基于机器学习的高效恶意软件分类系统
2019-01-18李东宝
屈 巍, 侍 啸, 李东宝
(沈阳师范大学 科信软件学院, 沈阳 110034)
0 引 言
近年来,恶意软件技术的不断发展对现代信息技术与个人信息安全造成了极大的威胁,这使得人类对反恶意软件技术的需求日益月滋[1]。2017年5月12日,全球范围内多所高校、企业、政府机构被名为“WannaCry”的勒索病毒攻击[2]。各大反恶意软件厂商紧急采取措施减少损失。但随之而来的“WannaCry”的变种使用多种手段躲避查杀,并且借助新的安全漏洞进行大规模传播。“WannaCry”变种的出现只是一个例子,随着恶意软件技术的发展,其逐渐能够以成熟的技术避开传统的保护机制,成为非法活动的强大工具。
为了躲避检测,恶意软件作者不断修改和混淆原本的恶意软件[3],这是恶意软件数量迅速增长的一个重要因素。根据2017macfee的Q3季度恶意软件报告,Q3季度变种恶意软件数量同比Q2季度增长了约10%。而大量的新变种的出现意味着研究人员需要分析这些大量的样本以寻求应对的措施。被使用不同策略进行修改与模糊处理,看起来各不相同的代码,实际上拥有相似的恶意特征的样本群,称为一个恶意软件“家族”。研究者需要分析新出现的恶意软件样本,发掘和汇总其中的特征。但近几年,大量的新样本使得人工分析的缺口愈加严重。所以将具有相似特征的样本一同分析,可以减轻研究人员的负担,也会更容易发现某一家族的隐含特征。因此恶意软件的分类在恶意软件分析中扮演着重要角色。但在机器学习概念成熟之前,普遍采用人力辅以简单的静态匹配分类。而混淆多态策略会让静态匹配技术的效果大打折扣。近年来,随着机器学习的兴起,越来越多研究者尝试使用机器学习的方式建立分类系统,它具有自动特征提取,和人工干预较少的特点。
1 相关工作
在恶意软件的特征指纹的确定过程中,为了获取和理解其可能的来源和潜在的威胁方向,研究人员需要对一个新的恶意软件样本进行分析和分类。
静态分析指在不运行程序的情况下对程序的分析。在静态分析前研究人员需要尽可能地去除代码中的混淆和加密手段[4],以防止静态特征受到干扰。但是随着恶意软件多态化技术的发展,恶意软件作者开始使用各种多态化方法以回避静态分析[5]。
动态分析指在可控的模拟环境下运行恶意代码,观察其行为,进而确定其意图。与静态分析相比,动态分析无需反汇编,也不需要解密或解压。但由于需要运行,动态分析在消耗上要大于静态分析,且由于模拟环境的模式单一,恶意代码的各个分支难以被遍历。
