局部差分隐私约束的链接攻击保护*
2019-02-13杨高明方贤进肖亚飞
杨高明,方贤进,肖亚飞
安徽理工大学 计算机科学与工程学院,安徽 淮南 232001
1 引言
研究机构和互联网公司正在以各种方法收集个人数据,这些数据不可避免地包含个人隐私信息,如果直接发布这些数据将会导致用户隐私信息的泄露[1-2]。如AOL(American Online)曾经发布数据用于竞赛,结果导致一位老年妇人个人隐私泄露[3]。因此,必须在发布之前进行数据净化处理,以保护个人隐私信息。隐私保护的数据发布主要关注数据的微观方面,这种方法把记录的属性分为三类:(1)身份属性(如姓名、身份证号码、微信账号等),其相当于数据库的主键(key),可以唯一地标识个体;(2)准标识符(quasi-identifier,QI)属性(如邮政编码、年龄和性别等),其值的组合可以潜在地标识个体;(3)敏感属性(如所患疾病和收入等),表明个人不想对外泄露的敏感信息。许多研究者已经发现,在发布数据之前仅仅删除用户的身份属性,并不能保护发布数据表中的个人隐私信息[4-5]。QI属性可能被攻击者与其他公共数据集联系起来,获得个人的隐私信息,这被称作数据发布中的链接攻击(link attack),这种攻击主要导致用户身份泄露和属性泄露。如果攻击者可以从发布的数据中识别个人,则会发生身份泄露;而攻击者通过属性链接揭示个人的敏感属性则会发生属性泄露。
为应对链接攻击导致的用户身份泄露和敏感属性泄露,学者们提出了许多隐私保护数据发布模型并试图建立一种通用的隐私保护模型。k-匿名[3]是关系数据库文献中提出的第一个有影响力的模型,它使用泛化(generalization)概念来提供隐私保护,该方法将属性的细粒度值泛化为不特定的粗粒度属性值,以阻止攻击者根据准标识符属性值把具体的个人与其他k-1个体区分开来,其核心思想是确保至少k条准标识符属性值相同的记录在同一个组内。后来,学者引入l-多样性[6]来解决k-匿名存在的限制,以抵御身份泄露和属性泄露,使攻击者无法实现同质攻击或背景知识攻击。t-closeness[7]进一步优化了多样性的概念,并要求每个等价类的敏感值的分布与数据集的整体分布密切相关,在任何等价类中的敏感属性的分布接近整个表中属性的分布。以上基于泛化思想提出的隐私保护数据发布匿名化模型并不能完全阻止用户的隐私泄露,后来Dwork[8]提出了差分隐私的概念,确保添加或删除单个记录不会显著影响任何分析结果的输出。差分隐私在交互式的基础上实现隐私保护,其实现机制是添加拉普拉斯噪音或者指数噪音,目前很多研究者在差分隐私方面做了大量工作,取得了丰富的研究成果[9]。
除了以概化为基础的匿名化和以添加随机噪音为基础的差分隐私之外,随机响应方法也被用于发布数据[10-11]。该方法不像匿名化一样将QI属性值泛化为粗粒度值,而是根据一定的概率将原始值扰动为其他值,他们专注于评估将目标个体成功链接到其他记录的风险。如Shen等人[12]假设数据扰动在客户端进行,用户不知道其他用户的信息。他们的工作集中在购物篮数据或一般分类数据的随机化,而不是在链接攻击下研究随机化的隐私泄露。Cormode等人[13]是通过引入经验隐私和数据效用的概念来解决这些挑战,并通过改变每个模型的相应参数来比较传统隐私模型与差分隐私。再者,已有的基于随机调查数据的方法并不能直接用于中心数据的发布,因为随机调查方法的扰动矩阵P由调查者决定,与用户数据无关,而中心数据的方法,其扰动矩阵除了受数据发布者决定之外,还受到数据分布的影响。在前人已有的基础上,Wang等人[14]在理论上证明了随机响应方法实现差分隐私的可行性。
