基于卷积神经网络和上下文模型的目标检测
2019-01-29公安部第一研究所马增妍
■ 文/公安部第一研究所 马增妍
关键字:卷积神经网络 R-CNN NMS 上下文模型
1 引言
中国的安防产业起步晚,改革开放以前,中国的安防主要以人防为主,安全技术防范还只是一个概念,技术防范产品几乎还是空白。改革开放以后,在公安信息化的大背景下,随着大数据,人工智能等技术的快速发展,以深度学习算法为核心的安防产品已经初步应用于公安一线,目标检测算法是深度学习的重要分支。R-CNN算法是目标检测的经典算法,但是R-CNN算法在图像后处理阶段,采用的是NMS算法。NMS算法存在两方面的缺点:一方面,如何选择合适的阈值是一件困难的事;另一方面,没有考虑图像中物体与物体之间的共存与空间位置关系。
文献中提出了用上下文模型来统计一幅图像里面总是同时出现的目标之间的空间位置关系,从而有利于目标更准确的定位。文献中是在浅层网络的图像特征提取之上进行的上下文模型训练,因此,我们把上下文模型运用到深层网络的图像特征提取之上,进一步提高目标检测的正确率。
本文主要把上下文模型和R-CNN算法结合起来,在R-CNN算法的最后一步,即经过SVM分类器分类之后,把候选窗口的信息保存下来,并对其应用训练好的上下文模型,我们采用割平面方法来学习上下文模型中的参数。该模型给每一幅图像,依据各个候选窗口的SVM分数以及它们的空间布局,定义了一个总分数来刻画物体间的共存与空间位置关系,最优候选窗口的布局就是最大化图像所对应的总分数,本文采用了贪心优化算法来选择最优候选窗口。这种结合既避免了NMS算法的缺点,又避免了文献中对图像信息进行浅层特征提取的不足。
2 R-CNN算法
R-CNN算法在图像预处理方面采用的是选择搜索算法,在特征提取方面,采用的是八层卷积神经网络,其中前五层是卷基层,后三层是全连接层。八层网络的所有卷积层的卷积核被连接到第二个卷积层中的所有核映射上。全连接层中的神经元被连接到前一层中所有的神经元上。网络的前五层为卷积层,其中第一层、第二层、第五层之后跟有最大池化层,之后三层是全连接层,最后是一个有21个(20PASCAL VOC类+1个背景类)输出的softmax层,输出图像的分类结果。局部响应归一化层跟在第一、第二个卷积层后面。最大池化层是在局部响应归一化层之后以及第五层卷积层之后使用的。ReLU激活函数是在每一个卷积层和全连接层中使用的。