继Schultz[6]首次将数据挖掘引入到恶意软件的检测中,许多人在这一方面做出了创新和改进工作。Nataraj[7]提出了一种将恶意代码图片化后提取图像特征的机器学习算法;Kong[8]构建了一个以函数调用图为特征的机器学习框架;n-gram被广泛使用在恶意代码检测中[9]。单一的选择某种特征,会忽略掉很多重要的信息,并且如n-gram这样的特征在提取时会占用大量的系统资源,运行速度较慢,因此本文提出了多特征选择融合的方法。
本文提出的方法的主要优点有:
1) 提取数据方便,自动化分类,
2) 使用了恶意软件自身信息作为部分字符串特征,
3) 仅需提取一些简单的特征,实现方法简单,
4) 分类系统误差较小且运行速度极快。
2 基于机器学习的多特征融合的高效恶意软件自动分类系统
本文提出了一种基于机器学习的多特征融合的高效恶意软件自动分类系统,其分类步骤如图1所示。

图1 系统分类步骤Fig.1 System classification steps
2.1 恶意代码表现形式
本文使用恶意软件的字节码和反汇编代码这2种最常见的表现形式作为的数据。
字节码是分析恶意软件的一种常见形式,它易于获取,无需获取样本文件本身,通过一些内存查看工具就可以获得内存中恶意代码的最直接的表现形式,如图2所示。
对于编译型语言而言,反汇编代码是借助反汇编工具,针对编译时的目标代码生成步骤对二进制可执行程序进行逆向工程的产物,其主要表现为汇编语言代码,如图3所示。
图2 十六进制视图Fig.2 Hexadecimal view

图3 反汇编视图Fig.3 Disassembly view
本文使用UPX加壳工具和一些修复检测工具,如UPX Packer、UPXfix等,对大量样本进行了UPX程序壳的简单去除
2.2 特 征
为了达到高性能且高效率的最终目的,本文尝试多种特征并择优使用。这些特征更容表现出恶意软件的体系结构与恶意行为。
2.2.1 文件属性
文件属性(fp)对恶意软件分类非常有用,压缩率可以很大程度上描述文件的类型,本文提取了字节文件与反汇编文件大小和压缩率,并且获取了他们的比值。
图4描述了对于每类家族字节文件压缩率的分布,其中0~8分别代表9类恶意软件家族,颜色较深处为样本集中处。
2.2.2 反汇编文件关键字
在汇编代码中,软件的行为通常由一些代码关键字符或者字符串(key)决定[10]。程序节、操作码、应用编程接口调用和动态链接库在很大程度上描述了一个软件的行为与目的[11],这些属性的数量与分布具有一定的规律,本文统计了他们出现的频率,与其占的比例。