以上采用随机化实现隐私保护主要使用均匀扰动方法,没有考虑数据的分布情况,导致数据的效用和隐私保护之间没有得到很好的平衡[15],本文结合数据分布的情况对数据进行扰动,即考虑扰动准标识符属性又考虑扰动敏感属性,其应用场景主要包括:政府部门或者企事业单位外包数据进行数据分析或者数据挖掘。具体贡献如下:研究了链接攻击下的身份披露和属性披露问题,重点关注攻击者得到用户的准标识符属性以后,成功预测目标个体敏感属性值的风险;提出了一个随机化技术实现局部差分隐私的框架,系统地研究了随机化方法防止链接攻击的策略,有效解决了随机化方法实现局部差分隐私参数P选择问题,在数据集满足隐私保护要求的同时,最大化数据效用。最后,使用UCI机器学习库的Adult数据集进行了广泛的实验,利用数据分布(KL-散度、卡方距离)有效验证了数据的分布变化情况。
2 基本概念
设数据库DB具有N条记录,每个记录具有m+1个属性,其中A1,A2,…,Am是m个准标识符属性,S是敏感属性。属性Ai(S)具有di(ds)个不同的值,用0,1,…,di-1(ds-1)表示,并使用Ωi(Ωs)表示Ai(S)的域,Ωi={0,1,…,di-1},ΩQI=Ω1×Ω2×…×Ωm是准识别符的域,Ωs敏感属性的域。对于给定的个体,准标识符属性值对攻击者是透明的,其中S表示敏感属性,其值不应与攻击者需要识别的个人相关联。一般而言,数据库DB也可能包含其他属性,这些属性既不是敏感属性也不是准标识符属性,它们通常在发布的数据中保持不变。由于这些属性不会导致隐私泄露风险或数据效用损失,此处将不讨论它们。另外,本文主要讨论单敏感属性,而多敏感属性可以在现有讨论的基础上推广。
随机响应实现局部差分隐私的基本思想主要是:(1)对每一个准标识符属性Ak,选择属性转换矩阵(2)使用概率2,…,dk)随机改变原始属性值为扰动属性值,使之满足局部差分隐私要求,此处表示第k个属性的第i个取值与之类似。随机化过程根据每个记录的属性独立执行,即执行随机化过程不考虑记录之间的关系,与朴素贝叶斯网络类似,假设各个属性之间的关系独立,而记录的属性之间的关系若不独立则需要另行考虑。确定随机化矩阵以后就可以生成扰动数据,数据接收者根据扰动数据和扰动矩阵可以取得数据的统计特征,以及进行数据分析或者挖掘工作。
2.1 失真矩阵选择
使用随机化方法对数据进行隐私保护主要是寻找失真矩阵,它确定随机数据的隐私和效用,如何找到具有隐私或效用约束的最优失真矩阵是一个具有挑战性的问题。Huang和Du[16]应用一种进化多目标优化方法,从单个属性的整个搜索空间中搜索最优失真矩阵。然而,由于其高度的复杂性,该方法难以处理多个属性。目前的随机化矩阵主要是均匀随机化及其变种。它们将每个QI属性Ai(或敏感属性S)的随机化参数限制为:
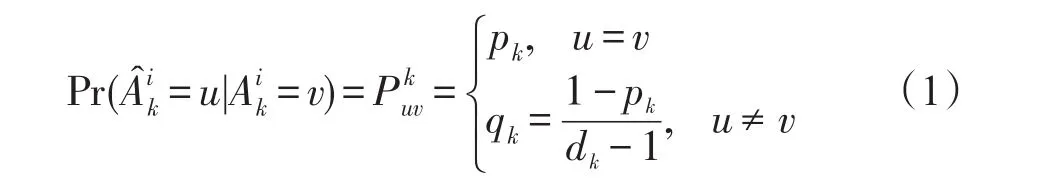
换句话说,对于每个属性Ak的所有值,其以相同的概率pk保持不变,以概率qk被扰动到其他值。这种扰动方法主要缺点是不能反映数据的分布情况,导致数据效用下降。为解决这个问题,提出考虑原始数据分布的解决方案。
前面已经介绍了随机响应的基本思想,下面介绍随机响应的基本过程。对于每个记录Ri,i=1,2,…,N,数据所有者使用失真矩阵Pk独立地随机化属性Ak,k=1,2,…,m。具体来说,对于具有dk个值的属性Ak,随机化过程将属性值以一定的概率替换为为方便起见用表示第k个属性值为v转换为值u的概率,即有:

式中,i,j=1,2,…,dk。令,则Pk称为Ak的失真矩阵,Pk的列总和等于1。对于敏感属性,其处理方式与准标识符属性一样。运用失真矩阵,可以把原始数据库DB扰动为,然后发布随机数据集和失真矩阵P。数据发布者发布失真矩阵,是为了让数据分析人员了解原始数据的随机化大小,帮助数据分析人员估计原始数据分布。
2.2 局部差分隐私
数据的隐私需求有两种不同的上下文环境:局部隐私场景,如个人在社交网站主动披露个人信息;全局隐私场景,如机构发布包含个人信息数据库或基于这些数据库回答某些问题(例如,美国政府发布人口普查数据,Netflix公司等发布专有数据供他人数据分析)。对于这两种情况都可以通过在发布数据之前将数据随机化来实现差分隐私。本文主要研究局部隐私情况,该模式的数据提供者不信任数据收集者或者数据分析师。
隐私保护的主要目的是使攻击者在净化数据上推理得到与原始数据几乎相同的结果,同时使用户的隐私信息得以隐藏,差分隐私就是在这个概念的基础上产生的。在差分隐私模式下,即使攻击者具有无限的计算能力并且可以访问数据库中除查询数据之外的每个记录,也不能确定某个特定用户是否在数据库中。由于差分隐私具有理论基础的支持,得到了广泛研究和应用,最近,差分隐私的概念已经扩展到局部隐私环境[17]。实际上局部差分隐私可以看作全局差分隐私的特例,即敏感度为1的情况。
定义1(局部差分隐私)设有n个数据记录,Ak是数据集DB的第k个属性,其转换矩阵为Pk,k∈{0,1,…,m}。机制 M 是将 Ak∈ΩAk随机映射到ΩAk阈值内的任何一个值,且ΩAk内每一个阈值独立同分布。对于非负数值ε,如果机制M是ε-局部差分隐私的,则有:

ε越小隐私保护效果越好,然而当多次查询,耗尽ε则会导致隐私泄露,故ε的选择也需要根据实际情况确定。
2.3 数据效用及度量标准
隐私保护的数据发布除了满足不泄露用户隐私信息之外,还要满足数据分析者对数据效用的要求。发布数据的最终目标是最大限度地保留数据效用,同时降低属性披露的风险,任何数据集的效用,无论是否随机化,都会依赖于可能执行的任务。有许多数据效用的度量标准,匿名化使用的效用度量标准之一是数据泛化高度,它是指数据泛化步骤的总数。然而,在隐私保护的数据发布领域这种方法存在的问题是:对泛化高度相等的两个匿名化组,其数据效用差距巨大。鉴于目前许多数据挖掘应用与数据的概率分布有关,在评估数据库的效用时,本文采用KL-散度、卡方度量数据的效用。
KL-散度(Kullback-Leibler divergence)是离散概率分布P和Q之间的对数差,用于找到两个频率分布之间距离的度量,此处用于查找原始数据的分布与随机化后的数据相同属性分布之间的距离,即它表示当原始数据集变换为扰动数据集之后其分布信息的丢失量,其计算公式如下:
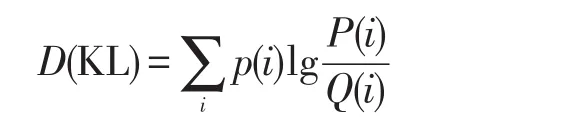
除了采用KL-散度量化数据效用,文中还采用卡方距离比较原始数据和重建数据之间的分布差异,即统计样本的实际观测值与理论推断值之间的偏离程度,其决定卡方值的大小。卡方值越大,原始分布与扰动分布的差异越大;卡方值越小,原始分布与扰动分布的差异越小,若两个值完全相等时,卡方值就为0,表明理论值完全符合。给定两个分布P=(p1,p2,…,pm),Q=(q1,q2,…,qm),其卡方距离如下:
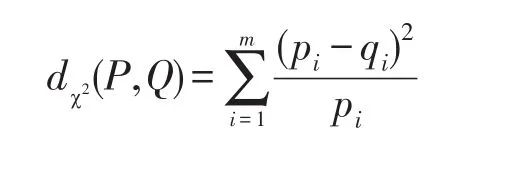
3 属性披露和链接攻击
确定随机化概率转换矩阵Pk以后,攻击者将观测值视为Ak的真实值是不合理的。相反,攻击者可以根据观察到的数据和发布的随机参数来尝试估计原始值。假设攻击者能够得到扰动数据集及后验概率,并采用以下概率扰动策略:对于任何u,v∈ΩAk,在概率情况下计算其中表示当攻击者观察时,而实际原始值Ak=u的后验概率。由贝叶斯定理可以得到以下计算公式:
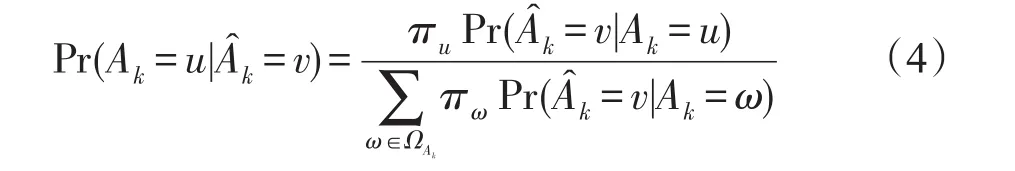
式中,πw表示Ak=ω时的概率分布。下面,分别对二值属性和多值属性进行讨论,并进一步讨论其组合。
3.1 二值属性随机化矩阵的构造

这种扰动方式要求每列的概率和为1,在随机响应相关文献中,一般设pu=pv。为有效地增加数据的随机性和提高数据的效用,此处采用双重扰动的方式。首先,计算二进制属性的每一个属性的值在数据集中所占的比例,分别为pu、pv,并根据给定的隐私保护参数ε计算出pu、pv与ε的关系。第一次扰动根据原始取值进行扰动,比如要扰动的数据值为u,则生成随机函数,并把随机函数以pu为界分为两部分,若随机值位于[1,pu],则扰动值保持不变;若随机值位于(pu,1],则需要第二次扰动。每一步扰动都要根据它们在数据分布中的占比,并考虑隐私保护参数ε,具体过程见算法1。二值属性得到的扰动矩阵PBB为:
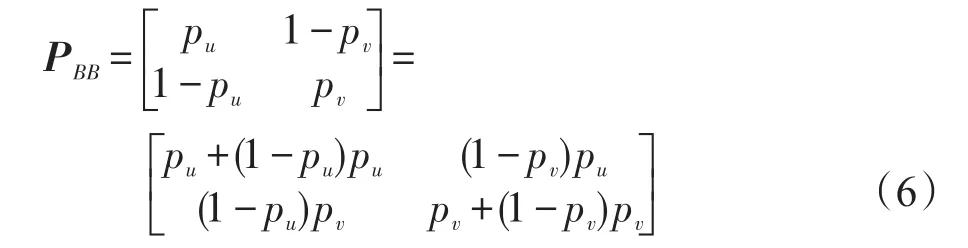
对于二进制属性,一般采用均匀扰动,这种扰动方法把对角线元素设为p,0.5<p≤1,该方法的优点是可以排除离群点对数据的干扰,缺点是所有数据均匀出现,违反了数据的自然规律,鉴于此,本文提出使用数据的原始分布作为随机扰动基础,并在随后的实验中分析该方法对离群点影响。下面给出二值扰动的基本方法。由于二值属性仅仅有两个值,可以分别用u和v表示。若u在原数据集中所占的比例为pu,则v所占的比例为1-pu。即采用的扰动矩阵PB为:
式中,puv=P(u|v),表示原始值为v扰动为u的概率。Geng等人[18]已经理论证明了局部差分隐私的最优形式是采用楼梯机制(staircase mechanism),因此,此处令属性值保持不变的概率为puu=pvv=eε(1+eε),则pv=1-pu=1(1+eε),带入式(6),可得:
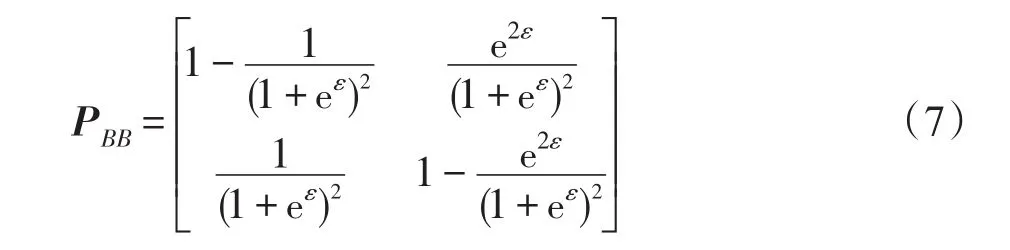
算法1二值属性扰动算法


算法1的行1主要对数据集进行统计工作,用于计算随机扰动方法是否满足局部差分隐私,行3是为了确保数据分布倾斜情况下满足差分隐私要求,行4~8用于处理属性Ak=u的情况,行9~11用于处理Ak=v的情况。对于这两种情况,都需要根据数据的原始分布状态进行二次扰动。
下面讨论采用PBB扰动矩阵的数据集,是否满足局部差分隐私的要求。根据局部差分隐私的定义,此处仅仅讨论给定ε的值大于或等于0的情况。另外若由pu计算得到的ε′>0.5ε,则令ε′=0.5ε,因此仅需讨论ε取最大值的情况。
(1)属性值u扰动为u的概率为puu,扰动为v的概率为pvu,由pu计算出ε′满足:
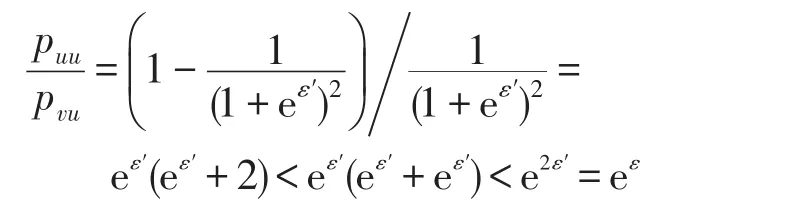
由算法1行3知,ε′≤ 0.5ε,故puu/pvu≤ eε满足局部差分隐私。
(2)属性值v扰动为v的概率为pvv,v扰动为u的概率为puv,则有:
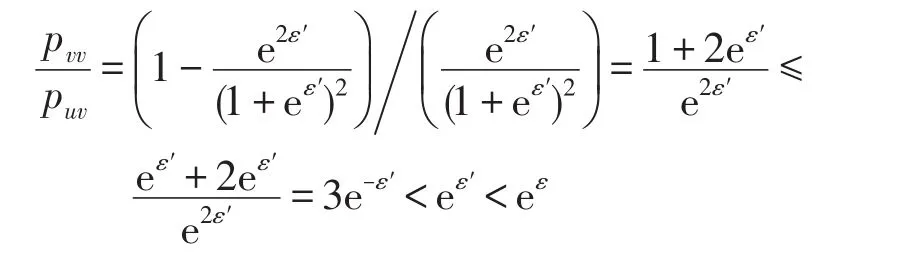
故pvv/puv满足局部差分隐私。
3.2 多值属性随机化矩阵的构造
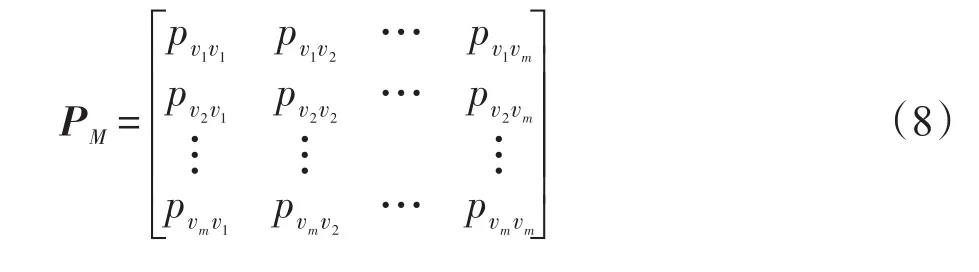
设属性Ak具有m个属性值,分别用v1,v2,…,vm表示。若Ak=vi(i=1,2,…,m)在原数据集中所占的比例为pvi,则采用均匀扰动有Âk=vj(j=1,2,…,m),由此得扰动矩阵PM为:的比率pvi,把随机函数以pvi为界分为两部分,若随机值位于[0,pvi],则扰动值保持不变;若随机值位于(pvi,1],则需要第二次扰动,这时仍根据它们在函数中的占比进行扰动,即扰动时考虑它们在原始数据集的分布情况,具体过程见算法2。此时得到的扰动矩阵PMB为式(9)所示:
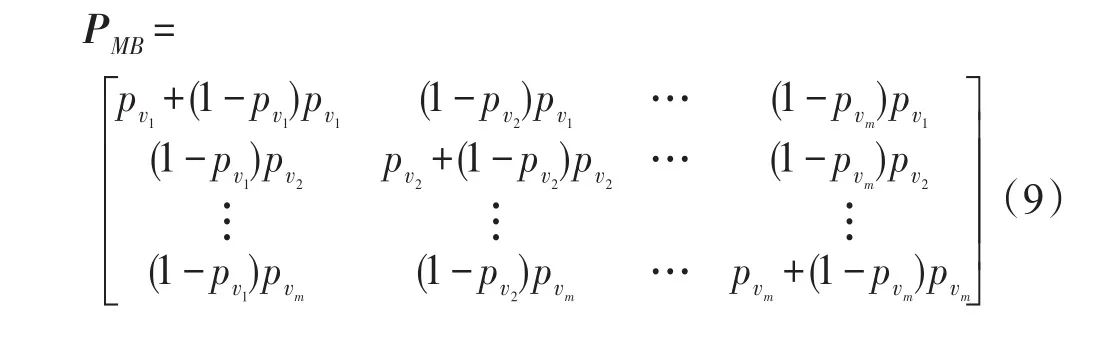
与二进制属性的处理方式一样,多值属性也采用两次扰动的方式。首先,计算多值属性的每一个值在数据集中所占的比例,设为pvi,i=1,2,…,m,并根据差分隐私参数ε计算它们之间的关系。第一次扰动根据原始取值进行扰动,需要扰动的数据值vi所占
式中,pvivj=P(vi|vj),i,j=1,2,…,m,表示原始值为vj扰动为vi的概率,与二值属性相似,此处令pvi=eεi/(1+eεi),i=1,2,…,m,带入式(9)可得:
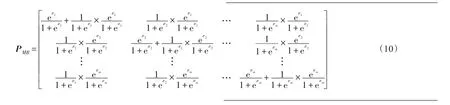
算法2多值属性扰动算法


算法2的行1用于统计属性Ak的每一个值所占的比例,行2、3用于设置满足局部差分隐私的随机扰动概率,行4~10用于处理属性每个值的扰动。
下面讨论采用PMB扰动矩阵的数据集,是否满足局部差分隐私的要求。
(1)属性值vi扰动为vi的概率为pvivi,扰动为vj的概率为pvivj,i,j=1,2,…,m,设由pvivj计算得到的差分隐私参数为ε′,则有:

式中,取ε=2 ln 4随机扰动即可满足局部差分隐私。
(2)属性值vi扰动为vj的概率pvjvi,扰动概率为pvkvi,i,j,k=1,2,…,m,则有:
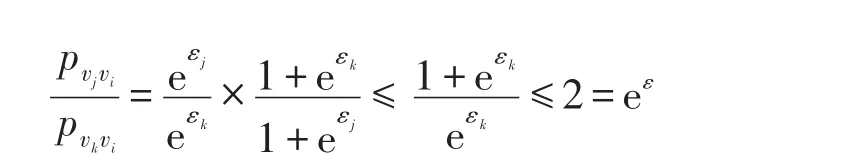
式中,ε大于等于1即可满足局部差分隐私。
3.3 多值属性的保护
隐私保护的数据发布没有统一地衡量隐私泄露标准,常用属性披露风险衡量隐私泄露。假设攻击者的目标个体是r,准标识符属性为QIr,则成功预测Sr的概率为Pr(Sr|QIr)。若攻击者可以访问发布数据集了解数据集每个属性的取值域,由其他渠道获得目标个体r(例如Alice)的QI值并且确定目标个体在已发布的数据集中,但不知道发布数据中的哪个记录属于目标个人。对数据发布者来说,可以选择是否发布失真矩阵PBB或PMB,若数据发布者为了让分析人员更有效地分析数据,则可以选择发布失真矩阵PBB或PMB。
设πi=P[X=ci],i=1,2,…,k,π=(π1,π2,…,πk)T,n表示数据集的个数,Ti表示原始数据集中值为ci的属性个数,Si表示扰动数据集中值为ci的属性个数,λi=P(Z=ci),λ=(λ1,λ2,…,λk)T则有概率分布T=(T1,T2,…,Tk)T,S=(S1,S2,…,Sk)T,于是T~Mult(n,π),S~Mult(n,λ),此处λ=Pπ。需要注意的是数据发布者并不发布T1,T2,…,Tk,对数据分析者而言仅仅从扰动的数据无从得知它们,因此π的值不能直接求得,只能由T的观察值S求得。如果P是非奇异矩阵,̂是λ的无偏估计,则̂是π的无偏估计。λ的最大似然估计是则有:

π的无偏估计方差为:
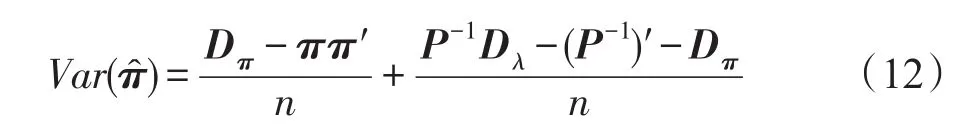
式中,Dπ是对角矩阵,其对角元素为π1,π2,…,πk,Dλ的定义与Dπ类似。等式(12)的右边第一项是数据集固有方差,第二项是随机化导致的额外附加方差。
3.4 随机扰动的基本模式
数据集的属性分为敏感属性、准标识符属性和其他属性,攻击者很容易根据原始数据集中准标识符属性QIr推导出个体r的敏感属性。为增加数据的不确定性、同时最大限度地保持数据效用,下面针对敏感属性、准标识符属性以及它们的组合讨论随机化问题。
敏感属性随机化(randomized response sensitive,RRS):当数据所有者仅对敏感属性随机化时,攻击者使用观察到的敏感值和等式(4)估计其敏感值。正确估计的概率是那么敏感属性披露风险为
这种情况针对攻击者知晓用户身份,有效保护用户敏感信息,主要处理用户身份不敏感的场合。
准标识符属性随机化(randomized response QI,RRQI):当数据所有者仅对准标识符属性进行随机化时,正确重构QIr的概率由给出,因此敏感属性披露的风险为其具体推导过程由下文等式(15)给出。
两种属性组合随机化(randomized response both attributes,RRB):当数据所有者同时随机化QI和S时,攻击者首先需要正确重构准标识符属性值,其概率由给出,另外攻击者还需要在正确重构准标识符属性值以后重构敏感属性值。这种隐私泄露情况与随机化准标识符属性类似,不再详述。
下面对RRS、RRQI和RRB中敏感属性披露风险进行总结,并给出随机化属性披露风险的一般计算:假设个体r具有准标识符属性QIr=α={i1,i2,…,im},ik∈Ωk,它的敏感属性Sr=u,u∈ΩS。给定目标个体r的准标识符属性值QIr,成功预测其敏感属性值Sr的概率是:
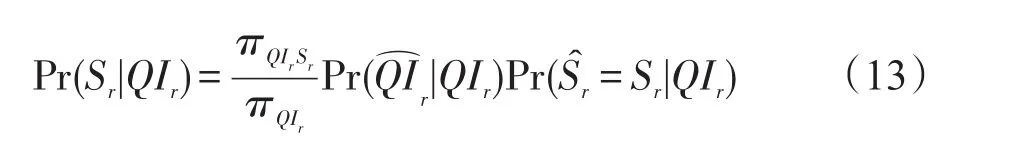
等式(13)中计算Pr(Sr|QIr)所需的重建概率表达式,其准标识符的重构概率由下式给出:

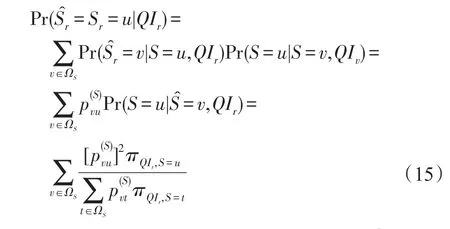
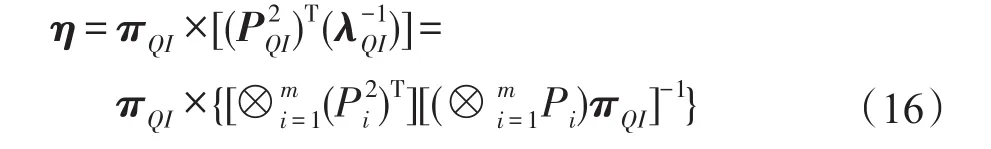
4 实验评估
4.1 实验设置
实验采用UCI机器学习数据集,该数据集包含48 842个记录的美国人口普查数据,共有14个属性。此处选取 education、maritial-status、occupation、native-country、workclass这5个属性,其中workclass作为敏感属性,其余属性作为准标识符属性。实验中利用KL-散度和χ2来测量原始敏感值分布和净化数据集之间的距离,同时还验证程序执行所需时间,检验数据量增长对运行时间的影响。为消除概率波动对实验数据的影响,每个实验运行11次,目的是验证随机化算法的稳定性。
4.2 实验数据分析
一般情况下准标识符属性和敏感属性之间存在相关性,为减少相关性的干扰,在选取属性值的时候进行了属性相关性分析,选取的5个属性相关性较小,即假设属性之间具有独立性。为表示方便,把本文的算法称为RRPP(randomized respond to achieve privacy preserving)。