3 上下文模型
3.1 上下文模型的介绍
该模型主要是统计了真实图像中目标之间的空间位置关系,从而确定目标最优的位置,进而提高目标检测的正确率。在现实生活中,无论目标是同类别还是不同类,都会有一些经常出现的空间位置关系和一些几乎不可能出现的位置关系。比如“人”和“马”这两类物体,它们之间的空间位置关系有很大的可能是“人”骑在“马”上,即“人”在“马”上面(above),或者“人”在“马”的旁边(next-to),很少会出现“人”在“马”下面(below)这种空间位置关系。再比如“人”和“人”这种同类别的目标,他们所组成的空间位置关系一般都是“人”在“人”的旁边(nextto),很少有“人”在“人”上面(above)的,或者“人”在“人”下面(below)的空间位置关系。因此,如果我们能够统计出这种共同出现在一副图像里面的物体之间特有的空间位置关系,那么就会对目标检测的正确率有一定的帮助。本论文统计了这种现实生活中物体之间特有的空间位置关系,从而构造了一个上下文模型,定义了如图1所示的几种空间位置关系,分别是上面(above)、下面(below)、两个对称的旁边(nest-to)、近(near)、远(far)、覆盖(overlap):
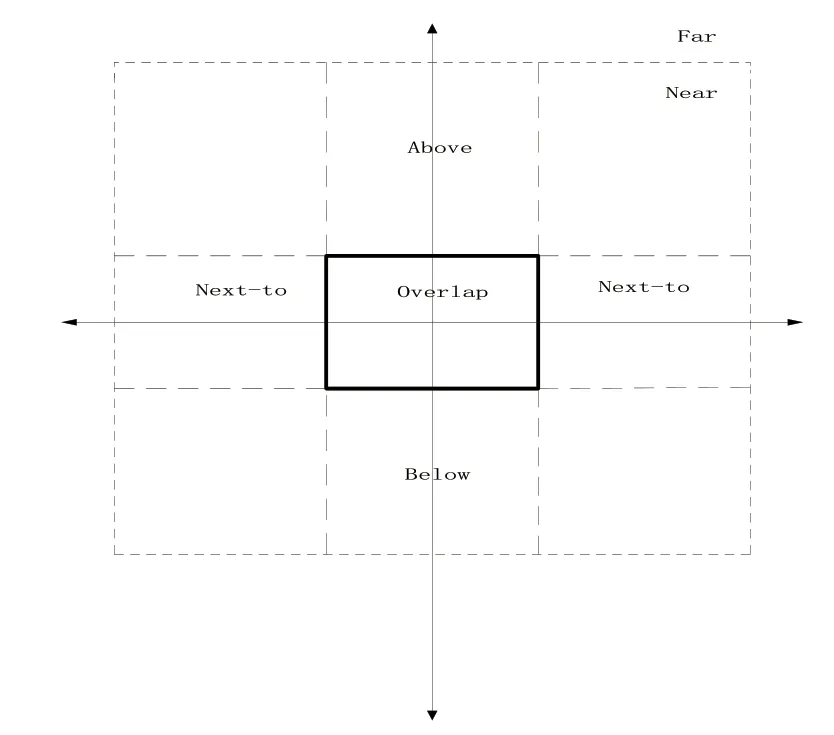
图1 位置关系
3.2 上下文模型的构造
首先构造一个上下文模型,用于捕获目标检测器之间的存在空间位置关系。用一系列有重合的窗口明确表示一幅图像(本论文是一幅图像经过线性SVM分类器之后的所有候选窗口),第i个窗口的位置用其中心和长宽表示,写作Ii=(x,y,s),其中(x,y)是中心的坐标,s是窗口的尺寸,N表示一幅图像有N个窗口,xi表示从第i个窗口提取的图像特征,整幅图像就可用X={xi:i=1,……N}表示,K代表图像类别个数(本论文所用的是PASCAL VOC 2011数据集,所以K为20),yi∈{0,……,K}代表了第i个窗口的标签,0表示背景,那么Y={yi:i=1,……N}。定义X,Y之间的分数,用公式(1)表示:
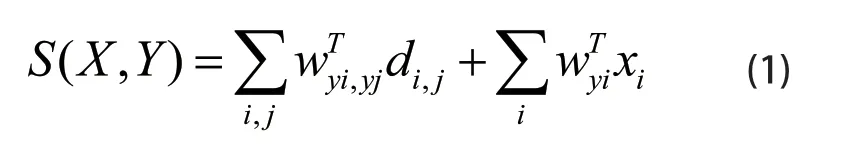