本文还统计了一些特殊字符如@,+,*,?在文件中出现的频率,和一些有意义且与软件行为相关的字符串的频率与其占的比例,其中一部分是从微软Windows Defender Security Intelligenc获取了关于这些恶意软件家族描述中提及的注册表键等字符串。
2.2.3 熵
熵(ent)是信息不确定性的一个测度,熵越大则表示信息的不确定程度越高[12]。本文压缩了字节文件中每4kB块的字节,使用香农公式计算每块的熵e作为特征:
(1)
其中,p(i)代表这一块中字节i的频率;m代表窗口内不同字节的数量。
信息熵描述了信息的不确定程度,同时也能表现出代码文件之间的逻辑,尽管恶意软件代码改变了软件原有的目的,但是其很难改变软件原有的信息量。在恶意软件变种的过程中,会通过一些简单的手段隐藏恶意行为,却难以改变整个文件信息之间的逻辑,并且信息熵在描述信息分布的同时,也同时会描述出信息分布的变化,可以有效分析出恶意软件隐藏的恶意行为。
2.2.4 N-gram
N-gram是NLP领域中非常重要的一个概念,N-gram的一个主要作用是评估2段文字之间的差异程度[13],是模糊匹配中最常用的一种手段。一连串的十六进制代码可以通过N-gram有效的分析,捕获到代码中的关键信息。1-gram有256个特征,2-gram有65 536个特征,本文对于1-gram(1gram)提取所有词的频率,而2-gram(2gram)仅考虑最受欢迎的600词与特殊字符串的前2个字节。这些特殊字符串在2.2.2节中考虑过,但由于编码的问题,一部分在反汇编文件中不可见,于是再次使用。本文还将将字节文件的一行作为1-gram(flgram),本文选取了1 000个文件中最常出现的一些行作为gram。
一个字节文件中获取的1-gram、2-gram与整行的1-gram例子如图5所示。

图5 N-gram应用在字节码中Fig.5 N-gram applied in byte code
2.2.5 图像特征
恶意软件可以通过将每个字节解释为图像中的一个像素而把字节文件形象转化为灰度图像[7],将字节表示为像素,很容易可以得到图像的像素强度,因此提取图像的前300~600像素强度(img)作为特征。同时,借用文献[7]的思路,本文在asm文件中也进行了应用。