隐私保护数据发布的目的是最大限度地减少信息损失和最小限度地泄露隐私信息,为达到度量这两方面的目的,此处使用KL-散度和χ2来度量原始数据和扰动数据之间的距离,其结果如表1、表2所示,其中表1是1次随机响应运行结果,表2是10次运行取平均值的结果。原始数据和扰动数据之间的距离值越小,它们之间的差异越小,失真数据库的效用越好。由表1和表2可以看到,在所有3个随机化情景中,以KL-散度和χ2作为距离差异的效用损失在概率扰动和均匀扰动之间的差异(此处均匀扰动转移概率取p=0.60,p=0.75,p=0.90)。表中数据显示,采用RRPP方法比均匀扰动可以更有效地保留数据的效用,减少用户信息的泄露。对均匀扰动来说,取p=0.90,攻击者推测出用户的敏感信息已经非常大了。另外,由表1和表2的平行数据对比中可以看出,算法的1次运行结果和10次运行结果的平均值差异很小,说明了算法较稳定。
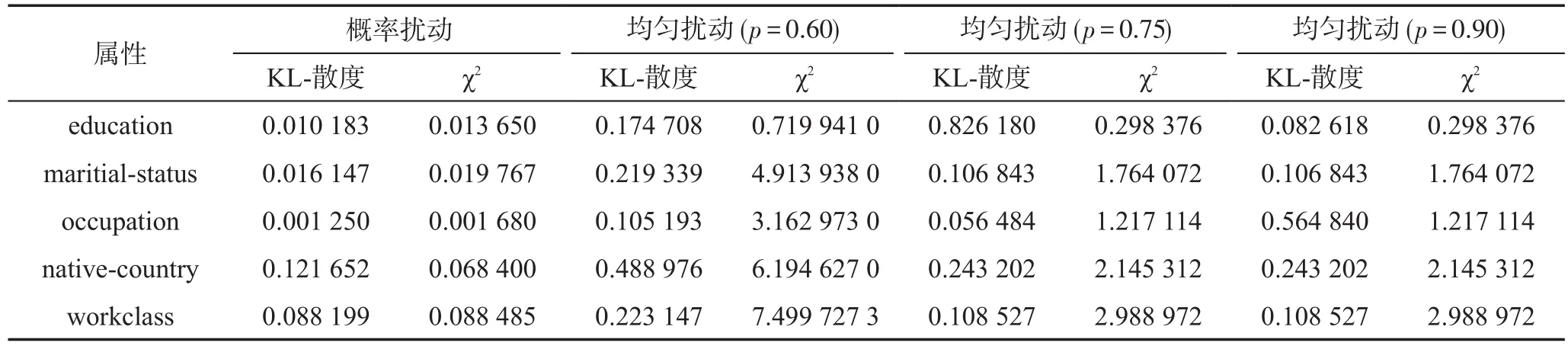
Table 1 Distance of original and perturbed dada(one time)表1 原始数据与扰动数据的距离(1次)
由于小概率事件可以视为不可能事件,这会导致采用RRPP算法扰动时发生属性丢失现象。在后10次实验中,有3次发生native-country属性中Holand-Netherlands属性值丢失,1次发生Ireland属性值丢失。而采用均匀扰动p=0.60,p=0.75,p=0.90均没有发生属性值丢失现象。这可以解释为RRPP算法对离群点具有一定的鲁棒性。

Table 2 Distance of original and perturbed dada(ten times)表2 原始数据与扰动数据的距离(10次)
表3是RRPP与均匀扰动p=0.60,p=0.75,p=0.90的运行时间,该时间包括扰动、计算KL-散度、计算卡方的时间。之所以没有把扰动的时间单独测量,主要是为了验证扰动和进行数据分析的时间是否可以接受。为了解算法的效率,采用执行10次算法取平均值的方式度量运行时间。对于RRPP算法其最小值为28.571 12 s,最大值为39.804 41 s。p=0.6时,运行时间的最小值为22.012 51 s,最大值为35.628 62 s,p=0.75和p=0.90其运行时间波动较小。由运行时间的对比可以看出,RRPP算法与均匀算法的运行时间处于同一个数量级。

Table 3 Running time ofAdult data set表3 Adult数据集运行时间 s
为验证数据增长时扰动算法的有效性,针对每个属性以增量的方式验证其距离,横轴表示增量,纵轴表示KL-散度和χ2,参与扰动的元组数分别为1 000、2 000、4 000、8 000、16 000、32 000,这些数据是均匀抽样所得。属性分别取敏感属性workclass和准标识符属性education(对所取的5个属性都进行了验证,由于篇幅关系,此处仅选取两个属性作为说明)。与验证Adult数据集全部数据类似,执行算法11次,图1(a)是敏感属性值个数递增workclass的KL-散度1次运行结果,图1(b)是敏感属性值个数递增workclass的χ2距离1次运行结果;图2(a)是敏感属性值个数递增workclass的KL-散度10次运行取平均值的结果,图2(b)是敏感属性值个数递增workclass的χ2距离10次运行取平均值的结果。由图1和图2可以看出RRPP算法与均匀扰动p=0.90的结果相近,说明算法可以很好地保护用户隐私和提供有效的数据效用。图1的数据波动性较大,而10次运行结果取平均值则基本没有大的数据波动。另外,无论RRPP算法还是均匀扰动在数据量较小时,其数据波动性较大,说明随机响应方法需要用于数据量较大的场合。