其中wyi,yj表示yi类和yj类之间的权重,wyi表示类i的局部模板,dij表示窗口i和窗口j之间的空间位置关系,位置关系可分为:上面(above)、下面(below)、重叠(overlap)、两个对称的旁边(next-to)、近(near)和远(far),还有一个二进制的(overlap)。因此dij是一个稀疏的一维向量,只有满足相互之间的空间位置关系的对应项会赋值为1。比如,一副图像中“人”与“人”之间的空间位置关系是旁边(next-to),不是上面(above),也不是下面(below)。那么,上面(above)、下面(below)及其他位置的对应项赋值为0,而给旁边(next-to)赋值为1。
3.3 上下文模型的推理
利用上下文模型进行最优候选窗口的选择,就是计算出公式(1) S(X,Y)的最大值,因为计算S(X,Y)的最大值是非确定性多项式NP(non-deterministic polynomial) hard,所以本论文采用贪心算法(greedy algorithms)的思想来解决这个问题。
算法步骤如下:
(1)对每一个窗口的向量Y初始化为背景类;
(2)贪心地选择不是背景类的单一窗口,即最大限度的增加公式(1)中S(X,Y)的值;
(3) 当选择任意一个窗口,S(X,Y)的值不再增加反而减少时,停止迭代。
用公式表示如下:I代表一系列实例化的窗口-类(window-class),I={pairs(I,c)},记Y(I)代表相关的标签向量,当所有的pairs在集合I中时,yi=c,否则yi=0;通过加窗口-类pair(I,c)到集合I里改变S(X,Y)的值,具体过程用公式(2)表示:
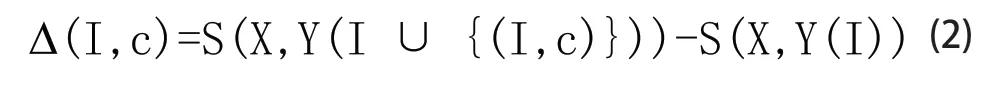

3.4 上下文模型的优化
为了优化上下文模型的学习算法,需要把公式(1)写公式(3)的形式:

公式(3)等价于公式(4)
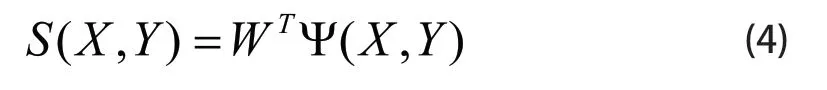
凸训练的目的是假设给定一系列训练图像Xi和标签Yi,希望得到一个W的最优值,使得给定一幅新的图像Xi,可以产生一个标签向量Y*=Yi。因此,凸训练的结果是得到W的最优值,使得Y*和Yi的差值尽可能的小,凸训练得到W最优值的这一过程既是求下列数学公式(5)极值的过程。