将代码转换为图像,可以获得非常精致的纹理,这些纹理很大程度地描述了代码之间的相似程度以及代码的函数结构和代码之间的文件结构,恶意软件相似的行为也通常包括相同的代码或相同的函数调用,并且部分恶意软件作者通过将代码改为相似的格式用于隐藏部分恶意信息,将代码转为肉眼可见的图像,可以有效地分析代码在恶意行为上的相似之处。
图6中,图6a与图6b分别是Ramnit家族中一例恶意软件将字节码与反汇编代码转化成的灰度图像,图6c与图6d是Gatak家族。可以看出,不同家族的灰度图纹理上有较大差异。

(a)—Ramnlt家族asm文件样例; (b)—Ramnlt家族bytes文件样例; (c)—Garak家族asm文件样例; (d)—Garak家族bytes文件样例
2.3 分类器
本文选取了3种算法进行了考虑分别是常用的ExtraTreesClassifier、支持向量机和一种渐进回归树的优化算法xgboost[14],对比多种分类器,最终实验使用多分类器融合,使用80%的xgboost和20%的ExtraTreesClassifier作为分类算法。
3 实 验
3.1 数 据
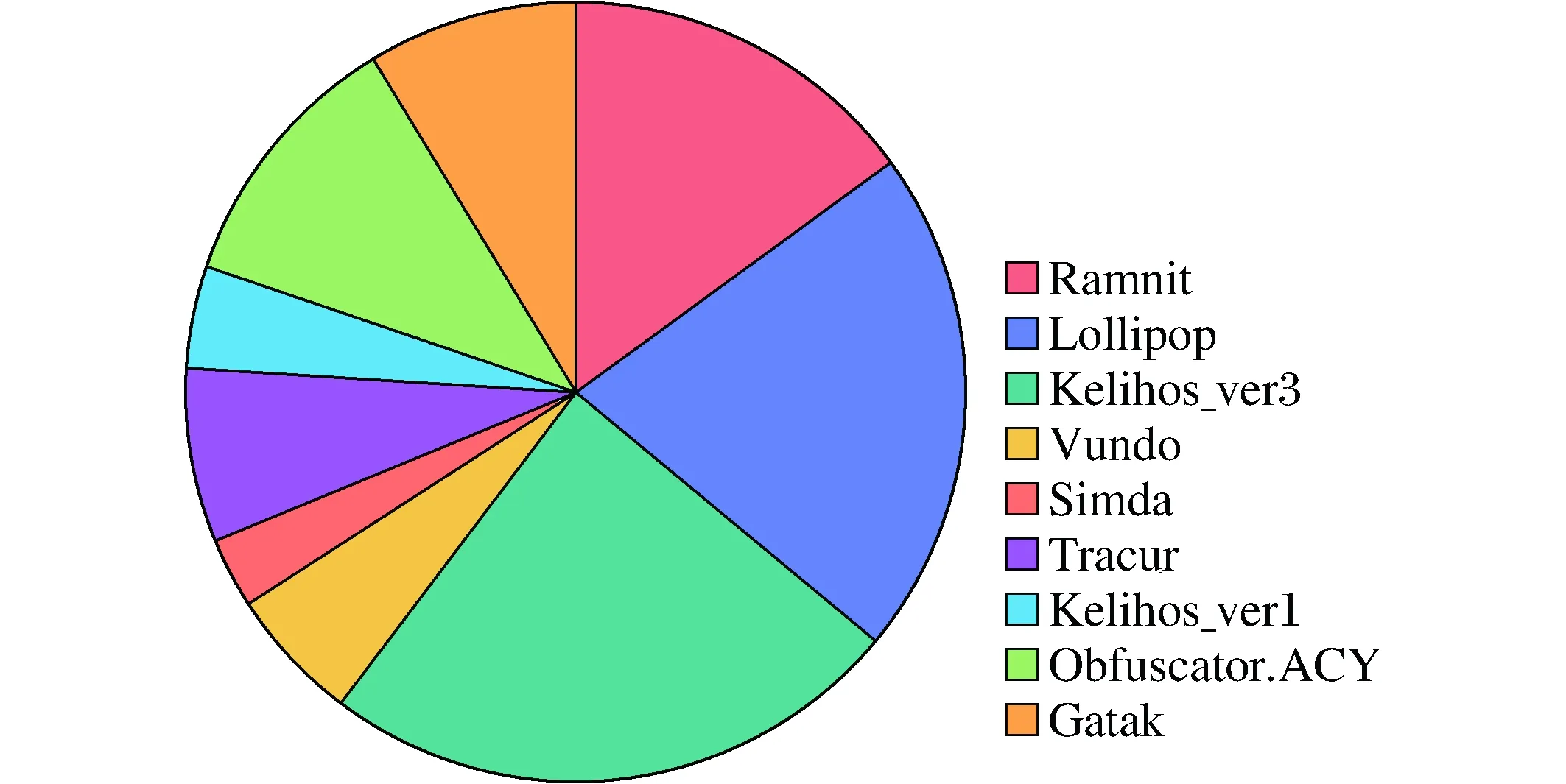
图7 数据分布饼状图Fig.7 Data Distribution Pie Chart
微软在2015年在kaggle平台上发布了一组近0.3T的带有标签的样本供各界恶意软件研究者研究学习。考虑到数据的代表性,我们在VirusTotal等相关恶意软件交流平台中又收集了近0.1T的近期数据。这些数据被分成9个家族(0~8),分别是Ramnit, Lollipop, Kelihos_ver3, Vundo, Simda, Tracur, Kelihos_ver1, Obfuscator.ACY和Gatak(如图7)。
3.2 评估方法
本文使用对数损失作为分类系统的性能的评估方法,对数损失公式:
(2)
式(2)中N和M分别代表样本的数量与恶意软件家族的数量,yij表示样本i是否被预测为j类,而pij则表示为样本i被预测为j类的概率。
3.3 结果与分析
本系统在一台四核2.60 GHz处理器,8 G内存的个人笔记本上运行。
将所有的样本选进行了多次交叉验证,取平均值作为最终结果,最终logloss为0.006 4。最终模型多次交叉评估后对应的对数混淆矩阵如图8所示。图9是本文选取的各个特征提取所需的平均时间,将其相加,即可得到系统总的特征提取平均时间6.5 s。
