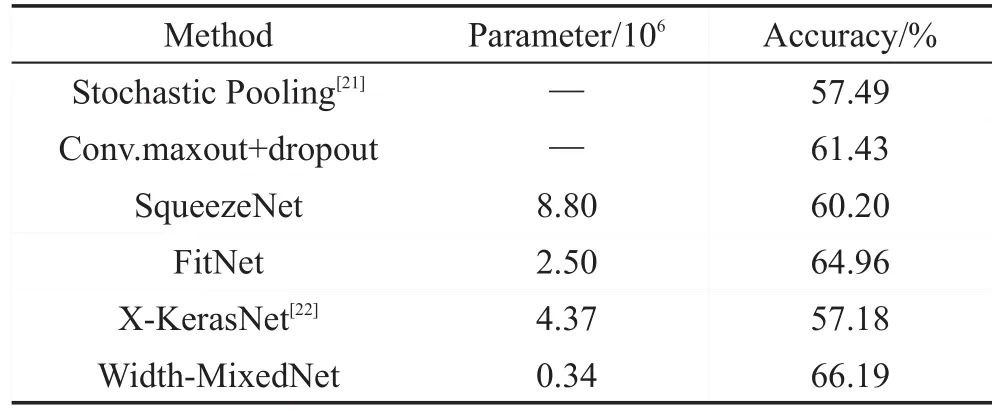
Table 3 Comparative evaluation results on CIFAR-100表3 CIFAR-100对比实验结果
3.3 MNIST数据集
MNIST数据集是由60 000张训练样本和10 000张测试样本组成的手写字体图像数据集,每个样本为28×28大小的二值图像,MNIST识别任务相对简单,为了使整个网络的参数数量尽可能得少,在实验CIFAR-10的结构基础上缩减了普通卷积(conv)和Conv-mixed的数量和卷积核的通道数。为了能使实验结果更直观,在表4中使用测试集的错误率作对比,实验表明,Width-MixedNet在参数数量较少的情况下,有更好的识别率。

Table 4 Comparative evaluation results on MNIST表4 MNIST对比实验结果
3.4 卷积层代替全连接层
为了验证多个小型卷积逐层缩小特征图代替全连接层的性能,在MNIST和CIFAR-10数据集上,分别比较了直接使用全连接层进行最后的特征提取的Width-MixedNet-FC、将卷积层直接转换为全连接层的Width-MixedNet-FCN和多个小型卷积层代替全连接层的Width-MixedNet-CNNs在交叉熵损失函数Loss、训练每个batch的平均耗时和测试数据集平均每张图片的耗时。通过TensorBoard得到TensorFlow的可视化结果,TensorBoard的效果图通过Chrome浏览器查看,为了使实验结果更直观,折线图进行了相应的平滑处理。
该实验中MNIST数据集每个batch大小为50,迭代1 500次,CIFAR-10数据集每个batch大小为128,迭代5 000次。如图9和图10的折线图所示,Width-MixedNet-CNNs交叉熵损失Loss下降速度最快,值最小,效果最好;Width-MixedNet-FC交叉熵损失Loss下降速度最慢,虽然Width-MixedNet-FC和Width-MixedNet-FCN的参数数量相同,但是Width-MixedNet-FCN的表现能力和学习能力更强。不同的网络结构训练每个batch的时间、测试每张图片的时间和测试的准确率如表5和表6所示,实验表明,Width-MixedNet-CNNs训练每个batch的时间最短,测试每张图片的时间最短,同时达到更高的准确率。