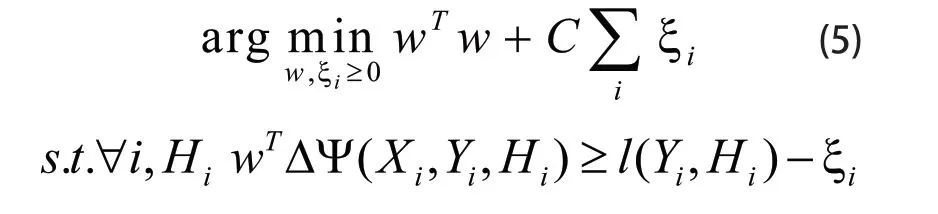
其中:Hi是自己算出的标签,

考虑到第n个训练图像Xi和其真正的标签Yi,我们需要真标签的得分比所有其他虚拟标号{Hi}的更高。然而,并非所有不正确标签是同样程度的不正确,即有的错的多,有的错的少。损失函数L(Yi,Hi)测量Hi是如何不正确,并用松弛变量按比例错的比例惩罚。因此,约束函数如公式(6)所示:

其中,第一行对应的是错误(negative)的窗口,第二行对应的是错误的窗口但是被归类为正确的(positive)窗口了,第三行对应其它情况。
为了方便最优化,把公式(5)的约束问题等价于公式(7)的无约束问题:
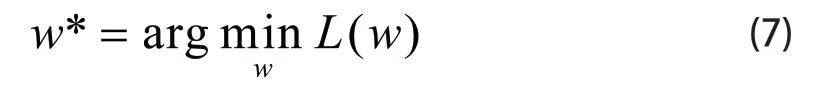
R(w)是凸函数,因为它等于一系列线性函数中最大的值,N是所有的训练图像的总数,因此也证明了目标函数L(W)是凸函数,因为它是两个凸函数的总和。定义一个简化问题(reduced problem),用公式(8)表示:
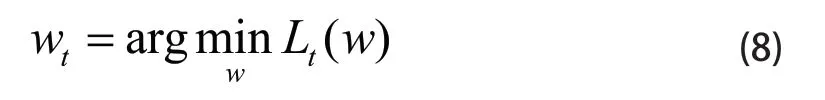
R被近似成了一个分段的线性函数Rt,

g(wi)是函数R(w)在一个点wj的子梯度,用公式(9)表示:

由此,二次规划问题可以写成公式(10)的形式:
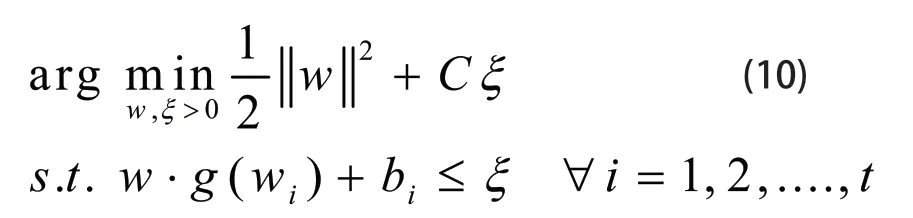
最终,上下文模型的优化就变成解二次规划问题,即求解公式(10),具体的优化过程在第四章给出。
4 在R-CNN中应用上下文模型
在R-CNN中应用上下文模型,即把上下文模型应用在经过线性SVM分类器分类之后图像的候选窗口上。在测试实验之前,首先要学习上下文模型的参数即训练训练上下文模型。
由第3.4小节可知,对于构造好的上下文模型进行割平面(Cutting Plane)最优化,即可得到W的最优值。割平面最优化的过程就是求解二次规划问题,用公式(11)表示如下:
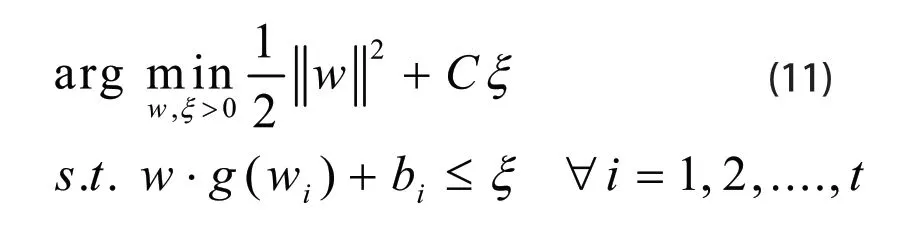