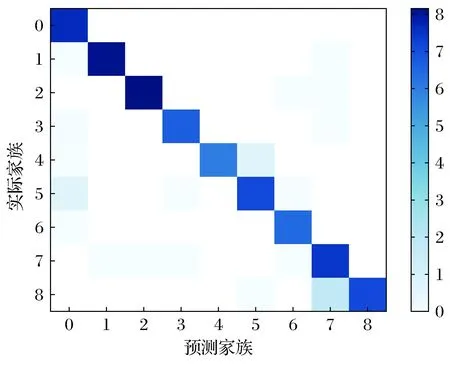
图8 对数混淆矩阵Fig.8 Logarithmic confusion matrix
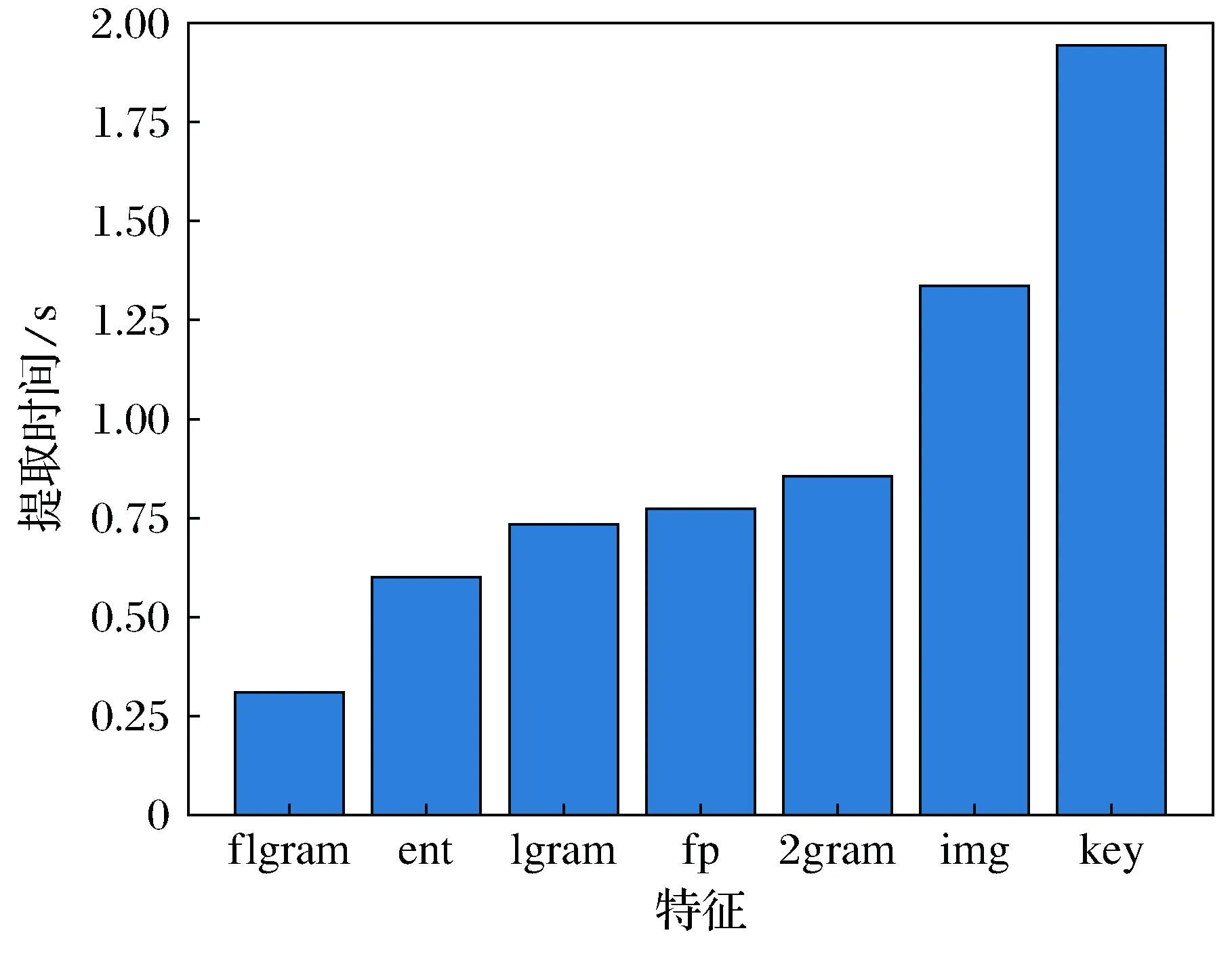
图9 各特征所需平均时间Fig.9 The average time for each feature

模型名称特征组成Logloss模型0key+fp+ent0.0128模型1img0.2473模型21gram+2gram+flgram0.0227模型3模型0+img0.0103模型4模型0+模型20.0088模型5模型5+img0.0064

表2 与其他系统性能对比Tab.2 Compared with other system performance
从图9中可以看出,将整行字节码作为1gram的方法,提取时间极短,而关键字特征提取时间长是因为关键字特征中包含多种类型关键字,并且在系统中也发挥了很好的效果。
3.3.1 不同模型
表1是本文选取的特征不同组合情况下所得到的logloss情况,根据图中不同组合情况下的结果能看出,图片特征单独使用时表现仅达到了0.247 3的logloss,但是与其他特征搭配使用是却能有效的将logloss减少至0.006 4,并且仅搭配汇编关键字与文件属性等特征就能减少到0.010 3的logloss,辅以其他特征,可以达到非常理想的效果。
3.3.2 与其他系统对比
本文简单复现了一些已被提出的方法(表2),并且与本文的系统比较,其中Hu, X的做法收集与还原了文件的中大量的信息作为特征,得到了0.025 8的logloss,并且未曾考虑过效率问题。Mikhail的做法采用了诸如10-gram等复杂度极高的特征,已无法在个人PC中运行。而本文在提取时间6.5 s的情况下,得到0.006 4的较低logloss,即使对比于Mansour的融合方法也有效的缩短了3.5 s的提取时间,并优化了约0.003 0的logloss。
4 总 结
由于现代恶意软件通过变形和多态的方式躲避检测,恶意软件数目爆发式增长。因此对于大量的恶意软件,高效自动的恶意软件分类系统对研究人员的工作有巨大的帮助。基于这些,本文提出了一种基于机器学习方法的多种特征选择融合的高性能、高效率的恶意软件自动分类系统。通过对比实验,本文分析了已有方法的缺点与本文的优势,证明本文提出的系统在效率与性能上明显优于已有的方法。