Fig.1 Distance of workclass betweenπ andπ̂(one time)图1 敏感属性workclass的π和π̂之间的距离(1次)

Fig.2 Distance of workclass betweenπandπ̂(ten times)图2 敏感属性workclass的π和π̂之间的距离(10次)
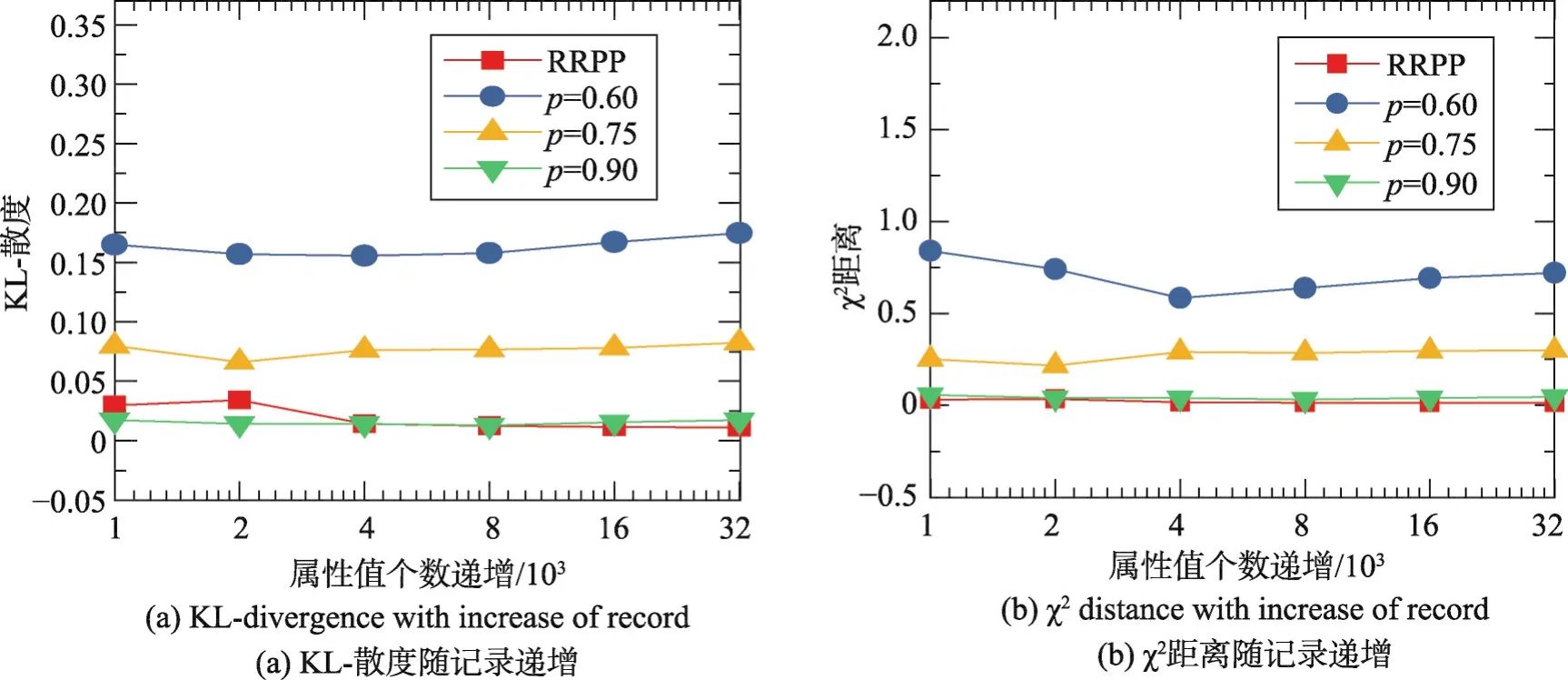
Fig.3 Distance of education betweenπandπ̂(one time)图3 准标识符属性education的π和π̂之间的距离(1次)
图3(a)准标识符属性education递增时的KL-散度1次运行结果,图3(b)是准标识符属性education递增时的χ2距离1次运行结果。图4(a)准标识符属性education递增时的KL-散度10次运行结果,图4(b)是准标识符属性education递增时的χ2距离10次运行结果。它们的结果与workclass基本相同。
由图2和图4可以看出,属性不同,扰动数据与原始数据之间的KL-散度差别不大,而χ2距离却比较明显,比较图2(b)和图4(b),可以明显看出敏感属性workclass和准标识符属性education的χ2距离有所差别。不过,无论KL-散度还是χ2距离,都在一个数量级。
由图1至图4可以看出敏感属性个数的增加对KL-散度和χ2影响很小,特别是数据量达到2 000以后,基本上处于非常稳定的状态。另外,在记录很少的情况下有时会发生属性值丢失现象,即对那些在总体中比率很小的属性值在扰动时发生丢失。比如在增量实验时,使用平均扰动方法,几乎不发生属性值丢失现象,因此离群点得以保留,这会导致离群点表示的用户隐私泄露。而RRPP方法则可以剔除离群点的影响,在对native-country属性进行扰动过程中发生了从少数国家或地区移民美国的公民其属性值丢失(在数据量等于1 000时,属性值丢失严重),被大概率的属性值取代,这样会导致数据失真,但是保持了用户的隐私。

Fig.4 Distance of education betweenπ andπ̂(ten times)图4 准标识符属性education的π和π̂之间的距离(10次)
5 结束语
针对均匀扰动的隐私保护数据发布没有考虑数据的原始分布问题,提出一种根据数据的原始分布对发布数据进行随机扰动的方法,并详细讨论了二进制和多值属性扰动矩阵参数设置,以及扰动矩阵满足局部差分隐私的条件,最后设计实验予以验证,并对实验结果进行讨论。实验结果表明,考虑数据原始概率情况下进行随机化扰动显著优于均匀扰动方法,相当于均匀扰动p=0.90的情况。实验结果表明,基于数据原始分布的随机化方法可以更好地保持原始数据集的分布特性,在数据效用和披露风险方面具有较好的效果。然而,文中还有不完美的地方,主要是假设数据属性之间关系独立性,实际上属性之间存在千丝万缕的联系,下一步将对准标识符属性之间存在强依赖关系时如何扰动进行研究,以更好地维持数据效用,保护用户的隐私信息。