本论文选择的惩罚因子C为2。割平面算法的原理是用有限半个空间来近似凸规划的可行解集合,并求解一系列不断改进的线性规划,它们的最优解收敛于原凸规划问题的最优解。这一方法的基本思想是:每次迭代求函数在某一个凸多面体的极小值,每次迭代后引进一个割面,这个割面是可以随意选择的,从而逐步缩小多面体,促使迭代点收敛至最优解。凸优化过程如下:
(1)初始化t=0,割平面的集合为空,根据第三章公式(3-8),计算wt;
(2)计算子梯度g(wt)并把新的割平面加入到割平面集合中,根据第三章公式(3-7)计算L(wt);
(3)迭代的停止的条件是,本论文把的值设置成0.01,当不满足停止条件时,跳到步骤(2)继续进行优化直到满足停止条件。
5 实验结果与分析
5.1 实验数据及流程
PASCAL VOC是国际权威的物体检测挑战赛,其作为视觉对象的分类识别和检测的一个标准测试,提供了检测算法和学习性能的标准图像注释数据集和标准的评估系统。因此本论文采用的测试数据是PASCAL VOC 2011数据集,大约有6000张图像,20个图像类别。
我们把数据集平均分成两部分,训练集和测试集。本论文遵循PASCAL VOC协议的规则,如果图像检测窗口与该图像的ground truth窗口的交集是大于50%的,其中,ground truth窗口是图像当中已经标注好的检测目标的正确窗口,那么检测被认为是正确的。实验对比了R-CNN算法的测试结果,计算每一个类别的精度-召回PR (Precision-Recall)曲线,和每一个类别的平均正确率,在表1中给出:
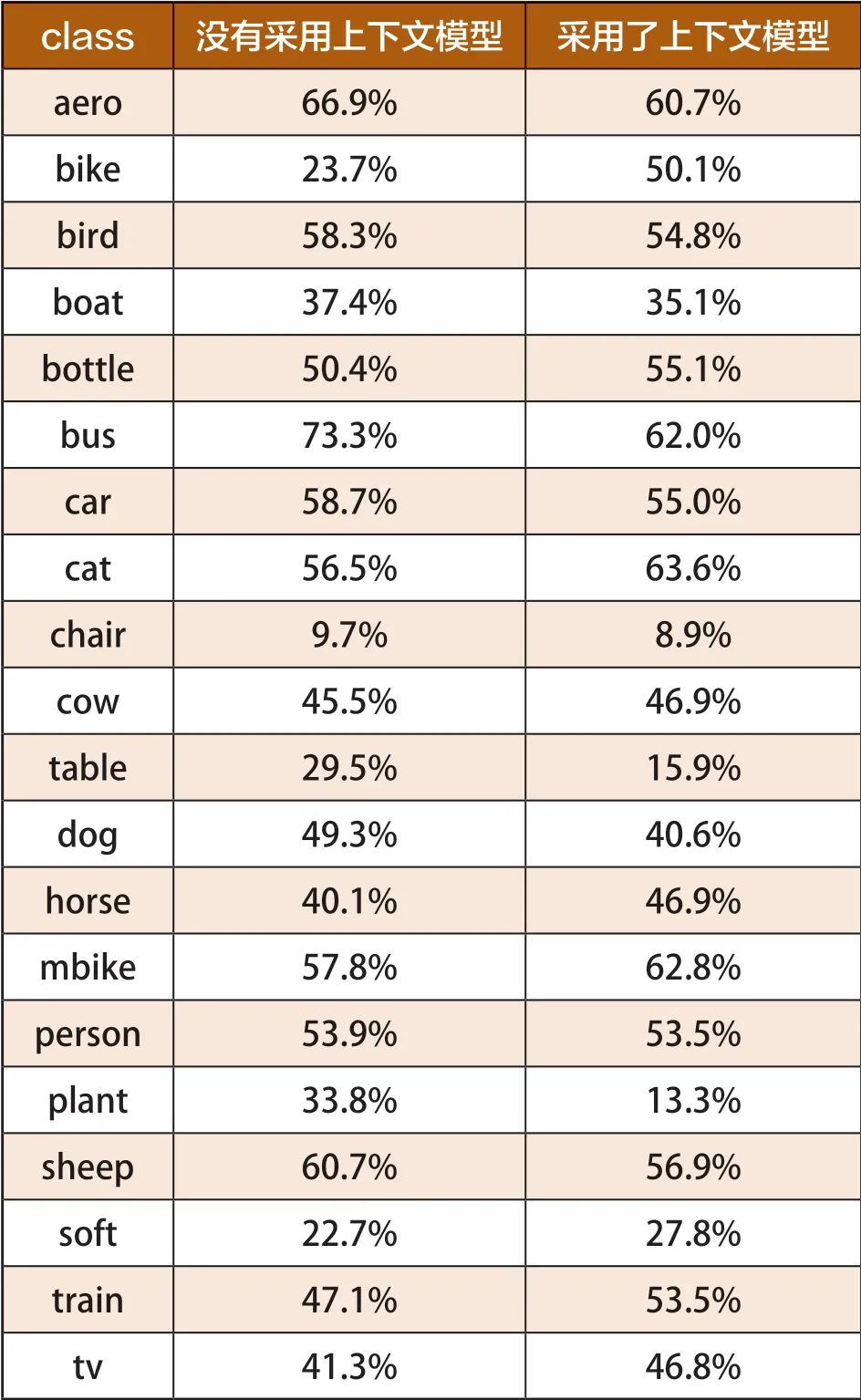
表1 测试结果对比
5.2 实验结果分析
由表1可以看出,具有明显的空间位置关系,并且总是同时出现在一幅图像里面的类别,正确率有了一定的提高,比如“bike”,“horse”,“soft”正确率分别由原来的23.7%,40.1%,22.7%提高到了50.1%,46.9%,27.8%。而和“bike”,“horse”,“soft”有明显位置关系的“person”的正确率出现了微小的下降,从53.9%到53.5%。图2,图5-2分别表示的是,“person”和“horse”,“person”和“soft”的经过线性SVM分类后的所有候选窗口和经过上下文模型选择出的最优候选窗口的对比图。
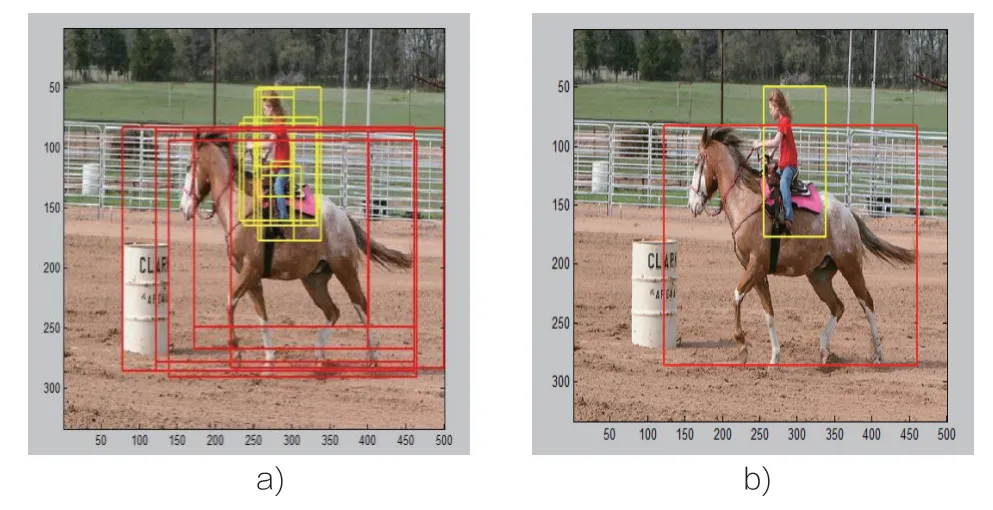