Fig.9 Cross entropy loss function of CIFAR-10图9 CIFAR-10的交叉熵损失函数的折线图
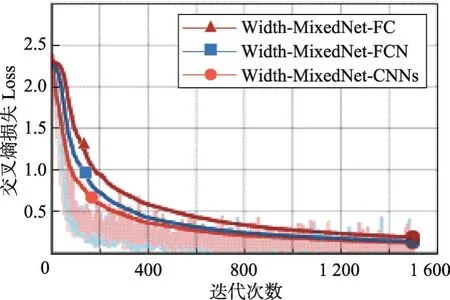
Fig.10 Cross entropy loss function of MNIST图10 MNIST的交叉熵损失函数的折线图
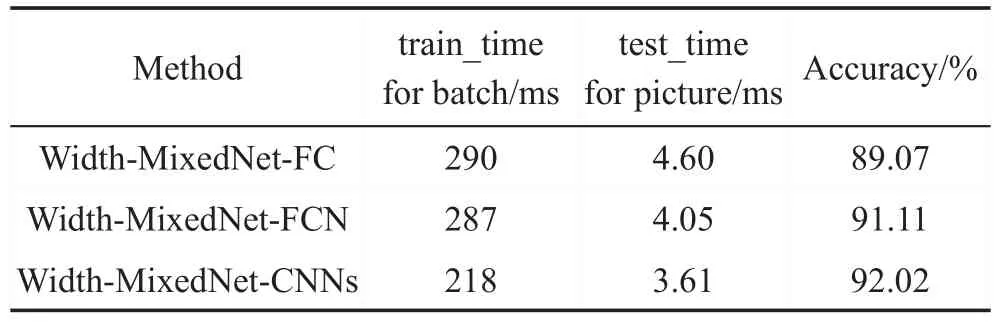
Table 5 Comparison of running time of CIFAR-10表5 CIFAR-10的运行时间对比

Table 6 Comparison of running time of MNIST表6 MNIST的运行时间对比
为了验证多个小型卷积逐层缩小特征图代替全连接层时网络参数的减少对算法的影响,在CIFAR-10数据集上,分别比较了将卷积层直接转换为全连接层的Width-MixedNet-FCN和不同尺寸的小型卷积层在交叉熵损失函数Loss、训练集的准确率training accuracy和测试集的准确率test accuracy。在实验中,对Width-MixedNet的结构进行了微调,去掉了最后一个maxpool层,并且使最后的输出特征图变成12×12×96,随着迭代次数的增加,在实验中Loss逐渐稳定在一个极小的区间内,不利于观察,为了使实验结果更为直观,将迭代次数设为1 500,并且对折线图进行了相应的平滑处理。实验结果Loss折线图如图11所示。

Fig.11 Cross entropy loss function of CIFAR-10图11 CIFAR-10的交叉熵损失函数的折线图
表7显示了将卷积层直接转换为全连接层的Width-MixedNet-FCN和多个小型卷积层代替全连接层的Width-MixedNet-1、2、3、4在CIFAR-10数据集上的对比,其中Filter/Stride表示卷积核的宽度和高度的乘积以及步长,Feature maps/Padding表示输出通道数和是否填充,Training accuracy和Test accuracy表示训练集和测试集的准确率。Width-MixedNet-FCN最后由全连接层直接转换的2个卷积层的参数数量达到了13.9×106,并且训练集的准确率高于测试集的准确率,说明Width-MixedNet-FCN的学习能力较差于其他结构,并且有过拟合的倾向。由图11可以看出,Width-MixedNet-FCN的交叉熵损失函数Loss的值较大,下降速度较慢。Width-MixedNet-4最后的特征提取是由一个内核为4×4、步长为4和一个内核为3×3、步长为1的卷积层组成,其参数数量为1.2×105,效果最好。Width-MixedNet-1、2、3、4的测试集准确率都高于训练集准确率,并且准确率都高于Width-MixedNet-FCN,说明多个小型卷积层叠加代替全连接层的方法效果更好。

Table 7 Comparative evaluation results on CIFAR-10表7 CIFAR-10的对比实验结果
4 结束语
本文针对现有的深度神经网络参数数量过于庞大的问题,分析了现有的深度神经网络的不同结构,设计了一种紧凑型的高效深度卷积神经网络架构Width-MixedNet,其多种不同卷积层组成多分支的基本模块Conv-mixed,在卷积神经网络的宽度上进行扩充,提高了网络在同一层中提取不同特征的能力,并且在深度神经网络的最后分类任务中,改进了FCN中将全连接层直接转换为卷积层的方法,使用多个小型卷积层逐层缩小特征图的规模的方法代替全连接层,进一步减少了网络的参数数量,提高了网络的表现能力和学习能力。实验结果表明,Width-MixedNet在参数规模远低于其他深度卷积神经网络的情况下,可以达到更好的效果。
本文提出的紧凑型结构Width-MixedNet,其学习能力强、参数规模小的特点适合部署移动平台,例如可穿戴设备、智能家具和无人机上。之后的工作中,将进一步研究Width-MixedNet在目标检测、图像分割等领域中的表现和Width-MixedNet部署在移动设备上的可行性。