图2 人和马

图3 人和沙发
图2 b)中,可以看到,这是由于“person”和“person”之间的位置关系通常都是“next-to”,所以上下文模型在选定“person”的最优候选窗口时,会优先选择“next-to”的候选窗口,但从图2 b)中可以看出,两个人其实是有重叠的部分的,而由于采用了上下文模型,优先选择了旁边的候选窗口而排除了有重叠的候选窗口,所以,经过上下文模型的学习后选出的最优的候选窗口并不是真正的最优的候选窗口,这个原因,可能导致“person”这个类别的总体正确率有了一点的下降,但是下降的不多,这是因为,测试集中会出现很多和“人”类有空间位置关系的类别,比如“bike”,“horse”等等,它们之间的空间位置关系会提高“person”的目标检测正确率。
对于一些和其他类别没有固定的空间位置关系,总是和自己同类的目标一同出现在一幅图像当中的类别,比如“cat”“cow”“dog”“plant”,它们的正确率并没有提高的很多,有的类别会出现正确率的小幅度下降,这可能是因为上下文模型更适合检测图像里面有多种不同类别目标的情况,而不适合检测一幅图像里面只有一种类别的多个目标的情况,所以正确率提高的不多。由此我们也可以得出,上下文模型更适合于一幅图像中有多个类别的图像检测,文献中也提到,上下文模型在多个类别同时出现在一幅图像上,一些目标容易检测而另一些目标不容易检测的情况下会有明显效果。总体而言,可以看出上下文模型对于数据集中的部分类别的检测正确率有了明显的提高。

6 结论
在公安信息化的大背景下,随着大数据,人工智能等技术的快速发展,以深度学习算法为核心的警用装备已经初步应用于公安安防一线,目标检测算法的是深度学习的重要分支,本文提出来一种新的选择候选框的方法,针对R-CNN算法的缺点,本文提出了一种新的目标检测方法,该方法结合了R-CNN与一个可以描述图像中物体间的共存与空间位置关系的上下文模型,在该上下文模型中,对每一幅图像,依据各个候选窗口的分类分数以及它们的空间布局,定义了一个总分数来刻画物体间的共存与空间位置关系,最优候选窗口的布局应该最大化该分数。实验结果表明,如果属于不同类别的物体经常同时出现在一幅图像中,并且相互之间存在特定的空间位置关系,那么,这些物体对应类别的检测正确率会有明显的提高。
